дЮФСДНгЃКhttp://tecdat.cn/?p=26678
дкБОБЪМЧБОжаЃЌЮвУЧЯђЖСепНщЩмСЫЛљБОЕФЫцЛњВЈЖЏТЪФЃаЭЃЌВЂЭЈЙ§СЌајађСаживЊаджиВЩбљЬжТлСЫЫќУЧЕФЙРМЦЁЃЮвУЧЪЙгУЪевцТЪЪ§ОнМЏРДЬжТл CSIR дкЫцЛњВЈЖЏТЪФЃаЭЙРМЦжаЕФЪЕЯжКЭадФмЁЃ
ЕквЛИіЫцЛњВЈЖЏТЪФЃаЭ
Сю yt ЮЊЪБМф t ЕФЙЩЦБЪевцЃЌІвt ЮЊЦфБъзМВюЁЃПМТЧвдЯТРыЩЂЪБМфЫцЛњВЈЖЏТЪФЃаЭЃК
ztЁЋN(0,1) КЭ ІЧtЁЋN(0,Іг2) ЃЌ
Іг>0 КЭ |Іе1|<1 вдШЗБЃВЈЖЏТЪзёбЦНЮШЙ§ГЬЁЃжБЙлЕиЫЕЃЌВЈЖЏЙ§ГЬБЛНЈФЃЮЊвЛИіЧБдкЙ§ГЬЃЌЦфжа log(Ів2t) зёб AR(1) Й§ГЬЁЃЮвУЧФЃФтСЫетИіЙ§ГЬЁЃдкБЪМЧБОЩЯЃЌЮвУЧНЋМЬајДІРэетаЉФЃФтЪ§ОнЁЃЮЊМђНрЦ№МћЃЌЮвУЧЖЈвх ІСt=log(Ів2t) КЭ ІШ=(?0,?1,Іг) ЮЊВЮЪ§ЯђСПЁЃ
## ЃЃЃЃЮвУЧФЃФтЪ§ОнЁЃ ##ЮвУЧЩшЖЈpi_0 = 0.05, pi = 0.98, tau = 0.02 ##ФЃФтЪ§ОнЕФКЏЪ§ #Input 2: T - ЪБМфађСаЕФДѓаЁ #Ouput: retF - ФЃФтЕФЪевцТЪЃЈyЃЉКЭВЈЖЏТЪЃЈalphaЃЉЁЃ pi <- thta\[2\] # здЯрЙиЯЕЪ§ phi tu2 <- heta\[3\] # Опгаtau2ЗНВюЕФе§ГЃЮѓВю eta <- rorm(T, 0, sqrt(tau2)) # AR(1)ВЈЖЏТЪФЃаЭЕФЮѓВю z <- rnrm(T, 0, 1) # БЖдіЯюЛиБЈФЃаЭ alha\[1\] <- cost # дкПЊЪМНзЖЮУЛгаздЯрЙиЕФЙлВьжЕ # ЗТецЪБМфађСа smdf <- s_sm(theta, T) y <- smdf$y lpa <- smdf$apha
ЕуЛїБъЬтВщдФЭљЦкФкШн

PYTHONгУЪББфТэЖћПЩЗђЧјжЦзЊЛЛЃЈMRSЃЉздЛиЙщФЃаЭЗжЮіОМУЪБМфађСа
01

02

03

04

вўТэЖћПЩЗђФЃаЭЃКЖЈвх
ЩЯУцЯдЪОЕФФЃаЭЪєгкИќвЛАуЕФвўТэЖћПЩЗђФЃаЭРрЁЃЩш h(ІСt|ІСt-1;ІШ) ЮЊдОЧЈУмЖШЃЌg(yt|ІСt;ІШ) ЮЊВтСПУмЖШЁЃ
ађСаУЩЬиПЈТо
ЖдгкЙРМЦЃЌЮвУЧЪЙгУађСаУЩЬиПЈТоЃЌЭЈЙ§ЩњГЩ P ЫцЛњГщШЁЃЌГЦЮЊЁАСЃзгЁБЃЌвдНќЫЦдЄВтКЭЙ§ТЫУмЖШЁЃЫфШЛгаКмЖрБфЬхЃЌЕЋЮвУЧжЛЬжТлЃЈСЌајЃЉађСаживЊаджиВЩбљЃЈSIRЃЉЁЃ
SIRгаСНИіВНжшЃЌдЄВтКЭЙ§ТЫВНжшЁЃ
ОпгаСЌајађСаживЊаджиВЩбљЕФЙ§ТЫВНжшЃКЫуЗЈ
СЌајађСаживЊаджиВЩбљ(CSIR) ЪЧ SIR ЕФвЛжжБфЬхЃЌЫќЬсЙЉСЫЙ§ТЫСЃзгЕФСЌајАцБОЁЃИУЗНЗЈЕФжївЊгХЕуЪЧЫќШЗБЃФЃФтЫЦШЛЯрЖдгкВЮЪ§ ІШ ЕФЯђСПЪЧЁАЦНЛЌЕФЁБЃЌвдБуФмЙЛЪЙгУЛљгкЬнЖШЕФгХЛЏЗНЗЈНјаагХЛЏЁЃ
ЪЙгУ CSIR ЕФЙ§ТЫВНжшЕФЫуЗЈШчЯТЃК
- ЪфШыЃК
- ОпгаЬѕФП u(j) ЕФХХађОљдШЫцЛњВЩбљЯђСПЃЈОмОјВЩбљЃЉЃЛ
- ЖдгкЖЈвхЮЊ W(i)t ЕФУПИіСЃзг ІС(i)t дк yt ДІЦРЙРЕФе§ЬЌ PDFЃЛ
- ДгдЄВтУмЖШ ІС(i)t жаХХађЁЃ
ДњТы
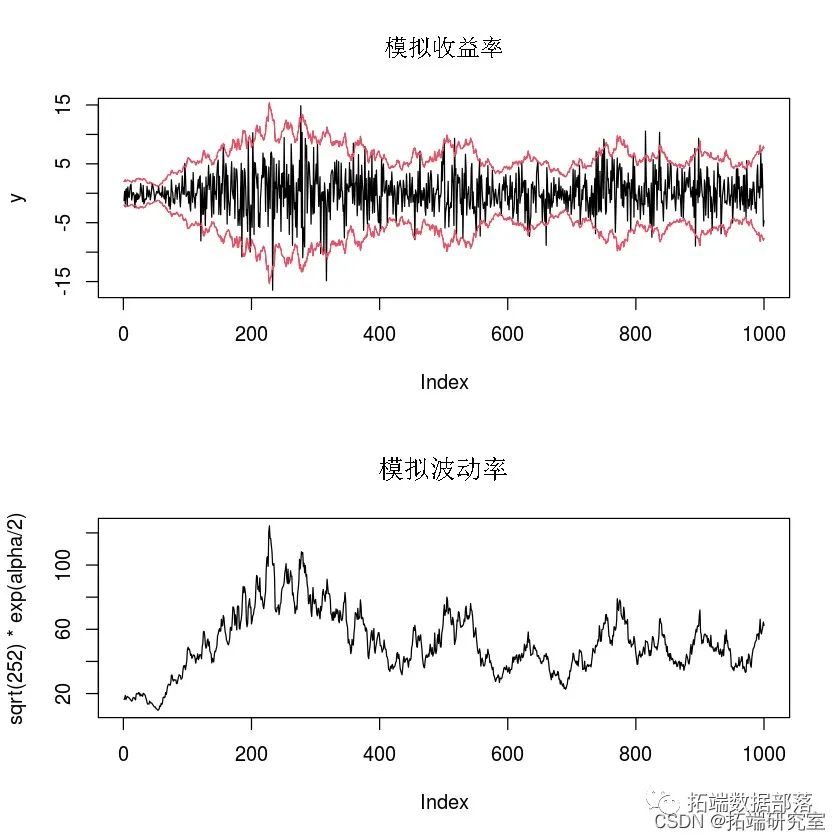
ЯТУцЮвУЧЩњГЩСЃзгМЏЃЌВЂЪЙгУ SIR НќЫЦЙ§ТЫКЭдЄВтУмЖШЁЃдкЕквЛИіЭМжаЃЌЮвУЧЯдЪОСЫдЄВтУмЖШЦНОљжЕМАЦф 95 КЭ 5 ЗжЮЛЪ§ЁЃдкЭЌвЛИіЭМжаЃЌЮвУЧЛЙЛцжЦСЫВЈЖЏТЪЕФецЪЕжЕЁЃдкЕкЖўИіЭМжаЃЌЮвУЧЛцжЦСЫЙ§ТЫУмЖШЕФШШЭМЁЃКкЯпЪЧеце§ЕФВЈЖЏТЪЁЃ
# --> ЃЈдЪМЃЉађСаживЊадШЁбљЫуЗЈЃКЙ§ТЫВНжш # ЪфШы 1: appr - дЄВтУмЖШ # ЪфШы 2: aha_t - дк y\[t\]ЦРЙРЕФе§ЬЌ pdf # ЪфШы 3: u - ХХађОљдШЕФЫцЛњВЩбљЯђСП(ОмОјВЩбљ) # ЪфГіЃКalphp - СЃзгЙ§ТЫ # ХХађКЭМгШЈЕФЫйЖШМѕТ§ alhawt <- alph\_wt/sum(alpha\_wt) alpa\_rt <- cbind(seq(1,P,1),alpha\_pr) alhapr\_id <- lpha\_sort\[order(alha_r\[,2\]),\]ЁЃ alhapr <- alpha_ridx\[,2\] alph\_ix <- alha\_p_idx\[,1\] alha\_wt <- alp\_w\[alpha_idx\] alhacwt <- c(0, cumsum(alpha_wt)) j <- 1 for (i in 1:P) while((aphawt\[i\] < u\[j\]) && (u\[j\] <= alpawt\[i+1\])){ lp\_up\[j\] <- alpa\_r\[i\] ЁЃ } # ---------------------------------------------------------------------- # ЩшжУСЃзгЙ§ТЫ # ---------------------------------------------------------------------- P <- 200 # ЩшжУСЃзгЕФЪ§СП lph_up <- rnorm(P,0,0.1) alpar <- rep(0,P) aha_w <- rep(1,P)/P alphup_mt <- matrix(rep(0,T*3),T) ala_pmat <- matrix(rep(0, T*3),T) ah_prare <- matrix(rep(0, T*20),T) # ДгвЛИіНќЫЦжЕжаЩњГЩвЛИігЩPИіЫцЛњГщбљзщГЩЕФСЃзгМЏ # УПИіЪБМфађСаЕуЕФдЄВтКЭЙ§ТЫЗжВМЕФНќЫЦжЕ for (t in 1:T){ # дЄВтВНжш appr <- nst + phi * alpp + rnorm(P,0,srt(tau2)) # ИќаТ/Й§ТЫВНжш(ЬЌУмЖШ) ahat <- dnorm(y\[t\]*rep1,P), mean=0 , sd = exp(phar/2) alpap <- sir(alhapr=aph\_r,alhawt=alpa\_t, u=sort(runif(P,0,1)) # ЛцжЦдЄВтУмЖШЭМ plot(sqrt(252) * exp(alpha/2), type='l') ## ЩИбЁУмЖШШШЭМ het <- matrix(rep(1,T*20), T, 20) plot(NULL, xlim = c(1, T), ylim = c(0, 160), main="Й§ТЫУмЖШШШЭМ",

дкЯТвЛВПЗжжаЃЌЮвУЧЬсЙЉСЫ CSIR ЕФ R КЭ C АцБОЁЃR АцБОНіГігкДњТыПЩЖСадЕФФПЕФЖјЬсЙЉЁЃ
###СЌајађСаживЊаджиШЁбљЃКЙ§ТЫВНжш # ЪфШы 1: alppr - дЄВтУмЖШ # ЪфШы 2: alhawt - дк y\[t\]ДІЦРЙРЕФе§ЬЌ pdf # ЪфШы 3: u - ХХађОљдШЕФЫцЛњВЩбљЯђСП(ОмОјВЩбљ) # ЪфГіЃКala_up - СЃзгЙ§ТЫЃЈСЌајАцБОЃЉЁЃ # RАцБО(адФмНЯТ§) cir <- function(aph_r, phwt, u) { P <- length(aphpr) al_p <- rep(0,P) # ХХађКЭМгШЈЕФЫйЖШМѕТ§ alpha\_wt <- alpha\_wt/sum(alpha_wt) j <- 1 for (i in 1:P){ while((a_ct\[i\] < u\[j\]) & (u\[j\] <= alhwt\[i+1\])){ alh\_u\[j\] <- aph\_pr\[i\] + ((apapr\[i+1\]-alar\[i\])/(ala\_ct\[i+1\]-alpha\_cwt\[i\]) * (u\[j\]-ala_wt\[i\]) } csir.c <- function(alppr, aht, u) { P <- length(alpap) ala_u <- rep(0,P) .C("cir", alpup=as.dole(aphup), alha\_pr=as.double(aha\_r), alh_wt=as.doublephawt), u=as.double(u),
ЮвУЧЯждкЬсЙЉгУгкзюДѓЛЏЖдЪ§ЫЦШЛКЭЙРМЦВЮЪ§ ІШ ЕФДњТыЁЃЮЊСЫМЦЫуБъзМЮѓВюЃЌЮвУЧЪЙгУдк MLE ЦРЙРЕФЖдЪ§ЫЦШЛЕФ Hessian ОиеѓЕФФцОиеѓЕФЖдНЧЯпЁЃ
ЮвУЧЯждкПЩвдзЊЕНВЮЪ§ІШЕФЙРМЦЁЃЪЙгУ C жаЕФКЏЪ§НјааЙРМЦЁЃ
vas <- sfit(y, c(0.5,0.5,0.5), P, 1) ## ЯдЪОНсЙћ matrix <- cbind(heta_mle ,eta_se)
Оиеѓ

