ЪВУДЪЧСаСЊБэЃП
СаСЊБэЬсЙЉЙигкСНИіЗжРрБфСПЕФВтСПЕФећЪ§МЦЪ§ЁЃзюМђЕЅЕФСаСЊБэЪЧвЛИі2 ЁС 22ЁС2 ЦЕТЪБэЃЌгЩСНИіБфСПВњЩњЃЌУПИіБфСПгаСНИіМЖБ№ЃК
| зщ/ЙлВь | ЙлВь1 | ЙлВь2 |
| Ек1зщ | ?1 ЃЌ1?1ЃЌ1 | ?1 ЃЌ2?1ЃЌ2 |
| Ек2зщ | ?2 ЃЌ1?2ЃЌ1 | ?2 ЃЌ2?2ЃЌ2 |
ИјЖЈетбљвЛИіБэИёЃЌЮЪЬтЪЧЕк1зщЪЧЗёБэЯжГігыЕк2зщЯрБШЕФЙлВтЦЕТЪЁЃетаЉзщДњБэвђБфСПЃЌвђЮЊЫќУЧвРРЕгкздБфСПЕФЙлВьЁЃЧызЂвтЃЌСаСЊБэБиаыЪЧвЛжжГЃМћЕФЮѓНт2 ЁС 22ЁС2; ЫќУЧПЩвдОпгаШЮвтЪ§СПЕФЮЌЖШЃЌОпЬхШЁОігкБфСПЯдЪОЕФМЖБ№Ъ§ЁЃОЁЙмШчДЫЃЌгІБмУтЖдОпгаЖрИіЮЌЖШЕФСаСЊБэНјааЭГМЦМьбщЃЌвђЮЊГ§ЦфЫћдвђЭтЃЌНтЪЭНсЙћНЋОпгаЬєеНадЁЃ
Ъ§ОнМЏ
вЊбаОПСаСЊБэЕФВтЪдЃЌЮвУЧНЋЪЙгУwarpbreaksЪ§ОнМЏЃК
data(warpbreaks) head(warpbreaks) ## breaks wool tension ## 1 26 A L ## 2 30 A L ## 3 54 A L ## 4 25 A L ## 5 70 A L ## 6 52 A L
етЪЧвЛИіАќКЌРДздЗФжЏаавЕЕФШ§ИіБфСПЕФЪ§ОнМЏЃКЖЯУшЪіСЫбђУЋЖЯЕФДЮЪ§ УшЪіСЫОЙ§ВтЪдЕФбђУЋРраЭ еХСІЁЪ { L ЃЌMЃЌH}еХСІЁЪ{ДѓКХЃЌжаКХЃЌH}ИјГіСЫЪЉМгдкТнЮЦЩЯЕФеХСІЃЈЕЭЃЌжаЛђИпЃЉЁЃЪ§ОнМЏжаЕФУПвЛааБэЪОЕЅИіжЏЛњЕФВтСПжЕЁЃЮЊСЫНтЪЭВЛЭЌжЏЛњЕФПЩБфадЃЌЖдбђУЋКЭеХСІЕФУПжжзщКЯНјааСЫ9ДЮВтСПЃЌЪ§ОнМЏзмЙВАќКЌ9 ? 2 ? 3 = 549?2?3=54 ЙлВьНсЙћЁЃ
ЗжЮіФПБъ
ЮвУЧЯыШЗЖЈвЛжжРраЭЕФбђУЋдкВЛЭЌГЬЖШЕФНєеХЧщПіЯТЪЧЗёгХгкСэвЛжжбђУЋЁЃЮЊСЫбаОПЮвУЧЪЧЗёПЩвдевЕНвЛаЉВювьЕФжЄОнЃЌШУЮвУЧРДПДПДЪ§ОнЃК
ЮЊСЫбаОПСДЖЯСбЪ§ЕФВювьЃЌШУЮвУЧПЩЪгЛЏЪ§ОнЃК
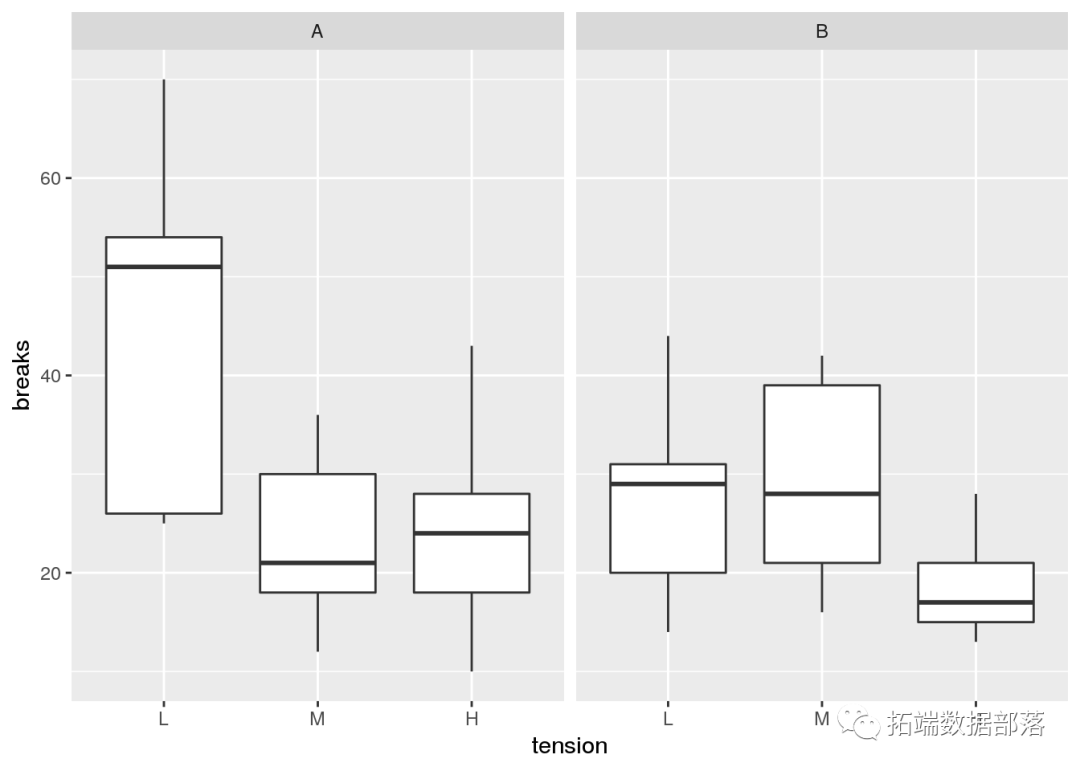
ДгЭМжаЮвУЧПЩвдПДГіЃЌзмЬхЖјбдЃЌбђУЋBгыНЯЩйЕФЖЯСбЯрЙиСЊЁЃбђУЋAЫЦКѕЬиБ№ЕЭСгЃЌвђЮЊЕЭеХСІЁЃ
зЊЛЛЮЊСаСЊБэ
ЮЊСЫЛёЕУСаСЊБэЃЌЮвУЧЪзЯШашвЊзмНсСНжжРраЭЕФбђУЋКЭШ§жжРраЭЕФеХСІЕФВЛЭЌжЏЛњЕФЖЯСбЁЃ
## wool tension breaks ## 1 A L 401 ## 2 A M 216 ## 3 A H 221 ## 4 B L 254 ## 5 B M 259 ## 6 B H 169
ШЛКѓЮвУЧЪЙгУxtabsЃЈЗЂвєЮЊНЛВцБэЃЉКЏЪ§РДЩњГЩСаСЊБэЃК
## tension ## wool L M H ## A 401 216 221 ## B 254 259 169
ЯждкЃЌdfЮвУЧгаСЫгІгУЭГМЦВтЪдЫљашЕФНсЙЙЁЃ
ЭГМЦМьбщ
гУгкШЗЖЈРДздВЛЭЌзщЕФВтСПжЕЪЧЗёЖРСЂЕФСНжжзюГЃМћЕФВтЪдЪЧПЈЗНМьбщЃЈІж2Іж2ВтЪдЃЉКЭЗбЩсЖћЕФОЋШЗВтЪдЁЃЧызЂвтЃЌШчЙћВтСПНсЙћХфЖдЃЌдђгІЪЙгУMcNemarВтЪдЃЈР§ШчЃЌПЩвдЪЖБ№ЕЅИіжЏЛњЃЉЁЃ
ЦЄЖћбЗЕФПЈЗНМьбщ
ИУ Іж2Іж2testЪЧвЛжжЗЧВЮЪ§ВтЪдЃЌПЩгІгУгкОпгаИїжжЮЌЖШЕФСаСЊБэЁЃВтЪдЕФУћГЦдДздІж2Іж2ЗжВМЃЌМДЖРСЂБъзМе§ЬЌБфСПЕФЦНЗНЗжВМЁЃетЪЧВтЪдЭГМЦЕФЗжВМІж2Іж2 ВтЪд
## [1] 7.900708e-07
гЩгкpжЕаЁгк0.05ЃЌЮвУЧПЩвддк5ЃЅЯдзХадЫЎЦНЩЯОмОјВтЪдЕФСуМйЩшЃЈЖЯСбЕФЦЕТЪЖРСЂгкбђУЋЃЉЁЃИљОнdfвЛИіШЫЕФЬѕФПЃЌШЛКѓПЩвдЩљГЦбђУЋBБШбђУЋAУїЯдИќКУЃЈЯрЖдгкОЩДЖЯСбЃЉЁЃ
ЕїВщPearsonВаВю
СэвЛжжЗНЗЈЪЧПМТЧВтЪдЕФПЈЗНжЕЁЃИУchisq.testКЏЪ§ЬсЙЉПЈЗНжЕЕФPearsonВаВюЃЈИљЃЉ ЁЃгыгЩЦНЗНВювьВњЩњЕФПЈЗНжЕЯрЗДЃЌВаВюВЛЪЧЦНЗНЕФЁЃвђДЫЃЌВаВюЗДгГСЫЙлВтжЕГЌЙ§дЄЦкжЕЃЈе§жЕЃЉЛђЕЭгкдЄЦкжЕЃЈИКжЕЃЉЕФГЬЖШЁЃдкЮвУЧЕФЪ§ОнМЏжаЃЌе§жЕБэЪОБШдЄЦкИќЖрЕФСДЖЯСбЃЌЖјИКжЕБэЪОИќЩйЕФЖЯЕуЃК
## tension ## wool L M H ## A 2.0990516 -2.8348433 0.4082867 ## B -2.3267672 3.1423813 -0.4525797
ВаСєЮяБэУїЃЌгыбђУЋAЯрБШЃЌбђУЋBЕФЕЭеХСІКЭИпеХСІЖЯСбБШдЄЦкЕФвЊЩйЁЃШЛЖјЃЌЖдгкжаЕШеХСІЃЌбђУЋBБШдЄЦкЕФЖЯСбИќЖрЁЃдйДЮЃЌЮвУЧЗЂЯжЃЌећЬхбђУЋBгХгкбђУЋA.ВаСєЮяЕФжЕвВБэУїбђУЋBЖдгкЕЭеХСІЃЈВаВюЮЊ2.1ЃЉЃЌИпеХСІЃЈ0.41ЃЉКЭжаЕШеХСІбЯжиЃЈ - 2.8ЃЉЁЃШЛЖјЃЌВаСєЮягажњгкЮвУЧЪЖБ№бђУЋBЕФЮЪЬтЃКЫќЖджаЕШеХСІЕФБэЯжВЛМбЁЃетНЋШчКЮДйНјНјвЛВНЗЂеЙЃПЮЊСЫЛёЕУдкЫљгаеХСІЫЎЦНЯТБэЯжСМКУЕФбђУЋЃЌЮвУЧашвЊзЈзЂгкИФЩЦбђУЋBЕФжаЕШеХСІЁЃЮЊДЫЃЌЮвУЧПЩвдПМТЧЪЙбђУЋAдкжаЕШеХСІЯТБэЯжИќКУЕФЬиадЁЃ
ЗбЩсЖћЕФШЗЧаВтЪд
FisherЕФОЋШЗВтЪдЪЧгУгкВтЪдЖРСЂадЕФЗЧВЮЪ§ВтЪдЃЌЭЈГЃНігУгкВтЪд 2 ЁС 22ЁС2СаСЊБэЁЃзїЮЊОЋШЗЯдзХадМьбщЃЌFisherМьбщЗћКЯЫљгаМйЩшЃЌдкДЫЛљДЁЩЯЖЈвхМьбщЭГМЦСПЕФЗжВМЁЃЪЕМЪЩЯЃЌетвтЮЖзХДэЮѓОмОјТЪЕШгкВтЪдЕФЯдзХадЫЎЦНЃЌЖдгкНќЫЦВтЪдЃЌР§ШчІж2Іж2ВтЪдЁЃМђЖјбджЎЃЌFisherЕФОЋШЗВтЪдвРРЕгкЪЙгУЖўЯюЪНЯЕЪ§ИљОнГЌМИКЮЗжВММЦЫуpжЕЃЌМДЭЈЙ§
p = ЃЈn1 ЃЌ1+ n1 ЃЌ2?1 ЃЌ1ЃЉЃЈn2 ЃЌ1+ n2 ЃЌ2?2 ЃЌ1ЃЉЃЈn1 ЃЌ1+ n1 ЃЌ2+ n2 ЃЌ1+ n2 ЃЌ2?1 ЃЌ1+ n2 ЃЌ1ЃЉp=ЃЈ?1ЃЌ1+?1ЃЌ2?1ЃЌ1ЃЉЃЈ?2ЃЌ1+?2ЃЌ2?2ЃЌ1ЃЉЃЈ?1ЃЌ1+?1ЃЌ2+?2ЃЌ1+?2ЃЌ2?1ЃЌ1+?2ЃЌ1ЃЉ
гЩгкМЦЫуЕФвђзгПЩФмБфЕУЗЧГЃДѓЃЌFisherОЋШЗМьбщПЩФмВЛЪЪгУгкДѓбљБОСПЁЃ
ЧызЂвтЃЌЮоЗЈжИЖЈВтЪдЕФЬцДњЗНЗЈЃЌdfвђЮЊгХЪЦБШЃЈБэЪОаЇЙћДѓаЁЃЉНіЖЈвхЮЊ2 ЁС 22ЁС2 ОиеѓЃК
O R = n1 ЃЌ1?1 ЃЌ2/ n2 ЃЌ1?2 ЃЌ2?[R=?1ЃЌ1?1ЃЌ2/?2ЃЌ1?2ЃЌ2
ЮвУЧШдШЛПЩвджДааFisherОЋШЗМьбщвдЛёЕУpжЕЃК
## [1] 8.162421e-07
ЕУЕНЕФpжЕРрЫЦгкДгжаЛёЕУЕФpжЕ Іж2Іж2 ВтЪдВЂЕУГіЯрЭЌЕФНсТлЃКЮвУЧПЩвдОмОјСуМйЩшЃЌМДбђУЋЕФРраЭгыВЛЭЌгІСІЫЎЦНЯТЙлВьЕНЕФЖЯСбДЮЪ§ЮоЙиЁЃ
зЊЛЛЮЊ2ГЫ2Оиеѓ
ЮЊСЫжИЖЈБИбЁМйЩшВЂЛёЕУгХЪЦБШЃЌЮвУЧПЩвдМЦЫуШ§епЕФВтЪд 2 ЁС 22ЁС2ПЩвдЙЙдьЕФОиеѓdfЃК
гЩгкЬцДњЗНАИЩшжУЕУИќДѓЃЌетвтЮЖзХЮвУЧе§дкНјааЕЅЮВВтЪдЃЌЦфжаСэвЛжжМйЩшЪЧбђУЋAгыбђУЋBЕФЖЯСбДЮЪ§ЯрЙиЃЈМДЮвУЧдЄЦкO R > 1?[R>1ЃЉЁЃЭЈЙ§жДааВтЪд2 ЁС 22ЁС2БэИёЃЌЮвУЧвВЛёЕУСЫНтЪЭадЃКЮвУЧЯждкПЩвдЧјЗжбђУЋВЛЭЌЕФОпЬхЬѕМўЁЃШЛЖјЃЌдкНтЪЭpжЕжЎЧАЃЌЮвУЧашвЊОРе§ЖрИіМйЩшМьбщЁЃдкетжжЧщПіЯТЃЌЮвУЧНјааСЫШ§ДЮВтЪдЁЃдкетРяЃЌЮвУЧжЛашНЋ0.05ЕФГѕЪМЯдзХадЫЎЦНЕїећЮЊ0.053= 0.01 6???0.053=0.016?ИљОнBonferroniЗНЗЈЁЃИљОнЕїећКѓЕФуажЕЃЌвдЯТВтЪдЯдзХЃК
## [1] "L vs others"
етвЛЗЂЯжБэУїЃЌШчЙћгІСІНЯЧсЃЌбђУЋBНіЯдзХгХгкбђУЋA. ЧызЂвтЃЌЮвУЧвВПЩвдВЩгУЙЙНЈЗНЗЈ2 ЁС 22ЁС2 Оиеѓ Іж2Іж2ВтЪдЁЃЫцзХІж2Іж2 ШЛЖјЃЌВтЪдВЂВЛЪЧБивЊЕФЃЌвђЮЊЮвУЧЕФЗжЮіЛљгкВаВюЁЃ
еЊвЊЃКПЈЗНЖдЗбЩсЖћЕФОЋШЗМьбщ
вдЯТЪЧСНИіВтЪдЕФЪєадеЊвЊЃК
| БъзМ | ПЈЗНМьбщ | ЗбЩсЖћЕФШЗЧаВтЪд |
| зюаЁбљБОСП | Дѓ | аЁ |
| зМШЗад | НќЫЦ | ОЋШЗ |
| СаСЊБэ | ШЮвтЮЌЖШ | ЭЈГЃЮЊ2x2 |
| НтЪЭ | ЦЄЖћбЗВаВю | гХЪЦБШ |
ЭЈГЃЃЌFisherОЋШЗМьбщгХгкПЈЗНМьбщЃЌвђЮЊЫќЪЧвЛжжОЋШЗМьбщЁЃШчЙћЕЅИіЯИАћЕФЙлВьНсЙћКмЩйЃЈР§ШчаЁгк10ЃЉЃЌдђгІЬиБ№БмУтПЈЗНМьбщЁЃгЩгкFisherЕФОЋШЗМьбщЖдгкДѓбљБОСПКЭОЋШЗЖШПЩФмдкМЦЫуЩЯЪЧВЛПЩааЕФІж2Іж2 ВтЪдЫцзХбљБОЪ§СПЕФдіМгЖјдіМг Іж2Іж2дкетжжЧщПіЯТЃЌВтЪдЪЧКЯЪЪЕФЬцДњЦЗЁЃСэвЛИігХЕуСЫІж2Іж2 ВтЪдЪЧЫќИќЪЪКЯЮЌЪ§ГЌЙ§ЕФСаСЊБэ 2 ЁС 22ЁС2ЁЃ
