ШЋЮФСДНгЃКhttp://tecdat.cn/?p=2858
БОЮФЕФФПЕФЪЧЖдШчКЮдкRжаНјааЩњДцЗжЮіНјааМђЖЬЖјШЋУцЕФЦРЙРЁЃЙигкИУжїЬтЕФЮФЯзКмЙуЗКЃЌНіЩцМАгаЯоЪ§СПЕФЃЈГЃМћЃЉЮЪЬтЁЃПЩгУЕФRАќЪ§СПЗДгГСЫЖдИУжїЬтЕФбаОПЗЖЮЇЁЃЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
RАќ
ПЩвдЪЙгУИїжжRАќРДНтОіЬиЖЈЮЪЬтЁЃвдЯТЪЧБОДЮгУгкЖСШЁЃЌЙмРэЃЌЗжЮіКЭЯдЪОЪ§ОнЕФШэМўАќЁЃ
дЫаавдЯТаавдАВзАКЭМгдиЫљашЕФАќЁЃ
if (!require(pacman)) install.packages("pacman") pacman::p_load(tidyverse, survival )
**
Ъ§Он
ИУЦРМлНЋЛљгкorcaЪ§ОнМЏЃЌЪ§ОнМЏАќКЌ1985Фъ1дТ1ШежС2005Фъ12дТ31ШеЦкМфЗвРМзюББВПЪЁЗнеяЖЯЮЊПкЧЛСлзДЯИАћАЉЃЈOSCCЃЉЕФ338УћЛМепЕФвЛВПЗжЁЃЛМепЕФЫцЗУЪМгкАЉжЂеяЖЯжЎШеЃЌВЂгк2008Фъ12дТ31ШеЫРЭіЃЌЧЈвЦЛђЫцЗУНижЙШеЦкНсЪјЁЃЫРЭідвђЗжЮЊСНРрЃКЃЈ1ЃЉ ЃЉOSCCЫРЭі; ЃЈ2ЃЉЦфЫћдвђдьГЩЕФЫРЭіЁЃ
Ъ§ОнМЏАќКЌвдЯТБфСПЃК
id=ађКХЃЌ
sex=адБ№ЃЌРрБ№1 =ЁАХЎадЁБЃЌ2 =ЁАФаадЁБЃЌ
age=еяЖЯАЉжЂШеЦкЕФФъСфЃЈФъЃЉЃЌ
stage=жзСіЕФTNMЗжЦкЃЈвђзгЃЉЃК1 =ЁАIЁБЃЌ...ЃЌ 4 =ЁАIVЁБЃЌ5 =ЁАunknЁБ
time=здеяЖЯжСЫРЭіЛђЩѓВщЕФЫцЗУЪБМфЃЈвдФъЮЊЕЅЮЛЃЉЃЌ
event=НсЪјЫцЗУЕФЪТМўЃЈвђзгЃЉЃК1 =е§ГЃЃЌ2 =ПкЧЛАЉЫРЭіЃЌ 3 =ЦфЫћдвђдьГЩЕФЫРЭіЁЃ
НЋЪ§ОнДгURLМгдиЕНRжаЁЃ
head(orca)
id sex age stage time event 1 1 Male 65.42274 unkn 5.081 Alive 2 2 Female 83.08783 III 0.419 Oral ca. death 3 3 Male 52.59008 II 7.915 Other death 4 4 Male 77.08630 I 2.480 Other death 5 5 Male 80.33622 IV 2.500 Oral ca. death 6 6 Female 82.58132 IV 0.167 Other death
summary(orca)
id sex age stage time event Min. : 1.00 Female:152 Min. :15.15 I :50 Min. : 0.085 Alive :109 1st Qu.: 85.25 Male :186 1st Qu.:53.24 II :77 1st Qu.: 1.333 Oral ca. death:122 Median :169.50 Median :64.86 III :72 Median : 3.869 Other death :107 Mean :169.50 Mean :63.51 IV :68 Mean : 5.662 3rd Qu.:253.75 3rd Qu.:74.29 unkn:71 3rd Qu.: 8.417 Max. :338.00 Max. :92.24 Max. :23.258
ЩњДцЪ§ОнЗжЮі
ЩњДцЗжЮіВржигкЪТМўЪ§ОнЕФЪБМфЁЃдкЮвУЧЕФР§згжаЃЌЪЧеяЖЯКѓЕФЫРЭіЪБМфЁЃ
ЮЊСЫЖЈвхЪЇаЇЪБМфЫцЛњБфСПЃЌЮвУЧашвЊЃК
1ЁЃЪБМфЦ№дДЃЈеяЖЯOSCCЃЉЃЌ
2ЁЃЪБМфГпЖШЃЈеяЖЯКѓЕФФъЪ§ЃЌФъСфЃЉЃЌ
3ЁЃЪТМўЕФЖЈвхЁЃЮвУЧНЋЪзЯШПМТЧзмЫРЭіТЪ ЁЃ
ЭМ1ЃКзЊЛЛЕФПђЭМЁЃ
Alive Oral ca. death Other death 109 122 107
FALSE TRUE 109 229
вдЭМаЮЗНЪНЯдЪОЙлВьЕНЕФЫцЗУЪБМфЖдгкЩњДцЪ§ОнЕФЗжЮіЗЧГЃгаАяжњЁЃ

OSCCЫРЭіИќгаПЩФмдкеяЖЯКѓдчЦкЗЂЩњЃЌЖјВЛЪЧЦфЫћдвђв§Ц№ЕФЫРЭіЁЃРраЭдѕУДбљЃП
'Surv' num [1:338, 1:2] 5.081+ 0.419 7.915 2.480 2.500 0.167 5.925+ 1.503 13.333 7.666+ ... - attr(*, "dimnames")=List of 2 ..$ : NULL ..$ : chr [1:2] "time" "status" - attr(*, "type")= chr "right"
ШЛКѓНЋДДНЈЕФЩњДцЖдЯѓгУзїЩњДцЗжЮіЕФЦфЫћЬиЖЈКЏЪ§жаЕФвђБфСПЁЃ
ЙРМЦЩњДцКЏЪ§
ЗЧВЮЪ§ЙРМЦ
ЮвУЧНЋЪзЯШНщЩмвЛРрЗЧВЮЪ§ЙРМЦ ЁЃ
KaplanЈCMeier
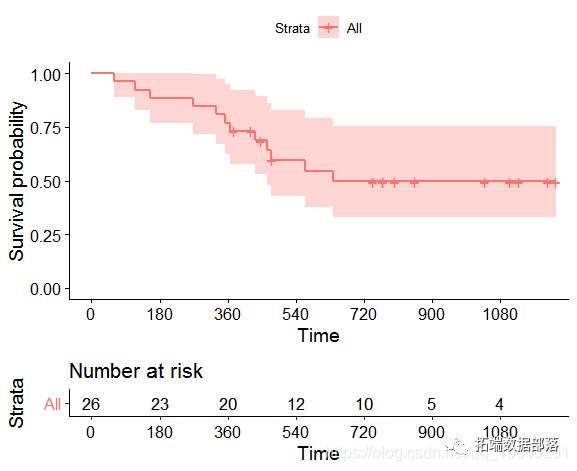
ЩњДцЧњЯпЛљгкУПИіЫРЭіЪБМфЕФЗчЯеЪ§СПКЭЪТМўЪ§СПЁЃАќЕФsurvfit()ДДНЈЃЈЙРМЦЃЉЩњДцЧњЯп ЁЃ
Call: survfit(formula = Surv(time, all) ~ 1, data = orca) n events *rmean *se(rmean) median 0.95LCL 0.95UCL 338.000 229.000 8.060 0.465 5.418 4.331 6.916 * restricted mean with upper limit = 23.3
КЏЪ§ЗЕЛиЙРМЦЕФЩњДцЧњЯпЕФеЊвЊЁЃ
time n.risk n.event n.censor surv std.err upper lower 1 0.085 338 2 0 0.9940828 0.004196498 1.0000000 0.9859401 2 0.162 336 2 0 0.9881657 0.005952486 0.9997618 0.9767041 3 0.167 334 4 0 0.9763314 0.008468952 0.9926726 0.9602592 4 0.170 330 2 0 0.9704142 0.009497400 0.9886472 0.9525175 5 0.246 328 1 0 0.9674556 0.009976176 0.9865584 0.9487228 6 0.249 327 1 0 0.9644970 0.010435745 0.9844277 0.9449699
ggsurvplot()ЕФsurvminerЬсЙЉСЫЙРМЦЕФЩњДцЧњЯпЕФаХЯЂадЫЕУїЁЃ

ФЌШЯЕФKMЭМБэЯдЪОСЫЩњДцКЏЪ§ЁЃ
ЕуЛїБъЬтВщдФЭљЦкФкШн

ЁОЪгЦЕЁПЗжРрФЃаЭЦРЙР:ОЋШЗТЪЁЂейЛиТЪЁЂROCЧњЯпЁЂAUCгыRгябдЩњДцЗжЮіЪБМфвРРЕадROCЪЕЯж
01

02

03

04
ЩњДцЧњЯпЙРЫу
ЩњДцЧњЯпдкОЋЫуЪІКЭШЫПкЭГМЦбЇжаЗЧГЃЦеБщЁЃЫќЬиБ№ЪЪгУгкЗжзщЪ§ОнЁЃ
ЮЊСЫдкЪЕМЪЪОР§жаЯдЪОДЫЗНЗЈЃЌЮвУЧЪзЯШашвЊДДНЈОлКЯЪ§ОнЃЌМДНЋКѓајЗжзщВЂдкУПИіВужаМЦЫуЗчЯеЁЃ
ЛљгкЗжзщЕФЪ§ОнЃЌЮвУЧЙРМЦЛсгУЩњДцЧњЯпЁЃ
nsubs nlost nrisk nevent surv pdf hazard se.surv se.pdf se.hazard 0-1 338 0 338.0 64 1.0000 0.1893 0.2092 0.0000 0.0213 0.0260 1-2 274 4 272.0 41 0.8107 0.1222 0.1630 0.0213 0.0179 0.0254 2-3 229 9 224.5 21 0.6885 0.0644 0.0981 0.0252 0.0136 0.0214 3-4 199 12 193.0 20 0.6241 0.0647 0.1093 0.0265 0.0140 0.0244 4-5 167 9 162.5 13 0.5594 0.0448 0.0833 0.0274 0.0121 0.0231 5-6 145 14 138.0 13 0.5146 0.0485 0.0989 0.0279 0.0131 0.0274 6-7 118 5 115.5 8 0.4662 0.0323 0.0717 0.0283 0.0112 0.0254 7-8 105 8 101.0 9 0.4339 0.0387 0.0933 0.0286 0.0126 0.0311 8-9 88 7 84.5 1 0.3952 0.0047 0.0119 0.0288 0.0047 0.0119 9-10 80 4 78.0 8 0.3905 0.0401 0.1081 0.0288 0.0137 0.0382 10-11 68 4 66.0 5 0.3505 0.0266 0.0787 0.0291 0.0116 0.0352
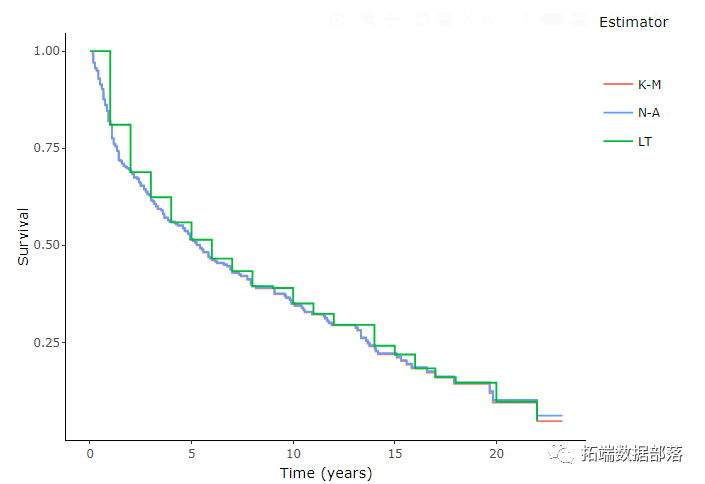
Nelson-AalenЙРМЦ
ЭМаЮБШНЯ
ПЩвдЛцжЦВЛЭЌЕФЩњДцКЏЪ§ЙРМЦжЕРДЦРЙРЧБдкЕФВювьЁЃ
ПЩвдДгЙРМЦЕФЩњДцЧњЯпЕМГіжюШчЗжЮЛЪ§ЕФМЏжаЧїЪЦЕФЖШСПЁЃ
q km.quantile km.lower km.upper fh.quantile fh.lower fh.upper 25 0.25 1.333 1.084 1.834 1.333 1.084 1.747 50 0.50 5.418 4.331 6.916 5.418 4.244 6.913 75 0.75 13.673 11.748 16.580 13.673 11.748 15.833
ЙРМЦАыЪ§ШЫЕФЪйУќГЌЙ§5.4ФъЁЃ
ЕквЛИіЫФЗжжЎвЛЕФШЫдк1.3ФъФкЫРЭіЃЌЖјЧАЫФЗжжЎШ§ЕФШЫЕФЪйУќГЌЙ§1.3ЫъЁЃ
ЧАШ§ЗжжЎШ§ЕФШЫдк13.7ФъФкЫРЭіЃЌЖјЧАЫФЗжжЎвЛЕФШЫЫРЭіЪБМфГЌЙ§13.7ЫъЁЃ
ЙРМЦСПЕФЭМаЮБэЪОЃЈЛљгкЪЙгУKMЕФЩњДцЧњЯпЃЉ

ВЮЪ§ЙРЫу
ЮвУЧНЋПМТЧШ§жжГЃМћЕФбЁдёЃКжИЪ§ЃЌWeibullКЭlog-logisticФЃаЭЁЃ
flexsurvreg(formula = su_obj ~ 1, data = orca, dist = "exponential") Estimates: est L95% U95% se rate 0.11967 0.10513 0.13621 0.00791 N = 338, Events: 229, Censored: 109 Total time at risk: 1913.673 Log-likelihood = -715.1802, df = 1 AIC = 1432.36
ЭЌбљЃЌПЩвдгУЗЧВЮЪ§ЙРМЦЭМаЮЕиБШНЯВЛЭЌЕФЗНЗЈ


ЩњДцЧњЯпЕФБШНЯ
Р§ШчЃЌжзСіНзЖЮЪЧАЉжЂДцЛюбаОПжаЕФживЊдЄКѓвђЫиЁЃЮвУЧПЩвдЙРМЦКЭЛцжЦВЛЭЌбеЩЋЕФВЛЭЌзщЃЈНзЖЮЃЉЕФЩњДцЧњЯпЁЃ
stage D Y x pt rate lower upper conf.level 1 I 25 336.776 25 336.776 0.07423332 0.04513439 0.1033322 0.95 2 II 51 556.700 51 556.700 0.09161128 0.06646858 0.1167540 0.95 3 III 51 464.836 51 464.836 0.10971611 0.07960454 0.1398277 0.95 4 IV 57 262.552 57 262.552 0.21709985 0.16073995 0.2734597 0.95 5 unkn 45 292.809 45 292.809 0.15368380 0.10878136 0.1985862 0.95
ЭЈГЃЃЌгыОпгаИпНзЖЮжзСіЕФЛМепЯрБШЃЌОпгаНЯЕЭНзЖЮжзСіЕФеяЖЯЛМепОпгаНЯЕЭЕФЃЈЫРЭіТЪЃЉЁЃПЩвдЪЙгУsurvfit()КЏЪ§жДааЩњДцКЏЪ§ЕФећЬхБШНЯЁЃ
Call: survfit(formula = su_obj ~ stage, data = orca) n events median 0.95LCL 0.95UCL stage=I 50 25 10.56 6.17 NA stage=II 77 51 7.92 4.92 13.34 stage=III 72 51 7.41 3.92 9.90 stage=IV 68 57 2.00 1.08 4.82 stage=unkn 71 45 3.67 2.83 8.17
гЩгкЕЭжзСіНзЖЮЕФЗЂВЁТЪНЯЕЭЃЌвђДЫжзСіЗжЦкдіМгЕФжаЮЛЩњДцЪБМфвВЛсМѕЩйЁЃПЩвдЙлВьЕНЯрЭЌЕФааЮЊЃЌЗжБ№еыЖдВЛЭЌЕФжзСіНзЖЮЛцжЦKMЩњДцЧњЯпЁЃ

вВПЩвдЮЊУПИіНзЖЮМЖБ№ЙЙНЈећИіЩњДцБэЁЃетРяЪЧУПИіжзСіНзЖЮЩњДцБэЕФЧА3ааЁЃ
# Groups: strata [5]
time n.risk n.event n.censor surv std.err upper lower strata <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> 1 0.17 50 1 0 0.98 0.0202 1 0.942 I 2 0.498 49 1 0 0.96 0.0289 1 0.907 I 3 0.665 48 1 0 0.94 0.0357 1 0.876 I 4 0.419 77 1 0 0.987 0.0131 1 0.962 II 5 0.498 76 1 0 0.974 0.0186 1 0.939 II 6 0.665 75 1 0 0.961 0.0229 1 0.919 II 7 0.167 72 1 0 0.986 0.0140 1 0.959 III 8 0.249 71 1 0 0.972 0.0199 1 0.935 III 9 0.413 70 1 0 0.958 0.0246 1 0.913 III 10 0.085 68 2 0 0.971 0.0211 1 0.931 IV 11 0.162 66 1 0 0.956 0.0261 1 0.908 IV 12 0.167 65 1 0 0.941 0.0303 0.999 0.887 IV 13 0.162 71 1 0 0.986 0.0142 1 0.959 unkn 14 0.167 70 2 0 0.958 0.0249 1 0.912 unkn 15 0.17 68 1 0 0.944 0.0290 0.999 0.892 unkn
arrange_ggsurvplots(glist, print = TRUE, ncol = 2, nrow = 1)

RгябдЩњДцЗжЮіЪ§ОнЗжЮіПЩЪгЛЏАИР§ЃЈЯТЃЉЃК/article/1493710
