ШЋЮФСДНгЃКhttp://tecdat.cn/?p=30131
зюНќЮвУЧБЛПЭЛЇвЊЧѓзЋаДЙигкЩЯКЃПеЦјжЪСПжИЪ§ЕФбаОПБЈИцЁЃБОЮФЯђДѓМвНщЩмRгябдЖдЩЯКЃPM2.5ЕШПеЦјжЪСПЪ§ОнЃЈВщПДЮФФЉСЫНтЪ§ОнУтЗбЛёШЁЗНЪНЃЉМфЕФЯрЙиЗжЮіКЭдЄВтЗжЮіЃЌжївЊФкШнАќРЈЦфЪЙгУЪЕР§ЃЌОпгавЛЖЈЕФВЮПММлжЕЃЌашвЊЕФХѓгбПЩвдВЮПМвЛЯТЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
ЯрЙиЗжЮіЃЈcorrelation analysisЃЉЪЧбаОПЯжЯѓжЎМфЪЧЗёДцдкФГжжвРДцЙиЯЕЃЌВЂЖдОпЬхгавРДцЙиЯЕЕФЯжЯѓЬНЬжЦфЯрЙиЗНЯђвдМАЯрЙиГЬЖШЃЌЪЧбаОПЫцЛњБфСПжЎМфЕФЯрЙиЙиЯЕЕФвЛжжЭГМЦЗНЗЈЁЃЗжРр:
ЁЄ ЯпадЯрЙиЗжЮіЃКбаОПСНИіБфСПМфЯпадЙиЯЕЕФГЬЖШ,гУЯрЙиЯЕЪ§rРДУшЪіЁЃГЃгУЕФШ§жжМЦЫуЗНЪНгаPearsonЯрЙиЯЕЪ§ЁЂSpearmanКЭKendallЯрЙиЯЕЪ§ЁЃ
ЁЄ ЦЋЯрЙиЗжЮіЃКЕБСНИіБфСПЭЌЪБгыЕкШ§ИіБфСПЯрЙиЪБЃЌНЋЕкШ§ИіБфСПЕФгАЯьЬоГ§ЃЌжЛЗжЮіСэЭтСНИіБфСПжЎМфЯрЙиГЬЖШЕФЙ§ГЬЁЃШчПижЦФъСфКЭЙЄзїОбщЕФгАЯьЃЌЙРМЦЙЄзЪЪеШыгыЪмНЬг§ЫЎЦНжЎМфЕФЯрЙиЙиЯЕЁЃ
дкБфСПНЯЖрЕФИДдгЧщПіЯТЃЌБфСПжЎМфЕФЦЋЯрЙиЯЕЪ§БШМђЕЅЯрЙиЯЕЪ§ИќМгЪЪКЯгкПЬЛБфСПжЎМфЕФЯрЙиадЁЃ
PM2.5ЯИПХСЃЮяжИЛЗОГПеЦјжаПеЦјЖЏСІбЇЕБСПжБОЖаЁгкЕШгк2.5ЮЂУзЕФПХСЃЮяЁЃЫќФмНЯГЄЪБМфаќИЁгкПеЦјжаЃЌЦфдкПеЦјжаКЌСПХЈЖШдНИпЃЌОЭДњБэПеЦјЮлШОдНбЯжиЁЃгыНЯДжЕФДѓЦјПХСЃЮяЯрБШЃЌPM2.5СЃОЖаЁЃЌУцЛ§ДѓЃЌЛюадЧПЃЌвзИНДјгаЖОЁЂгаКІЮяжЪЃЈР§ШчЃЌжиН№ЪєЁЂЮЂЩњЮяЕШЃЉЃЌЧвдкДѓЦјжаЕФЭЃСєЪБМфГЄЁЂЪфЫЭОрРыдЖЃЌвђЖјЖдШЫЬхНЁПЕКЭДѓЦјЛЗОГжЪСПЕФгАЯьИќДѓЁЃ
pydat2=read.csv("ЩЯКЃЪа_05.csv",header=T) pydat3=read.csv("ЩЯКЃЪа_06.csv",header=T) head(pydat) head(pydat2) attach(pydat) plot(pydat[,c(8:10)], col=жЪСПЕШМЖ)#ЛГіБфСПЯрЙиЭМ

col=жЪСПЕШМЖ)#ЛГіБфСПЯрЙиЭМ

col=жЪСПЕШМЖ)#ЛГіБфСПЯрЙиЭМ

ЩЯУцЕФЭМжаВЛЭЌбеЩЋДњБэВЛЭЌЕФПеЦјжЪСПЕиЧјЃЌДгЫљгаБфСПЕФСНСНЙиЯЕЩЂЕуЭМРДПДЃЌПЩвдПДЕНpm2.5КЭpm10ЕФЙиЯЕЭМПЩвдБШНЯКУЕФЧјЗжГіВЛЭЌПеЦјжЪСПЕФЕиЧјЁЃВЂЧвЫћУЧжЎМфДцдке§ЯрЙиЙиЯЕЁЃ
ЖдЪ§ОнНјааОлРр
plot(hc1, main="ВуДЮОлРр") border = "red")

ЖдЪ§ОнНјааВуДЮОлРрКѓЃЌИљОнЦзЯЕЭМПЩвдЗЂЯжЃЌЫљгабљБОДѓИХПЩвдЗжГЩ5ИіРрБ№ЁЃвђДЫЃЌКѓајЖдЪ§ОнНјааkmeanОлРрЁЃ
ЕуЛїБъЬтВщдФЭљЦкФкШн

RгябдПеЦјЮлШОЪ§ОнЕФЕиРэПеМфПЩЪгЛЏКЭЗжЮіЃКПХСЃЮя2.5ЃЈPM2.5ЃЉКЭПеЦјжЪСПжИЪ§ЃЈAQIЃЉ
01

02

03

04

ЬоГ§ШБЪЇжЕ
plot(pydat[,8:12], col =km$cluster, main="ОлРрНсЙћ1")

main="ОлРрНсЙћ2")

main="ОлРрНсЙћ3")

ЭЈЙ§kmeansЕФПЩЪгЛЏНсЙћРДПДЃЌkmeansЗНЗЈБШНЯКУЕФНЋЫљгабљБОЕуЧјЗжПЊРДЃЌЦфжаТЬЩЋЕФбљБОЕуИїЯюжИБъжЕНЯЕЭЃЌКьЩЋбљБОЕуИїЯюжИБъжЕНЯИпЃЌРЖЩЋКЭКкЩЋбљБОЕужївЊдкO3ЃЌNO2 ЕШжИБъЩЯгаНЯУїЯдЕФЧјБ№ЁЃЮЊСЫОпЬхБШНЯУПИіРрЕФжИБъЃЌЯТУцЖдУПИіРрЕФЪ§ОнЬиеїНјааУшЪіЁЃ
#УПИіРржаЕФПеЦјжЪСПЧщПі par(mfrow=c(3,4)) boxplot(pydat[,8]~pydat[,23])#ОлРрНсЙћКЭpm2.5ЕФЙиЯЕ

ДгЩЯУцЕФЯфЯпЭМЃЌПЩвдПДЕНУПИіРрБ№ЕФЬиеїЃЌЕквЛРрO3жЕНЯИпЃЌЕкЖўИіРрPM2.5ЕФжЕНЯИпЃЌЕкШ§ИіРрpm2.5ЃЌNOжЕНЯЕЭЃЌЕк4РрO3ЫЎЦННЯЕЭЃЌPM10жЕНЯИпЃЌЕкЮхРрЕФИїИіжИБъжЕЖМЯрЖдНЯЕЭЁЃвђДЫЕк5ИіРрБ№ПеЦјжЪСПБШНЯКУЁЃЦфЫћИїИіРрБ№ЕФЕиЧјдкВЛЭЌжИБъЩЯгаВЛЭЌЬиеїЁЃ
par(mfrow=c(2,3)) hist(as.numeric(pydat[km$cluster==1,6]))

дйПДУПИіРржаПеЦјжЪСПЫЎЦНЕФЦЕТЪЃЌПЩвдПДЕНЕквЛИіРрЕФЕиЧјПеЦјжЪСПЫЎЦНДѓЖрдкСМКУЫЎЦНЃЌЕкЖўИіРрЕиЧјЫЎЦНВуДЮВЛЦыЃЌЕк3ИіРрПеЦјжЪСПЫЎЦНдк4ОгЖрЃЌвђДЫПеЦјжЪСПНЯВюЃЌЕк4ИіРрБ№2,3ОгЖрЃЌвђДЫСМКУЃЌЕк5ИіРрДѓЖрЕиЧјМЏжадк1-3ЃЌвђДЫПеЦјжЪСПзюКУЁЃ
unique(pydat[pydat[,23]==5,4]) unique(pydat[pydat[,23]==1,4]) [1] ЪЎЮхГЇ КчПк аьЛуЩЯЪІДѓ бюЦжЫФЦЏ ЧрЦжЕэЩНКў [7] ОВАВМрВтеО ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН 12 Levels: КчПк ОВАВМрВтеО УРЙњСьЪТЙн ЦеЭг ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН ... бюЦжЫФЦЏ > unique(pydat[pydat[,23]==2,4]) [1] бюЦжЫФЦЏ ЦжЖЋаТЧјМрВтеО аьЛуЩЯЪІДѓ ОВАВМрВтеО ЧрЦжЕэЩНКў КчПк [7] ЪЎЮхГЇ ЦжЖЋДЈЩГ ЦжЖЋеХН ЦеЭг 12 Levels: КчПк ОВАВМрВтеО УРЙњСьЪТЙн ЦеЭг ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН ... бюЦжЫФЦЏ > unique(pydat[pydat[,23]==3,4]) [1] ЪЎЮхГЇ КчПк аьЛуЩЯЪІДѓ бюЦжЫФЦЏ ЧрЦжЕэЩНКў [7] ОВАВМрВтеО ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН 12 Levels: КчПк ОВАВМрВтеО УРЙњСьЪТЙн ЦеЭг ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН ... бюЦжЫФЦЏ > unique(pydat[pydat[,23]==4,4]) [1] КчПк ОВАВМрВтеО ЪЎЮхГЇ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН [7] аьЛуЩЯЪІДѓ ЧрЦжЕэЩНКў бюЦжЫФЦЏ ЦжЖЋДЈЩГ ЦеЭг 12 Levels: КчПк ОВАВМрВтеО УРЙњСьЪТЙн ЦеЭг ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН ... бюЦжЫФЦЏ > unique(pydat[pydat[,23]==5,4]) [1] ЦеЭг ОВАВМрВтеО 12 Levels: КчПк ОВАВМрВтеО УРЙњСьЪТЙн ЦеЭг ЦжЖЋДЈЩГ ЦжЖЋаТЧјМрВтеО ЦжЖЋеХН ... бюЦжЫФЦЏ
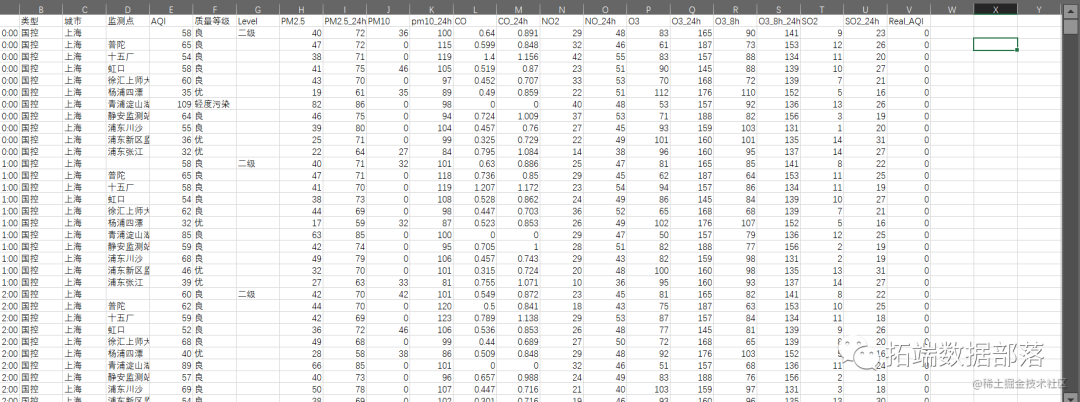
ЪБМфађСаЗжЮі
###ЖдAQiжЕНјааЪБМфађСаЗжЮі plot.ts(mynx1)
жИЪ§ЦНЛЌЗЈ
plot.ts(train)
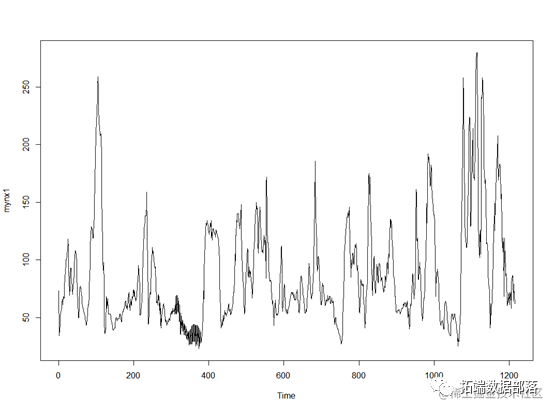
plot.ts(mynxSMA3)

plot.ts(mynxSMA10)
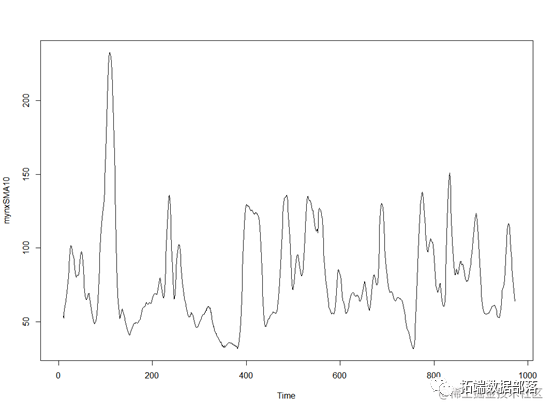
ЖдЪБМфађСаНјааЦНЛЌКѓЃЌПЩвдПДЕНЪ§ОнгаНЯЮШЖЈЕФВЈЖЏЧїЪЦЁЃ
#ЛГідЪМЪБМфађСаКЭдЄВтЕФ plot(mynxforecasts) mynxforecasts$SSE

ЕУЕНКьЩЋЕФФтКЯЪ§ОнКЭКкЩЋЕФдЪМЪ§ОнЃЌПЩвдПДЕНФЃаЭФтКЯНЯКУЁЃ
дЄВт
mynxforecasts2 plot.forecast(mynxforecasts2) lines(mynx1)#дЪМЪ§ОндЄВтЖдБШ
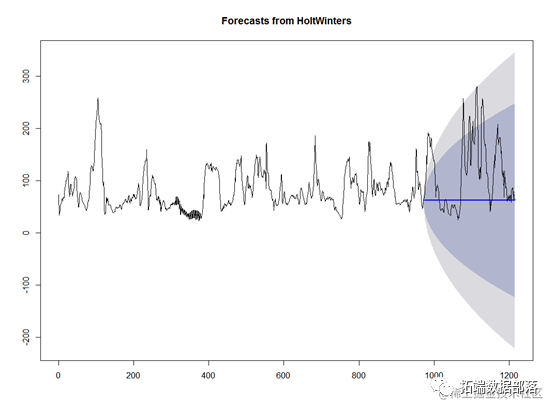
ЪЙгУИУФЃаЭЖдЪ§ОнНјааФтКЯЃЌПЩвдПДЕНВтЪдМЏЕФЪ§ОнЛљБОЩЯдйдЄВтЕФжУаХЧјМфжЎФкЁЃ
ЯђКѓдЄВт90Ьь
mynxforecasts2 plot.forecast(mynxforecasts2)

ШЛКѓЖдЮДРДЕФЪ§ОнНјаадЄВтЖюЃЌПЩвдЕУЕНдЄВтЕФЧјМфЁЃ
гЩгкКѓајдЄВтЕФЪ§жЕЧјМфНЯДѓЃЌвђДЫЮвУЧЪЙгУarimaФЃаЭНјааФтКЯЃЌВтЪдаЇЙћЁЃ
arimaФЃаЭ
plot(pre)#ЛцжЦдЄВтЪ§Он prev=train-residuals(fit3)#дЪМЪ§Он pre$mean#УПЬьЕФдЄВтОљжЕ lines(prev,col="red")#ФтКЯдЪМЪ§Он
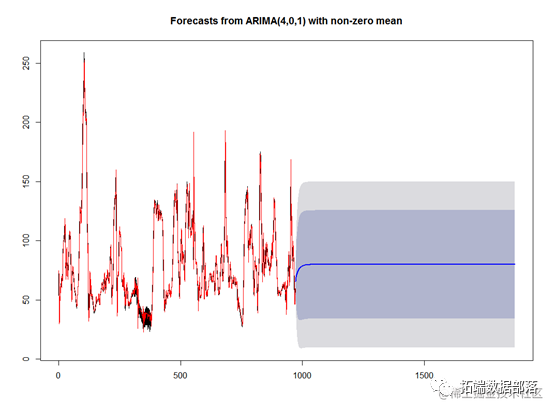
ЭЌбљЕУЕНФтКЯКЭдЄВтЕФжЕЃЌКьЩЋДњБэФтКЯЕФбљБОЕуЃЌКкЩЋДњБэдЪМЕФбљБОЕуЃЌКѓУцЕФДњБэдЄВтЕФЪ§ОнКЭжУаХЧјМфЃЌПЩвдПДЕНбљБОФтКЯЕФзДПіНЯКУЃЌдЄВтЕФЧјМфБШжИЪ§ЦНЛЌЗЈвЊОЋШЗЁЃ
