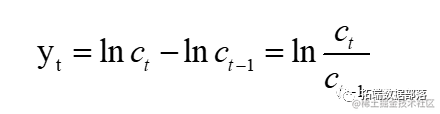ЫцзХШэМўАќЕФНјВНЃЌЪЙгУЙувхЯпадЛьКЯФЃаЭЃЈGLMMЃЉКЭЯпадЛьКЯФЃаЭЃЈLMMЃЉБфЕУдНРДдНШнвзЁЃгЩгкЮвУЧЗЂЯжздМКдкЙЄзїжадНРДдНЖрЕиЪЙгУетаЉФЃаЭЃЌЮвУЧПЊЗЂСЫвЛЬзR shinyЙЄОпРДМђЛЏКЭМгЫйгыЖдЯѓНЛЛЅЕФlme4ГЃМћШЮЮёЁЃ
shinyЕФгІгУГЬађКЭбнЪО
бнЪОДЫгІгУГЬађЙІФмЕФзюМђЕЅЗНЗЈЪЧЪЙгУShinyгІгУГЬађЃЌдкДЫДІЦєЖЏвЛаЉжИБъвдАяжњЬНЫїФЃаЭЁЃ
дкЕквЛИібЁЯюПЈЩЯЃЌИУКЏЪ§ЯдЪОгУЛЇбЁдёЕФЪ§ОнЕФдЄВтЧјМфЁЃИУКЏЪ§ЭЈЙ§ДгЙЬЖЈаЇгІКЭЫцЛњаЇгІЯюЕФФЃФтЗжВМжаГщбљВЂзщКЯетаЉФЃФтЙРМЦРДПьЫйМЦЫудЄВтЧјМфЃЌвдВњЩњУПИіЙлВьЕФдЄВтЗжВМЁЃ
дкЯТвЛИібЁЯюПЈЩЯЃЌЙЬЖЈаЇгІКЭзщМЖаЇЙћЕФЗжВМдкжУаХЧјМфЭМЩЯЯдЪОЁЃетаЉЖдгкеяЖЯЗЧГЃгагУЃЌВЂЬсЙЉСЫМьВщИїжжВЮЪ§ЕФЯрЖдДѓаЁЕФЗНЗЈЁЃ
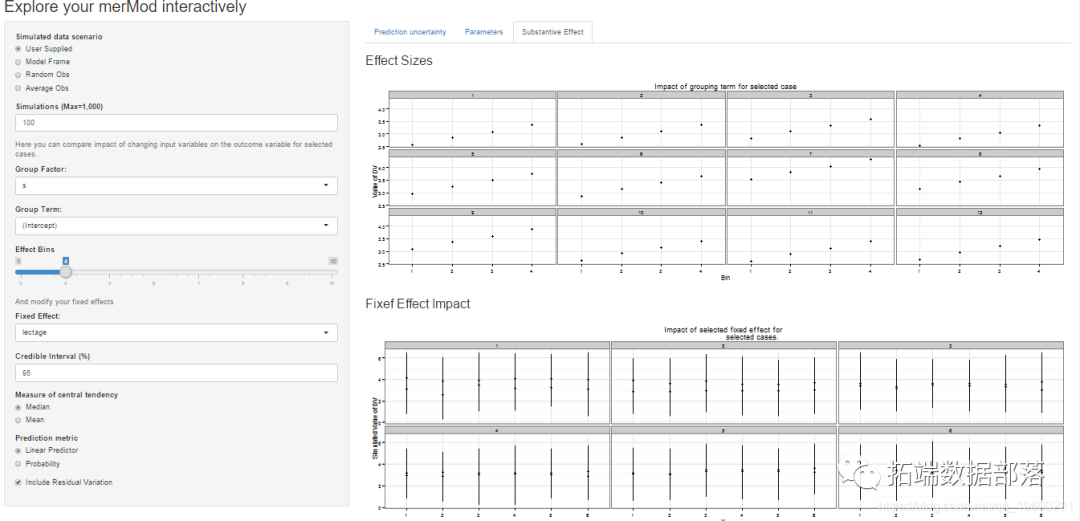
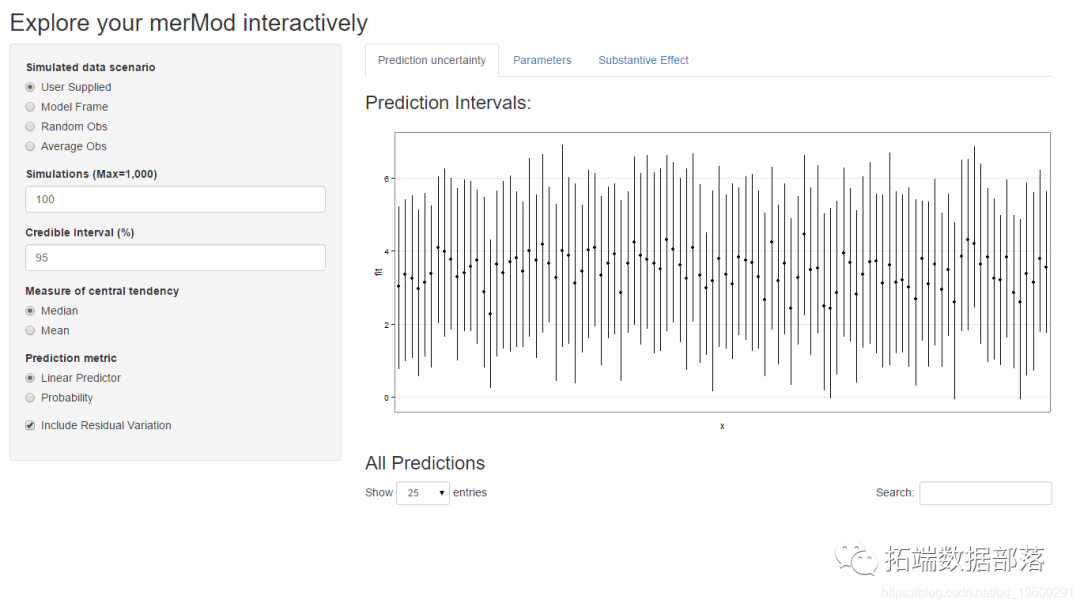
дкЕкШ§ИіБъЧЉЩЯгавЛаЉЗНБуЕФЗНЗЈЃЌЯдЪОаЇЙћЕФгАЯьЛђГЬЖШpredictIntervalЁЃЖдгкУПжжЧщПіЃЌзюЖр12ИіЃЌдкЫљбЁЪ§ОнРраЭжаЃЌгУЛЇПЩвдВщПДИќИФЙЬЖЈаЇгІЕФгАЯьЁЃетдЪаэгУЛЇБШНЯБфСПжЎМфЕФаЇЙћДѓаЁЃЌвдМАЯрЭЌЪ§ОнжЎМфЕФФЃаЭжЎМфЕФаЇЙћДѓаЁЁЃ
дЄВт
дЄВтЯёетбљЁЃ
predict(m1, newdata = Eva #> 1 2 3 4 5 6 7 8 #> 3.146336 3.165211 3.398499 3.114248 3.320686 3.252670 4.180896 3.845218 #> 9 10 #> 3.779336 3.331012</code></span>
дЄВтlmКЭglmЃК
#дЄВтЧјМф preInter(m1, newdata =Eval, n.sims = 900, stat = 'median') #> fit lwr upr #> 1 3.074148 1.112255 4.903116 #> 2 3.243587 1.271725 5.200187 #> 3 3.529055 1.409372 5.304214 #> 4 3.072788 1.079944 5.142912 #> 5 3.395598 1.268169 5.327549 #> 6 3.262092 1.333713 5.304931 #> 7 4.215371 2.136654 6.078790 #> 8 3.816399 1.860071 5.769248 #> 9 3.811090 1.697161 5.775237 #> 10 3.337685 1.417322 5.341484</code></span>
дЄВтЧјМфНЯТ§ЃЌвђЮЊЫќЪЧФЃФтМЦЫуЁЃ
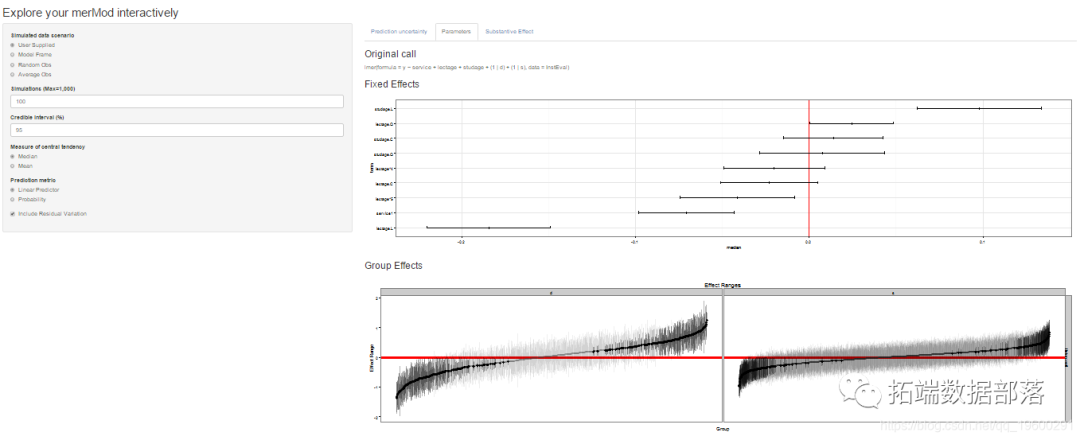
ПЩЪгЛЏ
ПЩЪгЛЏМьВщЖдЯѓЕФЙІФмЁЃзюМђЕЅЕФЪЧЕУЕНЙЬЖЈКЭЫцЛњаЇгІВЮЪ§ЕФКѓбщЗжВМЁЃ
head(Sims) #> term mean median sd #> 1 (Intercept) 3.22673524 3.22793168 0.01798444 #> 2 service1 -0.07331857 -0.07482390 0.01304097 #> 3 lectage.L -0.18419526 -0.18451731 0.01726253 #> 4 lectage.Q 0.02287717 0.02187172 0.01328641 #> 5 lectage.C -0.02282755 -0.02117014 0.01324410 #> 6 lectage^4 -0.01940499 -0.02041036 0.01196718
ЮвУЧетбљЛцжЦЃК
pltsim(sim(m1, n.sims = 100), level = 0.9, stat = 'median'

ЮвУЧЛЙПЩвдПьЫйжЦзїЫцЛњаЇгІЕФЭМЃК
head(Sims) #> groupFctr groupID term mean median sd #> 1 s 1 (Intercept) 0.15317316 0.11665654 0.3255914 #> 2 s 2 (Intercept) -0.08744824 -0.03964493 0.2940082 #> 3 s 3 (Intercept) 0.29063126 0.30065450 0.2882751 #> 4 s 4 (Intercept) 0.26176515 0.26428522 0.2972536 #> 5 s 5 (Intercept) 0.06069458 0.06518977 0.3105805 #> 6 s 6 (Intercept) 0.08055309 0.05872426 0.2182059</code></span><span style="color:#5c5c5c"><code>plotREsim(REsim(m1, n.sims = 100), stat = 'median', sd = TRUE)</code></span>

гаЪБЃЌЫцЛњаЇгІПЩФмФбвдНтЪЭ
Rank(m1, groupFctr = "d") head(ranks) #> d (Intercept) (Intercept)_var ER pctER #> 1 1866 1.2553613 0.012755634 1123.806 100 #> 2 1258 1.1674852 0.034291228 1115.766 99 #> 3 240 1.0933372 0.008761218 1115.090 99 #> 4 79 1.0998653 0.023095979 1112.315 99 #> 5 676 1.0169070 0.026562174 1101.553 98 #> 6 66 0.9568607 0.008602823 1098.049 97
аЇЙћФЃФт
НтЪЭLMMКЭGLMMФЃаЭЕФНсЙћКмРЇФбЃЌгШЦфЪЧВЛЭЌВЮЪ§ЖддЄВтНсЙћЕФЯрЖдгАЯьЁЃ
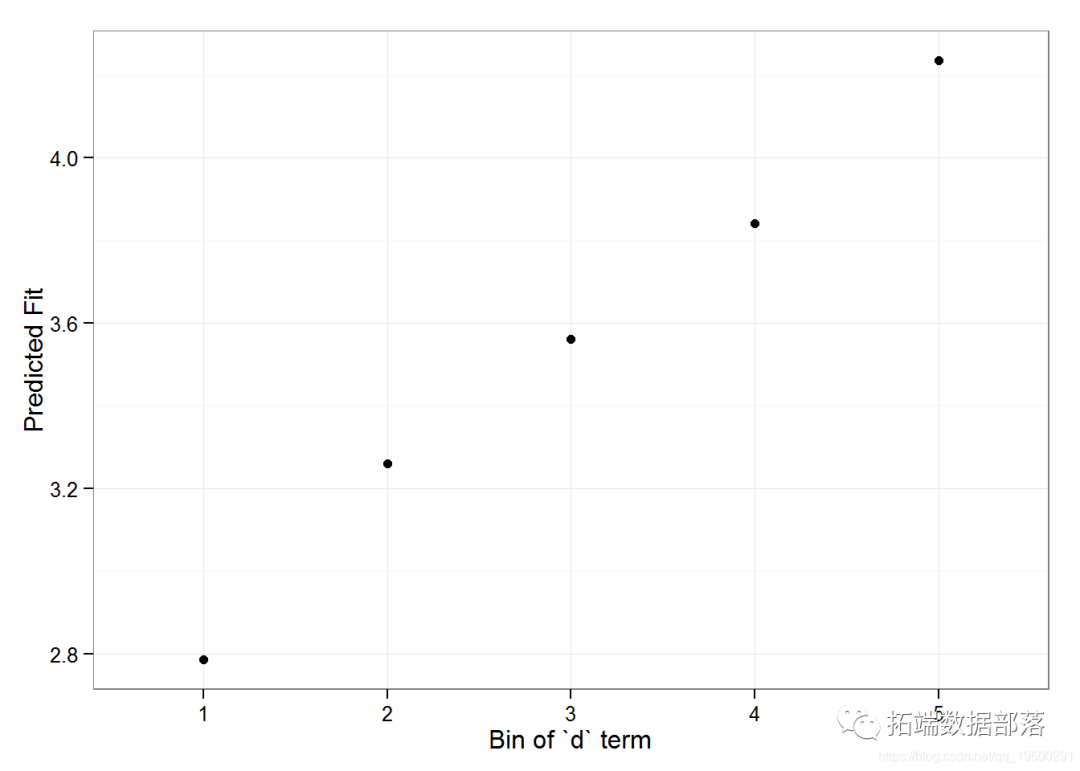
impact(m1, Eval[7, ], groupFctr = "d", breaks = 5, n.sims = 300, level = 0.9) #> case bin AvgFit AvgFitSE nobs #> 1 1 1 2.787033 2.801368e-04 193 #> 2 1 2 3.260565 5.389196e-05 240 #> 3 1 3 3.561137 5.976653e-05 254 #> 4 1 4 3.840941 6.266748e-05 265 #> 5 1 5 4.235376 1.881360e-04 176
НсЙћБэУїyhatИљОнЮвУЧЬсЙЉЕФnewdataдкзщвђзгЯЕЪ§ЕФДѓаЁЗНУцЃЌДгЕквЛИіЕНЕкЮхИіЮхЗжЮЛЪ§ЕФБфЛЏЁЃ
ggplot(impSim, aes(x = factor(bin), y = AvgFit, ymin = AvgFit - 1.96*AvgFitSE, ymax = AvgFit + 1.96*AvgFitSE)) +