дЮФСДНгЃКhttp://tecdat.cn/?p=26868
дкБОНЬГЬжаЃЌЮвУЧНЋбЇЯАИВИЧОіВпЪїКЭЫцЛњЩСжЁЃетаЉЪЧПЩгУгкЗжРрЛђЛиЙщЕФМрЖНбЇЯАЫуЗЈЁЃ
ЯТУцЕФДњТыНЋМгдиБОНЬГЬЫљашЕФАќКЭЪ§ОнМЏЁЃ
library(tidyverse) # ЕчаХПЭЛЇСїЪЇТЪЪ§Он churn <- read_rds(chuata.rds))
Ъ§Он
ЛЈЕуЪБМфЬНЫїЯТУцЕФетИіЪ§ОнМЏЃЈВщПДЮФФЉСЫНтЪ§ОнЛёШЁЗНЪНЃЉЁЃ
ДЫЪ§ОнПђжаЕФвЛааДњБэвЛМвЕчаХЙЋЫОЕФПЭЛЇЁЃУПИіПЭЛЇЖМДгИУЙЋЫОЙКТђСЫЕчЛАКЭЛЅСЊЭјЗўЮёЁЃ
ДЫЪ§ОнжаЕФвђБфСПБфСП canceled жИЪОПЭЛЇЪЧЗёжежЙСЫЫћУЧЕФЗўЮёЁЃ
ОіВпЪї
ЮЊСЫбнЪОФтКЯОіВпЪїЃЌЮвУЧНЋЪЙгУ churnЪ§ОнМЏВЂЪЙгУЫљгаПЩгУЕФдЄВтБфСПНјаадЄВтЁЃ
Ъ§ОнВ№Зж
ЮвУЧНЋЪ§ОнЗжГЩбЕСЗМЏКЭВтЪдМЏЁЃбЕСЗЪ§ОнНЋНјвЛВНЗжЮЊ 5 елНјааГЌВЮЪ§ЕїгХЁЃ
# МЧзЁвЛЖЈвЊЩшжУФуЕФЫцЛњЪ§жжзгЁЃ chuit <- iniplit(cdf) chining <- chulit %>% trang() chuest <- chuplit %>% tesg() #дкбЕСЗЪ§ОнМЏЩЯДДНЈНЛВцбщжЄЕФ ##етаЉНЋБЛгУгкЕїећФЃаЭЕФГЌВЮЪ§ chds <- vfcv(chung, v = 5)
ЬиеїЙЄГЬ
ЮвУЧНЋдкбЕСЗЪ§ОнЩЯНјаавдЯТзЊЛЛЁЃ
- ЯћГ§Ъ§жЕдЄВтБфСПЕФЦЋЖШ
- БъзМЛЏЫљгаЪ§зждЄВтБфСП
- ЮЊЫљгаУћвхдЄВтБфСПДДНЈащФтБфСП
chu\_rep <- recipe(cace\_srce ~ ., data = chutann) %>% stepYeonon(al\_nmeric(), -al\_utcoms()) %>% ste\_nomaze(all\_umic(), -al_oucoes()) %>% ste\_dumy(all\_inal(), -al_otcomes())
ШУЮвУЧМьВщвЛЯТЬиеїЙЄГЬВНжшЪЧЗёе§ШЗжДааЁЃ
ФЃаЭЙцИё
НгЯТРДЃЌЮвУЧжИЖЈОпгавдЯТГЌВЮЪ§ЕФОіВпЪїЗжРрЦїЃК
- ГЩБОИДдгЖШВЮЪ§ЃЈгжУћ Cp Лђ ІЫЃЉ
- ЪїЕФзюДѓЩюЖШ
- НкЕужаНјвЛВНВ№ЗжЫљашЕФзюаЁЪ§ОнЕуЪ§ЁЃ
ЙЄзїСїГЬ
НгЯТРДЃЌЮвУЧНЋФЃаЭзщКЯЕНвЛИіЙЄзїСїжаЃЌвдЧсЫЩЙмРэФЃаЭЙЙНЈЙ§ГЬЁЃ
treow <- workflow()
ГЌВЮЪ§ЕїгХ
ЮвУЧНЋЖдОіВпЪїГЌВЮЪ§НјааЭјИёЫбЫїЃЌВЂдкНЛВцбщжЄЦкМфИљОн ROC ЧњЯпЯТЕФУцЛ§бЁдёадФмзюМбЕФФЃаЭЁЃ
ЧыВЮМћЯТУцЕФЪОР§ЃЌЮвУЧдкЦфжаДДНЈ tree_grid ЖдЯѓЁЃ
## ДДНЈвЛИіГЌВЮЪ§жЕЕФЭјИёРДВтЪд tr_gid <- girular(cotolty(), teedeth(), mnn(), lvs = 2)
ЕїећГЌВЮЪ§ tune_grid()
ЮЊСЫДгЮвУЧЕФЕїећЭјИёжаевЕНГЌВЮЪ§ЕФзюМбзщКЯЃЌЮвУЧНЋЪЙгУИУ tune_grid() КЏЪ§ЁЃ
дкЮвУЧЕФ KNN ЪОР§жаЃЌДЫКЏЪ§НЋФЃаЭЖдЯѓЛђЙЄзїСїзїЮЊЕквЛИіВЮЪ§ЃЌНЋНЛВцбщжЄелЕўзїЮЊЕкЖўИіВЮЪ§ЃЌНЋЕїећЭјИёЪ§ОнПђзїЮЊЕкШ§ИіВЮЪ§ЁЃ
## ЕїећОіВпЪїЙЄзїСїГЬ set.seed(314) tre_tig <- trewolow %>% tue_rid(rsampes = chrnols, grid = reegid)
ВщПДЮвУЧЕФГЌВЮЪ§ЕїећЕФНсЙћЁЃ
ДгЯТУцЕФНсЙћжаЃЌЮвУЧПДЕНЖдгкЮвУЧЭјИёжаЕФУПИіГЌВЮЪ§зщКЯЁЃ
ЯТУц mean НсЙћжаЕФСаБэЪОЛёЕУЕФадФмжИБъЕФЦНОљжЕЁЃ
ЮвУЧПЩвдЪЙгУИУ select_best() ФЃаЭДгЮвУЧЕФЕїгХНсЙћжабЁдёОпгазюМбећЬхадФмЕФФЃаЭЁЃдкЯТУцЕФДњТыжаЃЌЮвУЧжИЖЈИљОн roc_auc жИБъбЁдёадФмзюМбЕФФЃаЭЁЃ
ЮвУЧПДЕНГЩБОИДдгЖШЮЊ 1-10ЁЂЪїЩюЖШЮЊ 15ЁЂзюаЁ n ЮЊ 40 ЕФФЃаЭВњЩњСЫзюМбФЃаЭЁЃ
## ИљОнroc_aucбЁдёзюМбФЃаЭ besree <- te_uin %>%
ЭъГЩЙЄзїСїГЬ
ГЌВЮЪ§ЕїећЕФзюКѓвЛВНЪЧ НЋЮвУЧЕФзюМбФЃаЭЬэМгЕНЮвУЧЕФЙЄзїСїЖдЯѓжаЁЃ
ПЩЪгЛЏНсЙћ
ЮЊСЫПЩЪгЛЏЮвУЧЕФОіВпЪїФЃаЭЃЌЮвУЧашвЊЪЙгУИУ fit() КЏЪ§ЪжЖЏбЕСЗЮвУЧЕФЙЄзїСїЖдЯѓЁЃ
ДЫВНжшЪЧПЩбЁЕФЃЌвђЮЊВЂЗЧЫљгагІгУГЬађЖМашвЊПЩЪгЛЏФЃаЭЁЃЕЋЪЧЃЌШчЙћФПБъЪЧСЫНт ФЃаЭдЄВтФГаЉжЕЕФдвђ ЃЌФЧУДНЈвщетбљзіЁЃ
ЯТвЛНкНЋеЙЪОШчКЮФтКЯФЃаЭвд здЖЏЛёЕУВтЪдМЏЕФадФмЁЃ
ФтКЯФЃаЭ
НгЯТРДЃЌЮвУЧНЋЙЄзїСїГЬгыбЕСЗЪ§ОнЯрЦЅХфЁЃетЪЧЭЈЙ§НЋЮвУЧЕФЙЄзїСїЖдЯѓДЋЕнИј fit() КЏЪ§РДЭъГЩЕФЁЃ
fit(data = chning)
ЬНЫїЮвУЧЕФбЕСЗФЃаЭБфСПЕФживЊад
вЛЕЉЮвУЧдкбЕСЗЪ§ОнЩЯбЕСЗСЫЮвУЧЕФФЃаЭЃЌЮвУЧОЭПЩвдЪЙгУИУ vip КЏЪ§баОПБфСПЕФживЊадЁЃ
teeit <- tree__it %>% pull_orfowit()
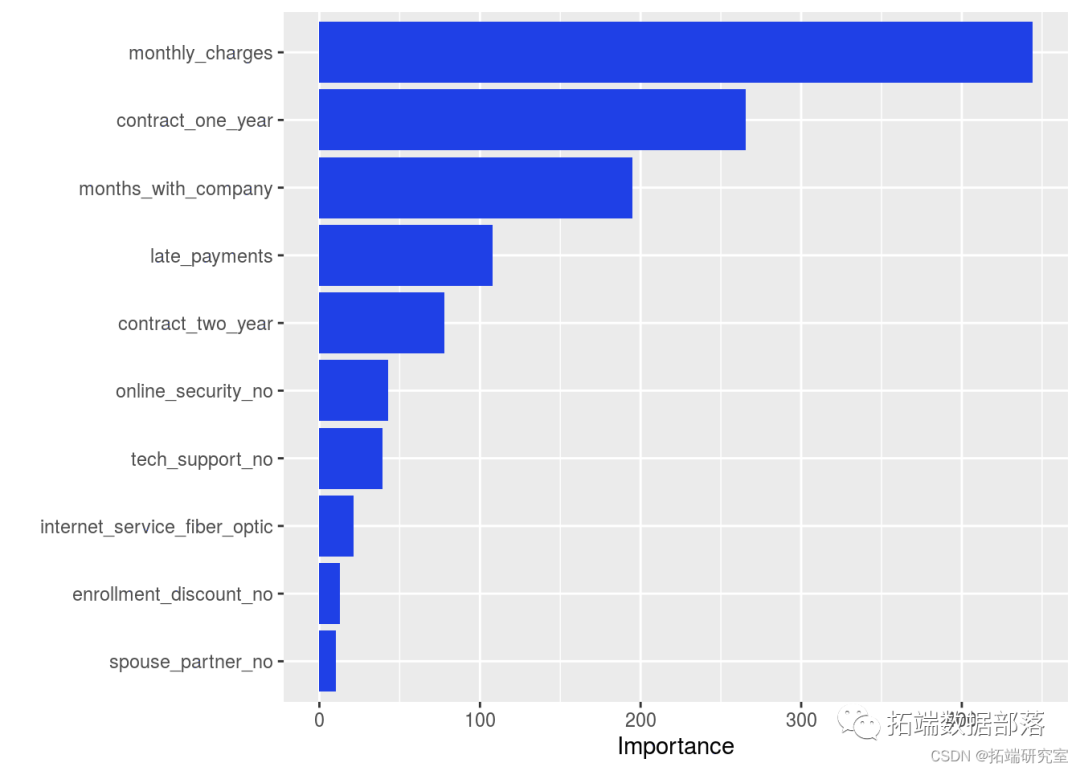
БфСПживЊад
НгЯТРДЮвУЧДЋЕн tree_fit Иј vip() КЏЪ§ЁЃ
ЮвУЧДгЯТУцЕФНсЙћжаПДЕНзюживЊЕФдЄВтвђзгЁЃ
vip(teeit)
ЕуЛїБъЬтВщдФЭљЦкФкШн

01

02

03

04

ОіВпЪїЭМ
ЮвУЧПЩвдПЩЪгЛЏбЕСЗКУЕФОіВпЪїЁЃ
етжжПЩЪгЛЏЪЧвЛжжЙЄОпЃЌгУгкДЋДяОЙ§бЕСЗЕФОіВпЪїЕФдЄВтЙцдђЁЃ
КмЖрЪБКђЃЌОіВпЪїЭМЛсКмДѓВЂЧвФбвддФЖСЁЃгазЈУХЕФШэМўАќ R гУгкЗХДѓОіВпЪїЭМЕФЧјгђЁЃ
бЕСЗКЭЦРЙР
НгЯТРДЃЌЮвУЧНЋзюжеФЃаЭЙЄзїСїГЬФтКЯЕНбЕСЗЪ§ОнВЂЦРЙРВтЪдЪ§ОнЕФадФмЁЃ
ИУ КЏЪ§НЋЪЙЮвУЧЕФЙЄзїСїГЬЪЪКЯбЕСЗЪ§ОнЃЌВЂИљОнЮвУЧЕФ chuplit ЖдЯѓЖЈвхЕФВтЪдЪ§ОнЩњГЩдЄВтЁЃ
tre\_latit <- fil\_tewklow %>% last_fit(chnpit)
ЮвУЧПЩвддкВтЪдЪ§ОнЩЯВщПДЮвУЧЕФадФмжИБъ
tre\_lft %>% collect\_metrics()
ROCЧњЯп
ЮвУЧПЩвдЛцжЦ ROC ЧњЯпРДПЩЪгЛЏЮвУЧЕїећЕФОіВпЪїЕФВтЪдМЏадФм
treatft %>% collect_predictions() %>%

ЛьЯ§Оиеѓ
ЮвУЧПДЕНЮвУЧЕФФЃаЭдкЮвУЧЕФВтЪдЪ§ОнМЏЩЯВњЩњСЫ 80 ИіМйвѕадКЭ 57 ИіМйбєадЁЃ
tre\_pcis <- tre\_s\_t %>% collect\_predictions()

ЫцЛњЩСж
дкБОНкжаЃЌЮвУЧНЋЮЊ chudf Ъ§ОнФтКЯвЛИіЫцЛњЩСжФЃаЭЁЃЫцЛњЩСжВЩгУОіВпЪїВЂдкдЄВтзМШЗадЗНУцЙЙНЈИќЧПДѓЕФФЃаЭЁЃжЇГжИУЫуЗЈЕФжївЊЛњжЦЪЧЖдбЕСЗЪ§ОнНјаажиИДВЩбљЃЈЬцЛЛЃЉвдЩњГЩвЛЯЕСаОіВпЪїФЃаЭЁЃШЛКѓЖдетаЉФЃаЭНјааЦНОљвдЛёЕУдЄВтПеМфжаИјЖЈжЕЕФЕЅИідЄВтЁЃ
ЫцЛњЩСжФЃаЭбЁдёдЄВтБфСПЕФЫцЛњзгМЏЃЌгУгкдкЪїЙЙНЈЙ§ГЬжаЗжИюдЄВтПеМфЁЃЫуЗЈЕФУПДЮЕќДњЖМЛсетбљзіЃЌЭЈГЃЪЧ 100 ЕН 2,000 ДЮЁЃ
Ъ§ОнЬиеїЙЄГЬ
ЮвУЧвбОНЋЮвУЧЕФЪ§ОнЗжГЩбЕСЗЁЂВтЪдКЭНЛВцбщжЄМЏЃЌВЂбЕСЗСЫЮвУЧЕФЬиеїЙЄГЬЃЌ chucipe. етаЉПЩвддкЮвУЧЕФЫцЛњЩСжЙЄзїСїГЬжажиИДЪЙгУЁЃ
ФЃаЭ
НгЯТРДЃЌЮвУЧжИЖЈОпгавдЯТГЌВЮЪ§ЕФЫцЛњЩСжЗжРрЦїЃК
mtryЃКДДНЈЪїФЃаЭЪБдкУПДЮВ№ЗжЪБЫцЛњГщбљЕФдЄВтБфСПЕФЪ§СПtreesЃКвЊФтКЯВЂзюжеЦНОљЕФОіВпЪїЕФЪ§СПmin_n: НкЕуНјвЛВНЗжСбЫљашЕФзюаЁЪ§ОнЕуЪ§
вЊжИЖЈОпга ЕФЫцЛњЩСжФЃаЭ ЃЌЮвУЧашвЊИУ ranorest() КЏЪ§ЁЃ
ЙЄзїСїГЬ
НгЯТРДЃЌЮвУЧНЋЮвУЧЕФФЃаЭКЭХфЗНзщКЯЕНвЛИіЙЄзїСїжаЃЌвдЧсЫЩЙмРэФЃаЭЙЙНЈЙ§ГЬЁЃ
f_orkflw <- workflow() %>%
ГЌВЮЪ§ЕїгХ
ЫцЛњЭјИёЫбЫї
ЮвУЧНЋЖдЫцЛњЩСжГЌВЮЪ§НјааЭјИёЫбЫїЃЌВЂдкНЛВцбщжЄЦкМфИљОн ROC ЧњЯпЯТЕФУцЛ§бЁдёадФмзюМбЕФФЃаЭЁЃ
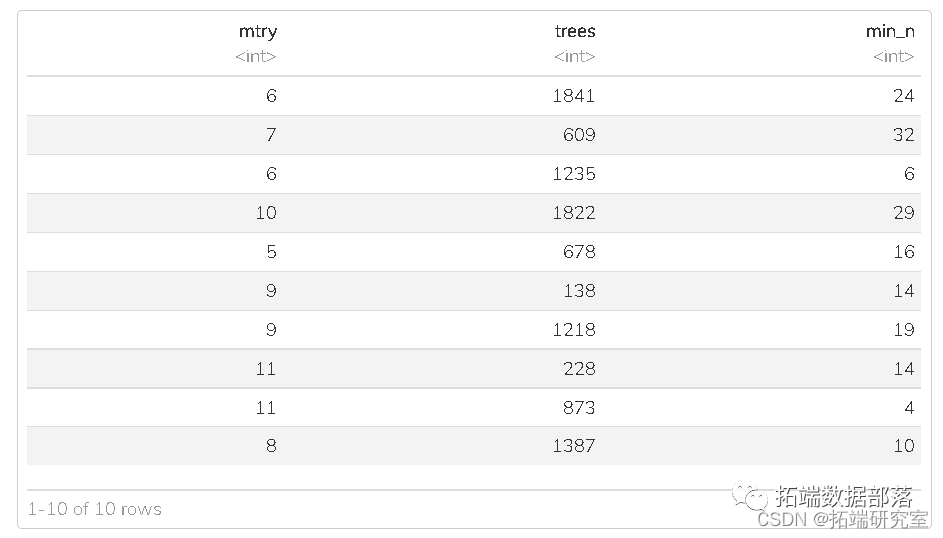
дкЩЯвЛНкжаЃЌЮвУЧдјО gridlar() ДДНЈвЛИіГЌВЮЪ§жЕЭјИёЁЃетДДНЈСЫЭЦМіФЌШЯжЕЕФГЃЙцЭјИёЁЃ
СэвЛжжНјааГЌВЮЪ§ЕїећЕФЗНЗЈЪЧДДНЈвЛИі ЫцЛњ ЕФжЕЭјИёЁЃаэЖрбаОПБэУїЃЌетжжЗНЗЈБШГЃЙцЭјИёЗНЗЈзіЕУИќКУЁЃ
дкЯТУцЕФДњТыжаЃЌЮвУЧНЋЗЖЮЇЩшжУЮЊ 4 ЕН 12ЁЃ
## ДДНЈвЛИіГЌВЮЪ§жЕЕФЭјИёРДВтЪд set.sd(314) rf\_gd <- grid\_random(mry() %>% range_set
ЕїећГЌВЮ
ЮЊСЫДгЮвУЧЕФЕїећЭјИёжаевЕНГЌВЮЪ§ЕФзюМбзщКЯЃЌЮвУЧНЋЪЙгУИУ tugid() КЏЪ§ЁЃ
## ЕїећЫцЛњЩСжЙЄзїСїГЬ set.seed(314) rftin <- rfwoflow %>% tune\_grid(resamples = cu\_olds, grid = r_id)
ВщПДЮвУЧЕФГЌВЮЪ§ЕїећЕФНсЙћЁЃ
ЮвУЧПЩвдЪЙгУФЃаЭДгЮвУЧЕФЕїгХНсЙћжабЁдёОпгазюМбећЬхадФмЕФФЃаЭЁЃдкЯТУцЕФДњТыжаЃЌЮвУЧжИЖЈИљОн rocauc жИБъбЁдёадФмзюМбЕФФЃаЭЁЃ
## ИљОнroc_aucбЁдёзюМбФЃаЭ berf <- rftunng %>% select_best
ЭъГЩЙЄзїСїГЬ
ГЌВЮЪ§ЕїећЕФзюКѓвЛВНЪЧ НЋЮвУЧЕФзюМбФЃаЭЬэМгЕНЮвУЧЕФЙЄзїСїЖдЯѓжаЁЃ
fina_rkflow <- rfow %>% finaflow(betrf)
БфСПживЊад
ЮЊСЫПЩЪгЛЏЫцЛњЩСжФЃаЭЕФПЩБфживЊадЗжЪ§ЁЃ
ФтКЯФЃаЭ
НгЯТРДЃЌЮвУЧНЋЙЄзїСїГЬгыбЕСЗЪ§ОнЯрЦЅХфЁЃетЪЧЭЈЙ§НЋЮвУЧЕФЙЄзїСїЖдЯѓДЋЕнИј fit() КЏЪ§РДЭъГЩЕФЁЃ
rf_it <- fnalrfrlow %>% fit(data = crnranng)
вЛЕЉЮвУЧдкбЕСЗЪ§ОнЩЯбЕСЗСЫЮвУЧЕФФЃаЭЃЌЮвУЧОЭПЩвдбаОПБфСПЕФживЊадЁЃ
ЕквЛВНЪЧДгЮвУЧЕФЙЄзїСїФтКЯжаЬсШЁбЕСЗКУЕФФЃаЭЁЃ
rf <- ft %>% pll\_orfow\_fit()
БфСПживЊад
ДгЮвУЧЕФФЃаЭЗЕЛивЛИі ggplot ОпгаПЩБфживЊадЗжЪ§ЕФЖдЯѓЁЃживЊадЗжЪ§ЛљгкЭЈЙ§ГЌВЮЪ§ЫцЛњбЁдёЕФОпгазюДѓдЄВтФмСІЕФдЄВтБфСПЁЃ

бЕСЗКЭЦРЙР
НгЯТРДЃЌЮвУЧНЋзюжеФЃаЭЙЄзїСїГЬФтКЯЕНбЕСЗЪ§ОнВЂЦРЙРВтЪдЪ§ОнЕФадФмЁЃ
ЪЙЮвУЧЕФЙЄзїСїГЬФтКЯбЕСЗЪ§ОнЃЌВЂИљОнВтЪдЪ§ОнЩњГЩдЄВтЁЃ
ЮвУЧПЩвддкВтЪдЪ§ОнЩЯВщПДЮвУЧЕФадФмжИБъ
rf\_tfit %>% cole\_trcs()
ROCЧњЯп
ЮвУЧПЩвдЛцжЦ ROC ЧњЯпРДПЩЪгЛЏЫцЛњЩСжФЃаЭЕФВтЪдМЏадФмЁЃ
rflafit %>% collepedions() %>% roc\_ve(trth = cncele\_srice, estimate = .rd_es) %>% autplot()

ЛьЯ§Оиеѓ
ЮвУЧПДЕНЮвУЧЕФФЃаЭдкЮвУЧЕФВтЪдЪ§ОнМЏЩЯВњЩњСЫ 61 ИіМйвѕадКЭ 48 ИіМйбєадЃЌгХгкЮвУЧЕФОіВпЪїФЃаЭЁЃ
conf\_mat(predis, truth = cncervice, estimate = .prd\_las)

