rгябджаЖдLASSOЛиЙщЃЌRidgeСыЛиЙщКЭЕЏадЭјТчElastic NetФЃаЭЪЕЯжЃЈЩЯЃЉЃК/article/1493896
ЯЕЪ§ЩЯЯТЯо
МйЩшЮвУЧвЊФтКЯЮвУЧЕФФЃаЭЃЌЕЋНЋЯЕЪ§ЯожЦЮЊДѓгк-0.7ЧваЁгк0.5ЁЃетПЩвдЭЈЙ§upper.limits КЭ lower.limits ВЮЪ§ЪЕЯж ЃК

ЭЈГЃЃЌЮвУЧЯЃЭћЯЕЪ§ЮЊе§ЃЌвђДЫЮвУЧжЛФмlower.limit НЋЦфЩшжУ ЮЊ0ЁЃ
ГЭЗЃвђЫи
ДЫВЮЪ§дЪаэгУЛЇНЋЕЅЖРЕФГЭЗЃвђзггІгУгкУПИіЯЕЪ§ЁЃУПИіВЮЪ§ЕФФЌШЯжЕЮЊ1ЃЌЕЋПЩвджИЖЈЦфЫћжЕЁЃЬиБ№ЪЧЃЌШЮКЮpenalty.factor ЕШгкСуЕФБфСП ЖМВЛЛсЪмЕНГЭЗЃ

дкаэЖрЧщПіЯТЃЌФГаЉБфСППЩФмЪЧживЊЃЌЮвУЧЯЃЭћвЛжББЃСєЫќУЧЃЌетПЩвдЭЈЙ§НЋЯргІЕФГЭЗЃвђзгЩшжУЮЊ0РДЪЕЯжЃК

ЮвУЧДгБъЧЉжаПДЕНГЭЗЃвђзгЮЊ0ЕФШ§ИіБфСПЪМжеБЃСєдкФЃаЭжаЃЌЖјЦфЫћБфСПзёбЕфаЭЕФе§дђЛЏТЗОЖВЂзюжеЫѕаЁЮЊ0ЁЃ
здЖЈвхЭМ
гаЪБЃЌгШЦфЪЧдкБфСПЪ§СПКмЩйЕФЧщПіЯТЃЌЮвУЧЯыдкЭМЩЯЬэМгБфСПБъЧЉЁЃ
ЮвУЧЪзЯШЩњГЩДјга10ИіБфСПЕФвЛаЉЪ§ОнЃЌШЛКѓЃЌЮвУЧФтКЯglmnetФЃаЭЃЌВЂЛцжЦБъзМЭМЁЃ

ЮвУЧЯЃЭћгУБфСПУћБъМЧЧњЯпЁЃдкТЗОЖЕФФЉЮВЗХжУЯЕЪ§ЕФЮЛжУЁЃ

ЖрдЊе§ЬЌ
ЪЙгУfamily = "mgaussian" option ЛёЕУЖрдЊе§ЬЌЗжВМglmnetЁЃ
ЯдШЛЃЌЙЫУћЫМвхЃЌyВЛЪЧЯђСПЃЌЖјЪЧОиеѓЁЃНсЙћЃЌУПИіІЫжЕЕФЯЕЪ§вВЪЧвЛИіОиеѓЁЃ
дкетРяЃЌЮвУЧНтОівдЯТЮЪЬтЃК

етРяЃЌІТjЪЧpЁСKЯЕЪ§ОиеѓІТЕФЕкjааЃЌЖдгкЕЅИідЄВтБфСПxjЃЌЮвУЧгУУПИіЯЕЪ§KЯђСПІТjЕФзщЬзЫїЗЃЗжДњЬцУПИіЕЅвЛЯЕЪ§ЕФОјЖдЗЃЗжЁЃ
ЮвУЧЪЙгУдЄЯШЩњГЩЕФвЛзщЪ§ОнНјааЫЕУїЁЃ
ЮвУЧФтКЯЪ§ОнЃЌВЂЗЕЛиЖдЯѓЁА mfitЁБЁЃ
mfit = glmnet(x, y, family = "mgaussian")
ШчЙћЮЊ standardize.response = TRUEЃЌдђНЋвђБфСПБъзМЛЏЁЃ
ЮЊСЫПЩЪгЛЏЯЕЪ§ЃЌЮвУЧЪЙгУ plot КЏЪ§ЁЃ

зЂвтЮвУЧЩшжУСЫ type.coef = "2norm"ЁЃдкДЫЩшжУЯТЃЌУПИіБфСПЛцжЦвЛЬѕЧњЯпЃЌЦфжЕЕШгк?2ЗЖЪ§ЁЃФЌШЯЩшжУЮЊ type.coef = "coef"ЃЌЦфжаЮЊУПИівђБфСПДДНЈвЛИіЯЕЪ§ЭМЁЃ
ЭЈЙ§ЪЙгУИУКЏЪ§coef ЃЌЮвУЧПЩвдЬсШЁвЊЧѓЕФІЫжЕЕФЯЕЪ§ЃЌ ВЂЭЈЙ§НјаадЄВт ЁЃ
## , , 1 ## ## y1 y2 y3 y4 ## \[1,\] -4.7106 -1.1635 0.6028 3.741 ## \[2,\] 4.1302 -3.0508 -1.2123 4.970 ## \[3,\] 3.1595 -0.5760 0.2608 2.054 ## \[4,\] 0.6459 2.1206 -0.2252 3.146 ## \[5,\] -1.1792 0.1056 -7.3353 3.248 ## ## , , 2 ## ## y1 y2 y3 y4 ## \[1,\] -4.6415 -1.2290 0.6118 3.780 ## \[2,\] 4.4713 -3.2530 -1.2573 5.266 ## \[3,\] 3.4735 -0.6929 0.4684 2.056 ## \[4,\] 0.7353 2.2965 -0.2190 2.989 ## \[5,\] -1.2760 0.2893 -7.8259 3.205
дЄВтНсЙћБЃДцдкШ§ЮЌЪ§зщжаЃЌЦфжаЧАСНИіЮЌЪЧУПИівђБфСПЕФдЄВтОиеѓЃЌЕкШ§ИіЮЌБэЪОвђБфСПЁЃ
ЮвУЧЛЙПЩвдНјааkелНЛВцбщжЄЁЃ
ЮвУЧЛцжЦНсЙћ cv.glmnet ЖдЯѓЁА cvmfitЁБЁЃ

ЯдЪОбЁЖЈЕФІЫзюМбжЕ
cvmfit$lambda.min
## \[1\] 0.04732
cvmfit$lambda.1se
## \[1\] 0.1317
ТпМЛиЙщ
ЕБвђБфСПЪЧЗжРрЕФЪБЃЌТпМЛиЙщЪЧСэвЛИіЙуЗКЪЙгУЕФФЃаЭЁЃШчЙћгаСНИіПЩФмЕФНсЙћЃЌдђЪЙгУЖўЯюЪНЗжВМЃЌЗёдђЪЙгУЖрЯюЪНЁЃ
ЖўЯюЪНФЃаЭ
ЖдгкЖўЯюЪНФЃаЭЃЌМйЩшвђБфСПЕФШЁжЕЮЊG = {1,2} ЁЃБэЪОyi = IЃЈgi = 1ЃЉЁЃЮвУЧНЈФЃ
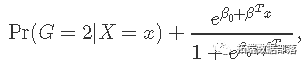
ПЩвдгУвдЯТаЮЪНаД
ГЭЗЃТпМЛиЙщЕФФПБъКЏЪ§ЪЙгУИКЖўЯюЪНЖдЪ§ЫЦШЛ

ЮвУЧЕФЫуЗЈЪЙгУЖдЪ§ЫЦШЛЕФЖўДЮБЦНќЃЌШЛКѓЖдЫљЕУЕФГЭЗЃМгШЈзюаЁЖўГЫЮЪЬтНјааЯТНЕЁЃетаЉЙЙГЩСЫФкВПКЭЭтВПбЛЗЁЃ
ГігкЫЕУїФПЕФЃЌЮвУЧ ДгЪ§ОнЮФМўМгдидЄЩњГЩЕФЪфШыОиеѓ x КЭвђБфСП yЁЃ
ЖдгкЖўЯюЪНТпМЛиЙщЃЌвђБфСПyПЩвдЪЧСНИіМЖБ№ЕФвђзгЃЌвВПЩвдЪЧМЦЪ§ЛђБШР§ЕФСНСаОиеѓЁЃ
glmnet ЖўЯюЪНЛиЙщЕФЦфЫћПЩбЁВЮЪ§гые§ЬЌЗжВМЕФВЮЪ§ МИКѕЯрЭЌЁЃВЛвЊЭќМЧНЋfamily бЁЯюЩшжУ ЮЊЁА binomialЁБЁЃ
fit = glmnet(x, y, family = "binomial")
ЯёвдЧАвЛбљЃЌЮвУЧПЩвдЪфГіКЭЛцжЦФтКЯЕФЖдЯѓЃЌЬсШЁЬиЖЈІЫДІЕФЯЕЪ§ЃЌВЂНјаадЄВтЁЃ
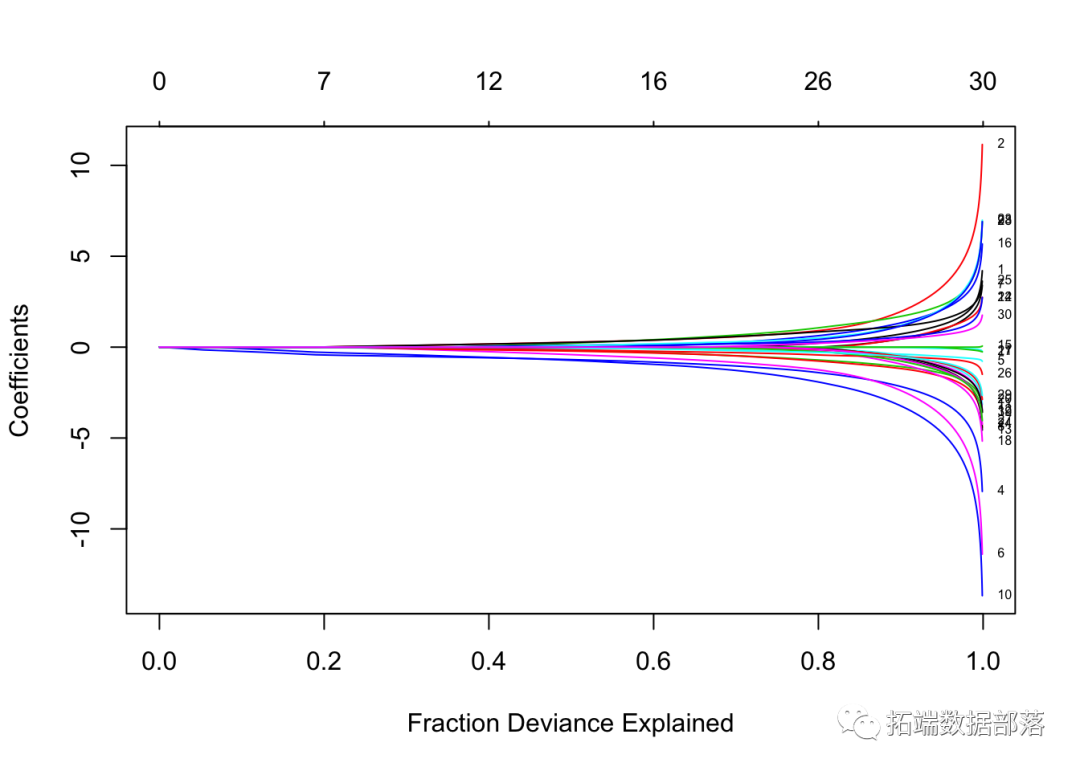
ТпМЛиЙщТдгаВЛЭЌЃЌжївЊЬхЯждкбЁдёЩЯ typeЁЃЁАСДНгЁБКЭЁАвђБфСПЁБВЛЕШМлЃЌЁАРрЁБНіПЩгУгкТпМЛиЙщЁЃзмжЎЃЌ*ЁАСДНгЁБИјГіСЫЯпаддЄВтБфСП
- ЁАвђБфСПЁБИјГіКЯЪЪЕФИХТЪ
- ЁАРрБ№ЁБВњЩњЖдгІгкзюДѓИХТЪЕФРрБ№БъЧЉЁЃ
- ЁАЯЕЪ§ЁБМЦЫужЕЮЊЕФЯЕЪ§
s
дкЯТУцЕФЪОР§жаЃЌЮвУЧдкІЫ=0.05,0.01ЕФЧщПіЯТЖдРрБ№БъЧЉНјааСЫдЄВтЁЃ
## 1 2 ## \[1,\] "0" "0" ## \[2,\] "1" "1" ## \[3,\] "1" "1" ## \[4,\] "0" "0" ## \[5,\] "1" "1"
ЖдгкТпМЛиЙщЃЌtype.measureЃК
- ЁАЦЋВюЁБЪЙгУЪЕМЪЦЋВюЁЃ
- ЁА maeЁБЪЙгУЦНОљОјЖдЮѓВюЁЃ
- ЁАclassЁБИјГіДэЮѓЗжРрДэЮѓЁЃ
- ЁА aucЁБЃЈНіЪЪгУгкСНРрТпМЛиЙщЃЉИјГіСЫROCЧњЯпЯТЕФУцЛ§ЁЃ
Р§ШчЃЌ
ЫќЪЙгУЗжРрЮѓВюзїЮЊ10БЖНЛВцбщжЄЕФБъзМЁЃ
ЮвУЧЛцжЦЖдЯѓВЂЯдЪОІЫЕФзюМбжЕЁЃ
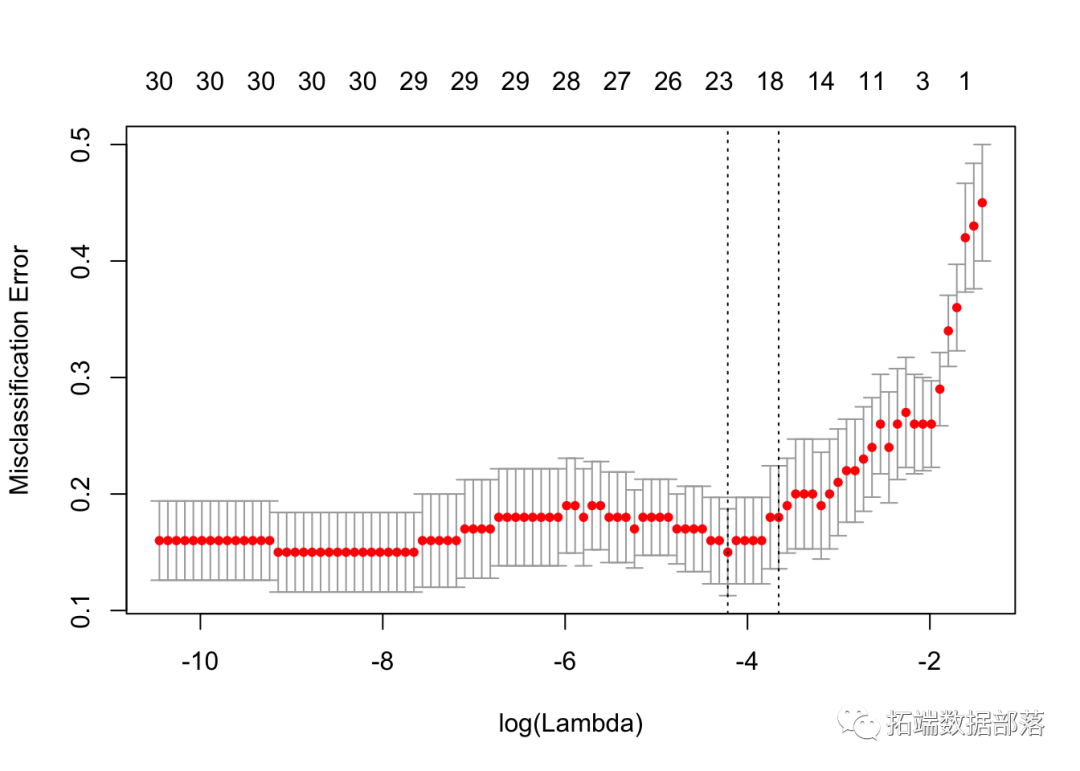
cvfit$lambda.min
## \[1\] 0.01476
cvfit$lambda.1se
## \[1\] 0.02579
coef ВЂЧв predict РрЫЦгке§ЬЌЗжВМАИР§ЃЌвђДЫЮвУЧЪЁТдСЫЯИНкЁЃЮвУЧЭЈЙ§вЛаЉР§згНјааЛиЙЫЁЃ
## 31 x 1 sparse Matrix of class "dgCMatrix" ## 1 ## (Intercept) 0.24371 ## V1 0.06897 ## V2 0.66252 ## V3 -0.54275 ## V4 -1.13693 ## V5 -0.19143 ## V6 -0.95852 ## V7 . ## V8 -0.56529 ## V9 0.77454 ## V10 -1.45079 ## V11 -0.04363 ## V12 -0.06894 ## V13 . ## V14 . ## V15 . ## V16 0.36685 ## V17 . ## V18 -0.04014 ## V19 . ## V20 . ## V21 . ## V22 0.20882 ## V23 0.34014 ## V24 . ## V25 0.66310 ## V26 -0.33696 ## V27 -0.10570 ## V28 0.24318 ## V29 -0.22445 ## V30 0.11091
ШчЧАЫљЪіЃЌДЫДІЗЕЛиЕФНсЙћНіеыЖдвђзгвђБфСПЕФЕкЖўРрЁЃ
## 1 ## \[1,\] "0" ## \[2,\] "1" ## \[3,\] "1" ## \[4,\] "0" ## \[5,\] "1" ## \[6,\] "0" ## \[7,\] "0" ## \[8,\] "0" ## \[9,\] "1" ## \[10,\] "1"
ЖрЯюЪНФЃаЭ
ЖдгкЖрЯюЪНФЃаЭЃЌМйЩшвђБфСПБфСПЕФKМЖБ№ЮЊG = {1,2ЃЌЁЃЌK}ЁЃдкетРяЮвУЧНЈФЃ

ЩшYЮЊNЁСKжИБъвђБфСПОиеѓЃЌдЊЫиyi?= IЃЈgi =?ЃЉЁЃШЛКѓЕЏадЭјГЭЗЃЕФИКЖдЪ§ЫЦШЛКЏЪ§БфЮЊ

ІТЪЧЯЕЪ§ЕФpЁСKОиеѓЁЃІТkжИЕкkСаЃЈЖдгкНсЙћРрБ№kЃЉЃЌІТjжИЕкjааЃЈБфСПjЕФKИіЯЕЪ§ЕФЯђСПЃЉЁЃзюКѓвЛИіГЭЗЃЯюЪЧ||ІТj|| q ЃЌЮвУЧЖдqгаСНИібЁдёЃКqЁЪ{1,2}ЁЃЕБq = 1ЪБЃЌетЪЧУПИіВЮЪ§ЕФЬзЫїГЭЗЃЁЃЕБq = 2ЪБЃЌетЪЧЖдЬиЖЈБфСПЕФЫљгаKИіЯЕЪ§ЕФЗжзщЬзЫїГЭЗЃЃЌетЪЙЫќУЧдквЛЦ№ШЋЮЊСуЛђЗЧСуЁЃ
ЖдгкЖрЯюЪНЧщПіЃЌгУЗЈРрЫЦгкТпМЛиЙщЃЌЮвУЧМгдивЛзщЩњГЩЕФЪ§ОнЁЃ
glmnet Г§ЩйЪ§ЧщПіЭтЃЌЖрЯюЪНТпМЛиЙщжаЕФПЩбЁВЮЪ§ гыЖўЯюЪНЛиЙщЛљБОЯрЫЦЁЃ
ЖрЯюЪНЛиЙщЕФвЛИіЬиЪтбЁЯюЪЧ type.multinomialЃЌШчЙћдЪаэЃЌдђдЪаэЪЙгУЗжзщЕФЬзЫїЗЃЗж type.multinomial = "grouped"ЁЃетНЋШЗБЃБфСПЕФЖрЯюЪНЯЕЪ§ШЋВПвЛЦ№ЪфШыЛђЪфГіЃЌОЭЯёЖрдЊвђБфСПвЛбљЁЃ
ЮвУЧЛцжЦНсЙћЁЃ

ЮвУЧЛЙПЩвдНјааНЛВцбщжЄВЂЛцжЦЗЕЛиЕФЖдЯѓЁЃ

дЄВтзюМббЁдёЕФІЫЃК
## 1 ## \[1,\] "3" ## \[2,\] "2" ## \[3,\] "2" ## \[4,\] "1" ## \[5,\] "1" ## \[6,\] "3" ## \[7,\] "3" ## \[8,\] "1" ## \[9,\] "1" ## \[10,\] "2"
ВДЫЩФЃаЭ
PoissonЛиЙщгУгкдкМйЩшPoissonЮѓВюЕФЧщПіЯТЖдМЦЪ§Ъ§ОнНјааНЈФЃЃЌЛђепдкОљжЕКЭЗНВюГЩБШР§ЕФЧщПіЯТЪЙгУЗЧИКЪ§ОнНјааНЈФЃЁЃВДЫЩвВЪЧжИЪ§ЗжВМзхЕФГЩдБЁЃЮвУЧЭЈГЃвдЖдЪ§НЈФЃЃК  ЁЃ
ЁЃ
ИјЖЈЙлВтжЕ  ЕФЖдЪ§ЫЦШЛ
ЕФЖдЪ§ЫЦШЛ
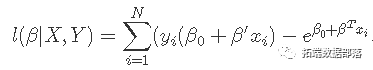
КЭвдЧАвЛбљЃЌЮвУЧгХЛЏСЫГЭЗЃЖдЪ§ЃК

GlmnetЪЙгУЭтВПХЃЖйбЛЗКЭФкВПМгШЈзюаЁЖўГЫбЛЗЃЈШчТпМЛиЙщЃЉРДгХЛЏДЫБъзМЁЃ
ЪзЯШЃЌЮвУЧМгдивЛзщВДЫЩЪ§ОнЁЃ
дйДЮЃЌЛцжЦЯЕЪ§ЁЃ

ЯёвдЧАвЛбљЃЌЮвУЧПЩвд ЗжБ№ЪЙгУcoef КЭ ЬсШЁЯЕЪ§ВЂдкЬиЖЈЕФІЫДІНјаадЄВт predictЁЃ
Р§ШчЃЌЮвУЧПЩвд
## 21 x 1 sparse Matrix of class "dgCMatrix" ## 1 ## (Intercept) 0.61123 ## V1 0.45820 ## V2 -0.77061 ## V3 1.34015 ## V4 0.04350 ## V5 -0.20326 ## V6 . ## V7 . ## V8 . ## V9 . ## V10 . ## V11 . ## V12 0.01816 ## V13 . ## V14 . ## V15 . ## V16 . ## V17 . ## V18 . ## V19 . ## V20 .
## 1 2 ## \[1,\] 2.4944 4.4263 ## \[2,\] 10.3513 11.0586 ## \[3,\] 0.1180 0.1782 ## \[4,\] 0.9713 1.6829 ## \[5,\] 1.1133 1.9935
ЮвУЧЛЙПЩвдЪЙгУНЛВцбщжЄРДевЕНзюМбЕФІЫЃЌДгЖјНјааЭЦЖЯЁЃ
бЁЯюМИКѕгые§ЬЌзхЯрЭЌЃЌВЛЭЌжЎДІдкгк type.measureЃЌЁА mseЁБДњБэОљЗНЮѓВюЃЌЁА maeЁБДњБэОљжЕОјЖдЮѓВюЁЃ
ЮвУЧПЩвдЛцжЦ cv.glmnet ЖдЯѓЁЃ

ЮвУЧЛЙПЩвдЯдЪОзюМбЕФІЫКЭЯргІЕФЯЕЪ§ЁЃ
## 21 x 2 sparse Matrix of class "dgCMatrix" ## 1 2 ## (Intercept) 0.031263 0.18570 ## V1 0.619053 0.57537 ## V2 -0.984550 -0.93212 ## V3 1.525234 1.47057 ## V4 0.231591 0.19692 ## V5 -0.336659 -0.30469 ## V6 0.001026 . ## V7 -0.012830 . ## V8 . . ## V9 . . ## V10 0.015983 . ## V11 . . ## V12 0.030867 0.02585 ## V13 -0.027971 . ## V14 0.032750 . ## V15 -0.005933 . ## V16 0.017506 . ## V17 . . ## V18 0.004026 . ## V19 -0.033579 . ## V20 0.012049 0.00993
CoxФЃаЭ
CoxБШР§ЗчЯеФЃаЭЭЈГЃгУгкбаОПдЄВтБфСПгыЩњДцЪБМфжЎМфЕФЙиЯЕЁЃ
CoxБШР§ЗчЯеЛиЙщФЃаЭЃЌЫќВЛЪЧжБНгПМВь 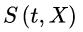 гыXЕФЙиЯЕЃЌЖјЪЧгУ
гыXЕФЙиЯЕЃЌЖјЪЧгУ  зїЮЊвђБфСПЃЌФЃаЭЕФЛљБОаЮЪНЮЊЃК
зїЮЊвђБфСПЃЌФЃаЭЕФЛљБОаЮЪНЮЊЃК

ЪНжаЃЌ  ЮЊздБфСПЕФЦЋЛиЙщЯЕЪ§ЃЌЫќЪЧаыДгбљБОЪ§ОнзїГіЙРМЦЕФВЮЪ§ЃЛ
ЮЊздБфСПЕФЦЋЛиЙщЯЕЪ§ЃЌЫќЪЧаыДгбљБОЪ§ОнзїГіЙРМЦЕФВЮЪ§ЃЛ 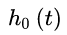 ЪЧЕБXЯђСПЮЊ0ЪБЃЌ
ЪЧЕБXЯђСПЮЊ0ЪБЃЌ 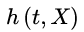 ЕФЛљзМЮЃЯеТЪЃЌЫќЪЧгаД§гкДгбљБОЪ§ОнзїГіЙРМЦЕФСПЁЃМђГЦЮЊCoxЛиЙщФЃаЭЁЃ
ЕФЛљзМЮЃЯеТЪЃЌЫќЪЧгаД§гкДгбљБОЪ§ОнзїГіЙРМЦЕФСПЁЃМђГЦЮЊCoxЛиЙщФЃаЭЁЃ
гЩгкCoxЛиЙщФЃаЭЖд  ЮДзїШЮКЮМйЖЈЃЌвђДЫCoxЛиЙщФЃаЭдкДІРэЮЪЬтЪБОпгаНЯДѓЕФСщЛюадЃЛСэвЛЗНУцЃЌдкаэЖрЧщПіЯТЃЌЮвУЧжЛашЙРМЦГіВЮЪ§
ЮДзїШЮКЮМйЖЈЃЌвђДЫCoxЛиЙщФЃаЭдкДІРэЮЪЬтЪБОпгаНЯДѓЕФСщЛюадЃЛСэвЛЗНУцЃЌдкаэЖрЧщПіЯТЃЌЮвУЧжЛашЙРМЦГіВЮЪ§  (ШчвђЫиЗжЮіЕШ)ЃЌМДЪЙдк
(ШчвђЫиЗжЮіЕШ)ЃЌМДЪЙдк  ЮДжЊЕФЧщПіЯТЃЌШдПЩЙРМЦГіВЮЪ§
ЮДжЊЕФЧщПіЯТЃЌШдПЩЙРМЦГіВЮЪ§  ЁЃетОЭЪЧЫЕЃЌCoxЛиЙщФЃаЭгЩгкКЌга
ЁЃетОЭЪЧЫЕЃЌCoxЛиЙщФЃаЭгЩгкКЌга  ЃЌвђДЫЫќВЛЪЧЭъШЋЕФВЮЪ§ФЃаЭЃЌЕЋШдПЩИљОнЙЋЪН(1)зїГіВЮЪ§
ЃЌвђДЫЫќВЛЪЧЭъШЋЕФВЮЪ§ФЃаЭЃЌЕЋШдПЩИљОнЙЋЪН(1)зїГіВЮЪ§ 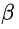 ЕФЙРМЦЃЌЙЪCoxЛиЙщФЃаЭЪєгкАыВЮЪ§ФЃаЭЁЃ
ЕФЙРМЦЃЌЙЪCoxЛиЙщФЃаЭЪєгкАыВЮЪ§ФЃаЭЁЃ
ЙЋЪНПЩвдзЊЛЏЮЊЃК 
ЮвУЧЪЙгУвЛзщдЄЯШЩњГЩЕФбљБОЪ§ОнЁЃгУЛЇПЩвдМгдиздМКЕФЪ§ОнВЂзёбРрЫЦЕФЙ§ГЬЁЃдкетжжЧщПіЯТЃЌxБиаыЪЧаБфСПжЕЕФnЁСpОиеѓ-УПааЖдгІвЛИіЛМепЃЌУПСаЖдгІвЛИіаБфСПЁЃyЪЧвЛИіnЁС2ОиеѓЁЃ
## time status ## \[1,\] 1.76878 1 ## \[2,\] 0.54528 1 ## \[3,\] 0.04486 0 ## \[4,\] 0.85032 0 ## \[5,\] 0.61488 1
Surv АќжаЕФ КЏЪ§ survival ПЩвдДДНЈетбљЕФОиеѓЁЃ
ЮвУЧМЦЫуФЌШЯЩшжУЯТЕФЧѓНтТЗОЖЁЃ
ЛцжЦЯЕЪ§ЁЃ

ЬсШЁЬиЖЈжЕІЫДІЕФЯЕЪ§ЁЃ
## 30 x 1 sparse Matrix of class "dgCMatrix" ## 1 ## V1 0.37694 ## V2 -0.09548 ## V3 -0.13596 ## V4 0.09814 ## V5 -0.11438 ## V6 -0.38899 ## V7 0.24291 ## V8 0.03648 ## V9 0.34740 ## V10 0.03865 ## V11 . ## V12 . ## V13 . ## V14 . ## V15 . ## V16 . ## V17 . ## V18 . ## V19 . ## V20 . ## V21 . ## V22 . ## V23 . ## V24 . ## V25 . ## V26 . ## V27 . ## V28 . ## V29 . ## V30 .
КЏЪ§ cv.glmnet ПЩгУгкМЦЫуCoxФЃаЭЕФkелНЛВцбщжЄЁЃ
ФтКЯКѓЃЌЮвУЧПЩвдВщПДзюМбІЫжЕКЭНЛВцбщжЄЕФЮѓВюЭМЃЌАяжњЦРЙРЮвУЧЕФФЃаЭЁЃ

ШчЧАЫљЪіЃЌЭМжаЕФзѓДЙжБЯпЯђЮвУЧЯдЪОСЫCVЮѓВюЧњЯпДяЕНзюаЁжЕЕФЮЛжУЁЃгвБпЕФДЙжБЯпЯђЮвУЧеЙЪОСЫе§дђЛЏЕФФЃаЭЃЌЦфCVЮѓВюдкзюаЁжЕЕФ1ИіБъзМЦЋВюжЎФкЁЃЮвУЧЛЙЬсШЁСЫзюгХІЫЁЃ
cvfit$lambda.min
## \[1\] 0.01594
cvfit$lambda.1se
## \[1\] 0.04869
ЮвУЧПЩвдМьВщФЃаЭжаЕФаБфСПВЂВщПДЦфЯЕЪ§ЁЃ
index.min
## \[1\] 0.491297 -0.174601 -0.218649 0.175112 -0.186673 -0.490250 0.335197 ## \[8\] 0.091587 0.450169 0.115922 0.017595 -0.018365 -0.002806 -0.001423 ## \[15\] -0.023429 0.001688 -0.008236
coef.min
## 30 x 1 sparse Matrix of class "dgCMatrix" ## 1 ## V1 0.491297 ## V2 -0.174601 ## V3 -0.218649 ## V4 0.175112 ## V5 -0.186673 ## V6 -0.490250 ## V7 0.335197 ## V8 0.091587 ## V9 0.450169 ## V10 0.115922 ## V11 . ## V12 . ## V13 0.017595 ## V14 . ## V15 . ## V16 . ## V17 -0.018365 ## V18 . ## V19 . ## V20 . ## V21 -0.002806 ## V22 -0.001423 ## V23 . ## V24 . ## V25 -0.023429 ## V26 . ## V27 0.001688 ## V28 . ## V29 . ## V30 -0.008236
ЯЁЪшОиеѓ
ЮвУЧЕФГЬађАќжЇГжЯЁЪшЕФЪфШыОиеѓЃЌИУОиеѓПЩвдИпаЇЕиДцДЂКЭВйзїДѓаЭОиеѓЃЌЕЋжЛгаЩйЪ§МИИіЗЧСуЬѕФПЁЃ
ЮвУЧМгдивЛзщдЄЯШДДНЈЕФбљБОЪ§ОнЁЃ
Мгди100 * 20ЕФЯЁЪшОиеѓКЭ yвђЯђСПЁЃ
## \[1\] "dgCMatrix" ## attr(,"package") ## \[1\] "Matrix"
ЮвУЧПЩвдЯёвдЧАвЛбљФтКЯФЃаЭЁЃ
fit = glmnet(x, y)
НјааНЛВцбщжЄВЂЛцжЦНсЙћЖдЯѓЁЃ

дЄВтаТЪфШыОиеѓ ЁЃР§ШчЃЌ
## 1 ## \[1,\] 0.3826 ## \[2,\] -0.2172 ## \[3,\] -1.6622 ## \[4,\] -0.4175 ## \[5,\] -1.3941
ВЮПМЮФЯз
Jerome Friedman, Trevor Hastie and Rob Tibshirani. (2008).
Regularization Paths for Generalized Linear Models via Coordinate Descent
