вђзгЩшМЦЯрЖдгквЛДЮвЛИівђзгЩшМЦЕФгХЪЦ
МйЩшвЛДЮжЛбаОПвЛИівђЫиЁЃР§ШчЃЌдкНЋХЈЖШБЃГждк 20% (-1) ВЂНЋДпЛЏМСБЃГждк B (+1) ЪБбаОПЮТЖШЁЃ
ЮЊСЫЪЙаЇЙћОпгаИќЦеБщЕФЯрЙиадЃЌгаБивЊЪЙаЇЙћдкЫљгаЦфЫћХЈЖШКЭДпЛЏМСЫЎЦНЩЯЖМЯрЭЌЁЃЛЛОфЛАЫЕЃЌвђЫиЃЈР§ШчЃЌЮТЖШКЭДпЛЏМСЃЉжЎМфУЛгаЯрЛЅзїгУЁЃШчЙћаЇЙћЯрЭЌЃЌдђвђзгЩшМЦИќгааЇЃЌвђЮЊаЇЙћЕФЙРМЦашвЊИќЩйЕФЙлВьРДДяЕНЯрЭЌЕФОЋЖШЁЃ
ШчЙћдкЦфЫћХЈЖШКЭДпЛЏМСЫЎЦНЯТаЇЙћВЛЭЌЃЌдђНзГЫПЩвдМьВтКЭЙРМЦЯрЛЅзїгУЁЃ
ЗЧжиИДвђзгЩшМЦжаЕФе§ЬЌЭМ
е§ЬЌЗжЮЛЪ§ЭМ
вЛзщЪ§ОнЕФе§ЬЌадПЩвдЭЈЙ§вдЯТЗНЗЈРДЦРЙРЁЃШУ  БэЪОЕФгаађжЕ
БэЪОЕФгаађжЕ  . Р§ШчЃЌr(1) ЪЧ r1,...,rN ЕФзюаЁжЕЃЌr(N) ЪЧ r1,...,rN ЕФзюДѓжЕЁЃЫљвдЃЌШчЙћЪ§ОнЪЧЃК-1, 2, -10, 20ЃЌ ФЧУД
. Р§ШчЃЌr(1) ЪЧ r1,...,rN ЕФзюаЁжЕЃЌr(N) ЪЧ r1,...,rN ЕФзюДѓжЕЁЃЫљвдЃЌШчЙћЪ§ОнЪЧЃК-1, 2, -10, 20ЃЌ ФЧУД 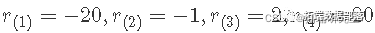 ЁЃ
ЁЃ
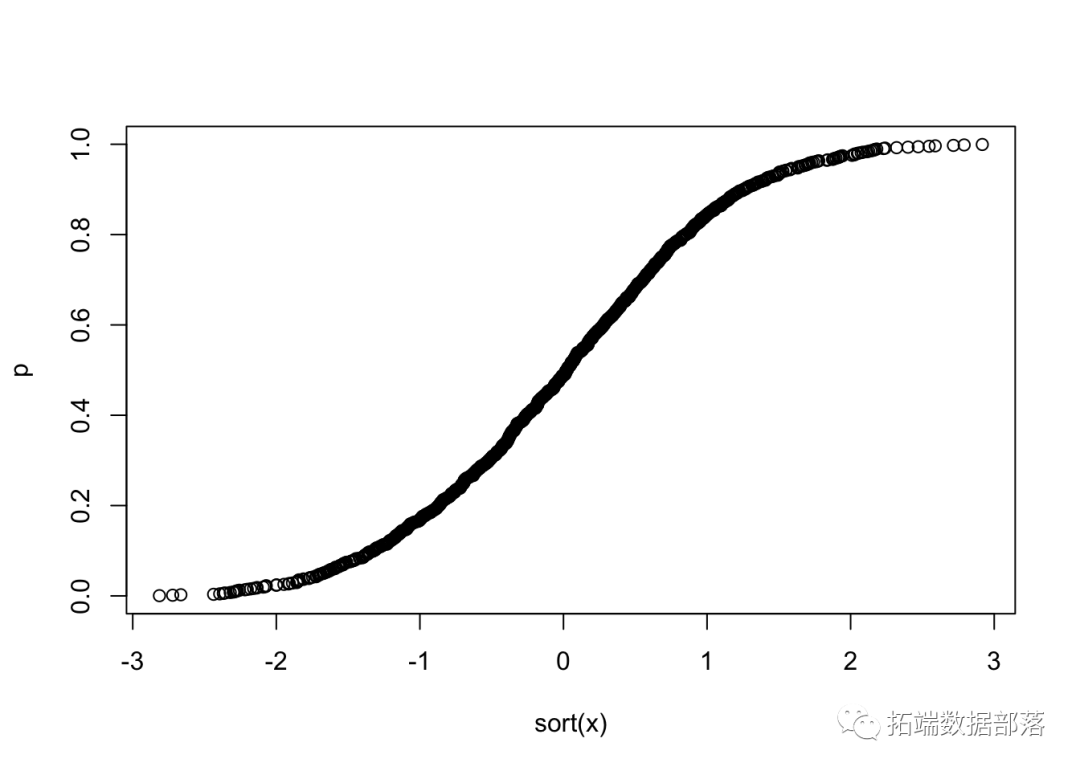
N(0,1)ЕФРлЛ§ЗжВМКЏЪ§ (CDF) Опга S аЮЁЃ
x <- seq plot(x,pnorm)
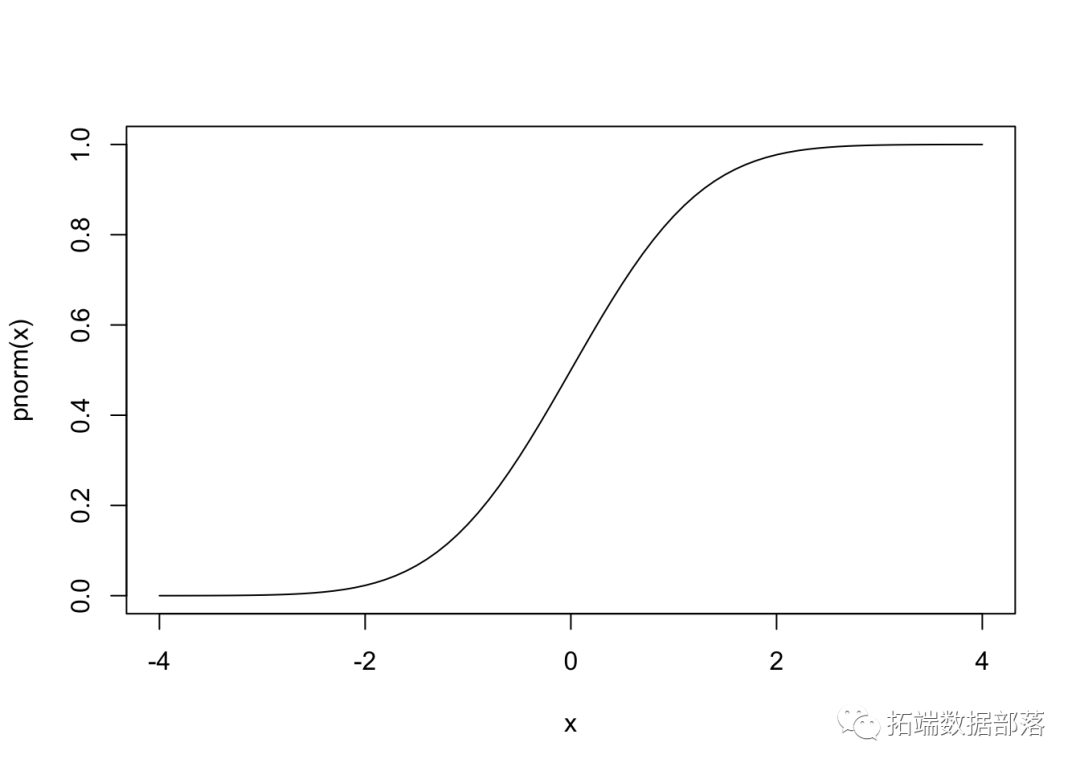
вђДЫЃЌвЛзщЪ§ОнЕФе§ЬЌадМьбщЪЧЛцжЦЪ§ОнЕФгаађжЕ r(i) гы pi=(i-0.5)/N ЕФЙиЯЕЁЃШчЙћИУЭМгые§ЬЌ CDF ОпгаЯрЭЌЕФ S аЮЃЌдђетБэУїЪ§ОнРДзде§ЬЌЗжВМЁЃ
ЯТУцЪЧДгЭМжаФЃФтЕФ 1000 ИіЫцЛњбљБОЕФ r(i) гы pi=(i?0.5)/N,i=1,...,N ЕФЙиЯЕЭМ
N <- 1000 x <- rnorm(N) p <- ((1:N)-0.5)/N plot
ЮвУЧЛЙПЩвдЙЙНЈвЛИіе§ЬЌЕФЗжЮЛЪ§-ЗжЮЛЪ§ЭМЁЃПЩвджЄУї ІЕ(r(i))ІЕ(r(i)) дк [0,1] ЩЯОпгаОљдШЗжВМЁЃетвтЮЖзХ E(ІЕ(r(i)))=i/(N+1)ЃЈетЪЧРДзд [0,1] ЩЯЕФОљдШЗжВМЕФЕк i НзЭГМЦСПЕФЦкЭћжЕЁЃ
етвтЮЖзХ N Еу (pi,ІЕ(r(i))) гІИУТфдквЛЬѕжБЯпЩЯЁЃЯждкНЋ ІЕ?1 БфЛЛгІгУгкЫЎЦНКЭДЙжБГпЖШЁЃNИіЕу
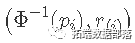
аЮГЩе§ЬЌИХТЪЭМ  . ШчЙћ
. ШчЙћ  ЪЧДге§ЬЌЗжВМЩњГЩЕФЃЌШЛКѓЪЧЕуЭМ
ЪЧДге§ЬЌЗжВМЩњГЩЕФЃЌШЛКѓЪЧЕуЭМ 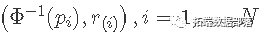 гІИУЪЧвЛЬѕжБЯпЁЃ
гІИУЪЧвЛЬѕжБЯпЁЃ
дк R qnorm() жаЪЧ ІЕ-1ЁЃ
plot(qnorm(p),sort(x))
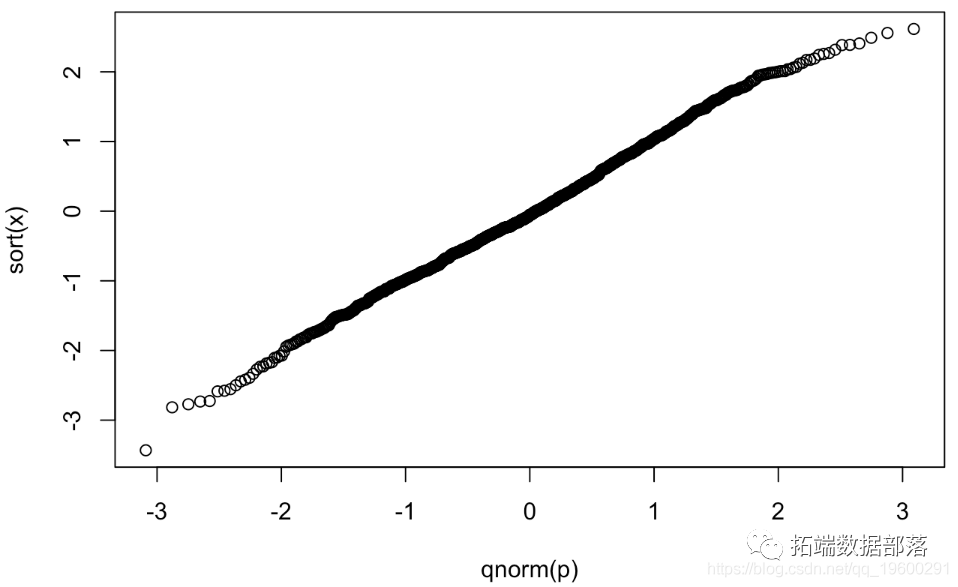
ЮвУЧЭЈГЃЪЙгУФкжУКЏЪ§ qqnorm() ЃЈВЂ qqline() ЬэМгвЛЬѕжБЯпНјааБШНЯЃЉРДЩњГЩ QQ ЭМЁЃЧызЂвтЃЌR ЪЙгУЩдЮЂИќЭЈгУЕФЗжЮЛЪ§ (pi=(1?a)/(N+(1?a)?a)ЃЌЦфжа a=3/8ЃЌШчЙћ NЁм10ЃЌa=1/2ЃЌШчЙћN>10ЁЃ
qqnorm(x);qqline(x)
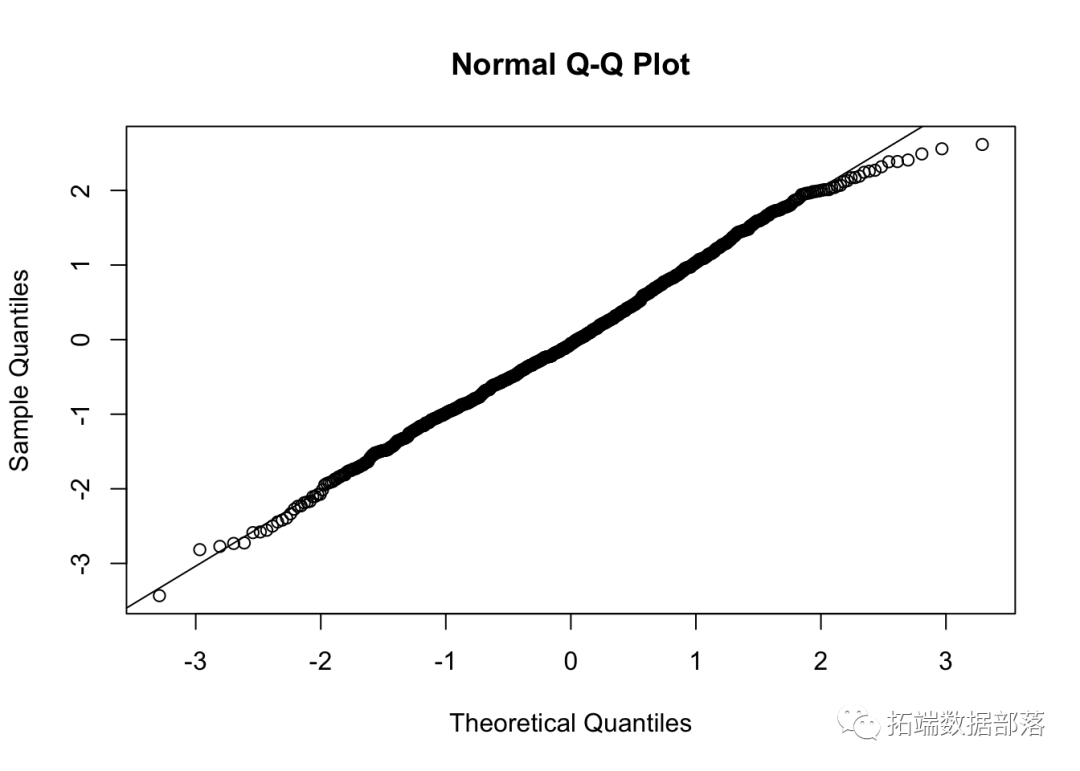
ИУЭМгыжБЯпЕФЯдзХЃЈЯЕЭГадЃЉЦЋВюБэУїЃК
- е§ЬЌМйЩшВЛГЩСЂЁЃ
- ЗНВюВЛЪЧКуЖЈЕФЁЃ
вЛИіжївЊгІгУЪЧдквђзгЩшМЦжаЃЌЦфжа r(i) БЛгаађвђзгаЇгІДњЬцЁЃЩш ^ІШ(1)<^ІШ(2)<?<^ІШ(N) ЮЊ N ИігаађвђзгЙРМЦЁЃШчЙћЮвУЧЛцжЦ

ФЧУДНгНќ 0 ЕФНзГЫаЇгІ ^ІШi НЋбижБЯпЯТНЕЁЃвђДЫЃЌЦЋРыжБЯпЕФЕуНЋБЛШЯЮЊЪЧживЊЕуЁЃ
ЛљБОдРэШчЯТЃК1. МйЩшЙРМЦаЇгІ ^ІШi ЮЊ N(ІШ,Ів)ЃЈЙРМЦаЇгІЩцМА N ИіЙлВтжЕЕФЦНОљжЕЃЌCLT ШЗБЃ N аЁжС 8 ЕФЦНОљжЕНгНќе§ЬЌЃЉЁЃ2. ШчЙћ H0:ІШi=0,i=1,...,N ЮЊецЃЌФЧУДЫљгаЙРМЦЕФгАЯьЖМНЋЮЊСуЁЃ3. ЙРМЦаЇгІЕФНсЙће§ЬЌИХТЪЭМНЋЪЧвЛЬѕжБЯпЁЃ4. вђДЫЃЌе§ЬЌИХТЪЭМЪЧМьбщЫљгаЙРМЦЕФаЇгІЪЧЗёОпгаЯрЭЌЕФЗжВМЃЈМДЯрЭЌЕФОљжЕЃЉЁЃ
- ЕБвЛаЉаЇгІВЛЮЊСуЪБЃЌЯргІЕФЙРМЦаЇгІНЋЧїгкИќДѓВЂЦЋРыжБЯпЁЃ
- Ждгке§УцгАЯьЃЌЙРМЦЕФгАЯьТфдкИУЯпжЎЩЯЃЌЖјИКУцгАЯьТфдкИУЯпжЎЯТЁЃ
ЪОР§ - 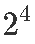 баОПЛЏбЇЗДгІЕФЩшМЦ
баОПЛЏбЇЗДгІЕФЩшМЦ
вЛИіЙЄвеПЊЗЂЪЕбщбаОПСЫЫФИівђЫи 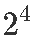 вђзгЩшМЦЃКДпЛЏМСзАСЯСП 1ЁЂЮТЖШ 2ЁЂбЙСІ 3КЭЦфжавЛжжЗДгІЮяЕФХЈЖШ 4ЁЃвђБфСП y ЪЧ 16 ИідЫааЬѕМўжаУПИіЬѕМўЯТЕФзЊЛЏАйЗжБШЁЃИУЩшМЦШчЯТЭМЫљЪОЁЃ
вђзгЩшМЦЃКДпЛЏМСзАСЯСП 1ЁЂЮТЖШ 2ЁЂбЙСІ 3КЭЦфжавЛжжЗДгІЮяЕФХЈЖШ 4ЁЃвђБфСП y ЪЧ 16 ИідЫааЬѕМўжаУПИіЬѕМўЯТЕФзЊЛЏАйЗжБШЁЃИУЩшМЦШчЯТЭМЫљЪОЁЃ
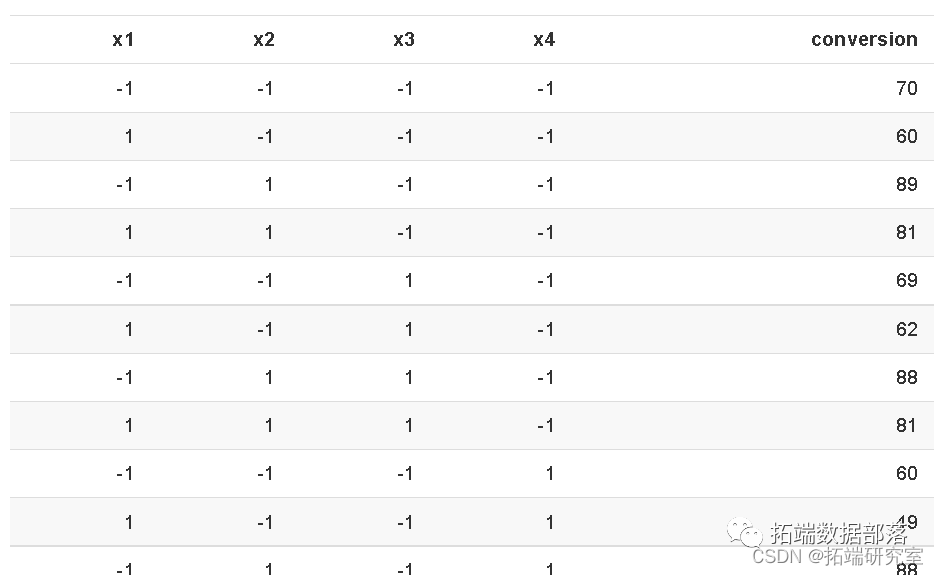
ИУЩшМЦЮДжиИДЃЌвђДЫЮоЗЈЙРМЦвђзгаЇгІЕФБъзМЮѓВюЁЃ
fct1 <- lm
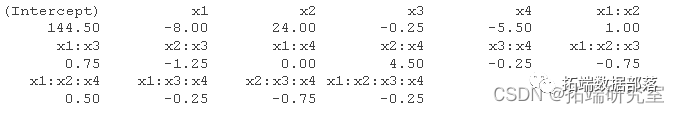
ПЩвдЛёЕУвђзгаЇгІЕФе§ЬЌЭМ ЁЃ
Plot(fac
ЖдгІЕФаЇЙћ x1, x4, x2:x4, x2 ВЛЛсбизХжБЯпЯТНЕЁЃ
Аые§ЬЌЭМ
ЯрЙиЕФЭМаЮЗНЗЈГЦЮЊАые§ЬЌИХТЪЭМЁЃШУ
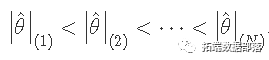
БэЪОЮоБъЪЖвђзгаЇгІЙРМЦЕФгаађжЕЁЃ
ИљОнАые§ЬЌЗжВМЕФзјБъЛцжЦЫќУЧ - е§ЬЌЫцЛњБфСПЕФОјЖджЕОпгаАые§ЬЌЗжВМЁЃ
Аые§ЬЌИХТЪЭМгЩЕузщГЩ
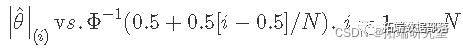
ИУЭМЕФвЛИігХЕуЪЧЫљгаНЯДѓЕФЙРМЦаЇгІЖМГіЯждкгвЩЯНЧВЂТфдкИУЯпжЎЩЯЁЃ
ПЩвдЛёЕУЙ§ГЬПЊЗЂЪОР§жааЇЙћЕФАые§ЬЌЭМhalf = TRUEЁЃ

Lenth ЗНЗЈЃКМьбщУЛгаЗНВюЙРМЦЕФЪЕбщЕФЯдзХад
Аые§ЬЌЭМКЭе§ЬЌЭМЪЧЩцМАЪгОѕХаЖЯЕФЗЧе§ЪНЭМаЮЗНЗЈЁЃзюКУИљОне§ЪНЕФЯдзХадМьбщРДЖЈСПЕиХаЖЯгыжБЯпЕФЦЋВюЁЃ

дк 2k ЩшМЦ N=2k-1 жаЙРМЦ ІШ1,ІШ2,...,ІШNЕФвђзгаЇгІЁЃМйЩшЫљгавђзгаЇгІОпгаЯрЭЌЕФБъзМВюЁЃ
ЮББъзМЮѓВю (PSE) ЖЈвхЮЊ

ЦфжажаЮЛЪ§ЪЧдк ЈOЈO^ІШiЈO жаМЦЫуЕФ  КЭ
КЭ

ЙРМЦЕФвђзгаЇгІЮЊЃК
ef <- 2*fat1$coeffic

s0=1.5?medianЈOЈO^ІШiЈOЈOЕФЙРМЦЪЧ
s0 <- 1.5*median(abs(eff)) s0
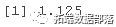
аоећГЃЪ§ 2.5s0 ЪЧ
2.5*s0
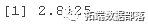
ЈOЈO^ІШiЈOЈOЁн2.5s0 ЕФаЇЙћ ^ІШi НЋБЛаоМєЁЃЯТУцЪЧБъМЧЮЊ TRUE ( x1,x2,x4,x2:x4)ЕФаЇЙћ
abs(eff)<2.5*s0

ШЛКѓНЋ PSE МЦЫуЮЊетаЉжЕжаЮЛЪ§ЕФ 1.5 БЖЁЃ
PE <- 1.5*median PE

ME КЭ SME ЪЧ
ME <- PE*qt ME
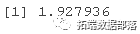
PE*qt(p =(1+.95^{1/15})/2,df=(16-1)/3)

вђДЫЃЌаЇЙћЕФ 95% жУаХЧјМфЮЊЃК
lor <- round(ef-ME,2) uper <- round(ef+ME,2) kable(cbind)

Опга ME КЭ SME ЕФаЇЙћЭМЭЈГЃГЦЮЊ Lenth ЭМЁЃPSE,ME,SMEPSE,ME,SME ЕФжЕЪЧЪфГіЕФвЛВПЗжЁЃЯТЭМжаЕФМтЗхгУгкЯдЪОвђзгаЇгІЁЃ
Plot(fat1,cex.fac = 0.5)
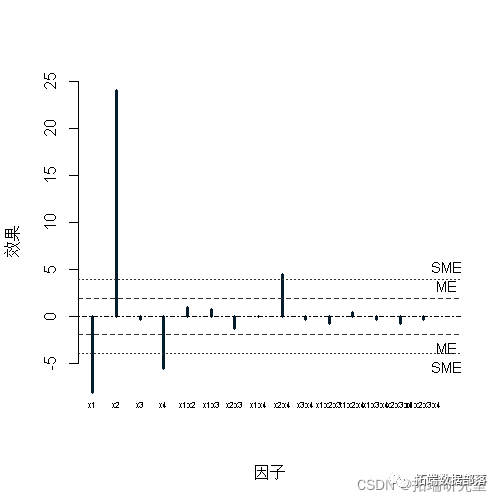

ИУбЁЯю cex.fac = 0.5 ЕїећгУгквђзгБъЧЉЕФзжЗћДѓаЁЁЃ
