ЫљЪіХфЖдЫЋбљЦЗЕФWilcoxonМьбщвЛжжЕФЗЧВЮЪ§МьбщЃЌЦфПЩвдБЛгУгкБШНЯбљЦЗЕФСНИіЖРСЂЪ§ОнЁЃ
БОЮФНщЩмШчКЮдк?жаМЦЫуСНИібљБОЕФжШМьбщЁЃ
ПЩЪгЛЏЪ§ОнВЂдк?жаМЦЫуЕФWilcoxonВтЪд
КЏЪ§гУгкМЦЫуЕФжШМьбщ
ЮЊСЫжДааСНИібљБОЕФWilcoxonМьбщЃЌБШНЯСНИіЖРСЂбљБОЃЈxЃІyЃЉЕФОљжЕЃЌRКЏЪ§wilcox.testЃЈЃЉПЩвдШчЯТЪЙгУЃК
wilcox.test(x, y, alternative = "two.sided")
- xЃЌyЃКЪ§зжЯђСП
- ЬцДњЗНАИЃКЬцДњМйЩшдЪаэжЕЪЧЁАtwo.sidedЁБЃЈФЌШЯжЕЃЉЃЌЁАИќДѓЁБЛђЁАИќЩйЁБжЎвЛЁЃ
НЋЪ§ОнЕМШыR.
- зМБИЪ§Он
- НЋЪ§ОнБЃДцдкЭтВПЕФ.TXTбЁЯюПЈЛђЕФЕФ.csvЮФМўжа
- НЋФњЕФЪ§ОнЕМШы?ШчЯТЃК
my_data <- read.delim(file.choose()) my_data <- read.csv(file.choose())
дкетРяЃЌЮвУЧНЋЪЙгУвЛИіЪОР§Ъ§ОнМЏЃЌЦфжаАќКЌ18ИіШЫЃЈ9УћХЎадКЭ9УћФаадЃЉЕФШЈжиЃК
women_weight <- c(38.9, 61.2, 73.3, 21.8, 63.4, 64.6, 48.4, 48.8, 48.5) men_weight <- c(67.8, 60, 63.4, 76, 89.4, 73.3, 67.3, 61.3, 62.4) # ДДНЈ data frame my_data <- data.frame( group = rep(c("Woman", "Man"), each = 9), weight = c(women_weight, men_weight) )
ЮвУЧЯыжЊЕРЃЌШчЙћХЎадЬхжиЕФжаЮЛЪ§гыФаадЬхжиЕФжаЮЛЪ§ВЛЭЌЃП
МьВщЪ§Он
print(my_data) group weight 1 Woman 38.9 2 Woman 61.2 3 Woman 73.3 4 Woman 21.8 5 Woman 63.4 6 Woman 64.6 7 Woman 48.4 8 Woman 48.8 9 Woman 48.5 10 Man 67.8 11 Man 60.0 12 Man 63.4 13 Man 76.0 14 Man 89.4 15 Man 73.3 16 Man 67.3 17 Man 61.3 18 Man 62.4
ПЩвдАДзщМЦЫуЛузмЭГМЦЪ§ОнЃЈжаЮЛЪ§КЭЫФЗжЮЛЪ§МфОрЃЈIQRЃЉЃЉЁЃПЩвдЪЙгУdplyrАќЁЃ
- вЊАВзАdplyrШэМўАќЃЌЧыМќШывдЯТФкШн
install.packages("dplyr")
- АДзщМЦЫуеЊвЊЭГМЦаХЯЂЃК
library(dplyr) group_by(my_data, group) %>% summarise( count = n(), median = median(weight, na.rm = TRUE), IQR = IQR(weight, na.rm = TRUE) ) Source: local data frame [2 x 4] group count median IQR (fctr) (int) (dbl) (dbl) 1 Man 9 67.3 10.9 2 Woman 9 48.8 15.0
ЪЙгУЯфаЮЭМПЩЪгЛЏЪ§Он
ПЩвдАДееДЫСДНгжаЕФУшЪіЛцжЦRЛљБОЭМЃКRЛљБОЭМЁЃдкетРяЃЌЮвУЧНЋЪЙгУggpubr RАќНјааЛљгкggplot2ЕФМђЕЅЪ§ОнПЩЪгЛЏ
- ДгGitHubЩЯЕФАВзАзюаТАцБОЕФggpubrШчЯТЃЈЭЦМіЃЉЃК
# АВзА if(!require(devtools)) install.packages("devtools") devtools::install_github("kassambara/ggpubr")
- ЛђепЃЌДгCRANАВзАШчЯТЃК
install.packages("ggpubr")
# ЗжзщЛцжЦЬхжи library("ggpubr") ggboxplot(my_data, x = "group", y = "weight", color = "group", palette = c("#00AFBB", "#E7B800"), ylab = "Weight", xlab = "Groups")
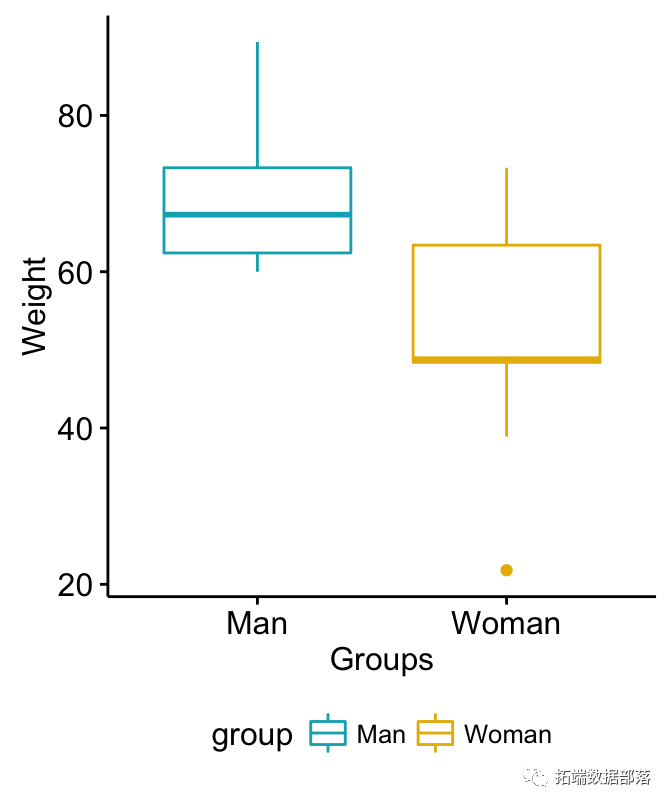
МЦЫуВЛГЩЖдЕФЫЋбљБОжШМьбщ
ЮЪЬтЃКХЎадКЭФаадЬхжигаЯдзХВювьТ№ЃП
1ЃЉМЦЫуЫЋбљБОWilcoxonМьбщ - ЗНЗЈ1ЃКЪ§ОнБЃДцдкСНИіВЛЭЌЕФЪ§жЕЯђСПжаЁЃ
res <- wilcox.test(women_weight, men_weight) res Wilcoxon rank sum test with continuity correction data: women_weight and men_weight W = 15, p-value = 0.02712 alternative hypothesis: true location shift is not equal to 0
вЛЬѕОЏИцаХЯЂЃЌГЦЮЊЁАЮоЗЈгУЦНОжМЦЫуОЋШЗЕФpжЕЁБЁЃЫќПЩвдЭЈЙ§ЬэМгСэвЛИіВЮЪ§exact = FALSEРДвжжЦДЫЯћЯЂЃЌЕЋНсЙћНЋЪЧЯрЭЌЕФЁЃ
2ЃЉМЦЫуЫЋбљБОWilcoxonМьбщ - ЗНЗЈ2ЃКНЋЪ§ОнБЃДцдкЪ§ОнПђжаЁЃ
res <- wilcox.test(weight ~ group, data = my_data, exact = FALSE) res Wilcoxon rank sum test with continuity correction data: weight by group W = 66, p-value = 0.02712 alternative hypothesis: true location shift is not equal to 0 # Print the p-value only res$p.value[1] 0.02711657
етСНжжЗНЗЈИјГіСЫЯрЭЌЕФНсЙћЁЃ
ВтЪдЕФpжЕЮЊ 0.02712ЃЌаЁгкЯдзХадЫЎЦНІС= 0.05ЁЃЮвУЧПЩвдЕУГіНсТлЃЌФаадЕФжаЮЛЪ§ЬхжигыХЎадЕФжаЮЛЪ§ЬхжиЯдзХВЛЭЌЃЌpжЕ = 0.02712ЁЃ
зЂвтЃК
- ШчЙћФуЯыВтЪдФаадЬхжиЕФжаЮЛЪ§ЪЧЗёаЁгкХЎадЬхжиЕФжаЮЛЪ§ЃЌЧыЪфШыЃК
wilcox.test(weight ~ group, data = my_data, exact = FALSE, alternative = "less")
- ЛђепЃЌШчЙћФњЯыВтЪдФаадЬхжиЕФжаЮЛЪ§ЪЧЗёДѓгкХЎадЬхжиЕФжаЮЛЪ§ЃЌЧыЪфШыДЫжЕ
wilcox.test(weight ~ group, data = my_data,exact = FALSE, alternative = "greater")
ЛЙгаЮЪЬтТ№ЃПЧыдкЯТУцСєбдЃЁ
