ШЋЮФСДНгЃКhttp://tecdat.cn/?p=32427
ЗжЮіЪІЃКXueyan Liu
дкЕБЧАКЃСПЪ§ОнКЭзЪдДЕФЧщПіЯТЃЌУцЖдПЭЛЇашЧѓЃЌШчКЮевзМашЧѓБъЕФКЭЮЪЬтКЫаФЃЌВЂЮЇШЦИУФПБъЮЪЬтЭкОђЪ§ОнЁЂШЗЖЈЪаГЁживЊЙиСЊвђЫиЁЂЗжВуЗжРрЩИбЁПЩФмЙиСЊвђЫиЃЌЪЧЕБЧАЪ§ОнЗжЮідЫгУЕФЙиМќЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећЪ§ОнЃЉЁЃ
НтОіЗНАИ
ШЮЮё/ФПБъ
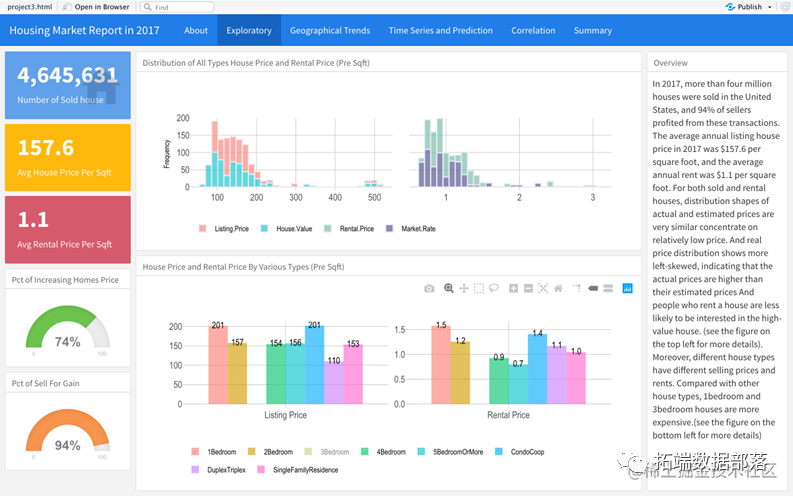
ДЫЯюФПИљОнШЋУРЗПЕиВњЯрЙиЖрдДЪ§ОнЃЈВщПДЮФФЉСЫНтЪ§ОнУтЗбЛёШЁЗНЪНЃЉЃЌжМдкгУЪ§ОнДДНЈвЛИіБЈИцЃЌ ШЋЗНУцЖрЮЌЖШеЙЪОУРЙњЗПЮнЪаГЁЯжзДЁЃвдЗПЮнЪлМлЮЊКЫаФЃЌЪсРэжївЊЯрЙижИБъЃЌВЂЭкОђЦфЫћПЩФмЯрЙиаджИБъЃЌЭЈЙ§ЖдЕЅвЛЛђЖрИіжИБъЃЌОЋзМбЁдёКЯРэЫуЗЈНЈФЃЃЌЖдЗПЮнЪаГЁЮДРДЗЂеЙзїГідЄВтЃЌгУвдИќКУЕФеЙЯжЪаГЁЕФШЋУВЁЃ
Ъ§ОнзМБИЃК
ЧАЦкЪ§ОнРДдДЃКЭЈЙ§ЫбЙ§ЙйЗНЛђепаТЮХУНЬхЕФаавЕБЈИцжаЕФЪ§ОнРДдДЃЌГѕЪМЪ§ОнАќРЈЃКдТЖШЗПЕиВњЯрЙиЪ§Он
КѓЦкЪ§ОнРДдДЃКИљОнЬНЫїадЗжЮіКѓЕФНсЙћЃЌгаеыЖдадЕФдкПЊдДЪ§ОнПтНјааЙиМќДЪЫбЫїЃЌАќРЈ
ЬНЫїадЪ§ОнЗжЮіЃЈEDAЃЉ:
ЭЈЙ§ЖдЪ§ОнНјааЧхЯДЃЌНЋЪ§ОнПЩЪгЛЏЃЛДгЭГМЦЗжВМЃЌЕигђЗжВМЃЌЪБМфЗжВМЕШЖрЮЌЖШНјааЗжЮіЁЂбАевЪ§ОнжЎМфЕФЙиЯЕЃЌВЂгЩДЫЗжЮіГіИќЖрПЩФмЯрЙивђЫиЃЌвдНјвЛВНЩюШыЭкОђЁЃ
ЮЊСЫИќЧхЮњЕФБэЯжЪ§ОнЃЌВЩгУRжаflexdashboardжЦзїПЩЛЅЖЏадБЈИцЃЌВЂОЁПЩФмВЩгУЖржжВЛЭЌЕФЭМБэЃЌвдзюДѓаЇгУПЩЪгЛЏЪ§ОнЁЃР§ШчЃКДДНЈЬѕаЮЭМЃЌЖдБШЗПЮнЙвХЦМлКЭЪЕМЪЪлМлЕФЗжВМЃЛЛђепДДНЈЕиЭМЃЌвдЪОВЛЭЌЕиЧјЗПЮнЪлМлЛђепзтН№ЗжВМЕФВювьЁЃ
ДДНЈдЄВтФЃаЭЃК
ЪЙгУдЄВтФЃаЭЃЌвдИќКУЕФСЫНтаавЕЮДРДЕФЗЂеЙЧїЪЦЃК
SARIMA ЪБМфађСаФЃаЭ
ЛљгкarimaЪБМфађСаФЃаЭжЎЩЯЃЌПМТЧСЫМОНкадвђЫиЁЃАбЙ§ШЅЕФжЕЃЈARЃЉЁЂЙ§ШЅЕФдЄВтЮѓВюЃЈMAЃЉЁЂЙ§ШЅжЕжЎМфЕФВювьЃЈIЃЉКЭМОНкГЄЖШЃЈSЃЉзїЮЊдЄВтВЮЪ§ЁЃЭЈЙ§ЖдPACFКЭACFЕФЗжЮіЃЌевЕНзюгХВЮЪ§ЃЌРДНјаадЄВтЁЃ
VAR ЪБМфађСаФЃаЭ
VARвВГЦЮЊЯђСПздЛиЙщФЃаЭЃЌ ЪЧвЛжждкздЛиЙщФЃаЭЕФЛљДЁЩЯРЉеЙФЃаЭЁЃVARФЃаЭМДНЋФкЩњжЭКѓжЕЃЌвВНЋЭЌЦкЕФЭтЩњжЭКѓЯюЪгЮЊЛиЙщСПЃЌПЩдкЕЅИіФЃаЭжаЭЌЪБдЄВтЖрИіЪБМфађСаЯрЙиБфСПЁЃ
XGBoost ФЃаЭ
ЪЧвЛжжГЃМћЕФОіВпЪїЫуФЃаЭЃЌЫћЭЈЙ§ВЛЖдЕФвбгаЕФЪїаое§дйДДНЈаТЪщЃЌжБЕНзюгХНсЙћЁЃЕБгУгкЪБМфађСадЄВтЪБЃЌашвЊАбЪБМфађСаЪ§ОнзЊЛЏЮЊМрЖНЪ§ОнЃКАбашвЊдЄВтФПБъЪ§ОнЮЊвђБфСП,АбЪБМфЕуВ№ЗжЮЊФъЗнКЭдТЃЌзїЮЊбЦБфСПЁЃ
ЦфЫћПЩФмадвђЫиЯрЙиадбщжЄЃК
Г§ШЅЗПЮнЪаГЁздЩэВњвЕжИБъЖдЗПМлЕФгАЯьЃЌдйЭкОђЦфЫћПЩФмадгАЯьвђЫиКѓЃЌашвЊбщжЄетаЉжИБъЪЧЗёЯрЙиЁЃ
ЯрЙиЯЕЪ§Оиеѓ
жБЙлЕФБэЯжГіВЛЭЌжИБъЙиСЊадЕФЧПШѕЁЃ
ЬиеїЬсШЁФЃаЭ
ЭЈЙ§НЈФЃаЭЃЌНЕЕЭЪ§ОнЮЌЖШЃЌЬєбЁГіживЊжИБъЁЃМШПЩвдЮЊШеКѓдЄВтНЈФЃЬсЙЉЭГМЦбЇЕФЪ§ОнВЮПМЃЌвВПЩвдВрУцЫЕУїИУжИБъЖдЗПМлгаКмДѓЕФгАЯь
1. PCA жїГЩЗжЗжЮі
ЭЈГЃгУгкМѕЩйЮЌЪ§ЁЃЫќгУгкНЋОпгааэЖрСаЕФЪ§ОнМЏМѕЩйЕННЯЩйЕФСаЪ§ЃЌЖјВЛЛсЖЊЪЇЪ§ОнЕФБОжЪЁЃзїЮЊИНДјНсЙћЃЌЫќЛЙЬсЙЉСЫБфСПжЎМфЕФЯрЙиадЁЃPCAНЋ24ИіжИБъЫѕМѕЮЊФмНтЪЭ90%ЕФжївЊГЩЗжЪ§ЃЌВЂНЋЬиеїдкНЕЮЌЗНУцЦ№СЫзїгУЕФживЊГЬЖШХХУћЩИбЁГізюживЊЕФЮхИіЬиеїЁЃ
2. LASSO
LassoЫуЗЈЪЧвЛжжМрЖНЫуЗЈЃЌГЂЪдевГіЫљгаЖРСЂБфСПгыФПБъБфСПжЎМфЕФЯрЙиадЁЃLassoБфСПЕФЯЕЪ§БЦНќСу,ЪЕЯжЪеЫѕЁЃЭЈЙ§НЛВцбщжЄевЕНзюМбдМЪјВЮЪ§ЁЃ
EDA НсЙћЃК
ЯТЭМНіЮЊБЈИцЕФПЩНЛЛЅЪНdashboardВПЗжНиЭМЃЌКИЧСЫВПЗжEDAНсЙћЁЃ
ЭЈЙ§EDAЕФЗжЮіЃЌЮвЗЂЯжЗПМлеЙЯжГіНЯЮЊЮШЖЈЕФжмЦкадКЭдіГЄЧїЪЦЃЌВЂКЭВПЗжЦфЫћжИБъгазХЙиСЊадЃЌвђДЫЬєбЁСЫШ§жжВЛЭЌЕФФЃаЭПЩФмЪЪгУЕФФЃаЭЃЈVAR,SARIMA,XGBOOSTЃЉЃЌдкЯТвЛВПЗжНјаадЄВтЗжЮіЁЃ
ЭЌЪБEDAвВеЙЪОЗПЮнЪаГЁИїРржИБъБэЯжГіНЯЧПЕФЕигђВювьЃЌгЩДЫеЙПЊЩюШыЭкОђЃЌЭЈЙ§ЖўДЮЪ§ОнЫбЫїКЭЕїВщЃЌНјааЯрЙиадЗжЮіЁЃ

ЕуЛїБъЬтВщдФЭљЦкФкШн

PYTHONСДМвзтЗПЪ§ОнЗжЮіЃКСыЛиЙщЁЂLASSOЁЂЫцЛњЩСжЁЂXGBOOSTЁЂKERASЩёОЭјТчЁЂKMEANSОлРрЁЂЕиРэПЩЪгЛЏ
01

02

03

04

дЄВтФЃаЭНсЙћЃК

Ш§ИіФЃаЭжазюОЋШЗЕФЪЧSARIMAФЃаЭЁЃЕЋЪЧДгЭМЯёРДПДИУФЃаЭУЛгаКмКУЕФМЦЫуГіМОНкадЃЌОЙ§дйДЮГЂЪддкШЅЕєМОНкадвђЫиКѓSARIMAФЃаЭЕФзМШЗТЪгжгаСЫНјвЛВНЬсЩ§ЁЃ
ЖјДгVar ФЃаЭЕФЯЕЪ§pжЕНсЙћРДПДЃЌЯрЙиЭтЩњвђЫиВЂУЛгаЯджјадВювьЁЃXGBoostФЃаЭдкУцЖдгаУїЯдЧїЪЦЕФЪБМфађСаЪ§ОнВЂВЛеМгХЁЃ
вдШ§ИідЄВтФЃаЭзїЮЊВЮПМЃЌЕЋЪЧЛљБОЩЯЖМдЄЪОСЫЗПМлдкЮДРДЛсЮШЖЈЩЯеЧЕФЧїЪЦЁЃ
ЦфЫћПЩФмадвђЫиЯрЙиадЗжЮіНсЙћЃК
ЯТЭМДгзѓжСгвЗжБ№ЪЧЯрЙиЯЕЪ§ОиеѓЁЂPCAКЭLASSOЫуЗЈНсЙћЕФПЩЪгЛЏ
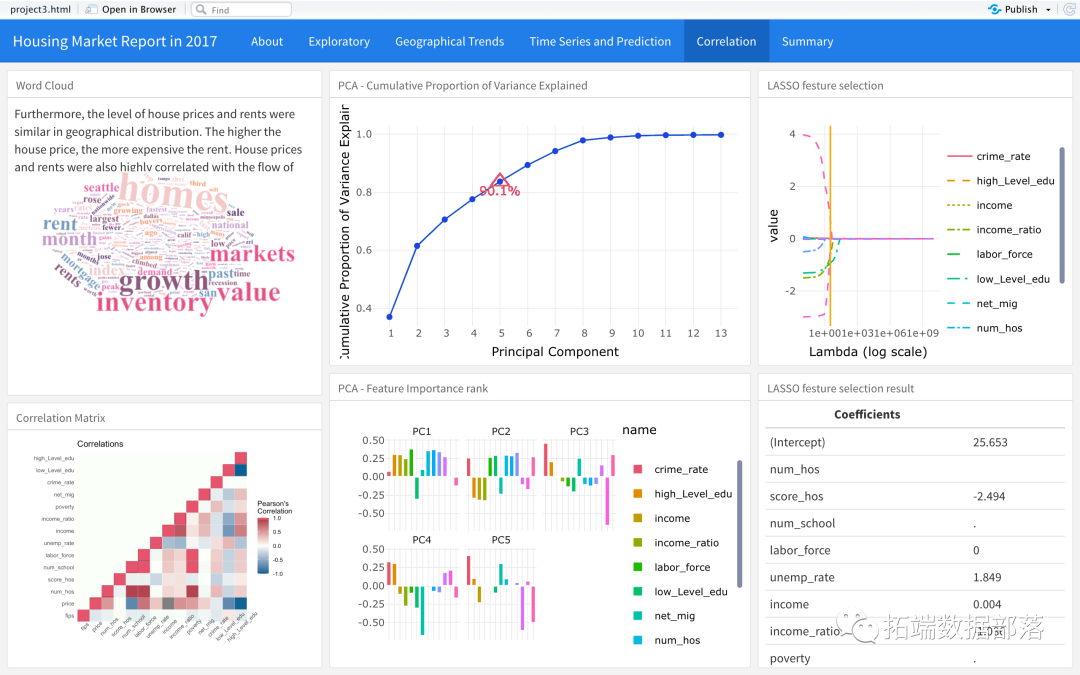
ЖюЭтЕФ24ИівђЫижаЃЌЫфШЛВЛЭЌЕФЗНЗЈНсЙћгаЫљВЛЭЌЃЌзмЕФРДЫЕНЬг§ВњвЕЯрЙиЕФжИБъОљБэЯжГіНЯИпЕФЯрЙиадЃЌПЩвдЕУГіНсТлЃЌЗПЮнЪаГЁКЭНЬг§ВњвЕИпЖШЯрЙиЁЃЭЌЪБетаЉИпЖШЯрЙиЕФжИБъвВПЩвдзїЮЊвЛИіЬиеїбЁдёЕФВЮПМЃЌвдБуШеКѓзіНјвЛВНбаОПЁЃ
змНс
вдЩЯеЙЯжЫљгаЕФНсЙћЃЌАќРЈЃКЪ§ОнПЩЪгЛЏЃЌЫуЗЈгІгУЕШЖМЪЧбаОПЗПЮнЪаГЁЯжзДЕФвЛИіЪжЖЮВЛЪЧФПЕФЁЃ
ЯывЊгУЪ§ОнЗжЮіШЋЗНУцЕФСЫНтвЛИіаавЕЃЌВЛФмНіЯогкаавЕРяЕФЪ§зжбаОПЃЌЛЙашвЊЗЂЩЂадЫМПМЃЌНсКЯЪаГЁЕїВщЛђепаавЕСьгђзЈМвЕФвтМћЃЌЖдЗжЮіНЧЖШНјаадіВЙЁЃетбљВХФмИќКУЕФНЋЪ§ОнЗжЮідЫгУЕНЪЕМЪжаШЅЁЃ
ЙигкЗжЮіЪІ
дкДЫЖдXueyan LiuЖдБОЮФЫљзїЕФЙБЯзБэЪОГЯжПИааЛЃЌЫ§дкЧЧжЮГЧДѓбЇЭъГЩСЫЪ§ОнПЦбЇзЈвЕЕФЫЖЪПбЇЮЛЁЃЩУГЄЪ§ОнећРэЃЌПЩЪгЛЏЪ§ОнКЭФЃаЭЃЌЭГМЦбЇЯАЃЌЛњЦїбЇЯА, ЪБМфађСаЁЃ
