RгябдГЭЗЃlogisticТпМЛиЙщЃЈLASSO,СыЛиЙщЃЉИпЮЌБфСПбЁдёЗжРраФМЁЙЃШћЪ§ОнФЃаЭАИР§(ЩЯ)ЃК/article/1493440
гІгУ
ШУЮвУЧГЂЪдЕкЖўзщЪ§Он
ЮвУЧПЩвдГЂЪдИїжжІЫЕФжЕ
glmnet(cbind(df0$x1,df0$x2), df0$y==1, alpha=0) plot(reg,xvar="lambda",col=c("blue","red"),lwd=2) abline(v=log(.2))
Лђеп
abline(v=log(1.2)) plot_lambda(1.2)
 ЯТвЛВНЪЧИФБфГЭЗЃЕФБъзМЃЌЪЙгУl1БъзМЗЖЪ§ЁЃ
ЯТвЛВНЪЧИФБфГЭЗЃЕФБъзМЃЌЪЙгУl1БъзМЗЖЪ§ЁЃ
аБфСПЕФБъзМЛЏ
ШчЧАЫљЪіЃЌЕквЛВНЪЧПМТЧЫљгааБфСПx_jxjЕФЯпадБфЛЛЃЌЪЙБфСПБъзМЛЏ(ДјгаЕЅЮЛЗНВю)
for(j in 1:7) X[,j] = (X[,j]-mean(X[,j]))/sd(X[,j]) X = as.matrix(X)
СыЛиЙщ
ЙигкlassoЬзЫїЛиЙщЕФЦєЗЂЪНЗНЗЈШчЯТЭМЫљЪОЁЃдкБГОАжаЃЌЮвУЧПЩвдПЩЪгЛЏlogisticЛиЙщЕФЃЈЖўЮЌЃЉЖдЪ§ЫЦШЛЃЌРЖЩЋе§ЗНаЮЪЧЮвУЧЕФдМЪјЬѕМўЃЌШчЙћЮвУЧНЋгХЛЏЮЪЬтзїЮЊвЛИідМЪјгХЛЏЮЪЬтжиаТПМТЧЃЌ
LogLik = function(bbeta){ sum(-y*log(1 + exp(-(b0+X%*%beta))) - (1-y)*log(1 + exp(b0+X%*%beta)))} contour(u,u,v,add=TRUE) polygon(c(-1,0,1,0),c(0,1,0,-1),border="blue")

етРяЕФКУДІЪЧЫќПЩвдгУзїБфСПбЁдёЙЄОпЁЃ
ЦєЗЂадЕиЃЌЪ§бЇНтЪЭШчЯТЁЃПМТЧвЛИіМђЕЅЕФЛиЙщЗНГЬy_i=xiІТ+ІХЃЌОпга l1-ГЭЗЃКЭ l2-Ы№ЪЇКЏЪ§ЁЃгХЛЏЮЪЬтБфГЩ

вЛНзЬѕМўПЩвдаДГЩ

дђНтЮЊ
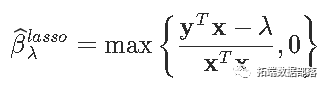
гХЛЏЙ§ГЬ
ШУЮвУЧДгБъзМЃЈRЃЉгХЛЏР§ГЬПЊЪМЃЌБШШчBFGS
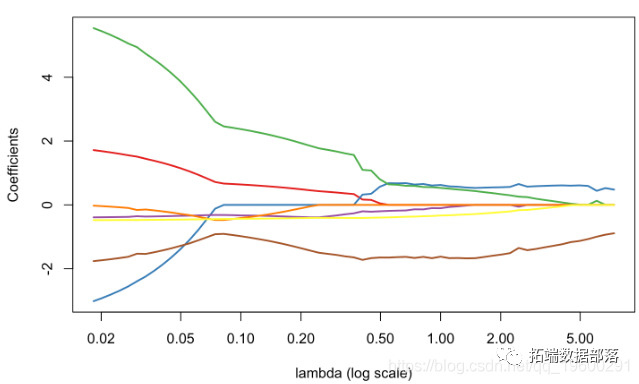
logistic_opt = optim(par = beta_init*0, function(x) PennegLogLik(x,lambda), hessian=TRUE, method = "BFGS", control=list(abstol=1e-9)) plot(v_lambda,est_lasso[1,],col=colrs[1],type="l") for(i in 2:7) lines(v_lambda,est_lasso[i,],col=colrs[i],lwd=2)
НсЙћЪЧВЛЮШЖЈЕФЁЃ
ЪЙгУglmnet
ЮЊСЫНјааБШНЯЃЌЪЙгУзЈгУгкlassoЕФRГЬађЃЌЮвУЧЕУЕНвдЯТФкШн
plot(glm_lasso,xvar="lambda",col=colrs,lwd=2)


ШчЙћЮвУЧзаЯИЙлВьЪфГіжаЕФФкШнЃЌОЭПЩвдПДЕНДцдкБфСПбЁдёЃЌОЭФГжжвтвхЖјбдЃЌІТjЃЌІЫ= 0ЃЌвтЮЖзХЁАецЕФЮЊСуЁБЁЃ
,lambda=exp(-4))$beta 7x1 sparse Matrix of class "dgCMatrix" s0 FRCAR . INCAR 0.11005070 INSYS 0.03231929 PRDIA . PAPUL . PVENT -0.03138089 REPUL -0.20962611
УЛгагХЛЏР§ГЬЃЌЮвУЧВЛФмЦкЭћгаПежЕ
opt_lasso(.2) FRCAR INCAR INSYS PRDIA 0.4810999782 0.0002813658 1.9117847987 -0.3873926427 PAPUL PVENT REPUL -0.0863050787 -0.4144139379 -1.3849264055
е§НЛаБфСП
дкбЇЯАЪ§бЇжЎЧАЃЌЧызЂвтЃЌЕБаБфСПЪЧе§НЛЕФЪБЃЌгавЛаЉЗЧГЃЧхГўЕФЁАБфСПЁБбЁдёЙ§ГЬЃЌ
pca = princomp(X) pca_X = get_pca_ind(pca)$coord plot(glm_lasso,xvar="lambda",col=colrs) plot(glm_lasso,col=colrs)

-
БъзМlasso
ШчЙћЮвУЧЛиЕНдРДЕФlassoЗНЗЈЃЌФПБъЪЧНтОі

зЂвтЃЌНиОрВЛЪмГЭЗЃЁЃвЛНзЬѕМўЪЧ

вВОЭЪЧ

ЮвУЧПЩвдМьВщbf0ЪЧЗёжСЩйАќКЌДЮЮЂЗжЁЃ


ЖдгкзѓБпЕФЯю

етбљЧАУцЕФЗНГЬОЭПЩвдаДГіРДСЫ

ШЛКѓЮвУЧНЋЫќУЧМђЛЏЮЊвЛзщЙцдђРДМьВщЮвУЧЕФНт
ЮвУЧПЩвдНЋІТjЗжНтЮЊе§ИКВПЗжжЎКЭЃЌЗНЗЈЪЧНЋІТjЬцЛЛЮЊІТj+-ІТj-ЃЌЦфжаІТj+ЃЌІТj-Ён0ЁЃlassoЮЪЬтОЭБфГЩСЫ

СюІСj+ЃЌІСj?ЗжБ№БэЪОІТj+ЃЌІТj?ЕФРИёРЪШеГЫЪ§ЁЃ

ЮЊСЫТњзуЦНЮШадЬѕМўЃЌЮвУЧШЁРИёРЪШеЙигкІТj+ЕФЬнЖШЃЌВЂНЋЦфЩшжУЮЊСуЛёЕУ

ЮвУЧЖдІТj?НјааЯрЭЌВйзївдЛёЕУ

ЮЊСЫЗНБуЦ№МћЃЌв§ШыСЫШэуажЕКЏЪ§

зЂвтгХЛЏЮЪЬт

вВПЩвдаД

ЙлВьЕН

етЪЧвЛИізјБъИќаТЁЃ
ЯждкЃЌШчЙћЮвУЧПМТЧвЛИіЃЈЩдЮЂЃЉИќвЛАуЕФЮЪЬтЃЌдкЕквЛВПЗжжагаШЈжи

зјБъИќаТБфЮЊ

ЛиЕНЮвУЧзюГѕЕФЮЪЬтЁЃ
lassoЬзЫїТпМЛиЙщ
етРяПЩвдНЋТпМЮЪЬтБэЪіЮЊЖўДЮЙцЛЎЮЪЬтЁЃЛиЯывЛЯТЖдЪ§ЫЦШЛдкетРя
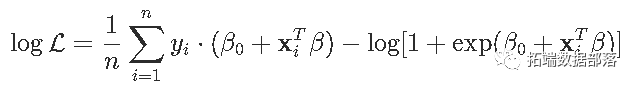
етЪЧВЮЪ§ЕФАМКЏЪ§ЁЃвђДЫЃЌПЩвдЪЙгУЖдЪ§ЫЦШЛЕФЖўДЮНќЫЦ-ЪЙгУЬЉРееЙПЊЃЌ

Цфжаz_iziЪЧ

piЪЧдЄВт
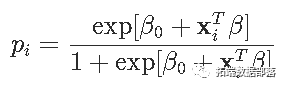
етбљЃЌЮвУЧЕУЕНСЫвЛИіГЭЗЃЕФзюаЁЖўГЫЮЪЬтЁЃЮвУЧПЩвдгУжЎЧАЕФЗНЗЈ
beta0 = sum(y-X%*%beta)/(length(y)) beta0list[j+1] = beta0 betalist[[j+1]] = beta obj[j] = (1/2)*(1/length(y))*norm(omega*(z - X%*%beta - beta0*rep(1,length(y))),'F')^2 + lambda*sum(abs(beta)) if (norm(rbind(beta0list[j],betalist[[j]]) - rbind(beta0,beta),'F') < tol) { break } } return(list(obj=obj[1:j],beta=beta,intercept=beta0)) }

ЫќПДЦ№РДЯёЪЧЕїгУglmnetЪБЕУЕНЕФНсЙћЃЌЖдгквЛаЉзуЙЛДѓЕФІЫЃЌЮвУЧШЗЪЕгаПеГЩЗжЁЃ
дкЕкЖўИіЪ§ОнМЏЩЯЕФгІгУ
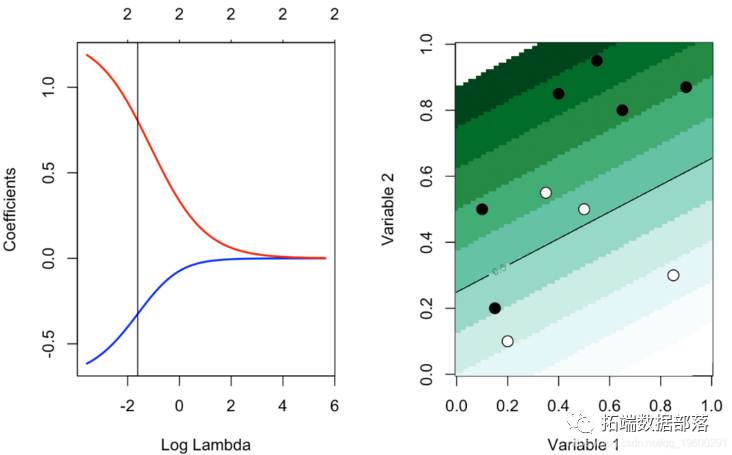
ЯждкПМТЧОпгаСНИіаБфСПЕФЕкЖўИіЪ§ОнМЏЁЃЛёШЁlassoЙРМЦЕФДњТыЪЧ
plot_l = function(lambda){ m = apply(df0,2,mean) s = apply(df0,2,sd) for(j in 1:2) df0[,j] & reg = glmnet(cbind(df0$x1,df0$x2), df0$y==1, alpha=1,lambda=lambda) u = seq(0,1,length=101) p = function(x,y){ predict(reg,newx=cbind(x1=xt,x2=yt),type="response")} image(u,u,v,col=clr10,breaks=(0:10)/10) points(df$x1,df$x2,pch=c(1,19)[1+z],cex=1.5) contour(u,u,v,levels = .5,add=TRUE)
ПМТЧ lambdaЕФвЛаЉаЁжЕЃЌЮвУЧОЭжЛгаФГжжГЬЖШЕФВЮЪ§ЫѕаЁ
plot(reg,xvar="lambda",col=c("blue","red"),lwd=2) abline(v=exp(-2.8)) plot_l(exp(-2.8))

ЕЋЪЧЪЙгУНЯДѓЕФІЫЃЌдђДцдкБфСПбЁдёЃКІТ1ЃЌІЫ= 0

