ЁОЪгЦЕЁПRгябдМЋжЕРэТлEVTЃКЛљгкGPDФЃаЭЕФЛ№джЫ№ЪЇЗжВМЗжЮі|Ъ§ОнЗжЯэ(ЩЯ)ЃК/article/1492333
ЫФЁЂФІЬьДѓТЅ
СэвЛИігаШЄЕФгІгУЪЧЖдФІЬьДѓТЅЕФЪ§ОнНЈФЃВЂМьВщЦфИпЖШКЭТЅВуЪ§ЕФЯожЦЁЃШЋЧђФІЬьДѓТЅЕФЪ§ОнРДздИпВуНЈжўКЭГЧЪаШЫОгЮЏдБЛс (CTBUH)ЁЃЖдФІЬьДѓТЅЕФЪ§СПЗжВМФтКЯСЫЖдЪ§ЯпадФЃаЭЁЃНјаа EVT ЗжЮівддЄВтМЋЖЫИпЖШКЭТЅВуЪ§ЁЃгУМЋжЕРэТлдЄВтГЧЪаЬьМЪЯпТлЮФгаЯъЯИЕФЗжЮіКЭНсЙћЁЃ

ЮхЁЂЗчЯеЙмРэ
дкетРяЮвВЛЛсСаОйвЛИіОпЬхЕФгІгУГЬађЃЌвђЮЊгаМИИігыБЃЯеКЭвјааСьгђЕФЗчЯеЙмРэЯрЙиЕФгІгУГЬађЪЙгУ EVTЁЃвЛИіЙиМќЙЄОпЪЧЗчЯеМлжЕ (VAR) КЭЦкЭћЫ№ЪЇЃЌЫќУЧЖМгУгкИљОнМЋЖЫЧщПіЦРЙРГЅИЖФмСІЁЃетаЉСьгђЛЙгаИќЖрЦфЫћЕФ EVT ЙЄОпКЭЪЕЯжЃЌФњПЩвдВщПДEXTREME VALUE THEORY AS A RISK MANAGEMENT TOOLНјвЛВНЬжТлКЭгІгУЁЃ
RгябдМЋжЕРэТлEVTЃКЛљгкGPDФЃаЭЕФЛ№джЫ№ЪЇЗжВМЗжЮі
МЋжЕРэТлЙизЂЗчЯеЫ№ЪЇЗжВМЕФЮВВПЬиеї,ЭЈГЃгУРДЗжЮіИХТЪКБМћЕФЪТМў,ЫќПЩвдвРППЩйСПбљБОЪ§Он,дкзмЬхЗжВМЮДжЊЕФЧщПіЯТ,ЕУЕНзмЬхЗжВМжаМЋжЕЕФБфЛЏЧщПі,ОпгаГЌдНбљБОЪ§ОнЕФЙРМЦФмСІЁЃвђДЫ,ЛљгкGPD(generalized pareto distribution)ЗжВМЕФФЃаЭПЩИќгааЇЕиРћгУгаЯоЕФОоджЫ№ЪЇЪ§ОнаХЯЂ,ДгЖјГЩЮЊМЋжЕРэТлЕБЧАЕФжїСїММЪѕЁЃ
еыЖдОоджЗЂЩњЦЕТЪЕЭЁЂЫ№ЪЇИпЁЂЪ§ОнВЛзуЧвОпгаКёЮВадЕШЬиЕу,РћгУGPDФЃаЭЖдЛ№джОМУЫ№ЪЇЪ§ОнНјааСЫЭГМЦНЈФЃ;ВЂЖдаЮзДВЮЪ§МАГпЖШВЮЪ§НјааСЫЙРМЦЁЃФЃаЭМьбщБэУї,GPDФЃаЭЖдОоджЗчЯеКёЮВЬиЕуОпгаНЯКУЕФФтКЯаЇЙћКЭФтКЯОЋЖШ,ЮЊОоджЗчЯеЙРМЦЕФНЈФЃМАОоджеЎШЏЕФЖЈМлЬсЙЉСЫРэТлвРОнЁЃ
Л№джЫ№ЪЇЪ§Он
БОЮФЪЙгУЕФЪ§ОнЃЈВщПДЮФФЉСЫНтЪ§ОнЛёШЁЗНЪНЃЉЪЧдкдйБЃЯеЙЋЫОЪеМЏЕФЃЌАќРЈ1980ФъжС1990ФъЦкМфЕФ2167Ц№Л№джЫ№ЪЇЁЃвбЖдЭЈЛѕХђеЭНјааСЫЕїећЁЃзмЫїХтЖювбЗжЮЊНЈжўЮяЫ№ЪЇЁЂРћШѓЫ№ЪЇЁЃ
base1=read.table( "dataunivar.txt", header=TRUE) base2=read.table( "datamultiva.txt", header=TRUE)
ПМТЧЕквЛИіЪ§ОнМЏЃЈЕНФПЧАЮЊжЙЃЌЮвУЧДІРэЕФЪЧЕЅБфСПМЋжЕЃЉЃЌ
> D=as.Date(as.character(base1$Date),"%m/%d/%Y") > plot(D,X,type="h")
ЭМБэШчЯТЃК

ШЛКѓвЛИіздШЛЕФЯыЗЈЪЧПЩЪгЛЏ

Р§Шч
> plot(log(Xs),log((n:1)/(n+1)))

ЯпадЛиЙщ
етРяЕФЕудквЛЬѕжБЯпЩЯЁЃаБТЪПЩвдЭЈЙ§ЯпадЛиЙщЕУЕНЃЌ
lm(formula = Y ~ X, data = B) lm(Y~X,data=B[(n-500):n,]) lm(formula = Y ~ X, data = B[(n - 100):n, ])



жиЮВЗжВМ
етРяЕФаБТЪгыЗжВМЕФЮВВПжИЪ§гаЙиЁЃПМТЧвЛаЉжиЮВЗжВМ

гЩгкздШЛЙРМЦСПЪЧНзДЮЭГМЦСПЃЌвђДЫжБЯпЕФаБТЪгыЮВВПжИЪ§ЯрЗД  . аБТЪЕФЙРМЦжЕЮЊЃЈНіПМТЧзюДѓЕФЙлВтжЕЃЉ
. аБТЪЕФЙРМЦжЕЮЊЃЈНіПМТЧзюДѓЕФЙлВтжЕЃЉ

ЯЃЖћЙРЫуСП
ЯЃЖћЙРЫуСПЛљгквдЯТМйЩшЃКЩЯУцЕФЗжФИМИКѕЮЊ1ЃЈМДЕШгкЃЉЁЃ

ФЧУДПЩвдЕУЕНЪеСВадМйЩшЁЃНјвЛВН

ЛљгкетИіЃЈНЅНќЃЉЗжВМЃЌПЩвдЕУЕНвЛИіЃЈНЅНќЃЉжУаХЧјМф 
> xi=1/(1:n)*cumsum(logXs)-logXs > xise=1.96/sqrt(1:n)*xi > polygon(c(1:n,n:1),c(xi+xise,rev(xi-xise)),

діСПЗНЗЈ
гыжЎРрЫЦЃЈЭЌбљЛЙгаЙигкЪеСВЫйЖШЕФИНМгМйЩшЃЉ
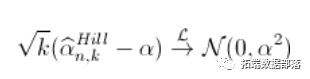
ЃЈЪЙгУдіСПЗНЗЈЛёЕУЃЉЁЃЭЌбљЃЌЮвУЧПЩвдЪЙгУИУНсЙћЕУГіЃЈНЅНќЃЉжУаХЧјМф
> alphase=1.96/sqrt(1:n)/xi > polygon(c(1:n,n:1),c(alpha+alphase,rev(alpha-alphase)),

Deckers-einmal-de-HaanЙРМЦСП

ШЛКѓЃЈдйДЮПМТЧЪеСВЫйЖШЕФЬѕМўЃЌМДЃЉЃЌ

PickandsЙРМЦ

гЩгк  ,
,

ДњТы
> xi=1/log(2)*log( (Xs[seq(1,length=trunc(n/4),by=1)]- + Xs[seq(2,length=trunc(n/4),by=2)])/ > xise=1.96/sqrt(seq(1,length=trunc(n/4),by=1))* +sqrt( xi^2*(2^(xi+1)+1)/((2*(2^xi-1)*log(2))^2)) > polygon(c(seq(1,length=trunc(n/4),by=1),rev(seq(1,

ФтКЯGPDЗжВМ
вВПЩвдЪЙгУзюДѓЫЦШЛЗНЗЈРДФтКЯИпуажЕЩЯЕФGPDЗжВМЁЃ
> gpd $n [1] 2167 $threshold [1] 5 $p.less.thresh [1] 0.8827873 $n.exceed [1] 254 $method [1] "ml" $par.ests xi beta 0.6320499 3.8074817 $par.ses xi beta 0.1117143 0.4637270 $varcov [,1] [,2] [1,] 0.01248007 -0.03203283 [2,] -0.03203283 0.21504269 $information [1] "observed" $converged [1] 0 $nllh.final [1] 754.1115 attr(,"class") [1] "gpd"
ЛђЕШаЇЕи
> gpd.fit $threshold [1] 5 $nexc [1] 254 $conv [1] 0 $nllh [1] 754.1115 $mle [1] 3.8078632 0.6315749 $rate [1] 0.1172127 $se [1] 0.4636270 0.1116136
ЫќПЩвдПЩЪгЛЏЮВВПжИЪ§ЕФТжРЊЫЦШЛадЃЌ
> gpd.prof

Лђеп
> gpd.prof

вђДЫЃЌПЩвдЛцжЦЮВжИЪ§ЕФзюДѓЫЦШЛЙРМЦСПЃЌзїЮЊуажЕЕФКЏЪ§ЃЈАќРЈжУаХЧјМфЃЉЃЌ
Vectorize(function(u){gpd(X,u)$par.ests[1]}) plot(u,XI,ylim=c(0,2)) segments(u,XI-1.96*XIS,u,XI+
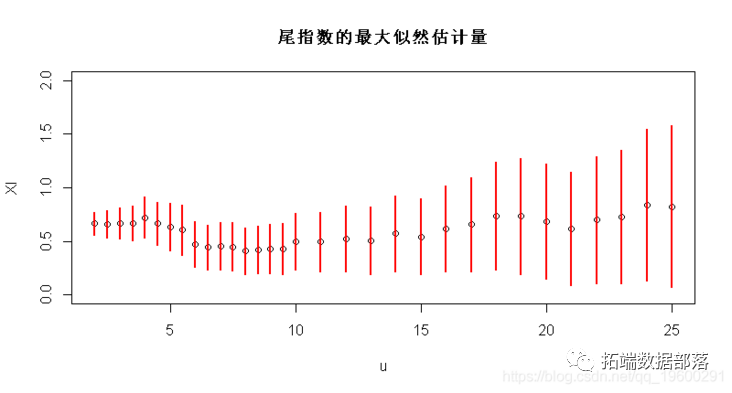
зюКѓЃЌПЩвдЪЙгУПщМЋДѓжЕММЪѕЁЃ
gev.fit $conv [1] 0 $nllh [1] 3392.418 $mle [1] 1.4833484 0.5930190 0.9168128 $se [1] 0.01507776 0.01866719 0.03035380
ЮВВПжИЪ§ЕФЙРМЦжЕЪЧдкетРязюКѓвЛИіЯЕЪ§ЁЃ
