дЮФСДНгЃКhttp://tecdat.cn/?p=22596
баОПДѓИй
- НщЩмЪ§ОнМЏКЭбаОПЕФФПБъ
- ЬНЫїЪ§ОнМЏ
- ПЩЪгЛЏ
- ЪЙгУChi-SquareЖРСЂМьбщЁЂCramer's VМьбщКЭGoodmanKruskal tauжЕЖдЪ§ОнМЏНјааЬНЫї
- дЄВтФЃаЭЃЌLogisiticЛиЙщКЭRandomForest
- step()
- bestglm()
- СНИіТпМЛиЙщЕФЪЕР§
- ЪЙгУ5елНЛВцбщжЄЖдФЃаЭЪЕР§НјааЦРЙР
- БфСПбЁдёИФНј
- ЫцЛњЩСжФЃаЭ
- гУRandomForestКЭLogisitcЛиЙщНјаадЄВт
- ЪЙгУПЩЪгЛЏНјаазюжеЕФФЃаЭЬНЫї
- НсТлКЭЯТвЛВНИФНј
1.МђНщ
БОБЈИцЪЧЖдаФдрбаОПЕФЛњЦїбЇЯА/Ъ§ОнПЦбЇЕїВщЗжЮіЁЃИќОпЬхЕиЫЕЃЌЮвУЧЕФФПБъЪЧдкаФдрбаОПЕФЪ§ОнМЏЩЯНЈСЂвЛаЉдЄВтФЃаЭЃЌВЂНЈСЂЬНЫїадКЭНЈФЃЗНЗЈЁЃЕЋЪВУДЪЧаФдрбаОПЃП
ЮвУЧдФЖССЫЙигкFHSЕФзЪСЯЃК
аФдрбаОПЪЧЖдЩчЧјздгЩЩњЛюЕФШЫШКжааФбЊЙмМВВЁВЁвђЕФГЄЦкЧАеАадбаОПЁЃаФдрбаОПЪЧСїааВЁбЇЕФвЛИіРяГЬБЎЪНЕФбаОПЃЌвђЮЊЫќЪЧЕквЛИіЙигкаФбЊЙмМВВЁЕФЧАеАадбаОПЃЌВЂШЗЖЈСЫЗчЯевђЫиЕФИХФюЁЃ
ИУЪ§ОнМЏЪЧFHSЪ§ОнМЏЕФвЛИіЯрЕБаЁЕФзгМЏЃЌга4240ИіЙлВтжЕКЭ16ИіБфСПЁЃетаЉБфСПШчЯТЃК
- ЙлВтжЕЕФадБ№ЁЃИУБфСПдкЪ§ОнМЏжаЪЧвЛИіУћЮЊ "Фаад "ЕФЖўжЕЁЃ
- ФъСфЃКЬхМьЪБЕФФъСфЃЌЕЅЮЛЮЊЫъЁЃ
- НЬг§ : ВЮгыепНЬг§ГЬЖШЕФЗжРрБфСПЃЌгаВЛЭЌЕФМЖБ№ЁЃвЛаЉИпжаЃЈ1ЃЉЃЌИпжа/GEDЃЈ2ЃЉЃЌвЛаЉДѓбЇ/жАвЕбЇаЃЃЈ3ЃЉЃЌДѓбЇЃЈ4)
- ФПЧАЮќбЬепЁЃ
- УПЬьГщЕФбЬЕФЪ§СП
- МьВщЪБЪЙгУПЙИпбЊбЙвЉЮяЕФЧщПі
- СїаааджаЗчЁЃСїаааджаЗчЃЈ0 = ЮоВЁЃЉЁЃ
- СїааадИпбЊбЙЃЈprevalentHypЃЉЁЃСїааадИпбЊбЙЁЃШчЙћНгЪмжЮСЦЃЌЪмЪдепБЛЖЈвхЮЊИпбЊбЙ
- ЬЧФђВЁЁЃИљОнЕквЛДЮМьВщЕФБъзМжЮСЦЕФЬЧФђВЁЛМеп
- змЕЈЙЬДМ(mg/dL)
- ЪеЫѕбЙ(mmHg)
- ЪцеХбЙ(mmHg)
- BMI: ЩэЬхжЪСПжИЪ§ЃЌЬхжиЃЈЙЋНяЃЉ/ЩэИпЃЈУзЃЉ^2
- аФТЪЃЈДЮ/ЗжжгЃЉ
- ЦЯЬбЬЧЁЃбЊЬЧЫЎЦН(mg/dL)
зюКѓЪЧвђБфСПЃКЙкаФВЁЃЈCHDЃЉЕФ10ФъЗчЯеЁЃ
ет4240ЬѕМЧТМжага3658ЬѕЪЧЭъећЕФВЁР§ЃЌЦфгрЕФгавЛаЉШБЪЇжЕЁЃ
2.СЫНтЪ§ОнЕФвтвх
дкУПвЛВНжЎЧАЃЌвЊМгдиЫљашЕФПтЁЃ
require(knitr) require(dplyr) require(ggplot2) require(readr) require(gridExtra) #ГЪЯжЖрЗљЭМ
ШЛКѓЃЌМгдиаФдрбаОПЕФЪ§ОнМЏЁЃ
2.1 БфСПКЭЪ§ОнМЏНсЙЙЕФМьВщ
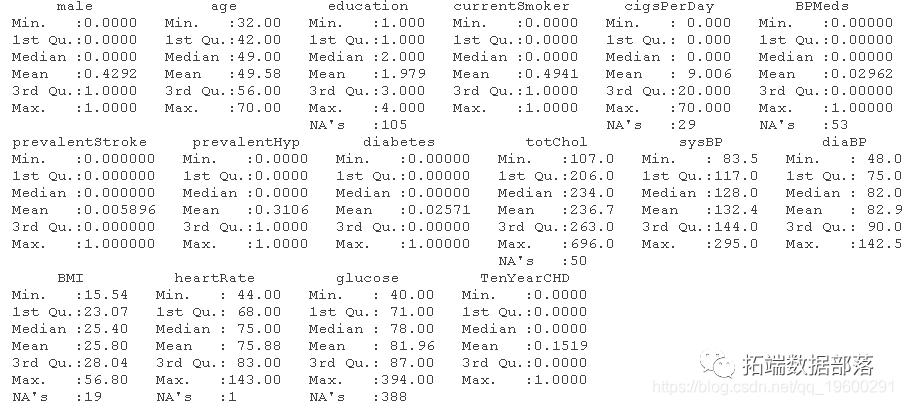
ЮвУЧЖдЪ§ОнМЏНјаавЛДЮМьВщЁЃ
dim(dataset)
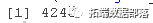
kable(head(dataset))
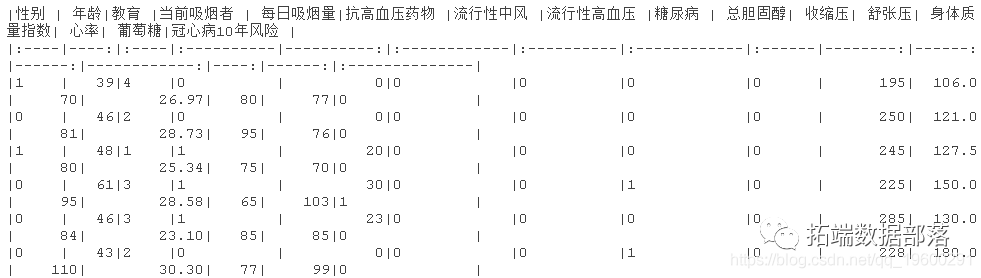
str(dataset)

##МьВщБфСПЕФеЊвЊ summary(dataset)
2.2 Ъ§ОнМЏЕФЕЅБфСПЭМ
ЩњГЩвЛИіЪ§ОнМЏЕФЫљгаЕЅБфСПЭМЁЃ
# ашвЊЩОГ§зжЗћЁЂЪБМфКЭШеЦкЕШБфСП geom_bar(data = dataset, theme_linedraw()+ #colnames(dataset) marrangeGrob(grobs=all_plots, nrow=2, ncol=2)



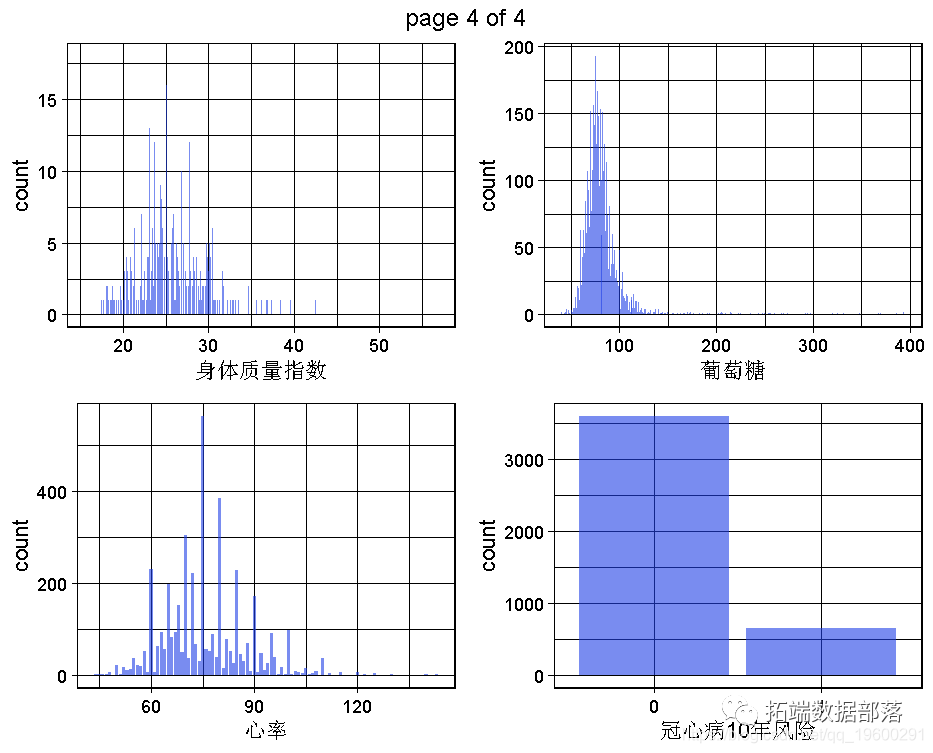
етЪЧЮЊСЫЛёЕУЖдБфСПЃЌЖдећИіЮЪЬтКЭЪ§ОнМЏЕФРэНтЃЌНЋЭЈЙ§ЖрБфСПЛђжСЩйЫЋБфСПЕФПЩЪгЛЏРДЪЕЯжЁЃ
2.3 Ъ§ОнМЏЕФЫЋБфСПЭМЃКвђБфСПКЭдЄВтвђЫижЎМфЕФЙиЯЕ
ЯждкЮвУЧПЩвдНјаавЛаЉЫЋБфСПЕФПЩЪгЛЏЃЌЬиБ№ЪЧЮЊСЫПДЕНвђБфСПЃЈTenYearCHDЃЉКЭдЄВтвђЫижЎМфЕФЙиЯЕЁЃгЩгкЭМЕФЪ§СПЬЋЖрЃЌВЛЪЧЫљгаЕФвЛЖдБфСПЖМФмБЛЕїВщЕНЃЁЮвУЧПЩвддкКѓУцЕФВНжшжаМЬајЕїВщЁЃЮвУЧПЩвдЩдКѓдйЛиЕНетвЛВНЃЌЩюШыСЫНтЁЃ
ЯТУцЕФДњТыПЩвдЩњГЩвђБфСПЕФЫљгаЫЋБфСПЭМЁЃгЩгквђБфСПЪЧвЛИіЖўдЊБфСПЃЌЫљвдЕБдЄВтБфСПЪЧЖЈСПЕФЪБКђЃЌЮвУЧЛсгаboxplotsЃЌЛђепЕБдЄВтБфСПЪЧЖЈадЕФЪБКђЃЌЮвУЧЛсгаЗжЖЮЕФbarЭМЁЃ
for (var in colnames(dataset) ){ if (class(dataset\[,var\]) %in% c("factor","logical") ) { ggplot(data = dataset) + geom\_bar( aes\_string(x = var, } else if (class(dataset\[,var\]) %in% c("numeric","double","integer") ) { ggplot(data = dataset) + geom_boxplot()
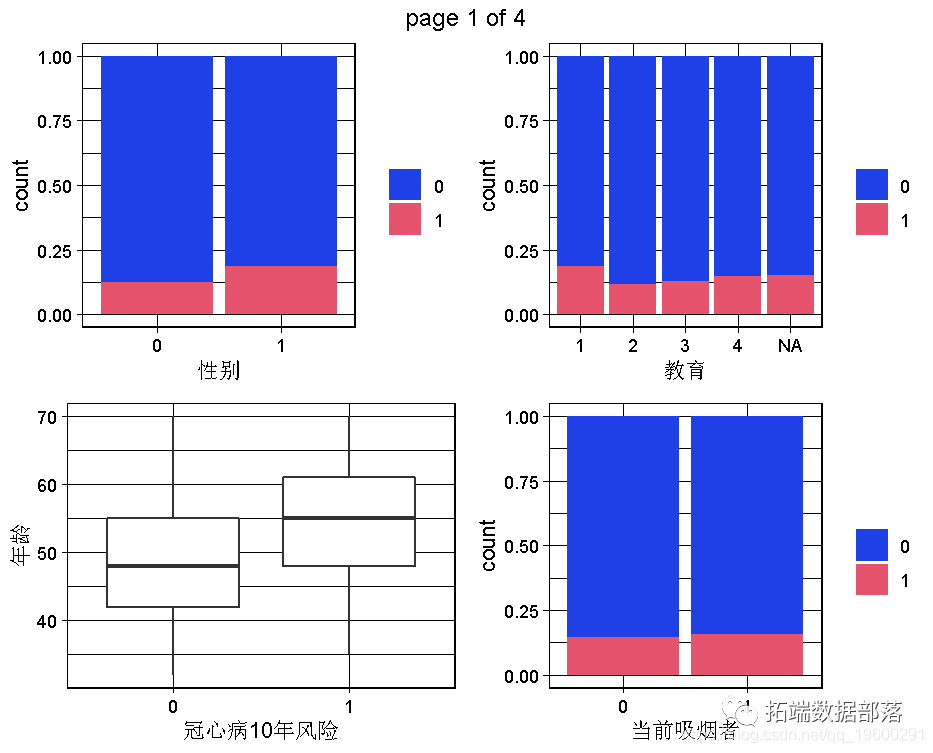



ИљОнЮвУЧеЦЮеЕФЧщПіЃЌФаадгыTenYearCHDжБНгЯрЙиЃЌвђДЫФаадетИіБфСПЫЦКѕЪЧвЛИіЯрЖдНЯКУЕФдЄВтвђЫиЁЃЭЌбљЃЌФъСфЫЦКѕвВЪЧвЛИіКмКУЕФдЄВтвђЫиЃЌвђЮЊTenYearCHD == TRUEЕФВЁШЫгаНЯИпЕФФъСфжаЮЛЪ§ЃЌЦфЗжВММИКѕЯрЫЦЁЃЯрЗДЃЌВЛЭЌРрБ№ЕФНЬг§КЭвђБфСПжЎМфЫЦКѕУЛгаЙиЯЕЁЃФПЧАЕФЮќбЬепБфСПгывђБфСПгаЧсЮЂЕФЙиЯЕЃЌвђЮЊФПЧАЕФЮќбЬепЛМTenYearCHDЕФЗчЯеТдИпЁЃ
2.4 ЪЙгУGoodman&Kruskal tauМьбщЖЈадБфСПжЎМфЕФЙиЯЕ
ШЛЖјЃЌГ§СЫетаЉБОжЪЩЯЪЧЖЈадЗНЗЈЕФЭМБэЭтЃЌШЫУЧПЩФмЯЃЭћЖдетжжЙиСЊгавЛИіЪ§зжжЕЁЃЮЊСЫгаетбљЕФЪ§зжВтСПЃЌЮвЯыЪЙгУGoodman&KruskalЕФtauВтСПЃЌетЪЧСНИіЮоађвђзгЃЌМДСНИіЗжРр/УћвхБфСПжЎМфЕФЙиСЊВтСПЁЃдкЮвУЧетИіЪ§ОнМЏжаЕФвђзгБфСПжаЃЌжЛгаНЬг§ЪЧ_ађЪ§БфСП_ЃЌМДЫќЕФРрБ№гавтвхЁЃетжжВтСПЗНЗЈБШCramer's VЛђchi-squareВтСПЗНЗЈИќОпаХЯЂСПЁЃ
GKtauData(cat_variables) plot(dataset)

ПЩвдПДГіЃЌЙигквђБфСПЕФБфвьадЃЌдЄВтвђЫиЕФНтЪЭСІЗЧГЃаЁЁЃЛЛОфЛАЫЕЃЌИљОнGoodmanКЭKruskal's tauЖШСПЃЌЮвУЧЕФдЄВтвђЫиКЭвђБфСПжЎМфМИКѕУЛгаЙиСЊЁЃетПЩвдДгTenYearCHDвЛРИЕФЪ§жЕжаПДГіЁЃ
МйЩшЮвЕФG&KtauМьбще§ШЗЕФЛАЃЌетЖдФЃаЭРДЫЕВЂВЛЪЧвЛИіКУЯћЯЂЁЃ
ЮЊСЫМьбщетаЉЗЂЯжЃЌЮвУЧПЩвдгУChi-squareМьбщРДМьбщЗжРрБфСПгывђБфСПЕФЙиСЊЕФЯджјадЃЌШЛКѓгУPhiЯрЙиЯЕЪ§РДЦРЙРПЩФмЕФЙиСЊЕФЧПЖШЁЃPhiгУгк2x2ЕШжЕБэЁЃЖдгкИќДѓЕФБэИёЃЌМДгаИќЖрВуДЮЕФБфСПЃЌПЩвдРћгУCramer's VЁЃ
chisq.test(table(dataset_cat$p.value ))

phi(matrix(table(dataset\_cat\_variables\[,7\],
ЦцЙжЕФЪЧЃЌЕБChi-squareЕФPжЕШчДЫжЎЕЭЪБЃЌПЩФмЕФЙиСЊЕФЯджјадЮЊСуЁЃетСНИіВтЪдЃЈChi-squareКЭPhiЯрЙиЃЉдкДѓСПЕФЙлВьжаЛљБОЩЯЕУГіЯрЭЌЕФНсЙћЃЌвђЮЊвЛИіЪЧЛљгке§ЬЌЗжВМЕФЃЌСэвЛИіЪЧЛљгкtЗжВМЕФЁЃ
RгябдЫцЛњЩСжRandomForestЁЂТпМЛиЙщLogisitcдЄВтаФдрВЁЪ§ОнКЭПЩЪгЛЏЗжЮіЃЈЯТЃЉЃК/article/1491744
