зМБИЪ§Он
ВЩбљКЏЪ§svsampleашвЊЦфЪфШыЪ§ОнyЪЧЪ§жЕЯђСПЃЌЖјЧвУЛгаШЮКЮШБЪЇжЕЃЈNAЃЉЃЌШчЙћЬсЙЉЦфЫћШЮКЮФкШнЃЌдђЛсБЈДэЁЃдкyАќКЌСуЕФЧщПіЯТЃЌЛсЗЂГіОЏИцЃЌВЂдкНјааИЈжњЛьКЯВЩбљжЎЧАЃЌНЋДѓаЁЮЊsdЃЈyЃЉ/ 10000ЕФаЁЦЋвЦГЃЪ§ЬэМгЕНЦНЗНЪевцЩЯЁЃ
ЕЋЪЧЃЌЮвУЧЭЈГЃНЈвщЭъШЋБмУтСуЪевцЪ§ОнЃЌР§ШчЭЈЙ§дЄЯШНЕЕЭСуЪевцЁЃЯТУцЪЧШчКЮЪЙгУбљБОЪ§ОнМЏНјааЫЕУїЁЃ
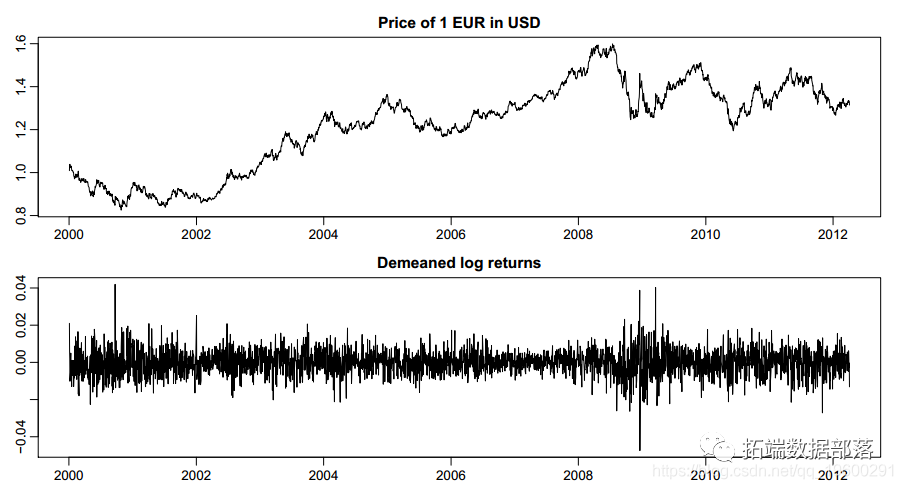
ЭМ1ЬсЙЉСЫИУЪ§ОнМЏжаЪБМфађСаЕФПЩЪгЛЏЁЃ
R> par(mfrow = c(2, 1), mar = c(1.9, 1.9, 1.9, 0.5), mgp = c(2, 0.6, 0)) R> plot(exrates$date, exrates$USD, type = "l", + main = "Price of 1 EUR in USD") R> plot(exrates$date\[-1\], ret, type = "l", main = "Demeaned log returns")
Г§СЫЯжЪЕЪРНчЕФЪ§ОнЭтЃЌЛЙПЩвдЪЙгУФкжУЕФФЃФтЪ§ОнЩњГЩЦїsvsimЁЃДЫКЏЪ§НіЖдSVСїГЬЕФЪЕЯжЃЌВЂЗЕЛиsvsimРрЕФЖдЯѓЃЌИУЖдЯѓОпгаздМКЕФprintЃЌsummaryКЭplotЗНЗЈЁЃ
ЯТУцИјГіСЫЪЙгУsvsimЕФЪОР§ДњТыЃЌИУФЃФтЪЕР§ЯдЪОдкЭМ2жаЁЃ
R> par(mfrow = c(2, 1)) R> plot(sim)

дЫааВЩбљЦї
КЏЪ§svsampleЃЌЫќгУзїCгябджаЪЕМЪВЩбљЦїЕФR-wrapper ЁЃДЫКЏЪ§ЕФЪОР§гУЗЈдкЯТУцЕФДњТыжаЬсЙЉСЫФЌШЯЪфГіЁЃ
Calling GIS_C MCMC sampler with 11000 iter. Series length is 3139. 0% \[+++++++++++++++++++++++++++++++++++++++++++++++++++\] 100% Timing (elapsed): 12.92 seconds. 851 iterations per second. Converting results to coda objects... Done! Summarizing posterior draws... Done!
ПЩвдПДГіЃЌИУКЏЪ§ЕїгУжїMCMCВЩбљЦїВЂНЋЦфЪфГізЊЛЛЮЊгыcodaМцШнЕФЖдЯѓЁЃКѓепЕФЭъГЩжївЊЪЧГігкМцШнадЕФПМТЧЃЌВЂЧвПЩвджБНгЗУЮЪЪеСВеяЖЯМьВщЁЃ
svsampleЕФЗЕЛижЕЪЧsvdrawsРраЭЕФЖдЯѓЃЌИУЖдЯѓЪЧОпгаАЫИідЊЫиЕФУќУћСаБэЃЌЦфжаАќКЌЃЈ1ЃЉВЮЪ§дкparaжаЛцжЦЃЌЃЈ2ЃЉЧБдкЕФЖдЪ§ВЈЖЏТЪЃЌЃЈ3ЃЉГѕЪМЧБдкЕФЖдЪ§ВЈЖЏТЪЛцжЦlatent0ЃЌЃЈ4ЃЉyжаЬсЙЉЕФЪ§ОнЃЌЃЈ5ЃЉдЫааЪБжаЕФВЩбљдЫааЪБЃЌЃЈ6ЃЉЯШбщжаЕФЯШбщГЌВЮЪ§ЃЌЃЈ7ЃЉЯИЛЏЕФВЮЪ§жЕЃЌвдМАЃЈ8ЃЉетаЉЭМЕФЛузмЭГМЦаХЯЂЃЌвдМАвЛаЉГЃМћЕФзЊЛЛЁЃ
ЦРЙРЪфГіВЂЯдЪОНсЙћ
АДееГЃЙцзіЗЈЃЌПЩЪЙгУsvdrawsЖдЯѓЕФprintКЭsummaryЗНЗЈЁЃУПИіВЮЪ§ЖМгаСНИіПЩбЁВЮЪ§showparaКЭshowlatentЃЌгУгкжИЖЈгІЯдЪОЕФЪфГіЁЃШчЙћshowparaЮЊTRUEЃЈФЌШЯЩшжУЃЉЃЌдђЛсЯдЪОВЮЪ§ЛцжЦЕФжЕ/еЊвЊЁЃШчЙћshowlatentЮЊTRUEЃЈФЌШЯжЕЃЉЃЌдђЯдЪОЧБдкБфСПЛцжЦЕФжЕ/еЊвЊЁЃдкЯТУцЕФЪОР§жаЃЌНіЯдЪОВЮЪ§ЛцжЦЕФеЊвЊЁЃ
Summary of 10000 MCMC draws after a burn-in of 1000. Prior distributions: mu ~ Normal(mean = -10, sd = 1) (phi+1)/2 ~ Beta(a0 = 20, b0 = 1.1) sigma^2 ~ 0.1 * Chisq(df = 1) Posterior draws of parameters (thinning = 1): mean sd 5% 50% 95% ESS mu -10.1366 0.22711 -10.4749 -10.1399 -9.7933 4552 phi 0.9935 0.00282 0.9886 0.9938 0.9977 397 sigma 0.0656 0.01001 0.0509 0.0649 0.0830 143 exp(mu/2) 0.0063 0.00075 0.0053 0.0063 0.0075 4552 sigma^2 0.0044 0.00139 0.0026 0.0042 0.0069 143
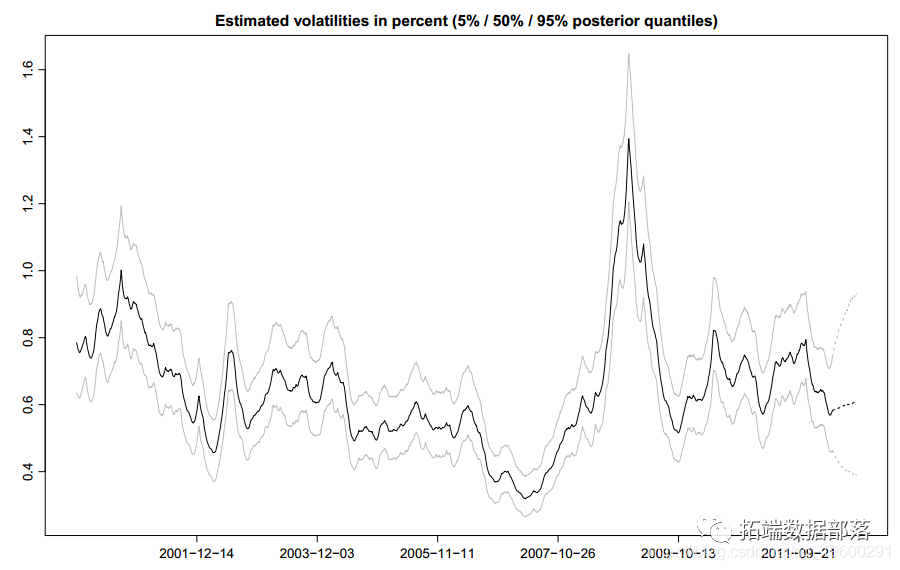
ЃЈ1ЃЉvolplotЃКЛцжЦЧБдкВЈЖЏТЪЕФЗжЮЛЪ§ЃЌвдАйЗжБШБэЪОЃЌМДЫцЪБМфБфЛЏЕФКѓбщЗжВМЕФОбщЗжЮЛЪ§ЁЃГЃгУЕФПЩбЁВЮЪ§АќРЈnВНВЈЖЏТЪЕФдЄВтЃЌxжсЩЯБъЧЉЕФШеЦквдМАвЛаЉЭМаЮВЮЪ§ЁЃЯТУцЕФДњТыЦЌЖЮЯдЪОСЫвЛИіЕфаЭЪОР§ЃЌЭМ3ЯдЪОСЫЦфЪфГіЁЃ
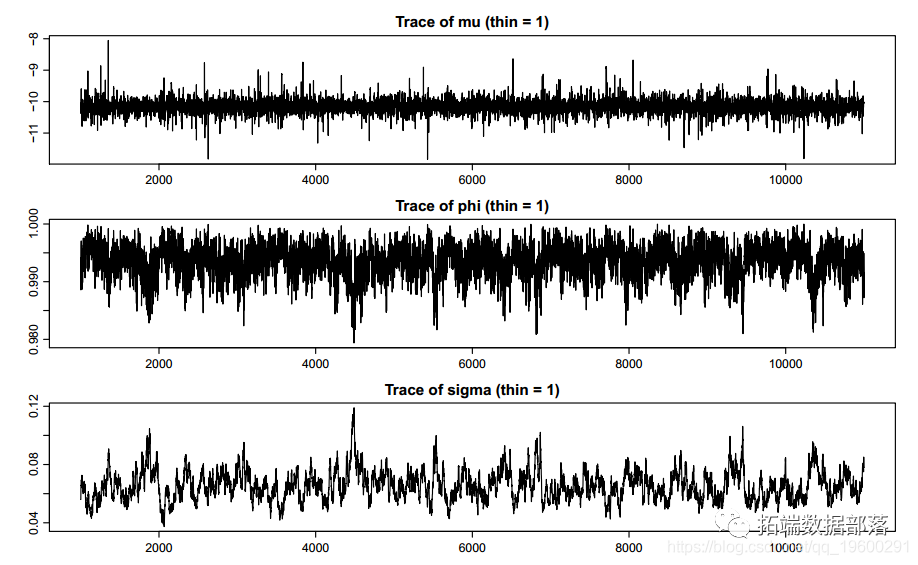
ЃЈ2ЃЉparatraceplotЃКЯдЪОІШжаАќКЌЕФВЮЪ§ЕФЙьМЃЭМЁЃЭМ5ЯдЪОСЫвЛИіЪОР§ЁЃ
ЃЈ3ЃЉparadensplotЃКЯдЪОІШжаАќКЌЕФВЮЪ§ЕФКЫУмЖШЙРМЦЁЃЮЊСЫИќПьЕиЛцжЦНЯДѓЕФКѓбщбљБОЃЌгІНЋДЫВЮЪ§ЩшжУЮЊFALSEЁЃШчЙћВЮЪ§showpriorЮЊTRUEЃЈФЌШЯжЕЃЉЃЌдђЯШбщЗжВМЭЈЙ§ащЯпЛвЩЋЯпжИЪОЁЃЭМ6ЯдЪОСЫДгЛуТЪЬсШЁЪ§ОнМЏжаЛёЕУЕФEUR-USDЛуТЪЕФЪОР§ЪфГіЁЃ
svdrawsЖдЯѓЕФЭЈгУЛцЭМЗНЗЈНЋЩЯЪіЫљгаЭМКЯВЂЁЃПЩвдЪЙгУЩЯЪіЫљгаВЮЪ§ЁЃЧыВЮМћЭМ7ЁЃ
R> plot(res, showobs = FALSE)

ЮЊСЫЬсШЁБъзМЛЏВаВюЃЌПЩвддкИјЖЈЕФsvdrawsЖдЯѓЩЯЪЙгУВаВюЗНЗЈЁЃЪЙгУПЩбЁЕФВЮЪ§РраЭЃЌПЩвджИЖЈеЊвЊЭГМЦЕФРраЭЁЃЕБЧАЃЌРраЭдЪаэЮЊЁАЦНОљжЕЁБЛђЁАжаЮЛЪ§ЁБЃЌЦфжаЧАепЖдгІгкФЌШЯжЕЁЃДЫЗНЗЈЗЕЛиsvresidРрЕФЪЕЯђСПЃЌЦфжаАќКЌУПИіЪБМфЕуЫљЧыЧѓЕФБъзМЛЏВаВюЕФеЊвЊЭГМЦСПЁЃЛЙгавЛжжЛцЭМЗНЗЈЃЌЕБВЮЪ§origdataИјЖЈЪБЃЌЬсЙЉСЫНЋБъзМЛЏВаВюгыдЪМЪ§ОнНјааБШНЯЕФбЁЯюЁЃЧыВЮМћЯТУцЕФДњТыЃЌЖдгкЯргІЕФЪфГіЃЌЧыВЮМћЭМ8ЁЃ

