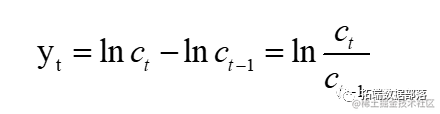ЛвЩЋЙиСЊЗжЮіАќРЈСНИіживЊЙІФмЁЃ
ЕквЛЯюЙІФмЃКЛвЩЋЙиСЊЖШЃЌгыcorrelationЯЕЪ§ЯрЫЦЃЌШчЙћвЊЦРЙРФГаЉЕЅЮЛЃЌдкЪЙгУДЫЙІФмжЎЧАзЊжУЪ§ОнЁЃЕкЖўИіЙІФмЃКЛвЩЋОлРрЃЌШчВуДЮОлРрЁЃ
ЛвЩЋЙиСЊЖШ
ЛвЩЋЙиСЊЖШгаСНжжгУЗЈЁЃИУЫуЗЈгУгкВтСПСНИіБфСПЕФЯрЫЦадЃЌОЭЯё`cor`вЛбљЁЃШчЙћвЊЦРЙРФГаЉЕЅЮЛЃЌПЩвдзЊжУЪ§ОнМЏЁЃ
*вЛжжЪЧМьВщСНИіБфСПЕФЯрЙиадЃЌЪ§ОнРраЭШчЯТЃК
| ВЮПМ| v1 | v2 | v3 |
| ----------- |||| ---- | ---- |
| 1.2 | 1.8 | 0.9 | 8.4 |
| 0.11 | 0.3 | 0.5 | 0.2 |
| 1.3 | 0.7 | 0.12 | 0.98 |
| 1.9 | 1.09 | 2.8 | 0.99 |
referenceЃКВЮПМБфСПЃЌreferenceКЭv1жЎМфЕФЛвЩЋЙиСЊЖШ...НќЫЦЕиВтСПreferenceКЭv1ЕФЯрЫЦЖШЁЃ
*СэвЛИіЪЧЦРЙРФГаЉЕЅЮЛЕФКУЛЕЁЃ
| ЕЅЮЛ| v1 | v2 | v3 |
| ----------- |||| ---- | ---- |
| НЫе| 1.8 | 0.9 | 8.4 |
| еуН| 0.3 | 0.5 | 0.2 |
| АВЛе 0.7 | 0.12 | 0.98 |
| ИЃНЈ| 1.09 | 2.8 | 0.99 |
ЪОР§
##ЩњГЩЪ§Он #' economyCompare = data.frame(refer, liaoning, shandong, jiangsu, zhejiang, fujian, guangdong) # # вьГЃПижЦ # if (any(is.na(df))) stop("'df' have NA" ) if (distingCoeff<0 | distingCoeff>1) stop("'distingCoeff' must be in range of [0,1]" ) diff = X #ЩшжУВюбЇСаОиеѓПеМф for (i in mx = max(diff) #МЦЫуЙиСЊЯЕЪ§# relations = (mi+distingCoeff*mx) / (diff + distingCoeff*mx) #МЦЫуЙиСЊЖШ# # днЪБМђЕЅДІРэ, ЕШШЈ relDegree = rep(NA, nc) for (i in 1:nc) { relDegree[i] = mean(relations[,i]) # ЕШШЈ } #ХХађ: АДЙиСЊЖШДѓЕНаЁ# X_order = X[order(relDegree, relDes = rep(NA, nc) #ЗжХфПеМф ЙиСЊЙиЯЕУшЪі(ЫЕУїЫКЭЫЕФЙиСЊЖШ) X_names = names(X_o names(relationalDegree) = relDes if (cluster) { greyRelDegree = GRA(economyC # ЕУЕНВювьТЪОиеѓ # grey_diff = matrix(0 grey_diff[i,j] = abs(rel #ЕУЕНОрРыОиеѓ# grey_dist = matrix(0, nrow iff[i,j]+grey_diff[j,i] } } # ЕУЕНЛвЩЋЯрЙиЯЕЪ§Оиеѓ # grey_dist_max = max(grey_dist) grey_correl = matrix(0, nrow = nc, ncol = nc) for (i in 1:nc) { for (j in 1:nc) { grey_correl[i,j] = 1 - grey_dist[i,j] / grey_dist_max } } d = as.dist(1-grey_correl) # ЕУЕНЮоЖдНЧЯпЕФЯТШ§НЧОиеѓ(Ъ§жЕвтвхЗДЯђСЫ, жЕдНаЁБэЪОдНЯрЙи ) # жїЖдНЧЯпЦфЪЕБэЪОСЫИїИіЖдЯѓЕФЯрНќГЬЖШ, ЛЭМЕФЪБКђ, ЯрНќЕФЖдЯѓЗХдквЛЦ№ hc = hclust(d, method = clusterMethod) # ЯЕЭГОлРр(ЗжВуОлРр)КЏЪ§, single: ЕЅвЛСЌНг(зюЖЬОрРыЗЈ/зюНќСк) # hc$height, ЪЧЩЯУцОиеѓЕФЖдНЧдЊЫиЩ§ађ # hc$order, ВуДЮЪїЭМЩЯКсжсИіЬхађКХ plot(hc,hang=-1) #hang: ЩшжУБъЧЉаќЙвЮЛжУ } #ЪфГі# if (cluster) { lst = list(relationalDegree=relationalDegree, return(lst) } ``` ```{r} ## ЩњГЩЪ§Он rownames(economyCompare) = c("indGV", "indVA", "profit", "incomeTax") ## ЛвЩЋЙиСЊЖШ greyRelDegree = greya(economyCompare) greyRelDegree ```
ЛвЩЋЙиСЊЖШ


ЛвЩЋОлРрЃЌШчВуДЮОлРр
## ЛвЩЋОлРр greya(economyCompare, cluster = T)