дЮФСДНг:http://tecdat.cn/?p=27515
НЈСЂжиЧьЪаОМУжИБъЗЂеЙЬхЯЕЃЌвджиЧьЪавЛаЁЪБОМУШІзїЮЊбљБОЃЌдЫгУвђзгЗжЮіЗНЗЈНјааЪЕжЄЗжЮіЃЌдкНшМјСЫЯрЙиЦРМлРэТлКЭЦРМлЗНЗЈЕФЛљДЁЩЯЃЌБОЮФЬсШЁГіОМУЙцФЃЁЂШЫОљЗЂеЙЫЎЦНЁЂОМУЗЂеЙЧБСІЁЂ3ИіжївђзгЃЌДгжиЧьЪаЭГМЦФъМјбЁШЁ8ИіжИБъЙЙГЩЕФжИБъЬхЯЕЪ§ОнЃЈВщПДЮФФЉСЫНтЪ§ОнЛёШЁЗНЪНЃЉЖджиЧьЪа38ИіЧјЯиОМУЗЂеЙЛљБОЧщПіЕФАЫЯюжИБъНјааЗжЮіЃЌВЂЛљгкжївђзгЕУЗжОиеѓЖджиЧьЪа38ИіЧјЯиНјааОлРрЗжЮіЁЃ
НсЙћБэУїЃКИљОнзлКЯЕУЗжЃЌПЩвдПДГіИїЧјЯиЩчЛсОМУЗЂеЙЫЎЦНХХЧАШ§ЕФЪЧгхжаЧјЁЂгхББЧјЁЂОХСњЦТЧјЃЌЕУЗжзюЕЭЕФШ§ИіЪЧЮзЩНЯиЁЂЮзЯЊЯиЁЂГЧПкЯиЃЌНсКЯзмЬхЕФЗжЮіПЩвдПДГігхжаЧјЁЂОХСњЦТЧјдкОМУзмЬхЙцФЃКЭНЈжўвЕЗНУцНЯКУЃЌЖјжиЧьжмБпЕФЕиЧјОМУЪЕСІНЯВюЃЌЭЖзЪЛЗОГВЛКУЃЌЬиБ№ЪЧдкНЈжўЗНУцЕФШБЗІЃЌвджСгкОМУЗЂеЙЯрЖдЖјбдБЁШѕЕФЕиЧјЃЌВЛТлДгФФЗНУцРДЫЕжиЧьИїЧјЯижагхжаЧјЕФОМУЪЕСІЪЧзюКУЕФЁЃ
ЦРМлжИБъЕФНЈСЂ
ЦРМлЕиЧјЕФжЎМфЕФОМУЗЂеЙЫЎЦНЃЌБиаыНЈСЂЪЪЕБЕФжИБъЬхЯЕЁЃПМТЧЕНЕиЧјОМУжИБъЕФИДдгадЁЂЖрбљадКЭПЩВйзїадЃЌБОЮФдкДЫЛљДЁЩЯНЈСЂСЫвЛЬзНЯЮЊЭъећЕФвзгкЖЈСПЗжЮіЕФЕиЧјОМУЦРМлжИБъЬхЯЕЃЌЗжБ№ДгВЛЭЌЕФНЧЖШЗДгГЕиЧјОМУЗЂеЙЬиеїЁЃ
БОЮФЫљНЈСЂЕФжИБъЬхЯЕЙВАќРЈ8ИіжИБъЃЌЗжБ№ДгОМУЙцФЃЁЂШЫОљЗЂеЙЫЎЦНЁЂОМУЗЂеЙЧБСІЕШЗНУцРДЗДгГЕиЧјОМУЗЂеЙЬиеїЁЃОпЬхжИБъШчЯТЃК
ЕиЧјЩњВњзмжЕЃЈЭђдЊЃЉЃЈX1ЃЉ
ЩчЛсЯћЗбЦЗСуЪлзмЖюЃЈЭђдЊЃЉЃЈX2ЃЉ
ЙЄвЕзмВњжЕЃЈЭђдЊЃЉ(X3)
НЈжўвЕзмВњжЕЃЈЭђдЊЃЉ(X4)
ИпММЪѕЩњВњзмжЕЃЈЭђдЊЃЉЃЈX5ЃЉ
ШЋЩчЛсЙЬЖЈзЪВњЭЖзЪЃЈЭђдЊЃЉЃЈX6)
ШЫОљПЩжЇХфЪеШыЃЈдЊЃЉЃЈX7ЃЉ
ШЫОљЕиЧјЩњВњзмжЕЃЈдЊЃЉ(X8)
вђзгЗжЮідкЕиЧјОМУбаОПжаЕФгІгУ
вђзгЗжЮіФЃаЭМАЦфВНжш
вђзгЗжЮіЪЧвЛжжЪ§ОнМђЛЏЕФММЪѕЁЃЫќЭЈЙ§баОПжкЖрБфСПжЎМфЕФФкВПвРРЕЙиЯЕЃЌЬНЧѓЙлВтЪ§ОнжаЕФЛљБОНсЙЙЃЌВЂгУЩйЪ§МИИіМйЯыБфСПРДБэЪОЦфЛљБОЕФЪ§ОнНсЙЙЁЃетМИИіМйЯыБфСПФмЙЛЗДгГдРДжкЖрБфСПЕФжївЊаХЯЂЁЃдЪМЕФБфСПЪЧПЩЙлВтЕФЯддкБфСПЃЌЖјМйЯыБфСПЪЧВЛПЩЙлВтЕФЧБдкБфСПЃЌГЦЮЊвђзгЁЃЩшpИіБфСПЃЌдђвђзгЗжЮіЕФЪ§бЇФЃаЭПЩБэЪОЮЊЃК
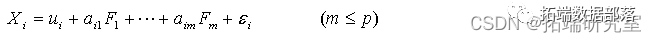
ГЦ  ЮЊЙЋЙВвђзгЃЌЪЧВЛПЩЙлВтЕФБфСПЃЌЫћУЧЕФЯЕЪ§ГЦЮЊвђзгдиКЩЁЃЪЧЬиЪтвђзгЃЌЪЧВЛФмБЛЧАmИіЙЋЙВвђзгАќКЌЕФВПЗжЁЃвђзгЗжЮіВНжшШчЯТЃК
ЮЊЙЋЙВвђзгЃЌЪЧВЛПЩЙлВтЕФБфСПЃЌЫћУЧЕФЯЕЪ§ГЦЮЊвђзгдиКЩЁЃЪЧЬиЪтвђзгЃЌЪЧВЛФмБЛЧАmИіЙЋЙВвђзгАќКЌЕФВПЗжЁЃвђзгЗжЮіВНжшШчЯТЃК
ЃЈ1ЃЉНЋдЪМЪ§ОнБъзМЛЏЃЌШдМЧЮЊXЃЛЃЈ2ЃЉНЈСЂЯрЙиЯЕЪ§ОиеѓRЃЛЃЈ3ЃЉНтЬиеїЗНГЬЃЌМЦЫуЬиеїжЕКЭЬиеїЯђСПЃЌЕБРлМЦЙБЯзТЪВЛЕЭгк85%ЪБЃЌЬсШЁkИіжїГЩЗжДњЬцдРДЕФmИіжИБъЃЌМЦЫувђзгдиКЩОиеѓAЃЛЃЈ4ЃЉЖдAНјаазюДѓе§НЛа§зЊНЛЛЛЃЛЃЈ5ЃЉЖджївђзгНјааУќУћКЭНтЪЭЁЃШчашНјааХХађЃЌдђМЦЫуИїИіжївђзгЕФЕУЗжЃЌвдЙБЯзТЪЮЊШЈжиЃЌЖдМгШЈМЦЫузлКЯвђзгЕУЗжЁЃ
бљБОбЁШЁМАЪ§ОнРДдД
БОЮФбЁШЁСЫжиЧьЪа38ИіЧјЯизїЮЊбљБОНјааЗжЮіЃЌФПЕФдкгкЬНЫїШчКЮЛљгкRЭГМЦШэМўЕФвђзгЗжЮіКЭОлРрЗжЮіЗНЗЈбаОПЕиЧјОМУЗЂеЙЁЃОпЬхЪ§ОнШчЯТЃК

Ъ§ОнЗжЮіЙ§ГЬ
НЋдЪМЪ§ОнТМШыRШэМўжаЃЌбЁШЁЕиЧјЩњВњзмжЕЃЈЭђдЊЃЉЃЈX1ЃЉЁЂЩчЛсЯћЗбЦЗСуЪлзмЖюЃЈЭђдЊЃЉЃЈX2ЃЉЁЂЙЄвЕзмВњжЕЃЈЭђдЊЃЉ(X3ЃЉЁЂНЈжўвЕзмВњжЕЃЈЭђдЊЃЉ(X4)ЁЂИпММЪѕЩњВњзмжЕЃЈЭђдЊЃЉЃЈX5ЃЉЁЂШЋЩчЛсЙЬЖЈзЪВњЭЖзЪЃЈЭђдЊЃЉЃЈX6)ЁЂШЫОљПЩжЇХфЪеШыЃЈдЊЃЉЃЈX7ЃЉЁЂШЫОљЕиЧјЩњВњзмжЕЃЈдЊЃЉ(X8)ЁЃ
дкНјаавђзгЗжЮіжЎЧАЃЌЮвУЧЭЈЙ§ЙлВьЯрЙиЯЕЪ§ОиеѓЃЌВЂгУKMO and BartlettЁЏs TestМьбщвЛЯТЪ§ОнЪЧЗёЪЪКЯзївђзгЗжЮіЁЃдйзіУшЪіадЗжЮіAnalysis-factor-descriptionЕУЕНГѕЪМЙЋвђзгЗНВюЁЂвђзгЁЂЬиеїжЕвдМАгЩУПИівђзгНтЪЭЕФАйЗжБШКЭРлМЦАйЗжБШЁЃЗжЮіНсЙћШчЯТЃК
coebaltt(COR,)#BartlettЧђаЮМь

Bartlett ЕФЧђаЮЖШМьбщЕФpжЕЃЈЯджјадИХТЪжЕsigЃЉ<0.05ЃЌБэУїЭЈЙ§МьбщЃЌЗжВМПЩвдНќЫЦЮЊе§ЬЌЗжВМЃЌгЩДЫдђПЩвдНјаавђзгЗжЮіЁЃ
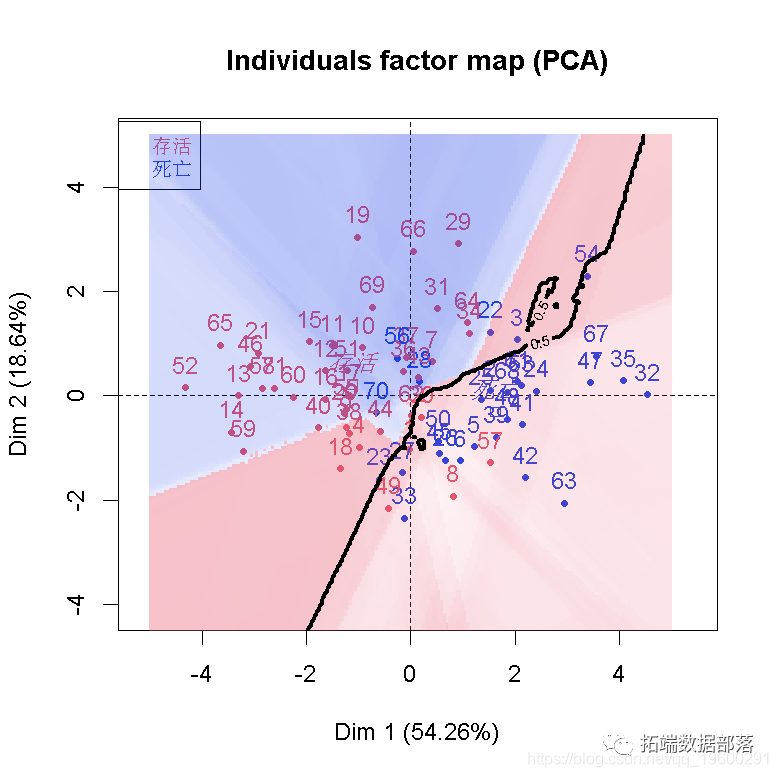
sreeot(PCA,type="lines")



ЕуЛїБъЬтВщдФЭљЦкФкШн

Ъ§ОнЗжЯэ|RгябдгУжїГЩЗжPCAЁЂ ТпМЛиЙщЁЂОіВпЪїЁЂЫцЛњЩСжЗжЮіаФдрВЁЪ§ОнВЂИпЮЌПЩЪгЛЏ
01
02

03

04

ДгБэПЩвдЕУГіЃЌЬсШЁ3ИівђзгЕФРлМЦЗНВюЙБЯзТЪвбОДяЕН89.854%>86%ЃЌаХЯЂЫ№ЪЇНіЮЊ10.146%ЃЌДгЕк4ИівђзгПЊЪМЗНВюЙБЯзТЪЖМЕЭгк5%ЃЌвђДЫбЁШЁ3ИіЙЋвђзгНјаавђзгЗжЮіаЇЙћНЯЮЊРэЯыЃЛДгЭМЕФЫщЪЏЭМПЩвдПДГіДгЕк4ИівђзгПЊЪМЃЌЬиеїжЕВювьБфЛЏКмаЁЃЌзлЩЯЫљЪіЃКдкЬиеїжЕДѓгк0.5ЕФЬѕМўЯТЃЌЫљЬсШЁЕФШ§ИівђзгФмЭЈЙ§МьбщВЂФмКмКУЕФУшЪі8ИіжИБъЃЌЫљвдЬсШЁЧА3ИіЬиеїжЕНЈСЂвђзгдиКЩОиеѓЁЃ
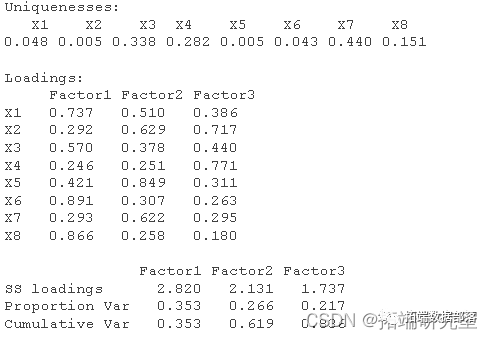
БэжаЮЊГѕЪМвђзгдиКЩОиеѓБэЃЌ F1ЁЂF2ЁЂF3ЗжБ№зїЮЊЕквЛЁЂЕкЖўЁЂЕкШ§ЙЋЙВвђзгЁЃНЈСЂСЫвђзгЗжЮіЪ§бЇФПЕФВЛНіНівЊевГіЙЋЙВвђзгвдМАЖдБфСПНјааЗжзщЃЌИќживЊЕФвЊжЊЕРУПИіЙЋЙВвђзгЕФвтвхЃЌвдБуНјааНјвЛВНЕФЗжЮіЃЌШчЙћУПИіЙЋЙВвђзгЕФКЌвхВЛЧхЃЌдђВЛБугкНјааЪЕМЪБГОАЕФНтЪЭЁЃгЩгквђзгдиКЩеѓЪЧВЛЮЈвЛЕФЃЌЫљвдгІИУЖдвђзгдиКЩеѓНјааа§зЊЁЃФПЕФЪЧЪЙвђзгдиКЩеѓЕФНсЙЙМђЛЏЃЌЪЙдиКЩОиеѓУПСаЛђааЕФдЊЫиЦНЗНжЕЯђ0КЭ1СНМЋЗжЛЏЁЃгаШ§жжжївЊЕФе§НЛа§зЊЗЈЁЃЫФДЮЗНзюДѓЗЈЁЂЗНВюзюДѓЗЈКЭЕШСПзюДѓЗЈЁЃ
вђДЫашЧѓНјаавђзга§зЊЃЌЪЙЕУвђзгЖдБфСПЕФЙБЯзДяЕНМЋЛЏЕФаЇЙћЁЃЮЊДЫВЩгУЗНВюзюДѓЛЏЕФе§НЛа§зЊЗНЪНЃЌЪЙИїБфСПдкФГИівђзгЩЯВњЩњНЯИпдиКЩЃЌЖјЦфгрвђзгЩЯдиКЩНЯаЁЃЌДгЖјЕУЕНа§зЊКѓЕФвђзгдиКЩОиеѓЃЌШчЯТБэЫљЪОЃК

гЩБэКЭа§зЊКѓЕФвђзгЭМПЩвдПДГіЃЌЭЈЙ§а§зЊКѓЕФЙЋЙВвђзгЕФНтЪЭдЪМЪ§ОнЕФФмСІЬсИпСЫЃЌБэЯжЮЊЙЋЙВвђзгF1дкX1(ЕиЧјЩњВњзмжЕ)ЃЌX6ЃЈШЋЩчЛсЙЬЖЈзЪВњЭЖзЪЃЉКЭX8ЃЈШЫОљЕиЧјЩњВњзмжЕЃЉЩЯЕФдиКЩжЕЖМКмДѓЁЃвђДЫЮвУЧПЩвдАбЕквЛЙЋЙВвђзгШЗСЂЮЊзлКЯОМУЪЕСІвђзгЃЌКъЙлЩЯЗДгГСЫЕиЧјОМУЗЂеЙЙцФЃЕФзмЬхЧщПіЃЌдкетИівђзгЩЯЕФЕУЗждНИпЃЌЫЕУїГЧЪаОМУЗЂеЙЕФзмЬхЧщПідНКУЁЃ
РћгУИїЙЋЙВвђзгЗНВюЙБЯзТЪМЦЫузлКЯЕУЗжЃЌВЂМЦЫузлКЯЕУЗж=вђзг1ЕФЗНВюЙБЯзТЪвђзг1ЕФЕУЗж+вђзг2ЕФЗНВюЙБЯзТЪвђзг2ЕФЕУЗж+вђзг3ЕФЗНВюЙБЯзТЪ*вђзг3ЕФЕУЗжЁЃНЋЪ§ОнАДзлКЯЕУЗжНЕађХХСаЃЌЕУЕНВПЗжвђзгЕУЗжКЭзлКЯЕУЗжЧщПіШчЯТЭМЫљЪОЃК



НсЙћЬжТл
ЛљгкЩЯЪівђзгЕУЗжЃЌПЩвдЕУГі2012ФъжиЧь38ИіЧјЯиЕФОМУЗЂеЙзДПіШчЯТЃК
1ЁЂИљОнОМУЪЕСІвђзгF1ЕУЗжДѓгк1ЕФвРДЮгагхжаЧјЁЂгхББЧјЁЂОХСњЦТЧјЁЂНББЧјКЭЭђжнЧјЃЌЗжЪ§ЗжБ№ЮЊ4.4211ЁЂ1.8967ЁЂ1.7808ЁЂ1.201ЁЂ1.2804ЁЃЫЕУїдкОМУзмЬхЙцФЃКЭНЈжўвЕЗНУцЃЌгхжаЧјЁЂгхББЧјЁЂОХСњЦТЁЂНББЧјКЭЭђжнЧјдкжиЧьЪаЕФ38ИіЧјЯижаЪЧзюКУЕФЃЌЙцФЃНЯДѓЃЌОМУЪЕСІзюЧПЃЌЗЂеЙЧАОАКмКУЃЌОМУЗЂеЙЪЕСІалКёЕФЕиЧјЁЃ
2ЁЂИљОнОМУЗЂеЙЧБСІвђзгF2ЕУЗжДѓгк1ЕФгаЩГЦКАгЧјКЭгхББЧјЃЌЗжЪ§ЗжБ№ЮЊ3.7052ЁЂ3.4396ЁЃЫЕУїдкИпММЪѕПЦММКЭЙЄвЕЗНУцБШНЯЗЂДяЃЌЙЬЖЈзЪВњЭЖзЪзюДѓЃЌетСНИіЕиЧјЖМдкжїГЧЃЌЖдЭтПЊЗХГЬЖШИпЃЌПЦММДДаТЗНУцБШНЯКУЃЌгаздМКЕФЙЄвЕЗЂеЙЃЌвбЛљБОаЮГЩСЫздМКЕФВњвЕНсЙЙЃЌГфЗжЗЂЛгСЫздМКЕФЕиРэгХЪЦКЭзЪдДЛЗОГгХЪЦЃЌЗЂеЙЧБСІНЯДѓЁЃ
ЛљгкжївђзгЕУЗжЕФОлРрЗжЮі
ЯЕЭГОлРрЗжЮі
ОлРрЗжЮігжГЦШКЗжЮіЃЌОЭЪЧНЋЪ§ОнЗжзщГЩЮЊЖрИіРрЁЃдкЭЌвЛИіРрФкЖдЯѓжЎМфОпгаНЯИпЕФЯрЫЦЖШЃЌВЛЭЌРржЎМфЕФЖдЯѓВюБ№НЯДѓЁЃдкЩчЛсОМУСьгђжаДцдкзХДѓСПЗжРрЮЪЬтЃЌБШШчШєЖдФГаЉДѓГЧЪаЕФЮяМлжИЪ§НјааПМВьЃЌЖјЮяМлжИЪ§КмЖрЃЌгаХЉгУЩњВњЮяМлжИЪ§ЁЂЗўЮёЯюФПМлжИЪ§ЁЂЪГЦЗЯћЗбЮяМлжИЪ§ЁЂНЈВФСуЪлМлИёжИЪ§ЕШЕШЁЃгЩгквЊПМВьЕФЮяМлжИЪ§КмЖрЃЌЭЈГЃЯШЖдетаЉЮяМлжИЪ§НјааЗжРрЁЃзмжЎЃЌашвЊЗжРрЕФЮЪЬтКмЖрЃЌвђДЫОлРрЗжЮіетИігагУЕФЙЄОпдНРДдНЪмЕНШЫУЧЕФжиЪгЃЌЫќдкаэЖрСьгђжаЖМЕУЕНСЫЙуЗКЕФгІгУЁЃ
ОлРрЗжЮіФкШнЗЧГЃЗсИЛЃЌгаЯЕЭГОлРрЗЈЁЂгаађбљЦЗОлРрЗЈЁЂЖЏЬЌОлРрЗЈЁЂФЃК§ОлРрЗЈЁЂЭМТлОлРрЗЈЁЂОлРрдЄБЈЗЈЕШЃЛзюГЃгУзюГЩЙІЕФОлРрЗжЮіЮЊЯЕЭГОлРрЗЈЃЌЯЕЭГОлРрЗЈЕФЛљБОЫМЯыЮЊЯШНЋnИібљЦЗИїздПДГЩвЛРрЃЌШЛКѓЙцЖЈбљЦЗжЎМфЕФЁАОрРыЁБКЭРргыРржЎМфЕФОрРыЁЃбЁдёОрРызюНќЕФСНРрКЯВЂГЩвЛИіаТРрЃЌМЦЫуаТРрКЭЦфЫћРрЃЈИїЕБЧАРрЃЉЕФОрРыЃЌдйНЋОрРызюНќЕФСНРрКЯВЂЁЃетбљЃЌУПДЮКЯВЂМѕЩйвЛРрЃЌжБжСЫљгаЕФбљЦЗЖМЙщГЩвЛРрЮЊжЙЁЃ
ЯЕЭГОлРрЗЈЕФЛљБОВНжшЃК
1ЁЂМЦЫуnИібљЦЗСНСНМфЕФОрРыЁЃ
2ЁЂЙЙдьnИіРрЃЌУПИіРржЛАќКЌвЛИібљЦЗЁЃ
3ЁЂКЯВЂОрРызюНќЕФСНРрЮЊвЛаТРрЁЃ
4ЁЂМЦЫуаТРргыИїЕБЧАРрЕФОрРыЁЃ
5ЁЂжиИДВНжш3ЁЂ4ЃЌКЯВЂОрРызюНќЕФСНРрЮЊаТРрЃЌжБЕНЫљгаЕФРрВЂЮЊвЛРрЮЊжЙЁЃ
6ЁЂЛОлРрЦзЯЕЭМЁЃ
7ЁЂОіЖЈРрЕФИіЪ§КЭРрЁЃ
ЯЕЭГОлРрЗНЗЈЃК1ЁЂзюЖЬОрРыЗЈЃЛ2ЁЂзюГЄОрРыЗЈЃЛ3ЁЂжаМфОрРыЗЈЃЛ4ЁЂжиаФЗЈЃЛ5ЁЂРрЦНОљЗЈЃЛ6ЁЂРыВюЦНЗНКЭЗЈЃЈWardЗЈЃЉЁЃ
ЛљгкжївђзгЕУЗжЖджиЧьЪа38ИіЧјЯиОМУЗЂеЙЗжЮіЃЌВЩгУОлРрЗНЗЈбЁдёзщМфСДНгЗЈ,МЦЫуОрРыбЁдёЦНЗНХЗЪНОрРы,БъзМЛЏЪ§ОнВХгУБъзМе§ЬЋЪ§ОнЛЏДІРэЁЃЕУЕНШчЯТНсЙћЃК
rct.st(hc,k = 6, border = "red")

гЩЪїзДЭМПЩжЊЃЌПЩвдНЋжиЧьИїЧјЯиАДОМУжаКЭЪЕСІЪЕМЪЧщПіЗжЮЊСљРрЃК
ЕквЛРржЛАќРЈгхжаЧјЃЌгхжаЧјЪЧжиЧьЪаЕФжааФГЧЪа,ЪЧжиЧьЪаЕФеўжЮОМУЮФЛЏжааФЁЂЛљДЁНЬг§ИпЕиЁЂОпгаЬиЪтЕФЧјЮЛгХЪЦКЭЭЛГіЕФеНТдЕиЮЛЁЃВњвЕНсЙЙЕФЯжзДЬиеїЪЧЕкШ§ВњвЕеМОјЖдгХЪЦ,ЦфжаН№ШквЕЁЂЩЬУГвЕвдМАжаНщЗўЮёвЕЮЊжїЕМаавЕ,ЪєгкОМУЗЂеЙЪЕСІалКёЕФЕиЧјЁЃ
ЕкЖўРржЛАќРЈгхББЧјЃЌгхББЧјЯШКѓЦєЖЏСЫзмЬхЙцЛЎНќ65ЦНЗНЙЋРяЕФжиЧьПЦММВњвЕдАЁЂжиЧьЯжДњХЉвЕдАЧјЁЂгхЖЋПЊЗЂЧјЕШЯюФПЃЌБЛЪаеўИЎУќУћЮЊ"жиЧьХЉвЕПЦММдАЧј"ЃЌЫљвдИУЕиЧјдкИпММЪѕЩњВњзмжЕЙБЯзКмДѓЃЌЖјЧвЭЖзЪЛЗОГгХдНЃЌЧвДѓВПЗжЕиЧјгаИіздМКжааФЩЬвЕЕиДјЃЌЖдЭтПЊЗХГЬЖШИпЃЌЧјЮЛгХЪЦКмУїЯдЃЌВњвЕНсЙЙКЯРэЃЌЪєгкОМУЗЂеЙНЯЧПЕФЕиЧјЁЃ
