змРР
БОЮФМђвЊНщЩмСЫвЛжжМђЕЅЕФзДЬЌЧаЛЛФЃаЭЃЌИУФЃаЭЙЙГЩСЫвўТэЖћПЩЗђФЃаЭЃЈHMMЃЉЕФЬиР§ЁЃетаЉФЃаЭЪЪгІЪБМфађСаЪ§ОнжаЕФЗЧЦНЮШадЁЃДггІгУЕФНЧЖШРДПДЃЌетаЉФЃаЭдкЦРЙРОМУ/ЪаГЁзДЬЌЪБЗЧГЃгагУЁЃетРяЕФЬжТлжївЊЮЇШЦЪЙгУетаЉФЃаЭЕФПЦбЇадЁЃ
ЛљБОАИР§
HMMЕФжївЊЬєеНЪЧдЄВтвўВиВПЗжЁЃЮвУЧШчКЮЪЖБ№ЁАВЛПЩЙлВьЁБЕФЪТЮяЃПHMMЕФЯыЗЈЪЧДгПЩЙлВьЕФЪТЮяРДдЄВтЧБдкЕФЪТЮяЁЃ
ФЃФтЪ§Он
ЮЊСЫбнЪОЃЌЮвУЧзМБИвЛаЉЪ§ОнВЂГЂЪдНјааЗДЯђЭЦВтЁЃЭЈЙ§ЙЙдьЃЌЮвЧПМгСЫвЛаЉМйЩшРДДДНЈЮвУЧЕФЪ§ОнЁЃУПИізДЬЌЖМОпгаВЛЭЌЕФОљжЕКЭВЈЖЏТЪЁЃ
library(knitr) library(kableExtra) library(dplyr) theta_v <- data.frame(t(c(2.00,-2.00,1.00,2.00,0.95,0.85))) names(theta_v) <- c("$\\mu_1$","$\\mu_2$","$\\sigma_1$","$\\sigma_2$","$p_{11}$","$p_{22}$") kable(theta_v, "html", booktabs = F,escape = F) %>% kable_styling(position = "center")
| mu_1 | mu_2 | sigma_1 | sigma_2 | p_ {11} | p_ {22} |
| 2 | -2 | 1Иі | 2 | 0.95 | 0.85 |
ШчЩЯБэЫљЪОЃЌзДЬЌ\ЃЈs = 2 \ЃЉБфГЩЁАЛЕЁБзДЬЌЃЌЦфжаЙ§ГЬ\ЃЈx_t \ЃЉБэЯжГіНЯИпЕФБфЛЏадЁЃ вђДЫЃЌЭЃСєдкзДЬЌ2ЕФПЩФмБШЭЃСєдкзДЬЌ1ЕФПЩФмадаЁЁЃ
ТэЖћПЩЗђЙ§ГЬ
ЮЊСЫФЃФтЙ§ГЬ\ЃЈx_t \ЃЉЃЌЮвУЧДгФЃФтТэЖћПЩЗђЙ§ГЬ\ЃЈs_t \ЃЉПЊЪМЁЃЮЊСЫФЃФт\ЃЈT \ЃЉЦкМфЕФЙ§ГЬЃЌЪзЯШЃЌЮвУЧашвЊЙЙНЈИјЖЈ\ЃЈp_ {11} \ЃЉКЭ\ЃЈp_ {22} \ЃЉЕФзЊЛЛОиеѓЁЃЦфДЮЃЌЮвУЧашвЊДгИјЖЈзДЬЌ\ЃЈs_1 = 1 \ЃЉПЊЪМЁЃДг\ЃЈs_1 = 1 \ЃЉПЊЪМЃЌЮвУЧжЊЕРга95ЃЅЕФИХТЪЭЃСєдкзДЬЌ1ЃЌга5ЃЅЕФИХТЪНјШызДЬЌ2ЁЃ
p11 <- theta_v[1,5] p22 <- theta_v[1,6] P <- matrix(c(p11,1-p22,1-p11,p22),2,2) P[1,] ## [1] 0.95 0.05
ФЃФт\ЃЈs_t \ЃЉЪЧЕнЙщЕФЃЌвђЮЊЫќЯШЧАЯШЧАЕФзДЬЌЁЃвђДЫЃЌЮвУЧашвЊЙЙдьвЛИібЛЗЃК
set.seed(13) T_end <- 10^2 s0 <- 1 st <- function(i) sample(1:2,1,prob = P[i,]) s <- st(s0) for(t in 2:T_end) { s <- c(s,st(s[t-1])) } plot(s, pch = 20,cex = 0.5)

ЩЯЭМЫЕУїСЫЙ§ГЬ\ЃЈs_t \ЃЉЕФГжОУадЁЃдкДѓЖрЪ§ЧщПіЯТЃЌзДЬЌ1ЕФЁАЪЕЯжЁБЖргкзДЬЌ2ЁЃЪЕМЪЩЯЃЌетПЩвдгЩЙЬЖЈИХТЪШЗЖЈЃЌИУЙЬЖЈИХТЪгЩЯТЪНБэЪОЃК
P_stat[1,] ## [1] 0.75 0.25
вђДЫЃЌОРњЪБМфЕФСїЪХЃЌга15ЃЅЕФИХТЪДІгк1зДЬЌЃЌЖјга25ЃЅЕФИХТЪДІгкзДЬЌ2ЁЃетгІИУЗДгГдкФЃФтЙ§ГЬжа sЃЌДгЖј
mean(s==1 )## [1] 0.69
гЩгкЮвУЧЪЙгУЕФЪЧ100ИіжмЦкЕФаЁбљБОЃЌвђДЫЮвУЧЙлВьЕНЮШЖЈИХТЪЮЊ69ЃЅЃЌНгНќЕЋВЛЭъШЋЕШгк75ЃЅЁЃ
НсЙћ
ИјЖЈФЃФтЕФТэЖћПЩЗђЙ§ГЬЃЌНсЙћЙ§ГЬЕФФЃФтЗЧГЃМђЕЅЁЃвЛИіМђЕЅЕФММЧЩЪЧФЃФт\ЃЈx_t \ mid s_t = 1 \ЃЉЕФ\ЃЈT \ЃЉжмЦкКЭ\ ЃЈx_t \ mid s_t = 2 \ЃЉЕФ\ЃЈT \ЃЉжмЦкЁЃШЛКѓЃЌИјЖЈ\ЃЈs_t \ЃЉЕФФЃФтЃЌЮвУЧеыЖдУПИізДЬЌДДНЈНсЙћБфСП\ЃЈx_t \ЃЉЁЃ
plot(x~t_index, pch = 20) points(x[s == 2]~t_index[s==2],col = 2)

ЫфШЛзмЬхЖјбдЪБМфађСаПДЦ№РДЪЧЦНЮШЕФЃЌЕЋЮвУЧЙлВьЕНвЛаЉжмЦкЃЈвдКьЩЋЭЛГіЯдЪОЃЉЯдЪОГіНЯИпЕФВЈЖЏЁЃгаШЫПЩФмЛсНЈвщЫЕЃЌЪ§ОнДцдкНсЙЙаджаЖЯЃЌЛђепЬхжЦЗЂЩњСЫБфЛЏЃЌЙ§ГЬ\ЃЈx_t \ЃЉБфЕУдНРДдНДѓЃЌДјгаИќЖрЕФИКжЕЁЃЫфШЛШчДЫЃЌЪТКѓНтЪЭзмЪЧБШНЯШнвзЕФЁЃжївЊЕФЬєеНЪЧЪЖБ№етжжЧщПіЁЃ
ЙРМЦВЮЪ§
дкБОНкжаЃЌЮвНЋЪЙгУRШэМўЪжЖЏЃЈДгЭЗПЊЪМЃЉКЭЗЧЪжЖЏНјааЭГМЦЗжНтЁЃдкЧАепжаЃЌЮвНЋбнЪОШчКЮЙЙдьЫЦШЛКЏЪ§ЃЌШЛКѓЪЙгУдМЪјгХЛЏЮЪЬтРДЙРМЦВЮЪ§ЁЃЮвНЋЫЕУїШчКЮдкВЛОРњНтЮіЭЦЕМЕФЧщПіЯТНјааИДжЦЁЃ
ЫЦШЛКЏЪ§-Ъ§жЕВПЗж
ЪзЯШЃЌЮвУЧашвЊДДНЈвЛИівд\ЃЈ\ Theta \ЃЉЯђСПЮЊжївЊЪфШыЕФКЏЪ§ЁЃЦфДЮЃЌЮвУЧашвЊЩшжУвЛИіЗЕЛиMLEЕФгХЛЏЮЪЬтЁЃ
дкгХЛЏЫЦШЛКЏЪ§жЎЧАЁЃШУЮвУЧПДвЛЯТЙЄзїдРэЁЃМйЩшЮвУЧжЊЕРВЮЪ§\ЃЈ\ Theta \ЃЉЕФЯђСПЃЌВЂЧвЮвУЧгааЫШЄЪЙгУ\ЃЈx_t \ЃЉЩЯЕФЪ§ОнЦРЙРвўВизДЬЌЫцЪБМфЕФБфЛЏЁЃ
| t | xi_ {t mid tЃЌ1} | xi_ {t mid tЃЌ2} |
| 1 | 0.878 | 0.122 |
| 2 | 0.982 | 0.018 |
| 3 | 0.887 | 0.113 |
| 4 | 0.875 | 0.125 |
| 5 | 0.318 | 0.682 |
| 6 | 0.000 | 1.000 |
ЯдШЛЃЌетСНжжзДЬЌЕФУПДЮЙ§ТЫЦїЕФзмКЭгІЮЊ1ЁЃПДЦ№РДЃЌЮвУЧПЩвдДІгкзДЬЌ1ЛђзДЬЌ2ЁЃ
all(round(apply(Filter[,-1],1,sum),9) == 1) ## [1] TRUE
гЩгкЮвУЧЩшМЦСЫДЫЪ§ОнЃЌвђДЫЮвУЧжЊЕРзДЬЌ2ЕФЪБЦкЁЃ
plot(Filter[,3]~t_index, type = "l", ylab = expression(xi[2])) points(Filter[s==2,3]~t_index[s==2],pch = 20, col = 2)
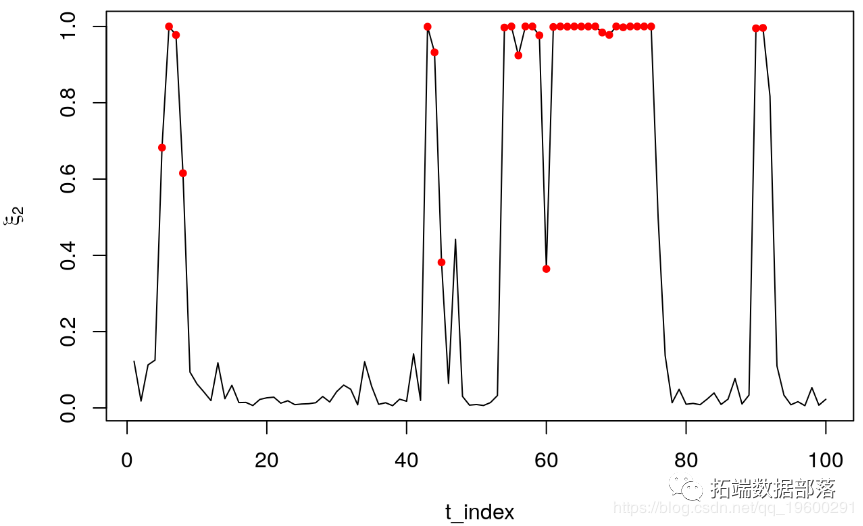
Й§ТЫЦїБГКѓЕФгХЕуЪЧНіЪЙгУ\ЃЈx_t \ЃЉЩЯЕФаХЯЂРДЪЖБ№ЧБдкзДЬЌЁЃЮвУЧЙлВьЕНЃЌзДЬЌ2ЕФЙ§ТЫЦїжївЊдкзДЬЌ2ЗЂЩњЪБдіМгЁЃетПЩвдЭЈЙ§ЗЂГіКьЕуЕФИХТЪдіМгРДжЄУїЃЌКьЕуБэЪОзДЬЌ2ЗЂЩњЕФЪБМфЖЮЁЃОЁЙмШчДЫЃЌЩЯЪіЛЙЪЧДцдквЛаЉжиДѓЮЪЬтЁЃЪзЯШЃЌЫќМйЖЈЮвУЧжЊЕРВЮЪ§\ЃЈ\ Theta \ЃЉЃЌЖјЪЕМЪЩЯЮвУЧашвЊЖдДЫНјааЙРМЦЃЌШЛКѓдкДЫЛљДЁЩЯНјааЭЦЖЯЁЃЦфДЮЃЌЫљгаетаЉЖМЪЧдкбљБОжаЙЙдьЕФЁЃДгЪЕМЪЕФНЧЖШРДПДЃЌОіВпепЖддЄВтЕФИХТЪМАЦфЖдЮДРДЭЖзЪЕФгАЯьИааЫШЄЁЃ
ЪжЖЏЙРЫу
ЮЊСЫгХЛЏЩЯУцЖЈвхЕФ HMM_Lik ЙІФмЃЌЮвНЋашвЊжДааСНИіИНМгВНжшЁЃЪзЯШЪЧНЈСЂвЛИіГѕЪМЙРМЦжЕЃЌзїЮЊЫбЫїЫуЗЈЕФЦ№ЕуЁЃЦфДЮЃЌЮвУЧашвЊЩшжУдМЪјЬѕМўвдбщжЄЙРМЦЕФВЮЪ§ЪЧЗёвЛжТЃЌМДЗЧИКВЈЖЏадКЭНщгк0КЭ1жЎМфЕФИХТЪжЕЁЃ
ЕквЛВНЃЌЮвЪЙгУбљБОДДНЈГѕЪМВЮЪ§ЯђСП\ЃЈ\ Theta_0 \ЃЉ
дкЕкЖўВНжаЃЌЮвЮЊЙРЫужЦЖЈСЫдМЪј
ЧызЂвтЃЌВЮЪ§ЕФГѕЪМЯђСПгІТњзудМЪјЬѕМў
all(A%*%theta0 >= B) ## [1] TRUE
зюКѓЃЌЛиЯывЛЯТЃЌЭЈЙ§ЙЙНЈДѓЖрЪ§гХЛЏЫуЗЈЖМПЩвдЫбЫїзюаЁЕуЁЃвђДЫЃЌЮвУЧашвЊНЋЫЦШЛКЏЪ§ЕФЪфГіИќИФЮЊИКжЕЁЃ
## $par ## [1] 1.7119528 -1.9981224 0.8345350 2.2183230 0.9365507 0.8487511 ## ## $value ## [1] 174.7445 ## ## $counts ## function gradient ## 1002 NA ## ## $convergence ## [1] 0 ## ## $message ## NULL ## ## $outer.iterations ## [1] 3 ## ## $barrier.value ## [1] 6.538295e-05
ЮЊСЫМьВщMLEжЕЪЧЗёгыецЪЕВЮЪ§вЛжТЃЌЮвУЧЛцжЦЙРМЦжЕгыецЪЕжЕЕФЙиЯЕЭМЃК
plot(opt$par ~ theta_known,pch = 20,cex=2,ylab="MLE",xlab = "True") abline(a=0,b=1,lty=2)

змЬхЖјбдЃЌЮвУЧЙлВьЕНЙРМЦжЕЗЧГЃвЛжТЃЌгЩгкMLEЕФвЛжТадЪєадЃЌетВЛзуЮЊЦцЁЃ
ЙРЫу
ЮвНЋдкЯТУцбнЪОШчКЮЪЙгУrШэМўИДжЦШЫЙЄЙРЫуЕФНсЙћ ЁЃ
ШчЙћЮвУЧвЊКіТдЙ§ГЬжаЕФШЮКЮЬхжЦзЊЛЛЃЌЮвУЧПЩвдМђЕЅЕиНЋВЮЪ§\ЃЈ\ mu \ЃЉКЭ\ЃЈ\ sigma \ЃЉЙРМЦЮЊ
kable(mod_est, "html", booktabs = F,escape = F) %>% kable_styling(position = "center")
| hat {mu} | hat {sigma} |
| 0.6244574 | 2.198929 |
ЦНОљЖјбдЃЌЮвУЧгІИУЦкЭћЙ§ГЬЦНОљжЕдМЮЊ1ЃЌМД\ЃЈ0.75 \ times 2 + 0.25 \ timesЃЈ-1ЃЉ= 1 \ЃЉЁЃетЪЧгЩзмЦкЭћЪєадЖЈТЩЕУГіЕФЃЌЦфжаЮвУЧжЊЕР\ [\ begin {equation} \ mathbb {E} [x] = \ sum _ {\ forall s} \ mathbb {E} \ left [x \ mid s \гв] \ mathbb {P}ЃЈsЃЉ= \ sum _ {\ forall s} \ mu_ {s} \ pi_ {s} \ end {equation} \]
етбљ
EX <- 0.75*2 + 0.25*-2 EX ## [1] 1
ЖдгкВЈЖЏТЪЃЌЪЪгУЯрЭЌЕФТпМЁЃ
EX2 <- (2^2 + 1^2)*0.75 + ((-2)^2 + 2^2)*0.25 VX <- EX2 - EX^2 sqrt(VX) ## [1] 2.179449
ЮвУЧзЂвтЕНЃЌЛиЙщЙРМЦжЕгыВЈЖЏТЪЕФвЛжТадИпгкОљжЕЁЃетжївЊЪЧгЩгкЙРЫуЕквЛЪБПЬгыЕкЖўЪБПЬЕФЙЄзїБШНЯЗБЫіЁЃ
ЩЯУцЕФЙлЕуЪЧЃЌЙРМЦжЕВЂЮДКИЧЪ§ОнЕФецЪЕаджЪЁЃШчЙћЮвУЧМйЩшЪ§ОнЪЧЙЬЖЈЕФЃЌФЧУДЮвУЧДэЮѓЕиЙРМЦЙ§ГЬЕФЦНОљжЕЮЊ62ЃЅЁЃЕЋЪЧЃЌгыДЫЭЌЪБЃЌЮвУЧЭЈЙ§ЙЙдьжЊЕРИУЙ§ГЬБэЯжГіСНИіЦНОљНсЙћ-вЛИіе§УцКЭвЛИіИКУцЁЃВЈЖЏадвВЪЧШчДЫЁЃ
ЮЊСЫНвЪОетаЉФЃЪНЃЌЮвУЧдкЯТУцбнЪОШчКЮЪЙгУЩЯУцЕФЯпадФЃаЭВПЪ№зДЬЌЧаЛЛФЃаЭЃК
жївЊЪфШыЪЧФтКЯФЃаЭЃЌ modЮвУЧНЋЦфЙщФЩЮЊЪЪгІЧаЛЛзДЬЌЁЃЕкЖўИі kЪЧжЦЖШЕФЪ§СПЁЃгЩгкЮвУЧжЊЕРЮвУЧвЊДІРэСНИізДЬЌЃЌвђДЫНЋЦфЩшжУЮЊ2ЁЃЕЋЪЧЃЌЪЕМЪЩЯЃЌашвЊВЮПМвЛжжаХЯЂБъзМРДШЗЖЈзюМбзДЬЌЪ§ЁЃИљОнЖЈвхЃЌЮвУЧгаСНИіВЮЪ§ЃЌОљжЕ\ЃЈ\ mu_s \ЃЉКЭВЈЖЏТЪ\ЃЈ\ sigma_s \ЃЉЁЃвђДЫЃЌЮвУЧЬэМгвЛИіtrue / falseЯђСПРДжИЪОе§дкЧаЛЛЕФВЮЪ§ЁЃдкЩЯУцЕФУќСюжаЃЌЮвУЧдЪаэСНИіВЮЪ§ЖМЧаЛЛЁЃзюКѓЃЌЮвУЧПЩвджИЖЈЙРМЦЙ§ГЬЪЧЗёе§дкЪЙгУВЂааМЦЫуНјааЁЃ
вЊСЫНтФЃаЭЕФЪфГіЃЌШУЮвУЧПДвЛЯТ
## Markov Switching Model ## ## ## AIC BIC logLik ## 352.2843 366.705 -174.1422 ## ## Coefficients: ## (Intercept)(S) Std(S) ## Model 1 1.711693 0.8346013 ## Model 2 -2.004137 2.2155742 ## ## Transition probabilities: ## Regime 1 Regime 2 ## Regime 1 0.93767719 0.1510052 ## Regime 2 0.06232281 0.8489948
ЩЯУцЕФЪфГіжївЊБЈИцЮвУЧГЂЪдЪжЖЏЙРЫуЕФСљИіЙРЫуВЮЪ§ЁЃЪзЯШЃЌЯЕЪ§БэБЈИцСЫУПИізДЬЌЕФОљжЕКЭВЈЗљЁЃФЃаЭ1ЕФЦНОљжЕЮЊ1.71ЃЌВЈЖЏТЪНгНќ1ЁЃФЃаЭ2ЕФЦНОљжЕЮЊ-2ЃЌВЈЖЏТЪдМЮЊ2ЁЃЯдШЛЃЌИУФЃаЭеыЖдЪ§ОнШЗЖЈСЫСНжжОпгаВЛЭЌОљжЕКЭВЈЖЏТЪЕФВЛЭЌзДЬЌЁЃЦфДЮЃЌдкЪфГіЕФЕзВПЃЌФтКЯЕФФЃаЭБЈИцЙ§ЖЩИХТЪЁЃ
plot(opt$par ~ theta_known,pch = 20,cex=2,ylab="MLE",xlab = "True") points(theta_mswm~theta_known,pch = 1,col = 2, cex = 2,lwd = 2) abline(a=0,b=1,lty=2) legend("topleft",c("Manual","MSwM"), pch = c(20,1), col = 1:2)
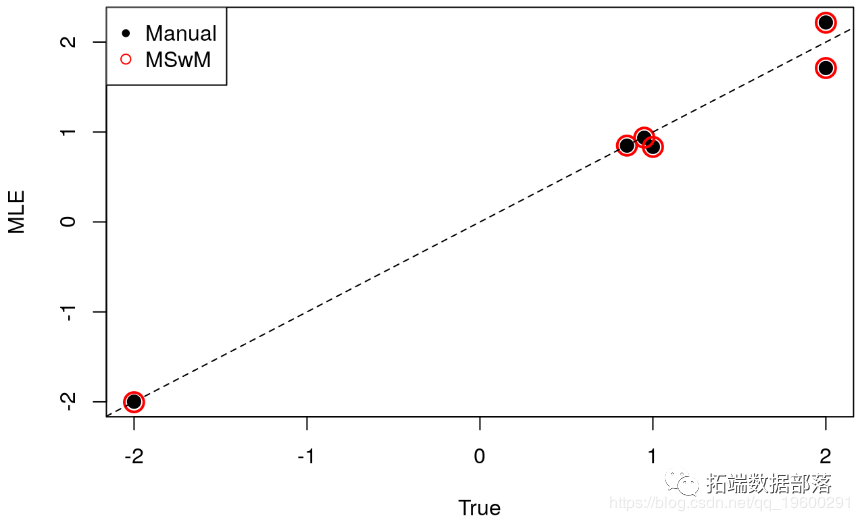
гаШЄЕФЪЧЃЌОЭУПжжзДЬЌЕФЙ§ТЫЦїЖјбдЃЌЮвУЧНЋДгАќжаМьЫїЕНЕФзДЬЌгыЪжЖЏЬсШЁЕФзДЬЌНјааБШНЯЁЃИљОнЖЈвхЃЌПЩвдЪЙгУmod.mswm ЖдЯѓЩЯЕФЭМКЏЪ§ РДСЫНтЦНЛЌИХТЪвдМАШЗЖЈЕФЗНАИЁЃ
par(mar = 2*c(1,1,1,1),mfrow = c(2,1)) plotProb(mod.mswm,2)

ЖЅВПЕФЭМБэЪОЫцЪБМфБфЛЏЕФЙ§ГЬ\ЃЈx_t \ЃЉЃЌЦфжаЛвЩЋвѕгАЧјгђБэЪО\ЃЈ\ hat {\ xi} _ {T \ mid tЃЌ1}> 0.5 \ЃЉЕФЪБМфЖЮЁЃЛЛОфЛАЫЕЃЌЛвЩЋЧјгђБэЪОзДЬЌ1еМгХЪЦЕФЪБМфЖЮЁЃ
plot(x~t_index,type ="l",col = 0,xlim=c(1,100)) rect(xx-1,-10,xx,10,col = "lightgray",lty = 0) lines(x~t_index) points(x[s==2] ~ t_index[s==2],col = 1,pch = 20)

Й§ТЫЦїЛсдквЛИіжмЦкФкМьВтЕНЕкЖўжжзДЬЌЁЃЗЂЩњетжжЧщПіЪЧвђЮЊ plotProb дкетжжЧщПіЯТЃЌЗЕЛиЕФЪЧЦНЛЌИХТЪЃЌМДдкЪЕЯжећИібљБО\ЃЈT \ЃЉКѓДІгкУПжжзДЬЌЕФИХТЪЃЌМД\ЃЈ\ hat {\ xi} _ {t \ mid TЃЌ1} \ ЃЉЁЃСэвЛЗНУцЃЌРДздЪжЖЏЙРМЦЕФвЛИіЖдгІгкЭЦЖЯИХТЪ\ЃЈ\ hat {\ xi} _ {t \ mid tЃЌ1} \ЃЉЁЃ
ЮоТлШчКЮЃЌгЩгкЮвУЧжЊЕРзДЬЌЕФецЪЕжЕЃЌвђДЫПЩвдШЗЖЈЮвУЧЪЧЗёДІгкецЪЕзДЬЌЁЃЮвУЧдкЩЯУцЕФЭМжаЪЙгУКкЕуЭЛГіЯдЪОзДЬЌ2ЁЃзмЕФРДЫЕЃЌЮвУЧЙлВьЕНФЃаЭдкМьВтЪ§ОнзДЬЌЗНУцБэЯжЗЧГЃГіЩЋЁЃЮЈвЛЕФР§ЭтЪЧЕк60ЬьЃЌЦфжаЭЦЖЯИХТЪДѓгк50ЃЅЁЃвЊВщПДЭЦРэИХТЪЖрГЄЪБМфе§ШЗвЛДЮЃЌЮвУЧдЫаавдЯТУќСю
mean(Filter$Regime_1 == (s==1)*1) ## [1] 0.96
НсЪјгя
ДЫЙ§ГЬЫЦКѕдЫааСМКУЁЃШЛЖјЃЌдкЪЕМЪЪ§ОнЪЕЯжЗНУцШдШЛДцдкаэЖрЬєеНЁЃЪзЯШЃЌЮвУЧВЛОпБИгаЙиЪ§ОнЩњГЩЙ§ГЬЕФжЊЪЖЁЃЦфДЮЃЌзДЬЌВЛвЛЖЈЪЕЯжЁЃвђДЫЃЌетСНИіЮЪЬтПЩФмЛсЦЦЛЕзДЬЌЧаЛЛФЃЪНЕФПЩППадЁЃдкгІгУЗНУцЃЌЭЈГЃВПЪ№ДЫРрФЃаЭвдЦРЙРОМУЛђЪаГЁзДПіЁЃДгОіВпЩЯРДЫЕЃЌетвВПЩвдЮЊВпТдЗжХфЬсЙЉгаШЄЕФгІгУЁЃ
