дЮФСДНгЃКhttp://tecdat.cn/?p=24198
ОлРрЪЧНЋзмЬхЛђЪ§ОнЕуЛЎЗжЮЊЖрИізщЕФШЮЮёЃЌвдЪЙЭЌвЛзщжаЕФЪ§ОнЕугыЭЌвЛзщжаЕФЦфЫћЪ§ОнЕуИќЯрЫЦЃЌЖјгыЦфЫћзщжаЕФЪ§ОнЕуВЛЯрЫЦЁЃЫќЛљБОЩЯЪЧЛљгкЫќУЧжЎМфЕФЯрЫЦадКЭЯрвьадЕФЖдЯѓЕФМЏКЯЁЃ
дкБОЯюФПжаЃЌЮвНЋЪЙгУЪРНчавИЃБЈИцжаЕФЪ§ОнЃЈВщПДЮФФЉСЫНтЪ§ОнЛёШЁЗНЪНЃЉРДЬНЫїбЧжо22ИіЙњМвЛђЕиЧјЃЌВЂЭЈЙ§ВщПДУПИіЙњМвЕФНзЬнЕУЗжЃЌЩчЛсжЇГжЃЌНЁПЕЕФЦкЭћЪйУќЃЌздгЩбЁдёЩњЛюЃЌПЖПЎЃЌЖдИЏАмЕФПДЗЈвдМАШЫОљGDPЃЌРДЬНЫїбЧжо22ИіЙњМвЕФЯрЫЦКЭВЛЭЌжЎДІЁЃЮвНЋЪЙгУСНжжОлРрЗНЗЈЃЌМДkОљжЕКЭВуДЮОлРрЃЌвдМАТжРЊЗжЮіРДбщжЄУПжжОлРрЗНЗЈЁЃ
ЁОЪгЦЕЁПKMEANSОљжЕОлРрКЭВуДЮОлРрЃКRгябдЗжЮіЩњЛюавИЃжЪСПЯЕЪ§ПЩЪгЛЏЪЕР§
Р§ШчЁЊЁЊЯТЭМжаОлМЏдквЛЦ№ЕФЪ§ОнЕуПЩвдЙщЮЊвЛзщЁЃЮвУЧПЩвдЧјЗжДиЃЌЮвУЧПЩвдЪЖБ№ГіЯТЭМжага3ИіДиЁЃ

ШУЮвУЧПДПДОлРрЫуЗЈЕФРраЭвдМАШчКЮЮЊФњЕФгУР§бЁдёЫќУЧЁЃ
ВуДЮОлРр
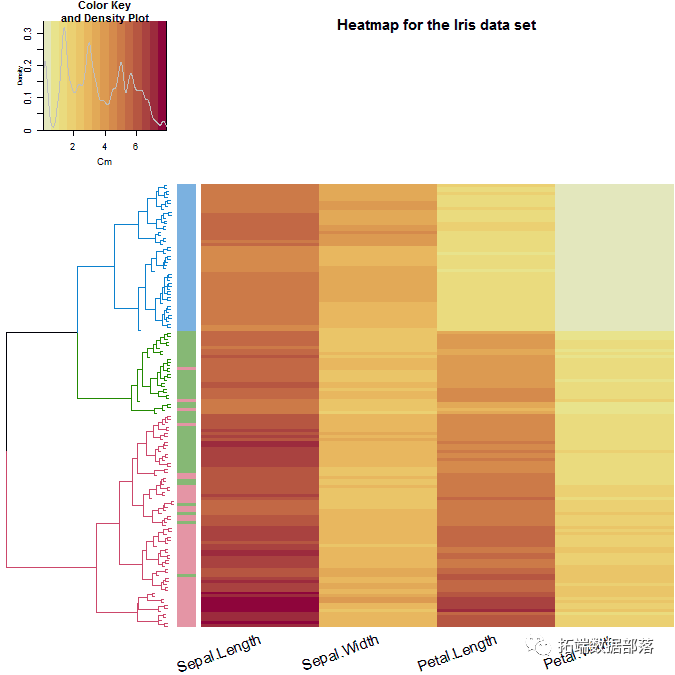
ВуДЮОлРрЕФжївЊЫМЯыЪЧЛљгкетбљЕФИХФюЃЌМДИННќЕФЖдЯѓБШИќдЖЕФЖдЯѓИќЯрЙиЁЃ

ФњгаСНРрВуДЮОлРрЫуЗЈЃЌздЩЯЖјЯТКЭздЯТЖјЩЯЁЃздЯТЖјЩЯЕФИХФюдкГѕЪМНзЖЮНЋУПИіЪ§ОнЕуЪгЮЊвЛИіЕЅЖРЕФМЏШКЁЃЫќЛсКЯВЂГЩЖдЕФМЏШКЃЌжБЕНФњгЕгавЛИіАќКЌЫљгаЪ§ОнЕуЕФзщЁЃвђДЫЃЌЫќвВБЛГЦЮЊЗжВуОлРрЃЈHACЃЉЁЃНЋЦфгывЛПУЪїНјааБШНЯЃЌЦфжаИљЪЧЮЈвЛЕФМЏШКЃЌЫќНЋЫљгабљБОгывЖзгвЛЦ№ЪеМЏЮЊОпгаЕЅИібљБОЕФМЏШКЁЃЯТЭМНЋИќКУЕиНтЪЭетИіИХФюЁЃ
1.НЋУПИіЪ§ОнЕуЪгЮЊвЛИіЕЅЖРЕФМЏШКЁЃЕкЖўВНЪЧбЁдёвЛИіОрРыЖШСПРДКтСПСНзщжЎМфЕФОрРыЁЃЪЙгУЦНОљСДНгЗНЗЈЃЌЦфжаСНИіМЏШКжЎМфЕФОрРыЪЧвЛИіМЏШКжаЕФЪ§ОнЕугыСэвЛИіМЏШКжаЕФЪ§ОнЕужЎМфЕФЦНОљОрРыЁЃ
2.дкУПДЮЕќДњжаЃЌЮвУЧНЋОпгазюаЁЦНОљСДНгЕФСНИіМЏШККЯВЂЮЊвЛИіЁЃ
3.жиИДЩЯЪіВНжшЃЌжБЕНЮвУЧгавЛИіАќКЌЫљгаЪ§ОнЕуЕФДѓМЏШКЁЃ

AHC ЕФгХЕуЃК
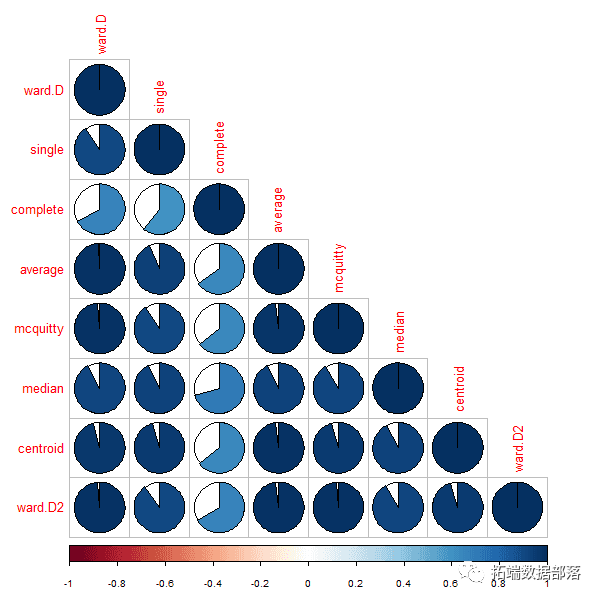
ЁЄAHC взгкЪЕЯжЃЌЫќЛЙПЩвдЬсЙЉЖдЯѓХХађЃЌетПЩвдЮЊЯдЪОЬсЙЉаХЯЂЁЃ
ЁЄЮвУЧВЛБидЄЯШжИЖЈМЏШКЕФЪ§СПЁЃЭЈЙ§дкЬиЖЈМЖБ№ЧаИюЪїзДЭМКмШнвзШЗЖЈОлРрЕФЪ§СПЁЃ
ЁЄдк AHC ЗНЗЈжаЃЌНЋДДНЈНЯаЁЕФМЏШКЃЌетПЩФмЛсЗЂЯжЪ§ОнЕФЯрЫЦадЁЃ
AHCЕФШБЕуЃК
ЁЄдкПЊЪМЕФШЮКЮВНжшжаЗжзщДэЮѓЕФЖдЯѓЖМЮоЗЈГЗЯћЁЃ
ЁЄВЛФмКмКУЕиДІРэвьГЃжЕЁЃУПЕБЗЂЯжвьГЃжЕЪБЃЌЫќУЧзюжеЛсГЩЮЊвЛИіаТЕФМЏШКЃЌЛђепгаЪБЛсЕМжТгыЦфЫћМЏШККЯВЂЁЃ

K-means ОлРрЫуЗЈ
KОљжЕОлРрЪЧзюГЃМћЕФОлРрЫуЗЈЃЌвђЮЊЫќвзгкРэНтКЭЪЕЯжЁЃKОљжЕЫуЗЈЪЙгУЬиЖЈЕФОрРыЖШСПНЋИјЖЈЕФЪ§ОнМЏВ№ЗжЮЊдЄЖЈвхKИіРрЁЃ
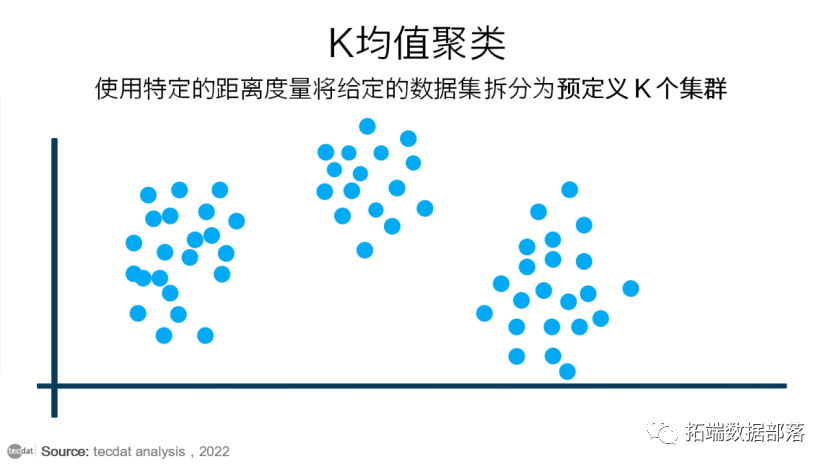
ЯТЭМНЋАяжњЮвУЧИќКУЕиРэНтетИіИХФюЁЃ

ЮвУЧДгЭМжаЭЦЖЯГіЪВУДЃП
бЁдёвЛаЉРрЛђзщВЂЫцЛњГѕЪМЛЏжааФЕуЁЃЧыМЧзЁЃЌШЗЖЈФњЪЙгУЕФРрЕФЪ§СПжСЙиживЊЁЃвђДЫЃЌЧызаЯИВщПДПЩгУЪ§ОнВЂШЗЖЈВЛЭЌЕФЬиеїЁЃЭМжагУ X БэЪОЕФжааФЕуЪЧгыУПИіЪ§ОнЕуЯђСПОпгаЯрЭЌГЄЖШЕФЯђСПЁЃ
1.ФњПЩвдЭЈЙ§МЦЫуЬиЖЈЕугыУПИізщжааФжЎМфЕФОрРыЖдУПИіЪ§ОнЕуНјааЗжРрЁЃЯТвЛВНЪЧЖдЪєгкжааФзюНќЕФзщЕФЕуНјааЗжРрЁЃ
2.ИљОнДЫаХЯЂЃЌШЁГіЬиЖЈзщжаЫљгаЯђСПЕФОљжЕВЂжиаТМЦЫузщжааФЁЃ
3.ЖдвЛИіЪ§зжжиИДИУЙ§ГЬЃЌВЂШЗБЃзщжааФдкЕќДњжЎМфБфЛЏВЛДѓЁЃ
гХЕу
ЁЄK-means ЪЧвЛжжПьЫйЕФЗНЗЈЃЌвђЮЊЫќВЛашвЊКмЖрМЦЫуЁЃ
ШБЕу
ЁЄЪЖБ№КЭЗжРрзщПЩФмЪЧвЛИіОпгаЬєеНадЕФЗНУцЁЃ
ЁЄгЩгкЫќДгЫцЛњбЁдёОлРржааФПЊЪМЃЌвђДЫЃЌНсЙћПЩФмШБЗІвЛжТадЁЃ
KMEANSОљжЕОлРрКЭВуДЮОлРрЃКбЧжоЙњМвЕиЧјЩњЛюавИЃжЪСПвьЭЌПЩЪгЛЏЗжЮіКЭбЁдёзюМбОлРрЪ§
НЋвЊЗжЮіЕФЙњМвКЭЕиЧјЪЧЃК
asia <- w filer(gepl('Asia', Rgion)

ЬНЫїадЪ§ОнЗжЮі
ЯрЙиОиеѓ
pair(aia\[,-c(1,2)\], sal=TUE,col,hst.ol)

- НзЬнЕУЗжЃЌЩчЛсжЇГжЃЌЩњЛюбЁдёЕФздгЩвдМАЖдИЏАмЕФПДЗЈЕФЗжВМЪЧзѓЦЋЕФЁЃ
- ПЖПЎКЭШЫОљGDPЕФЗжВМЪЧгвЦЋЕФЁЃ
- НЁПЕЦкЭћЪйУќЕФЦЋВюДѓдМЪЧЖдГЦЕФЁЃ
- СНепжЎМфДцдкКмЧПЕФе§ЯрЙиЙиЯЕЃК
- НзЬнЗжЪ§КЭЩчЛсжЇГж
- НЁПЕЦкЭћЪйУќКЭШЫОљGDP
- жЎМфДцдкЧПСвЕФИКЯрЙиЙиЯЕЃК
- ЖдИЏАмЕФПДЗЈКЭШЫОљGDP
- жЎМфДцдкжаЕШе§ЯрЙиЃК
- НзЬнЕУЗжКЭНЁПЕЦкЭћЪйУќ
- ЩчЛсжЇГжгыНЁПЕЦкЭћЪйУќ
- ШЫОљGDPНЯИпЕФЙњМвЭљЭљЖдИЏАмЕФПДЗЈНЯЕЭЃЌЖдНЁПЕЕФЦкЭћЪйУќЃЌЩчЛсжЇГжКЭНзЬнЕУЗжНЯИпЁЃ
ЙњМвКЭЕиЧјБШНЯ
grd.rrnge( ggplt(sia, es(rerder(x=fctor(ЙњМвУћГЦ), НзЬнЕУЗж, FN=min), y=НзЬнЕУЗж, fill=ЧјгђжИБъ)))
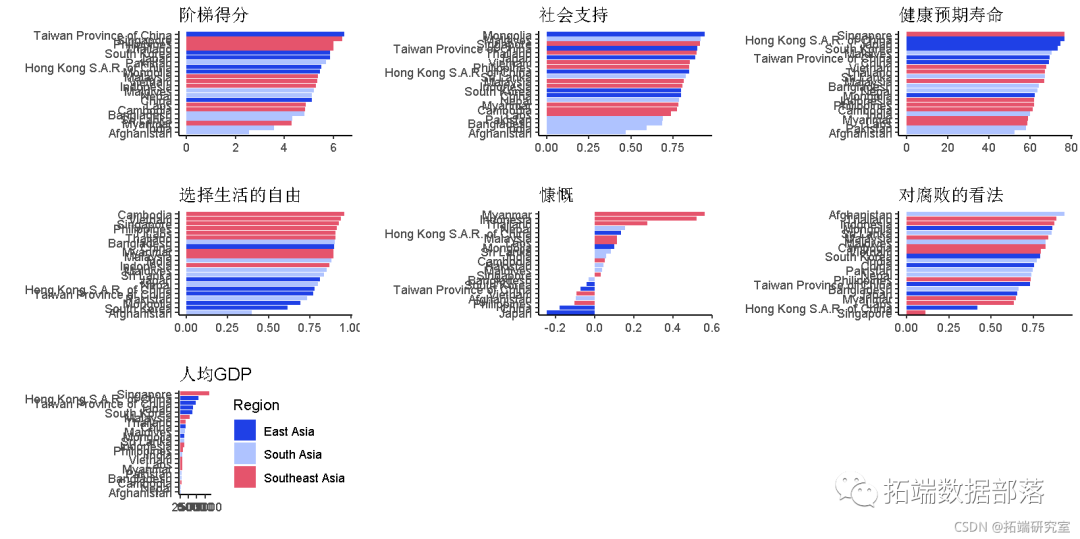
- ЖЋбЧЙњМвЕФНзЬнЕУЗжНЯИпЃЌЦкЭћЪйУќНЁПЕЃЌШЫОљGDPНЯИпЧвПЖПЎЖШНЯЕЭЁЃ
- ФЯбЧЙњМвЕФНзЬнЕУЗжЃЌЩчЛсжЇГжЃЌНЁПЕЕФЦкЭћЪйУќКЭШЫОљGDPЭљЭљНЯЕЭЁЃ
- ЖЋФЯбЧЙњМвЭљЭљгаКмИпЕФздгЩЖШЃЌПЩвдбЁдёЩњЛюКЭПЖПЎНтФвЁЃ
scterhst( aia, x = "ЩчЛсжЇГж", y = "НзЬнЕУЗж", clor = "ЧјгђжИБъ" titl = "НзЬнЕУЗжгыЩчЛсжЇГж" )

- ФЯбЧЕФЩчЛсжЇГжжаЮЛЪ§ЃЌНзЬнЕУЗжКЭШЫОљGDPзюЕЭЁЃ
- ЖЋбЧЕФЩчЛсжЇГжжаЮЛЪ§ЃЌНзЬнЕУЗжЃЌШЫОљGDPКЭНЁПЕЕФЦкЭћЪйУќзюИпЁЃ
- ЖЋФЯбЧЕФЦНОљНЁПЕЪйУќжаЮЛЪ§зюЕЭЃЌЖдИЏАмЕФжаЮЛЪ§зюИпЁЃ
- ЖЋФЯбЧЕФШЫОљGDPКмИпЃЌЦкЭћЪйУќНЁПЕЃЌЖдИЏАмЕФПДЗЈвВКмЕЭЃЈаТМгЦТЃЉЁЃ
- ЖЋбЧгаРыШКЕубљБОЖдеўИЎЕФСЫНтЕЭЃЈЯуИлЃЉЁЃ
01

02

03
04
ОлРрЗжЮі
етаЉЙњМвЛсЪєгкВЛЭЌЕФШКЬхТ№ЃПдкБОНкжаЃЌЮвУЧНЋЪЙгУОлРрЃЈвЛжжЮоМрЖНЕФбЇЯАЗНЗЈЃЌИУЗНЗЈЛљгкЯрЫЦадЖдЖдЯѓНјааЗжзщЃЉРДевЕНЙњМвзщЃЌЦфжазщФкЕФЙњМвЯрЫЦЁЃЮвНЋЪЙгУСНжжЗНЗЈНјааОлРрЃКЗжВуОлРрКЭK-MeansОлРрЁЃЪзЯШЃЌЮвУЧШчКЮЪЖБ№етаЉШКЬхЃПКтСПЖдЯѓжЎМфЯрЫЦадЕФвЛжжЗНЗЈЪЧВтСПЖдЯѓжЎМфЕФЪ§бЇОрРыЁЃвЛжжГЃМћЕФОрРыЖШСПЪЧХЗМИРяЕУОрРыЁЃ
ЁОЪгЦЕЁПKMEANSОљжЕОлРрКЭВуДЮОлРрЃКRгябдЗжЮіЩњЛюавИЃжИЪ§ПЩЪгЛЏ|Ъ§ОнЗжЯэ(ЯТ)ЃК/article/1491654
