ЁОЪгЦЕЁПKMEANSОљжЕОлРрКЭВуДЮОлРрЃКRгябдЗжЮіЩњЛюавИЃжИЪ§ПЩЪгЛЏ|Ъ§ОнЗжЯэЃЈЩЯЃЉЃК/article/1491650
ХЗЪЯОрРы
ЮвУЧНЋЪЙгУХЗМИРяЕУОрРыевЕНБЫДЫзюЯрЫЦЕФЙњМвЃЌВЂНЋЫќУЧЗжзщдквЛЦ№ЁЃ
aply(z,2,mean) # МЦЫуСаЕФЦНОљжЕ aply(z,2,sd) # МЦЫуСаЕФБъзМВю scale(z,ceter=means,scae=sds) # БъзМЛЏ # МЦЫуОрРыОиеѓ dsae = dit(nor) # МЦЫуХЗМИРяЕУЕФОрРы
ХЗМИРяЕУОрРыОиеѓЮЊЃК
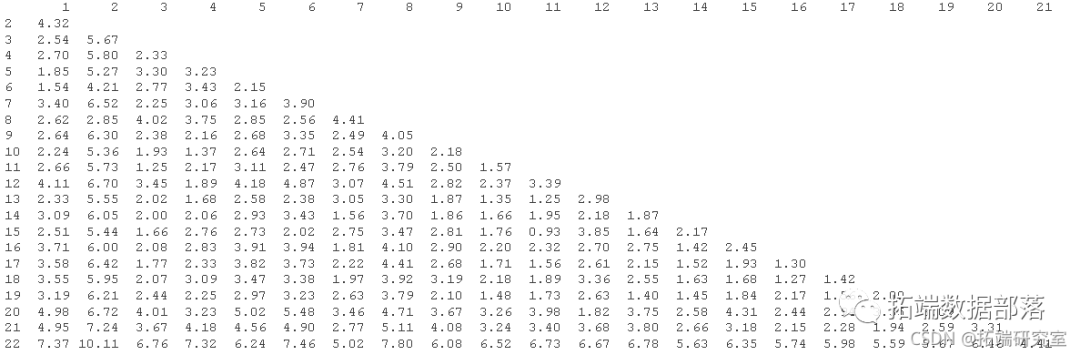
- ЫЦКѕЙњМв2ЃЈаТМгЦТЃЉКЭЙњМв22ЃЈАЂИЛКЙЃЉБЫДЫзюВЛЯрЫЦЁЃ
- 15ЙњЃЈжаЙњЃЉКЭ11ЙњЃЈдНФЯЃЉБЫДЫзюЯрЫЦЁЃ
ЮвУЧШчКЮбЁдёзюМбОлРрЪ§ЃП
жтЗЈ
for (i in 2:20) ws<- sum(kmens(nr, cetrs=i)$wthns)

ЮвУЧЕФФПБъЪЧМѕЩйОлРрФкВПЕФБфвьадЃЌвдБуНЋЯрЫЦЕФЖдЯѓЗжзщдквЛЦ№ЃЌВЂдіМгОлРржЎМфЕФБфвьадЃЌвдЪЙЯрвьЕФЖдЯѓЯрОрЩѕдЖЁЃWSSЃЈдкзщЦНЗНКЭФкЃЉЃЌЫќдкОлРрБфЛЏФкНјааЖШСПЃЌ
дкWSSЭМжаЃЌОлРрЪ§ЮЛгкxжсЩЯЃЌЖјWSSЮЛгкyжсЩЯЁЃИпЕФWSSжЕвтЮЖзХОлРржаЕФБфЛЏКмДѓЃЌЗДжЎврШЛЁЃЮвУЧПДЕНЃЌдк1ЁЂ2КЭ3ИіОлРржЎКѓЃЌWSSЕФЯТНЕКмДѓЁЃЕЋЪЧЃЌдк4ИіОлРржЎКѓЃЌWSSЕФЯТНЕКмаЁЁЃвђДЫЃЌОлРрЕФзюМбЪ§ФПЮЊk = 4ЃЈЧњЯпЕФЭфЭЗЃЉЁЃ
KОљжЕОлРр
kОљжЕЫуЗЈШчЯТЫљЪОЃК
- ЮЊУПИіЙлВтжЕЫцЛњЗжХфвЛИіДг1ЕНKЕФЪ§зжЃЌетаЉЪ§зжгУзїЙлВтжЕЕФГѕЪМОлРрЗжХфЁЃ
- ЕќДњжБЕНОлРрЗжХфЭЃжЙИќИФЃК
ЃЈaЃЉЖдгкKИіОлРржаЕФУПвЛИіЃЌМЦЫуОлРржЪаФЁЃ
ЃЈbЃЉНЋУПИіЙлВтжЕЗжХфИјжЪаФзюНгНќЕФОлРрЃЈЪЙгУХЗМИРяЕУОрРыЖЈвхЃЉЁЃ
ОлРрГЩдБКЭНсЙћ
kОљжЕОлРрЕФНсЙћЪЧЃК
#ОлРрГЩдБ asa$Cuter <- c$luser

ОлРрЭМдкЩЂЕуЭМжаЛцжЦkОљжЕОлРрКЭЧАСНИіжїГЩЗжЃЈЮЌЖШ1КЭ2ЃЉЁЃ
clstr(lstdaa = nr, cluter = cluser,col=ola), theme = hme_lsic()) + title("K-MeansОлРрЭМ")

- ОлРржЎМфУЛгажиЕўЁЃ
- ОлРр2гыЦфЫћОлРржЎМфДцдкКмЖрЗжИєЁЃ
- ОлРр1ЁЂ3КЭ4жЎМфЕФМфИєНЯаЁЁЃ
- ЧАСНИізщГЩВПЗжНтЪЭСЫЕуБфвьЕФ70ЃЅЁЃ

- ОлРр1га2ИіЙњМвЃЌЦфОлРрЦНЗНКЭжЎФкКмаЁЃЈдкОлРрБфвьадФкЃЉЁЃ
- ОлРр2га1ИіЙњМвЁЃ
- Опга14ИіЙњМв/ЕиЧјЕФЕк3зщдкРрФкБфвьаджазюИпЁЃ
- ОлРр4га5ИіЙњМвЃЌдкОлРрБфвьаджаХХУћЕкЖўЁЃ
- ОлРрЦНЗНКЭгыЦНЗНКЭжЎБШЮЊ61.6ЃЅЃЌЗЧГЃКЯЪЪЁЃ
етЫФИіОлРрЕФБъзМЦНОљжЕЪЧЃК
long <- melt(t(agreate(nor, ) plot(long,roup = cluster)+point(se=3)

здгЩбЁдёЩњЛюЃЌЩчЛсжЇГжКЭНзЬнЕУЗжжЎМфЕФВювьКмДѓЁЃетаЉБфСПЫЦКѕЖдОлРраЮГЩЙБЯззюДѓЁЃ
ЛиЯывЛЯТЃЌОлРрГЩдБзЪИёЮЊЃК
Ек1РрЃКгЁЖШФсЮїбЧЃЌУхЕщ
Ек2РрЃКАЂИЛКЙ
Ек3РрЃКЗЦТЩБіЃЌЬЉЙњЃЌАЭЛљЫЙЬЙЃЌУЩЙХЃЌТэРДЮїбЧЃЌдНФЯЃЌТэЖћДњЗђЃЌФсВДЖћЃЌжаЙњЃЌРЯЮЮЃЌМэЦвеЏЃЌУЯМгРЙњЃЌЫЙРяРМПЈЃЌгЁЖШ
Ек4РрЃКжаЙњЬЈЭхЕиЧјЃЌаТМгЦТЃЌКЋЙњЃЌШеБОЃЌжаЙњЯуИлЬиБ№ааеўЧј
ЯрЖдгкЦфЫћОлРрЃК
ОлРр1ЕФЬиЕуЪЧ
- КмИпЃКПЖПЎ
- ИпЃКздгЩбЁдёЩњЛю
- вЛАуЃКШЫОљGDPЃЌЖдИЏАмЕФПДЗЈЃЌПЖПЎЃЌНЁПЕЕФЦкЭћЪйУќЃЌЩчЛсжЇГжЃЌНзЬнЕУЗж
ОлРр2ЕФЬиЕуЪЧ
- ИпЃКЖдИЏАмЕФПДЗЈ
- ЕЭЃКШЫОљЙњФкЩњВњзмжЕЃЌПЖПЎ
- ЗЧГЃЕЭЃКздгЩбЁдёЩњЛюЃЌНЁПЕЕФЦкЭћЪйУќЃЌЩчЛсжЇГжЃЌНзЬнЕУЗж
ОлРр3ЕФЬиЕуЪЧ
- ИпЃКздгЩбЁдёЩњЛю
- вЛАуЃКШЫОљGDPЃЌЖдИЏАмЕФПДЗЈЃЌПЖПЎЃЌНЁПЕЕФЦкЭћЪйУќЃЌЩчЛсжЇГжЃЌНзЬнЕУЗж
ОлРр4ЕФЬиЕуЪЧ
- КмИпЃКШЫОљGDPЃЌЦкЭћЪйУќНЁПЕ
- ИпЃКЩчЛсжЇГжЃЌНзЬнЕУЗж
- вЛАуЃКздгЩбЁдёЩњЛю
- ЕЭЃКПЖПЎ
- МЋЕЭЃКЖдИЏАмЕФПДЗЈ
ТжРЊЭМ
ЮвУЧЪЙгУТжРЊЭМРДВщПДУПИіЙњМвдкЦфОлРржаЕФзДПіЁЃТжРЊПэЖШКтСПвЛИіОлРржаУПИіЙлВтжЕЯрЖдгкЦфЫћОлРрЕФНгНќГЬЖШЁЃНЯИпЕФТжРЊПэЖШБэЪОИУЙлВтжЕКмКУЕиОлРрЃЌЖјНгНќ0ЕФжЕБэЪОИУЙлВтжЕдкСНИіОлРржЎМфЦЅХфЃЌЖјИКжЕБэЪОИУЙлВтжЕдкДэЮѓЕФОлРржаЁЃ
plt(soette((cluser), diace), mn = "ТжРЊЯЕЪ§ЭМ")

- ДѓЖрЪ§ЙњМвЫЦКѕЖМЗЧГЃКУЁЃ
- Ек3зщжаЕФЙњМв4ЃЈЬЉЙњЃЉКЭЕк4зщжаЕФЙњМв5ЃЈКЋЙњЃЉЕФТжРЊПэЖШЗЧГЃЕЭЁЃ
ВуДЮОлРр
ЗжВуОлРрНЋзщгГЩфЕНГЦЮЊЪїзДЭМЕФВуДЮНсЙЙжаЁЃЗжВуОлРрЫуЗЈШчЯТЫљЪОЃК
- ДгnИіЙлВьжЕКЭЫљгаГЩЖдВЛЯрЫЦадЕФЖШСПЃЈР§ШчХЗМИРяЕУОрРыЃЉПЊЪМЁЃНЋУПИіЙлВьжЕЪгЮЊздМКЕФОлРрЁЃ
ЃЈaЃЉМьВщiИіОлРржЎМфЫљгаГЩЖдЕФОлРрМфВювьЃЌВЂевГізюЯрЫЦЕФвЛЖдОлРрЁЃМгШыетСНИіОлРрЁЃетСНИіДижЎМфЕФВювьБэУїЫќУЧдкЪїзДЭМжаЕФИпЖШЁЃ
ЃЈbЃЉМЦЫуЦфгрОлРржЎМфЕФаТЕФГЩЖдОлРрМфВювьЁЃЖдгкЗжВуОлРрЃЌЮвУЧдкОлРржЎМфЪЙгУОрРыКЏЪ§ЃЌГЦЮЊСДНгКЏЪ§ЁЃВЛЭЌРраЭЕФСДНгЃК
- ЭъШЋЃЈзюДѓОлРрМфВювьЃЉЃКМЦЫуОлРр1жаЕФЙлВтжЕгыОлРр2жаЕФЙлВтжЕжЎМфЕФЫљгаГЩЖдВювьЃЌВЂМЧТМетаЉВювьжазюДѓЕФвЛИіЁЃ
plt(aslus.c,laes=ЙњМвУћГЦ,min='ШЋСДНг k=4', hang=-1) rct.clut(whasi.hclusc, k=4)

- ЦНОљжЕЃЈОљжЕОлРрМфВювьЃЉЃКМЦЫуОлРр1жаЕФЙлВтжЕгыОлРр2жаЕФЙлВтжЕжЎМфЕФЫљгаГЩЖдВювьЃЌВЂМЧТМетаЉВювьЕФЦНОљжЕЁЃ
ШЋСДНг
ЯТУцЕФЪїзДЭМЯдЪОСЫЪЙгУШЋСДНгЕФОлРрВуДЮНсЙЙЁЃ
custr(ist(dta = or, cuse = mer.a), ghe = teelsic)) + title("ШЋСДНг lusterPlot")

- ОлРр1га16ИіЙњМвЁЃ
- ОлРр2га2ИіЙњМвЁЃ
- ОлРр3га3ИіЙњМвЁЃ
- ОлРр4га1ИіЙњМвЁЃ
- ОлРр4КЭЦфЫћОлРржЎМфгаКмЖрМфИєЁЃ
- ОлРр1ЁЂ2КЭ3жЎМфЕФМфИєНЯаЁЁЃ
- ОлРр1жаЕФБфвьадЫЦКѕКмДѓЁЃ
ТжРЊЭМ
plot(sloett(curee(asiahluc, 4), di), col min = "ШЋСДНг ТжРЊЯЕЪ§ЭМ")

ДѓЖрЪ§ЙњМвЫЦКѕЖМЗЧГЃКУЁЃ
- 16ЙњЃЈРЯЮЮЃЉЫЦКѕЪЧЕк1зщЕФвьГЃжЕЁЃ
- 21ЙњЃЈгЁЖШЃЉЫЦКѕЪЧЕк3зщЕФвьГЃжЕЁЃ
ЦНОљСДНг
ЯТУцЕФЪїзДЭМЯдЪОСЫЪЙгУЦНОљСДНгЕФОлРрВуДЮЁЃ
plt(s.hut.,abls=ЙњМвУћГЦ,min='ЦНОљСДНг k=4', hag=-1) rec(hsth_asa.lus.a, k= boder)

- ОлРр1га4ИіЙњМвЁЃ
- ОлРр2га1ИіЙњМвЁЃ
- ОлРр3га16ИіЙњМвЁЃ
- ОлРр4га1ИіЙњМвЁЃ
- ЪЙгУЦНОљСДНгЕФОлРржЎМфЕФБфвьадЫЦКѕДѓгкШЋСДНгЕФБфвьадЁЃ
custr(ist(dta = or, cuse = mer.a), ghe = teelsic)) + title("ЦНОљСДНг lusterPlot")

ТжРЊЭМ
plt(sltte(ctee(sia.lust, 4), istce), cl=cl\[:5\], min = "ЦНОљСДНг ТжРЊЯЕЪ§ЭМ")

- ДѓЖрЪ§ЙњМвЫЦКѕЖМЗЧГЃКУЁЃ
- Ек1зщжаЕФ8ЕиЧјЃЈЯуИлЃЉЕФТжРЊПэЖШЗЧГЃаЁЁЃ
ЬжТл
kОљжЕЃЌШЋСДНгКЭЦНОљСДНгЕФЦНОљТжРЊПэЖШЗжБ№ЮЊ0.26ЁЂ0.23КЭ0.27ЁЃдкШЋСДНгжаЃЌОлРржЎМфЕФОрРыаЁгкkОљжЕКЭЦНОљСДНгжЎМфЕФОрРыЃЌВЂЧвСНИіЙњМвВЛЬЋЪЪКЯЫќУЧЕФОлРрЁЃвђДЫЃЌkОљжЕКЭЦНОљСДНгЗНЗЈЫЦКѕБШШЋСДНгОпгаИќКУЕФФтКЯЖШЁЃБШНЯkОљжЕЃЌШЋСДНгКЭЦНОљСДНгЃЌЫљгаЗНЗЈЖМгыАЂИЛКЙЦЅХфЃЌГЩЮЊЦфздМКЕФОлРрЁЃЕЋЪЧЃЌУПжжЗНЗЈЕФОлРрГЩдБзЪИёгаЫљВЛЭЌЁЃР§ШчЃЌдкkОљжЕКЭШЋСДНгжаЃЌгЁЖШФсЮїбЧКЭУхЕщгыДѓЖрЪ§ФЯбЧКЭЖЋФЯбЧЙњМвВЛдкЭЌвЛОлРржаЃЌЖјгЁЖШФсЮїбЧКЭУхЕщгыдкЦНОљСДНгжаЕФЙњМвдкЭЌвЛОлРржаЁЃ
K-meansКЭЗжВуОлРрЖМВњЩњСЫЯрЕБКУЕФОлРрНсЙћЁЃдкЪЙгУДѓаЭЪ§ОнМЏКЭНтЪЭОлРрНсЙћЪБЃЌK-meansгавЛИігХЪЦЁЃK-meansЕФШБЕуЪЧЫќашвЊдкПЊЪМЪБжИЖЈЪ§зжЪ§ОнКЭОлРрЕФЪ§СПЁЃСэЭтЃЌгЩгкГѕЪМОлРрЗжХфдкПЊЪМЪБЪЧЫцЛњЕФЃЌЕБФудйДЮдЫааИУЫуЗЈЪБЃЌОлРрНсЙћЪЧВЛЭЌЕФЁЃСэвЛЗНУцЃЌЗжВуОлРрЖдЪ§зжКЭЗжРрЪ§ОнЖМгааЇЃЌВЛашвЊЯШжИЖЈОлРрЕФЪ§СПЃЌЖјЧвУПДЮдЫааЫуЗЈЖМЛсЕУЕНЯрЭЌЕФНсЙћЁЃЫќЛЙФмВњЩњЪїзДЭМЃЌетЖдАяжњФуРэНтЪ§ОнЕФНсЙЙКЭЬєбЁОлРрЕФЪ§СПКмгагУЁЃШЛЖјЃЌвЛаЉШБЕуЪЧЃЌЖдгкДѓЪ§ОнРДЫЕЃЌЫќУЛгаk-meansФЧУДгааЇЃЌЖјЧвДгЪїзДЭМжаШЗЖЈОлРрЕФЪ§СПБфЕУКмРЇФбЁЃ
