ШЋЮФСДНгЃКhttps://tecdat.cn/?p=32955
БОЮФОЭНЋВЩгУK-meansЫуЗЈКЭВуДЮОлРрЖдЛљгкгУЛЇЬиеїЕФЮЂВЉЪ§ОнАяжњПЭЛЇНјааОлРрЗжЮіЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
ЪзЯШЖдОлРрЗжЮізїЯЕЭГНщЩмЁЃЦфДЮЖдОлРрЫуЗЈНјааЮФЯзЛиЙЫЃЌЖдЦфИХПіЁЂЛљБОЫМЯыЁЂЫуЗЈНјааЯъЯИНщЩмЃЌдйЪЧЭЈЙ§ЖдЮЂВЉЪ§ОнЗжЮіОпЬхРДЧПЛЏСЫНтОлРрЫуЗЈЃЌБОЮФЕФЪ§ОнЪЧгЩЫљЩшМЦЕиШэМўдкЮЂВЉЦНЬЈЩЯЛёШЁЕФЪ§ОнЃЌзюКѓЕУЕНЯрЙиНсТлКЭЦєЪОЁЃ
ОлРрЗжЮіЗЈИХЪі
ОлРрЫуЗЈЕФбаОПгазХЯрЕБГЄЕФРњЪЗЃЌдчдк1975Фъ HartiganОЭдкЦфзЈжј Clustering AlgorithmsЃл5ЃнжаЖдОлРрЫуЗЈНјааСЫЯЕЭГЕФТлЪіЁЃОлРрЗжЮіЫуЗЈзїЮЊвЛжжгааЇЕФЪ§ОнЗжЮіЗНЗЈБЛЙуЗКгІгУгкЪ§ОнЭкОђЁЂЛњЦїбЇЯАЁЂЭМЯёЗжИюЁЂгявєЪЖБ№ЁЂЩњЮяаХЯЂДІРэЕШЁЃ
ОлРрЗНЗЈЪЧЮоМрЖНФЃЪНЪЖБ№ЕФвЛжжЗНЗЈЃЌЭЌЪБвВЪЧвЛжжКмживЊЕФЭГМЦЗжЮіЗНЗЈЁЃОлРрЗжЮівбОБЛЙуЗКЕФбаОПСЫКмЖрФъЃЌбаОПСьгђКИЧЪ§ОнЭкОђЁЂЭГМЦбЇЁЂЛњЦїбЇЯАКЭПеМфЪ§ОнПтЕШжкЖрСьгђЁЃОлРрЪЧЛљгкЪ§ОнЕФЯрЫЦадНЋЪ§ОнМЏКЯЛЎЗжГЩзщЃЌШЛКѓИјетаЉЛЎЗжКУЕФзщжИЖЈБъКХЁЃФПЧАЮФЯзжаДцдкзХДѓСПЕФОлРрЫуЗЈЃЌДѓЬхЩЯЃЌОлРрЗжЮіЫуЗЈжївЊЗжГЩШчЯТМИжж[6]ЃЌЭМ2-1ЯдЪОСЫвЛаЉжївЊЕФОлРрЫуЗЈЕФЗжРрЁЃ

ЮЂВЉгУЛЇЬиеїЪ§ОнбаОП
ЮЊСЫНјвЛВНбщжЄK-meansЫуЗЈЃЌБОЮФНЋВЩМЏвЛХњЮЂВЉЪ§ОнЃЌЭЈЙ§ИљОнЮЂВЉгУЛЇЬиеїЪєадЖдЦфНјааОлРрЃЌВЂЕУГіНсТлЁЃ
Ъ§ОнВЩМЏ
аТРЫЮЂВЉЃЌзїЮЊжаЙњЕФНЯДѓЕФгУЛЇЪЙгУНЯЪмЛЖгЕФЮЂВЉЪЙгУЦНЬЈжЎвЛЃЌДгЦфЦНЬЈЩЯГщШЁЕФЮЂВЉвЛЖЈГЬЖШЩЯПЩвдЗДгГЙњФкЮЂВЉЦНЬЈЕФДЋВЅЧщПіЁЃМјгкаТРЫЮЂВЉдкЙњФкОпгаНЯДѓгАЯьСІЃЌЙЪБОЮФбЁШЁгагАЯьСІЕФаТРЫЮЂВЉгУЛЇЮЊбаОПЖдЯѓЃЌАќРЈДѓVЁЂЕчЩЬЦНЬЈЁЂУїаЧЁЂЭјКьЕШЃЌДгЮЂВЉгУЛЇЬиеїГіЗЂЃЌРДЬНЫїЛљгкгУЛЇЬиеїЕФОлРрЗжЮіЁЃБОбаОПзмЙВЛёШЁСЫ50359ЬѕЮЂВЉЪ§ОнЁЃ
Ъ§ОнШЁжЕЗЖЮЇ
| жИБъ | ШЁжЕЗЖЮЇ |
| ЪЧЗёШЯжЄ | VЛђN |
| адБ№ | ФаЛђХЎ |
| ЗлЫПЪ§ | 0ЃЌ1ЃЌ2ЁЃЈЗЧИКећЪ§ЃЉ |
| ЮЂВЉЪ§ | 0ЃЌ1ЃЌ2ЁЃЈЗЧИКећЪ§ЃЉ |
| зЂВсЪБМфБШ | ШеЦк |
ИљОнБОЮФашЧѓЃЌВЩгУБрГЬШэМўдкаТРЫЮЂВЉЦНЬЈЩЯЪеМЏЕНЕФЯрЙиЪ§ОнЃЌОпЬхбљБОЪЕР§ШчЭМЫљЪОЃЌЦфжаЃЌЖдЪЧЗёМгVЃЌЗлЫПЙизЂБШНјааБъзМЛЏЁЃ

ЕуЛїБъЬтВщдФЭљЦкФкШн

RгябдЖдФЭПЫNIKEIDаТРЫЮЂВЉЪ§ОнKОљжЕ(K-MEANS)ОлРрЮФБОЭкОђКЭДЪдЦПЩЪгЛЏ
01

02

03

04

K-meansКЭВуДЮОлРр
data=read.csv("аТРЫЮЂВЉгУЛЇЪ§Он.csv") #ЩОГ§ШБЪЇжЕ dat=.mit(data) for(i in 3:ncol(dta))dta[,i]=as.nuerc(daa[,i]) kmas(data[,c("адБ№" ,"ЗлЫПЪ§","ЮЂВЉЪ§" ,"ЪЧЗёШЯжЄ" ,"зЂВсЪБМф" )]
БОЮФВЩгУRШэМўЖдЪ§ОнНјааK-meansОлРрКЭВуДЮОлРрЗжЮіЁЃRгябдЪЧЭГМЦСьгђЙуЗКЪЙгУЕФЃЌЕЎЩњгк1980ФъзѓгвЕФSгябдЕФвЛИіЗжжЇЁЃ
НсЙћ
НЋИУЪ§ОнМЏЗжЮЊСЫШ§РрЁЃ
plot(data[,3:4], fit$clust


ЕуЛїБъЬтВщдФЭљЦкФкШн

RгябджїГЩЗжPCAЁЂвђзгЗжЮіЁЂОлРрЖдЕиЧјОМУбаОПЗжЮіжиЧьЪаОМУжИБъ
01

02

03
04
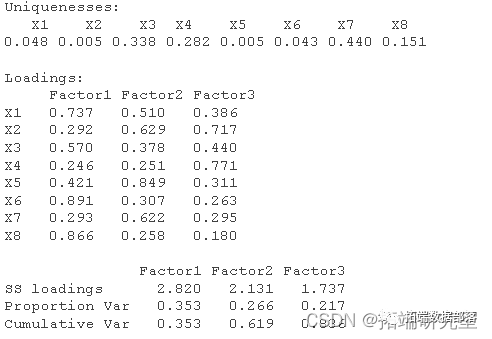


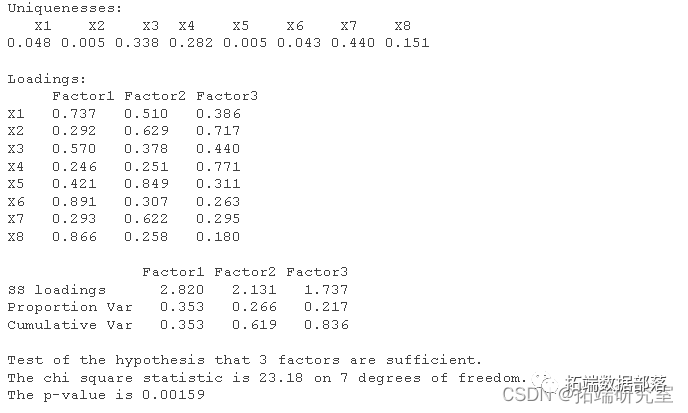
K-meansЫуЗЈНЋИУбљБОМЏЗжЮЊ4РрЃЌЦфжазюЖрЕФЮЊcluster-2ЃЌга39886ЬѕМЧТМЃЌЦфДЮЪЧcluster-3ЃЌга4561ЬѕМЧТМЃЌдйепЪЧcluster-1ЃЌЮЊ3514ЬѕМЧТМЃЌcluster-4ЃЌЮЊ2398ЬѕМЧТМЁЃДгОлРрЪ§СПРДПДОлРрЪ§ФПЗжВМКЯРэЃЌУЛгаГіЯжЙ§ЩйЕФРыШКЕуЁЃДгОлРржааФРДПДЃЌЕкЖўРрБ№ЪЧЮЂВЉЪ§НЯЩйЃЌЕЋЪЧЗлЫПКмЖрЃЌВЂЧвзЂВсЪБМфНЯдчЕФвЛХњгУЛЇЃЌВЂЧввбОЪЧШЯжЄЕФгУЛЇЃЌвђДЫПЩвдШЯЮЊЪЧДѓVгУЛЇЁЃЕк1РрЭЌбљгЕгаНЯЖрЕФЗлЫПЃЌЭЌбљЪЧШЯжЄгУЛЇЃЌПЩвдШЯЮЊЪЧаЁVгУЛЇЁЃЕкШ§РрЗлЫПЪ§ФПЩйЃЌУЛгаШЯжЄЃЌВЂЧвзЂВсНЯЭэЃЌвђДЫПЩвдШЯЮЊЪЧЦеЭЈЮЂВЉгУЛЇЃЌЕкЫФРргУЛЇЮЂВЉЪ§ФПЖрЃЌЗлЫПЪ§ФПНЯЖрЃЌЕЋЪЧУЛгаШЯжЄЃЌвђДЫПЩвдШЯЮЊЪЧВнИљУћВЉЁЃ

ВуДЮОлРрбщжЄ
ЮЊСЫбщжЄИУНсЙћЕФПЩааадЃЌгжВЩгУСЫRЭГМЦШэМўЖдбљБОНјааСЫВуДЮОлРрЗжЮіЁЃОпЬхДњТыШчЯТЫљЪОЃК
attach(x)ЃК c<-hcst(dist(x)ЃЌ"sin ct.hclu
ЕУЕНОлРрНсЙћШчЭМЃК

ДгВуДЮОлРрЕФНсЙћРДПДЃЌНЋИУЪ§ОнЛЎЗжГЩ4ИіРрБ№ЪЧЯрЖдКЯРэЕФЃЌвђДЫЩЯЪіШЯжЄгаРэгаОнЁЃ
НсТл
БОЮФбаОПСЫЪ§ОнЭкОђЕФбаОПБГОАгывтвхЃЌЬжТлСЫОлРрЫуЗЈЕФИїжжЛљБОРэТлАќРЈОлРрЕФаЮЪНЛЏУшЪіКЭЖЈвхЃЌОлРржаЕФЪ§ОнРраЭКЭЪ§ОнНсЙћЃЌОлРрЕФЯрЫЦадЖШСПКЭзМдђКЏЪ§ЕШЁЃЭЌЪБвВЬНЬжбЇЯАСЫЛљгкЛЎЗжЕФОлРрЗНЗЈЕФЕфаЭЕФОлРрЗНЗЈЁЃБОЮФжиЕуМЏжабЇЯАСЫбаОПСЫ K-MeansОлРрЫуЗЈЕФЫМЯыЁЂдРэвдМАИУЫуЗЈЕФгХШБЕуЁЃВЂдЫгУK-meansЫуЗЈЖдЫљВЩМЏЕФЪ§ОнНјааОлРрЗжЮіЃЌЩюЛЏСЫЖдИУЫуЗЈЕФРэНтЁЃ
ВЮПМЮФЯз
[1] жаЙњЛЅСЊЭјТчаХЯЂжааФЃЈCNNICЃЉ.Ек33ДЮжаЙњЛЅСЊЭјТчЗЂеЙзДПіЭГМЦБЈИц[EB/OL].
[2] ЙљгюКьЃЌЭЏдЦКЃЃЌЬЦЪРЮМЕШ.Ъ§ОнПтжаЕФжЊЪЖвўВи [ J ].ШэМўбЇБЈЃЌ2007ЃЌ 11 (18) : 278222797.
[3] hehroz S.KhanЃЌAmir Ahmad.Cluster center initialization algorithm for K-Means clustering[J].Pattern Recognition Letters 25(2004): 1293-1302.
[4] ЭѕДКЗчЃЌЬЦгЕеў.НсКЯНќСкКЭУмЖШЫМЯыЕФK-ОљжЕЫуЗЈЕФбаОП[J] МЦЫуЛњЙЄГЬгІгУ.2011 ФъЃЌ47(19).147-149.
[5] бюаЁБј.ОлРрЗжЮіжаШєИЩЙиМќММЪѕЕФбаОП[D].КМжн:еуНДѓбЇЃЌ2005Фъ:24-25.
[6] Hartigan J A. Clustering Algorithms[M].New York: John Wiley&Sons Inc.ЃЌ1975ЃЎ
[7] Tony Bain ЕШжј.ЩлгТвы.SQL Server2000 Ъ§ОнВжПтгы Analysis Services[M]. ББОЉ.жаЙњЕчСІГіАцЩчЃЌ2003.
[8] Handl JuliaЃЌ Joshua KnowlesЃЌ Douglas B. Kell. Computational cluster validation in post-genomic data
