ШчЙћФњЪьЯЄЯпадФЃаЭЃЌвтЪЖЕНЫќУЧЕФОжЯоЃЌФЧУДФњгІИУбЇЯАЯпадЛьКЯФЃаЭmixed-modelЁЃБОЪгЦЕжаЃЌЮвУЧЬжТлСЫЯпадЛьКЯФЃаЭВЂдкRШэМўжаНјаагІгУЁЃ
ЪгЦЕЃКЯпадЛьКЯаЇгІФЃаЭ(LMM,Linear Mixed Models)КЭRгябдЪЕЯж

ЪВУДЪЧЛьКЯаЇгІНЈФЃЃЌЮЊЪВУДвЊЪЙгУЃП
ЭГМЦЗжЮіжааэЖрЮЪЬтЕФДЋЭГЗНЗЈЪЧФтКЯЯпадФЃаЭЃЌЭЈГЃЪЙгУзюаЁЖўГЫЙРМЦЁЃгыЫљгаЭГМЦЗНЗЈвЛбљЃЌзюаЁЖўГЫЙРМЦашвЊзіГіФГаЉЪ§бЇМйЩшЃКЪ§ОнЗћКЯе§ЬЌЗжВМЕФВЂЧвБЫДЫЖРСЂЁЃ

ЯпадЭГМЦФЃаЭЕФвЛИіГЃМћЪОР§ЪЧЖрдЊЯпадЛиЙщФЃаЭЃК

ЦфжаYБЛГЦЮЊвђБфСПЃЌXЪЧздБфСПЃЌІТЪЧвЊдЄВтЕФЮДжЊВЮЪ§ЃЌЖј?ЪЧЫцЛњЮѓВюЯђСПЁЃ
ЖдгкЯпадЛиЙщФЃаЭЃЌЮвУЧашвЊМйЩшЮѓВюЪЧе§ЬЌЗжВМЕФВЂЧвБЫДЫЖРСЂЁЃздШЛЃЌбЯжиЮЅЗДетаЉМйЩшНЋЕМжТЭГМЦФЃаЭМИКѕУЛгагУДІЁЃ
ШЛЖјЃЌдкЪЕМЪЧщПіжаЃЌР§ШчЕБЮвУЧЖдЭЌвЛИіШЫжиИДВтСПвђБфСПжЧСІЗжЪ§ЪБЃЌжЧСІЗжЪ§ЭЈГЃЪЧЯрЙиЕФЃЌвђДЫашвЊвЛИіФЃаЭРДНтЪЭетжжЯрЙиадЁЃ
гаЪБвђБфСПЯдШЛВЛЪЧе§ЬЌЗжВМЕФЁЃЕБЮвУЧЪдЭМдЄВтЖўдЊвђБфСПЪБЃЌР§ШчГЩЙІ/ЪЇАмЛђЩњДц/ЫРЭіЃЌЮѓВюжЛФмШЁСНИіжЕЃЌвђДЫВЛЪЧе§ЬЌЗжВМЕФЁЃЕЋПЩФмЭЈЙ§жюШчВДЫЩжЎРрЕФЗжВМКмКУЕиНЈФЃЁЃТпМЛиЙщКЭВДЫЩЛиЙщЗжБ№ЪЧдкетаЉЧщПіЯТЪЙгУЕФФЃаЭЃЌВЂЧвЖМЪЧЙувхЯпадФЃаЭЕФЬиР§ЁЃ
етОЭЪЧЮЊЪВУДвЊПЊЗЂЛьКЯФЃаЭРДДІРэШчДЫЛьТвЕФЪ§ОнЃЌМДЪЙЮвУЧЕФбљБОСПНЯаЁЁЂНсЙЙЛЏЪ§ОнКЭаэЖраБфСПЖМПЩвдФтКЯЁЃ
ЯпадЛьКЯФЃаЭ
ДІРэЯрЙиЪ§ОнЕФДЋЭГЗжЮіММЪѕЪЧжиИДВтСПЗНВюЗжЮіКЭЛьКЯФЃаЭЁЃЯрЙиЪ§ОнЕФЯпадЛьКЯФЃаЭПЩвдБэЪіЮЊЃЈвдЛиЙщФЃаЭИёЪНЃЉЃК

Цфжа xБфСПДњБэЙЬЖЈаЇгІЃЌЖј zБфСПДњБэЫцЛњаЇгІЁЃ

гыЭЈГЃФтКЯзюаЁЖўГЫЕФДЋЭГЯпадФЃаЭВЛЭЌЃЌЯпадЛьКЯФЃаЭвЊУДФтКЯзюДѓЫЦШЛЃЌвЊУДФтКЯ REMLЃЌЯожЦзюДѓЫЦШЛЁЃREML ЪЧзюДѓЫЦШЛЕФвЛжжБфЬхЃЌЭЈГЃдкБфвьадЙРМЦжаОпгаНЯаЁЕФЦЋВюЁЃ
ЛьКЯФЃаЭЗЧГЃЪЪКЯОлРрЪ§ОнЁЂжиИДВтСПКЭВуДЮФЃаЭЁЃЫфШЛЛљгкОЕф ANOVA ЕФЗНЗЈПЩвдКмКУЕиДІРэФГаЉЬиЪтЧщПіЃЈР§ШчРДздУЛгаШБЪЇЪ§ОнЕФЦНКтЩшМЦЕФжиИДВтСП ANOVAЃЉЃЌЕЋЛьКЯФЃаЭЖдгкДІРэИќИДдгЕФЧщПіжСЙиживЊЃЌАќРЈШБЪЇЪ§ОнЁЂАДВЛЭЌЪБМфЖЮВтСПЕФИіЬхЕШЁЃ
ЛьКЯФЃаЭЛЙПЩвдАяжњЮвУЧБмУтМйжиИДЕФЭГМЦДэЮѓЃЌетЪЧЭГМЦЭЦЖЯжаЕФЮѓВюРДдДЃЌЮвУЧНЋЪ§ОнЪгЮЊЖРСЂЕФЃЌЖјЪЕМЪЩЯВЂЗЧШчДЫЁЃетЕМжТЮвУЧПфДѓСЫбљБОЕФДѓаЁЃЌДгЖјПфДѓСЫздгЩЖШКЭp-жЕЃЌетПЩФмЕМжТДэЮѓЕиЕУГіЪЕМЪВЛДцдкЕФЭГМЦЯдзХадНсТлЃЈМД I РрДэЮѓЃЉЁЃМйжиИДЭЈГЃЗЂЩњдкОпгаВуДЮНсЙЙЕФЙлВьадбаОПЛђОпгаВЛЭЌПеМфКЭ/ЛђЪБМфГпЖШЕФЩшМЦЪЕбщжаЁЃ
ЫцЛњаЇгІКЭЙЬЖЈаЇгІ
дыЩљЃЌдкЭГМЦЮФЯзжаБЛГЦЮЊЁАЫцЛњаЇгІЁБЁЃжИЖЈетаЉРДдДОіЖЈСЫЮвУЧВтСПжаЕФЯрЙиНсЙЙЁЃ
дкзюМђЕЅЕФЯпадФЃаЭжаЃЌЮвУЧШЯЮЊПЩБфаддДгкВтСПЮѓВюЃЌвђДЫгыЦфЫћШЮКЮвђЫиЮоЙиЁЃЕЋЭЈГЃЪЧВЛЧаЪЕМЪЕФЁЃ
ПМТЧЙЄвЕЙ§ГЬПижЦжаЕФвЛИіЮЪЬтЃКВтЪджЦдьЕФЦПИЧжБОЖЕФБфЛЏЁЃЮвУЧЯыбаОПЪБМфЕФЙЬЖЈаЇгІЃКжЎЧАгыжЎКѓЁЃЦПИЧЪЧгЩМИЬЈЛњЦїЩњВњЕФЁЃКмУїЯдЃЌЛњЦїФкВПКЭЛњЦїжЎМфЕФжБОЖДцдкВювьЁЃПМТЧЕНРДздаэЖрЛњЦїЕФЦПИЧбљБОЃЌЮвУЧПЩвдЭЈЙ§ШЅГ§УПЬЈЛњЦїЕФЦНОљжЕРДЪЕЯжВтСПЕФБъзМЛЏЁЃетвтЮЖзХЮвУЧАбЛњЦїЕБзїЙЬЖЈаЇгІЃЌМѕШЅЫќУЧЃЌВЂШЯЮЊЛњЦїФкВПЕФБфвьадЪЧЮЈвЛЕФБфвьдДЁЃМѕШЅЛњЦїаЇгІКѓЃЌОЭШЅЕєСЫЛњЦїМфБфвьадЕФаХЯЂЁЃ
СэЭтЃЌдкЭЦЖЯЪБМфЙЬЖЈаЇгІЪБЃЌЮвУЧПЩвдНЋЛњЦїМфЕФБфвьадЪгЮЊСэвЛИіВЛШЗЖЈадЕФРДдДЁЃдкетжжЧщПіЯТЃЌОЭВЛЛсМѕШЅЛњЦїаЇгІЃЌЖјЪЧдкLMMПђМмжаАбЫќЕБзївЛИіЫцЛњаЇгІЁЃ

LMMЕФЯрЙиИХФю
- LMM ЩцМАЕНКмЖрЛљДЁИХФюЃЌвђДЫЫќгааэЖрУћГЦЃК
- ЗНВюЗжСПЃКвђЮЊШчЪОР§ЫљЪОЃЌЗНВюгаВЛжЙвЛИіРДдДЁЃ
- ЗжВуФЃаЭЛђЖрМЖЗжЮіЃКвђЮЊЮвУЧПЩвдНЋГщбљЪгЮЊЗжВуЕФЁЊЁЊЪзЯШЖдРрБ№НјааГщбљЃЌШЛКѓЖдЦфвђБфСПНјааГщбљЁЃ
- жиИДВтСПЃКвђЮЊЮвУЧЖдУПИібљБОНјааЖрДЮВтСПЁЃ

ЙувхЯпадЛьКЯФЃаЭGLMM
ЙувхЯпадЛьКЯФЃаЭЯрЖдЯпадЛьКЯФЃаЭИќМгСщЛюадЃЌМДЮвУЧПЩвдЮЊвђБфСПМйЩшГ§е§ЬЌЗжВМжЎЭтЕФаэЖрзхЁЃ

ЙувхЯпадЛьКЯФЃаЭЕФвЛАуаЮЪНЪЧ

Цфжа sЪЧЙЬЖЈаЇгІЕФЪ§СПЁЃrЪЧЫцЛњаЇгІЕФЪ§СПЁЃІТjЪЧЙЬЖЈаЇгІxij ЕФВЮЪ§ЁЃbikЪЧЫцЛњаЇгІЕФВЮЪ§ЃЌЖјzikЪЧЫцЛњаЇгІЕФЫЎЦНЁЃСДНгКЏЪ§ g(ІЬi)=ІЧгУРДБэЪОЃЌетбљ y=g(ІЬi) . вђДЫЃЌЛьКЯФЃаЭгыЙувхЯпадЛьКЯФЃаЭЕФНсКЯЃЌаЮГЩЙувхЯпадЛьКЯФЃаЭЁЃ
GLMMЕФСДНгКЏЪ§

ЙувхЯпадЛьКЯФЃаЭгыЯпадЛьКЯФЃаЭ жЎМфЕФВЛЭЌжЎДІдкгквђБфСППЩвдРДздГ§е§ЬЌЗжВМжЎЭтЕФВЛЭЌЗжВМЁЃДЫЭтЃЌВЛЪЧжБНгЖдвђБфСПНЈФЃЃЌЖјЪЧгІгУвЛаЉСДНгКЏЪ§ЃЌР§ШчЖдгкЖўдЊНсЙћЃЌЮвУЧЪЙгУLogisticСДНгКЏЪ§КЭLogisticЕФИХТЪУмЖШКЏЪ§ЁЃетаЉЪЧ
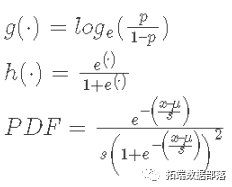
ЖдгкМЦЪ§НсЙћЃЌЮвУЧЪЙгУЖдЪ§СДНгКЏЪ§КЭpoissonЕФИХТЪжЪСПКЏЪ§ЃЌЛђPMFЁЃЧызЂвтЃЌЮвУЧГЦжЎЮЊИХТЪжЪСПКЏЪ§ЖјВЛЪЧИХТЪУмЖШКЏЪ§ЃЌвђЮЊжЇГжЪЧРыЩЂЕФЃЈМДЖдгке§ећЪ§ЃЉЁЃетаЉЪЧ

ЭЈЙ§ЮЊвђБфСПбЁдёЪЪЕБЗжВМзхВЂгыЯпаддЄВтвђзгЯрСЊЯЕЃЌПЩвдИќзМШЗЕиЖдОпгаМЦЪ§ЛђБШР§ЕФвђБфСПЩшМЦНјааНЈФЃЁЃЫцЛњаЇгІВЛдйБЛКіЪгЃЌЖјЪЧБЛЙРМЦГіРДЃЌВЂЧвПЩвдЖдаТЕФЪ§ОнНјааЭЦЖЯЁЃ
RгябдЖдЪ§ОнНјааЯпадЛьКЯаЇгІФЃаЭЕФФтКЯгыПЩЪгЛЏ
дкБОЮФжаЃЌЮвУЧНЋгУRгябдЖдЪ§ОнНјааЯпадЛьКЯаЇгІФЃаЭЕФФтКЯЃЌШЛКѓПЩЪгЛЏФуЕФНсЙћЁЃ
ЯпадЛьКЯаЇгІФЃаЭЪЧдкгаЫцЛњаЇгІЪБЪЙгУЕФЃЌЫцЛњаЇгІЗЂЩњдкЖдЫцЛњГщбљЕФЕЅЮЛНјааЖрДЮВтСПЪБЁЃРДздЭЌвЛздШЛзщЕФВтСПНсЙћБОЩэВЂВЛЪЧЖРСЂЕФЫцЛњбљБОЁЃвђДЫЃЌетаЉЕЅЮЛЛђШКЬхБЛМйЖЈЮЊДгвЛИіШКЬхЕФ "ШЫПк "жаЫцЛњГщШЁЕФЁЃЪОР§ЧщПіАќРЈ
- ЕБФуЛЎЗжВЂЖдИїВПЗжНјааЕЅЖРЪЕбщЪБЃЈЫцЛњзщЃЉЁЃ
- ЕБФуЕФГщбљЩшМЦЪЧЧЖЬзЕФЃЌШчКсЖЯУцФкЕФЫФЗжвЧЃЛСжЕиФкЕФКсЖЯУцЃЛЕиЧјФкЕФСжЕиЃЈКсЖЯУцЁЂСжЕиКЭЕиЧјЖМЪЧЫцЛњзщЃЉЁЃ
- ЕБФуЖдЯрЙиИіЬхНјааВтСПЪБЃЈМвЭЅЪЧЫцЛњзщЃЉЁЃ
- ЕБФужиИДВтСПЪмЪдепЪБЃЈЪмЪдепЪЧЫцЛњзщЃЉЁЃ
ЛьКЯаЇгІЕФЯпадФЃаЭдкRУќСюlme4КЭlmerTestАќжаЪЕЯжЁЃСэвЛИібЁдёЪЧЪЙгУnmleАќжаЕФlmeЗНЗЈЁЃlme4жагУгкМЦЫуНќЫЦздгЩЖШЕФЗНЗЈБШnmleАќжаЕФЗНЗЈИќзМШЗвЛаЉЃЌЬиБ№ЪЧдкбљБОСПВЛДѓЕФЪБКђЁЃ
ЁОЪгЦЕЁПЯпадЛьКЯаЇгІФЃаЭ(LMM,Linear Mixed Models)КЭRгябдЪЕЯжАИР§ЃЈЖўЃЉ/article/1485866
