ШчЙћФуе§дкНјааЭГМЦЗжЮіЃКЯывЊМгвЛаЉЯШбщаХЯЂЃЌзюжеФуЯывЊЕФЪЧдЄВтЁЃЫљвдФуОіЖЈЪЙгУБДвЖЫЙЁЃ
ЕЋЪЧЃЌФуУЛгаЙВщюЯШбщЁЃФуПЩФмЛсЛЈЗбКмГЄЪБМфБраД Metropolis-Hastings ДњТыЃЌгХЛЏНгЪмТЪКЭЬсвщЗжВМЃЌЛђепФуПЩвдЪЙгУ RStanЁЃ
Hamiltonian Monte CarloЃЈHMCЃЉ
HMC ЪЧвЛжжЮЊ MH ЫуЗЈЩњГЩЬсвщЗжВМЕФЗНЗЈЃЌИУЬсвщЗжВМБЛНгЪмЕФИХТЪКмИпЁЃОпЬхЫуЗЈЙ§ГЬЧыВщПДВЮПМЮФЯзЁЃ
ДђИіБШЗНЃК
ИјСЃзгвЛаЉЖЏСПЁЃ
ЫќдкЛЌБљГЁжмЮЇЛЌааЃЌДѓВПЗжЪБМфЖМдкУмЖШИпЕФЕиЗНЁЃ
ХФЩуетЬѕЙьМЃЕФПьееЮЊКѓбщЗжВМЬсЙЉСЫвЛИіНЈвщбљБОЁЃ
ШЛКѓЮвУЧЪЙгУ Metropolis-Hastings НјаааЃе§ЁЃ
NUTSВЩбљЦїЃЈNo-U-turn SamplerЃЉ
HMCЃЌЯёRWMHвЛбљЃЌашвЊЖдВНжшЕФЪ§СПКЭДѓаЁНјаавЛаЉЕїећЁЃ
No-U-Turn Sampler "ЛђNUTsЃЈHoffmanКЭGelmanЃЈ2014ЃЉЃЉЃЌЖдетаЉНјааСЫздЪЪгІЕФгХЛЏЁЃ
NUTSНЈСЂСЫвЛзщПЩФмЕФКђбЁЕуЃЌВЂдкЙьМЃПЊЪМздЯрУЌЖмЪБСЂМДЭЃжЙЁЃ
Stan ЕФгХЕу
ПЩвдВњЩњИпЮЌЖШЕФЬсвщЃЌетаЉЬсвщБЛНгЪмЕФИХТЪКмИпЃЌЖјВЛашвЊЛЈЪБМфНјааЕїећЁЃ
гаФкжУЕФеяЖЯГЬађРДЗжЮіMCMCЕФЪфГіЁЃ
дкC++жаЙЙНЈЃЌЫљвддЫаабИЫйЃЌЪфГіЕНRЁЃ
ЪОР§
ШчКЮЪЙгУ LASSO ЙЙНЈБДвЖЫЙЯпадЛиЙщФЃаЭЁЃ
ЙЙНЈ Stan ФЃаЭ
Ъ§ОнЃКnЁЂpЁЂYЁЂX ЯШбщВЮЪ§ЃЌГЌВЮЪ§
ВЮЪ§ЃК 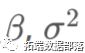
ФЃаЭЃКИпЫЙЫЦШЛЁЂРЦеРЫЙКЭйЄТъЯШбщЁЃ
ЪфГіЃККѓбщбљБОЃЌКѓбщдЄВтбљБОЁЃ
Ъ§Он
int=0> n; vectrn n y; rel=0> a;
ВЮЪ§
vetor\[p+1\] beta; real0> siga;
зЊЛЛКѓЕФВЮЪ§ЃЈПЩбЁЃЉ
vectrn n liped; lnpred = X*bea;
ФЃаЭ
bta ~ dolexneial(0,w); siga ~ gama(a,b); ЛђУЛгаЪИСПЛЏЃЌ for(i in 1:n){ yi i~noral(Xi, i,*beta,siga); }
ЩњГЩЕФЪ§СПЃЈПЩбЁЃЉ
vecor\[n\] yprict; for(i in 1:n){ prditi i = nrmlrng(lnprdi i,siga);
ЖдКѓбщбљБОЕФУПвЛИідЊЫиЖМвЊЦРЙРвЛДЮетИіДњТыЁЃ
жАвЕЩљЭћЪ§ОнМЏ
етРяЮвУЧЪЙгУжАвЕЩљЭћЪ§ОнМЏЃЌЫќгавдЯТБфСП
НЬг§ЃКжАвЕдкжАепЕФЦНОљНЬг§ГЬЖШЃЌФъЁЃ
ЪеШыЃКдкжАепЕФЦНОљЪеШыЃЌдЊЁЃ
ХЎадЃКдкжАепжаХЎадЕФАйЗжБШЁЃ
ЭўЭћЃКPineo-PorterЕФжАвЕЩљЭћЕУЗжЃЌРДздвЛЯюЩчЛсЕїВщЁЃ
ЦеВщЃКШЫПкЦеВщЕФжАвЕДњТыЁЃ
РраЭЃКжАвЕЕФРраЭ
bc: РЖСь
prof: зЈвЕЁЂЙмРэКЭММЪѕ
wc: АзСь
дкRжадЫаа
library(rstan) stan(file="byLASO",iter=50000)
дк3.5УыФкдЫаа25000ДЮдЄШШКЭ25000ДЮВЩбљЁЃ
ЕквЛДЮБрвыc++ДњТыЃЌЫљвдПЩФмашвЊИќГЄЕФЪБМфЁЃ
ЛцжЦКѓбщЗжВМЭМ
par(mrow=c(1,2)) plot(denty(prs$bea)

дЄВтЗжВМ
plot(density)

СДеяЖЯ
splas\[\[1\]\[1:5,\]

СДеяЖЯ
trac("beta" )
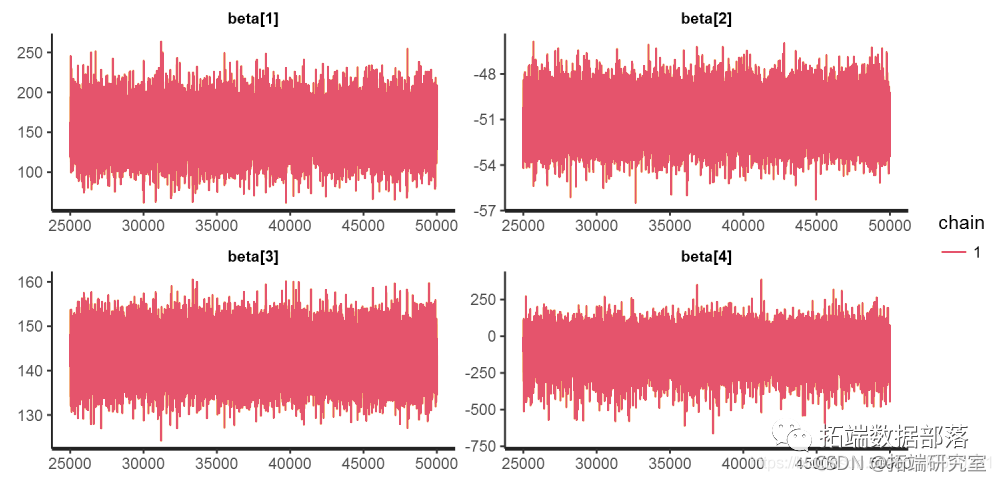
СДеяЖЯ
pa(pars="beta")

ИќЖрСДеяЖЯ
Stan ЛЙПЩвдДгСДжаЬсШЁИїжжЦфЫћеяЖЯЃЌШчжУаХЧјМфЁЂгааЇбљБОСПКЭТэЖћПЩЗђСДЦНЗНЮѓВюЁЃ
СДЕФжЕгыИїжжСДЪєадЁЂЖдЪ§ЫЦШЛЁЂНгЪмТЪКЭВНГЄжЎМфЕФБШНЯЭМЁЃ
Stan ГіДэ
stanЪЙгУЕФВНжшЬЋДѓЁЃ
ПЩвдЭЈЙ§ЪжЖЏдіМгЦкЭћЕФЦНОљНгЪмЖШРДНтОіЁЃ
adapt_deltaЃЌИпгкЦфФЌШЯЕФ0.8
stan(cntl = list(datta = 0.99, mxrh = 15))
етЛсМѕТ§ФуЕФСДЕФЫйЖШЃЌЕЋПЩФмЛсВњЩњИќКУЕФбљБОЁЃ
зджЦКЏЪ§
Stan вВМцШнзджЦКЏЪ§ЁЃ
ШчЙћФуЕФЯШбщЛђЫЦШЛКЏЪ§ВЛБъзМЃЌдђКмгагУЁЃ
model { beta ~ doubexp(0,w); for(i in 1:n){ logprb(Љ\0.5*fs(1Љ\(exp(normalog( siga))/yde)); } }
НсТл
ВЛвЊРЫЗбЪБМфБрТыКЭЕїећ RWMH.
Stan дЫааЕУИќПьЃЌЛсздЖЏЕїећЃЌВЂЧвгІИУЛсВњЩњНЯКУЕФбљБОЁЃ
ВЮПМЮФЯз
Alder, Berni J, and T E Wainwright. 1959. ЁАStudies in Molecular Dynamics. I. General Method.ЁБ The Journal of Chemical Physics 31 (2). AIP: 459ЈC66.
Hoffman, Matthew D, and Andrew Gelman. 2014. ЁАThe No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo.ЁБ Journal of Machine Learning Research 15 (1): 1593ЈC1623.

