Ъ§ОнМЏИХЪі
етИіЪ§ОнМЏГЃгУгкЪ§ОнИХЪіЁЂПЩЪгЛЏКЭОлРрФЃаЭЁЃЫќАќРЈШ§Иі№АЮВЛЈЦЗжжЃЌУПИіЦЗжжга50ИібљБОЃЌвдМАвЛаЉЪєадЁЃЦфжавЛИіЛЈжжгыЦфЫћСНИіЛЈжжЪЧЯпадПЩЗжРыЕФЃЌЕЋЦфЫћСНИіЛЈжжжЎМфВЛЪЧЯпадПЩЗжРыЕФЁЃ
етИіЪ§ОнМЏЕФИјЖЈСаЪЧ:
i> Id
ii> нрЦЌГЄЖШ(Cm)
iii>нрЦЌПэЖШ(Cm)
iv> ЛЈАъГЄЖШ(Cm)
v> ЛЈАъПэЖШ (Cm)
vi> ЦЗжж
ШУЮвУЧАбетИіЪ§ОнМЏПЩЪгЛЏЃЌВЂгУkmeansНјааОлРрЁЃ
ЛљБОПЩЪгЛЏ
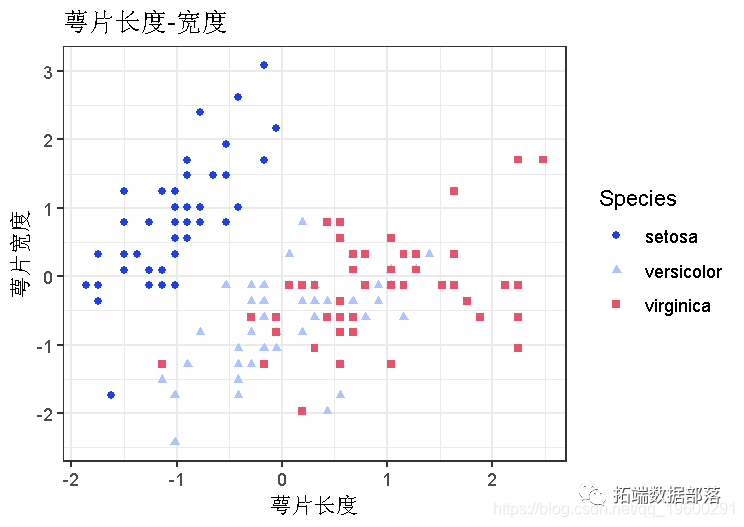
IRISЪ§ОнЃЌОлРрЧАЕФЛљБОПЩЪгЛЏ
plot(data, aes(x , y ))
plot(data,geom_density(alpha=0.25)

Л№ЩНЭМ
plot( iris, stat_density(aes(ymax = ..density.., ymin = -..density..,

plot(data, aes(x ),stat\_density= ..density.., facet\_grid. ~ Species)

ОлРрЪ§Он :: ЗНЗЈ-1
# дквЛИібЛЗжаНјаа15ДЮЕФkmeansОлРрЗжЮі for (i in 1:15) kmeans(Data, i) totalwSS\[i\]<-tot # ОлРрЫщЪЏЭМ - ЪЙгУplotКЏЪ§ЛцжЦtotal_wssгыno-of-clustersЕФЪ§жЕЁЃ plot(x=1:15, # x= РрЪ§СП, 1 to 15 totalwSS, #УПИіРрЕФtotal_wssжЕ type="b" # ЛцжЦСНЕуЃЌВЂНЋЫќУЧСЌНгЦ№РД
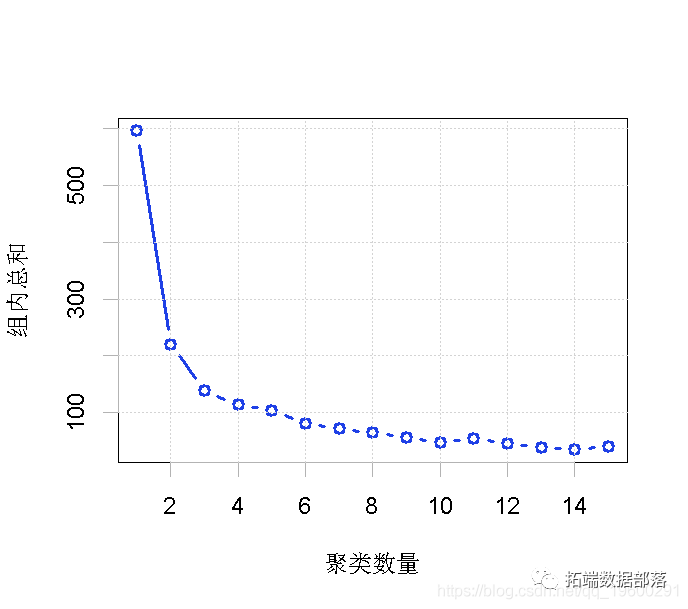
ОлРрЪ§Он :: ЗНЗЈ-2
ЪЙгУОлРргааЇадВтСПжИБъ
library(NbClust) # ЩшжУБпОрЮЊ: c(bottom, left, top, right) par(mar = c(2,2,2,2)) # ИљОнвЛаЉжИБъРДКтСПОлРрЕФКЯЪЪадЁЃ # ФЌШЯЧщПіЯТЃЌЫќМьВщДг2ИіОлРрЕН15ИіОлРрЕФЧщПі # ЛЈЗбЪБМф

анВЎЬижИЪ§
анВЎЬижИЪ§ЪЧвЛжжШЗЖЈОлРрЪ§СПЕФЭМаЮЗНЗЈЁЃ
дканВЎЬижИЪ§ЭМжаЃЌЮвУЧбАеввЛИіУїЯдЕФЙеЕуЃЌЖдгІгкВтСПжЕЕФУїЯддіМгЃЌМДанВЎЬижИЪ§ЕкЖўВюжЕЭМжаЕФУїЯдЗхжЕЁЃ
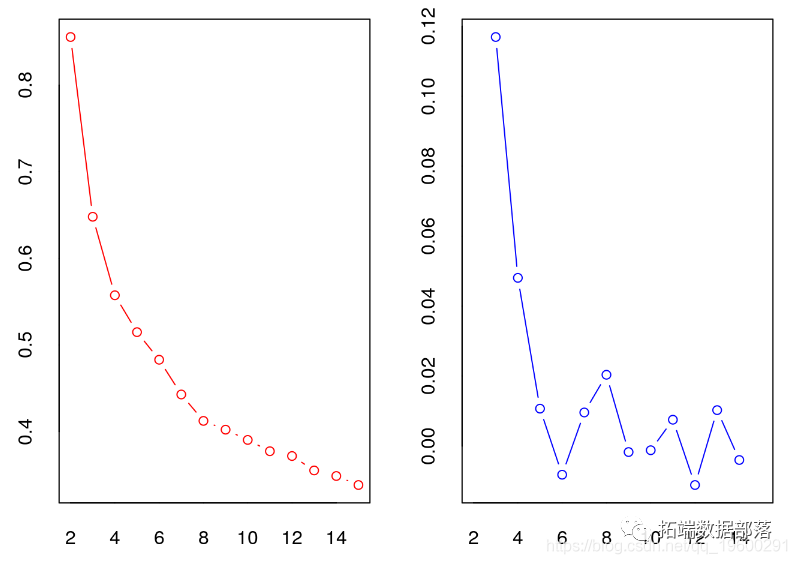
DжИЪ§
дкDжИЪ§ЕФЭМБэжаЃЌЮвУЧбАеввЛИіживЊЕФЙеЕуЃЈDжИЪ§ЕкЖўВюжЕЭМжаЕФживЊЗхжЕЃЉЃЌЖдгІгкВтСПжЕЕФЯджјдіМгЁЃ
## ## ******************************************************************* ## * дкЫљгажИЪ§жа: ## * 10 proposed 2 as the best number of clusters ## * 8 proposed 3 as the best number of clusters ## * 2 proposed 4 as the best number of clusters ## * 1 proposed 5 as the best number of clusters ## * 1 proposed 8 as the best number of clusters ## * 1 proposed 14 as the best number of clusters ## * 1 proposed 15 as the best number of clusters ## ## ***** НсТл***** ## ## * ИљОнЖрЪ§ЙцдђЃЌМЏШКЕФзюМбЪ§СПЪЧ2 ## ## ## *******************************************************************
ЛвЛИіжБЗНЭМЃЌБэЪОИїжжжИЪ§ЖдОлРрЪ§СПЕФЭЖЦБЧщПіЁЃ
дк26ИіжИЪ§жаЃЌДѓЖрЪ§ЃЈ10ИіЃЉЭЖЦБИј2ИіОлРрЃЌ8ИіЭЖЦБИј3ИіОлРрЃЌЦфгр8ИіЃЈ26-10-8ЃЉЭЖЦБИјЦфЫћЪ§СПЕФОлРрЁЃ
жБЗНЭМЃЌЖЯЕу=15ЃЌвђЮЊЮвУЧЕФЫуЗЈЪЧМьВщ2ЕН15ИіОлРрЕФЁЃ
hist(Best.nc)

ОлРрЪ§Он :: ЗНЗЈ-3
ПЈСжЫЙЛљжИБъРрЫЦгкбАевШКзщМфЗНВю/ШКзщФкЗНВюЕФБШТЪЁЃ
KM(Data, 1, 10) # ЖдОлРр1жС10ЕФВтЪд # sortg = TRUEЃКНЋirisЖдЯѓЃЈааЃЉзїЮЊЦфзщБ№ГЩдБЕФКЏЪ§ХХађ # дкШШЭМжагУбеЩЋБэЪОзщГЩдБРр # ХХађЪЧЮЊСЫВњЩњвЛИіИќШнвзНтЪЭЕФЭМБэЁЃ # СНИіЭМЁЃвЛИіЪЧШШЭМЃЌСэвЛИіЪЧОлРрЪ§ФПгыжЕЃЈ=BC/WCЃЉЁЃ

modelData$results\[2,\] # еыЖдBC/WCжЕЕФОлРр

# ФЧУДЃЌетаЉЪ§жЕжаФФвЛИіЪЧзюДѓЕФЃПBC/WCгІОЁПЩФмЕФДѓ which.max(modelData$results\[2,\])

гУSilhoutteЭМЖдЪ§ОнНјааОлРр :: ЗНЗЈ-4
ЯШЪдзХ2ИіРр
# МЦЫуВЂЗЕЛиЭЈЙ§ЪЙгУХЗЪЯОрРыВтСПЗЈМЦЫуЕФОрРыОиеѓЃЌМЦЫуЪ§ОнОиеѓжаИїаажЎМфЕФОрРыЁЃ # ЛёШЁsilhoutte ЯЕЪ§ silhouette (cluster, dis)
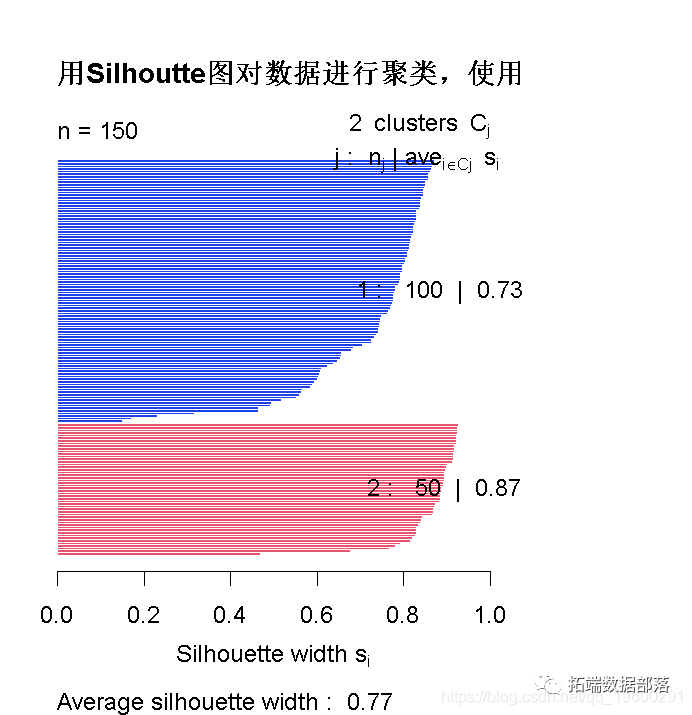
ЪдгУ8ИіОлРр
# МЦЫуВЂЗЕЛиЭЈЙ§ЪЙгУХЗЪЯОрРыВтСПЗЈМЦЫуЕФОрРыОиеѓЃЌМЦЫуЪ§ОнОиеѓжаИїаажЎМфЕФОрРыЁЃ # ЛёШЁsilhoutte ЯЕЪ§ silhouette (cluster, dis)

ЗжЮіОлРрЧїЪЦ
МЦЫуirisКЭЫцЛњЪ§ОнМЏЕФЛєЦеН№ЭГМЦжЕ
# 1. ИјЖЈвЛИіЪ§зжЯђСПЛђЪ§ОнПђМмЕФвЛСа ИљОнЦфзюаЁжЕКЭзюДѓжЕЩњГЩЭГвЛЕФЫцЛњЪ§ runif(length(x), min(x), (max(x))) # 2. ЭЈЙ§дкУПвЛСаЩЯгІгУКЏЪ§ЩњГЩЫцЛњЪ§Он apply(iris\[,-5\], 2, genx) # 3. НЋСНИіЪ§ОнМЏБъзМЛЏ scale(iris) # ФЌШЯ, center = T, scale = T # 4. МЦЫуЪ§ОнМЏЕФЛєЦеН№ЫЙЭГМЦЪ§зж hopkins_stat
# вВПЩвдгУКЏЪ§hopkins()МЦЫуЁЃ hopkins(iris)

# 5. МЦЫуЫцЛњЪ§ОнМЏЕФЛєЦеН№ЫЙЭГМЦСП hopkins_stat


