ЮЌЖШНЕЕЭгаСНИіжївЊгУР§ЃКЪ§ОнЬНЫїКЭЛњЦїбЇЯАЁЃЫќЖдгкЪ§ОнЬНЫїКмгагУЃЌвђЮЊЮЌЪ§МѕЩйЕНМИИіЮЌЖШЃЈР§Шч2Лђ3ЮЌЃЉдЪаэПЩЪгЛЏбљБОЁЃШЛКѓПЩвдЪЙгУетжжПЩЪгЛЏРДДгЪ§ОнЛёЕУМћНтЃЈР§ШчЃЌМьВтОлРрВЂЪЖБ№вьГЃжЕЃЉЁЃЖдгкЛњЦїбЇЯАЃЌНЕЮЌЪЧгагУЕФЃЌвђЮЊдкФтКЯЙ§ГЬжаЪЙгУНЯЩйЕФЬиеїЪБЃЌФЃаЭЭЈГЃЛсИќКУЕиИХРЈЁЃ
дкетЦЊЮФеТжаЃЌЮвУЧНЋбаОПШ§ЮЌНЕЮЌММЪѕЃК
- жїГЩЗжЗжЮіЃЈPCAЃЉЃКзюСїааЕФНЕЮЌЗНЗЈ
- ФкКЫPCAЃКPCAЕФвЛжжБфЬхЃЌдЪаэЗЧЯпад
- t-SNE tЗжВМЫцЛњСкгђЧЖШыЃКзюНќПЊЗЂЕФЗЧЯпадНЕЮЌММЪѕ
етаЉЗНЗЈжЎМфЕФЙиМќЧјБ№дкгкPCAЪфГіа§зЊОиеѓЃЌПЩвдгІгУгкШЮКЮЦфЫћОиеѓвдзЊЛЛЪ§ОнЁЃ
МгдиЪ§ОнМЏ
ЮвУЧПЩвдЭЈЙ§вдЯТЗНЪНМгдиЪ§ОнМЏЃК
df <- read.csv(textConnection(f), header=T) # select characterics of the whiskeys features <- c("Body", "Sweetness", "Smoky", "Medicinal", "Tobacco", "Honey", "Spicy", "Winey", "Nutty", "Malty", "Fruity", "Floral") feat.df <- df[, c("Distillery", features)]
- ЙигкНсЙћЕФМйЩш
дкЮвУЧПЊЪММѕЩйЪ§ОнЕФЮЌЖШжЎЧАЃЌЮвУЧгІИУПМТЧЪ§ОнЁЃ
гЩгкРДздСкНќФ№ОЦГЇЕФЭўЪПМЩЪЙгУРрЫЦЕФеєСѓММЪѕКЭзЪдДЃЌЫћУЧЕФЭўЪПМЩвВгаЯрЫЦжЎДІЁЃ
ЮЊСЫбщжЄетвЛМйЩшЃЌЮвУЧНЋВтЪдРДздВЛЭЌЕиЧјЕФФ№ОЦГЇжЎМфЭўЪПМЩЬиеїЕФЦНОљБэДяЪЧЗёВЛЭЌЁЃЮЊДЫЃЌЮвУЧНЋНјааMANOVAВтЪдЃК
### Df Pillai approx F num Df den Df Pr(>F) ## Region 5 1.2582 2.0455 60 365 3.352e-05 *** ## Residuals 80 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
МьбщЭГМЦСПдк5ЃЅЫЎЦНЩЯЪЧЯдзХЕФЃЌвђДЫЮвУЧПЩвдОмОјСуМйЩшЃЈЧјгђЖдЬиеїУЛгагАЯьЃЉЁЃ
Ф№ОЦГЇЕФЕиРэЮЛжУ
гЩгкЧјгђадЖдЭўЪПМЩЦ№зХживЊзїгУЃЌЮвУЧНЋЭЈЙ§ЛцжЦЦфЮГЖШКЭОЖШРДЬНЫїЪ§ОнМЏжаЕФФ№ОЦГЇЫљдкЕФЮЛжУЁЃвдЯТЫеИёРМЭўЪПМЩЕиЧјДцдкЃК

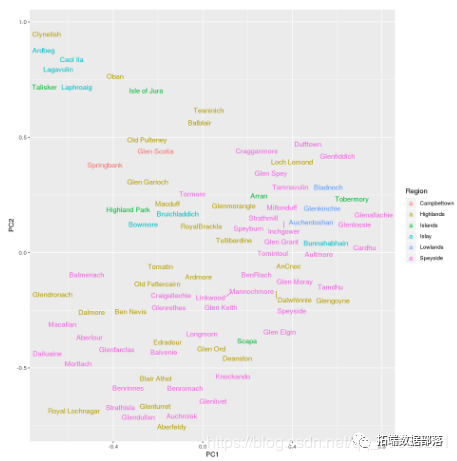
PCA
ЪЙгУPCAПЩЪгЛЏЭўЪПМЩЪ§ОнМЏ

дкЕкЖўИіЭМжаЃЌЮвУЧНЋЛцжЦФ№ОЦГЇЕФБъЧЉЃЌвдБуЮвУЧПЩвдИќЯъЯИЕиНтЪЭОлРрЁЃ

змЕФРДЫЕЃЌжївЊГЩЗжЫЦКѕЗДгГСЫвдЯТЬиеїЃК
- PC1БэЪОЮЖЕРЕФЧПЖШЃКМДбЬбЌЮЖЃЌвЉгУЮЖЃЈШчLaphroaigЛђLagavulinЃЉгыЦНЛЌЮЖЕРЃЈШчAuchentoshanЛђAberlourЃЉ
- PC2БэЪОЮЖЕРЕФИДдгадЃКМДЮЖЕРЬиеїЃЈР§ШчGlenfiddichЛђAuchentoshanЃЉгыИќОпЬиЩЋЕФЮЖЕРЬиеїЃЈР§ШчGlendronachЛђMacallanЃЉ
## Cluster Campbeltown Highlands Islands Islay Lowlands Speyside ## 1 1 2 17 2 2 0 19 ## 2 2 0 8 2 1 3 22 ## 3 3 0 2 2 4 0 0
ЖдМЏШКЕФКЯРэНтЪЭШчЯТЃК
- ШКМЏ1ЃК ИДКЯЭўЪПМЩЃЌжївЊРДздHighlands / Speyside
- ШКМЏ2ЃК ОљКтЕФЭўЪПМЩЃЌжївЊРДздЫЙХхШћЕТКЭИпЕи
- ШКМЏ3ЃК бЬбЌЭўЪПМЩЃЌжївЊРДздАЌРГЕК
ПЩЪгЛЏгаСНИігаШЄЕФЙлВьНсЙћЃК
- ObanКЭClynelishЪЧЮЈвЛвЛИіВњЩњРрЫЦгкАЌРГЕКФ№ОЦГЇПкЮЖЕФИпЕиФ№ОЦГЇЁЃ
- HighlandКЭSpeysideЭўЪПМЩжївЊдквЛИіЗНУцВЛЭЌЁЃдквЛИіМЋЖЫЪЧЦНЛЌЃЌОљКтЕФЭўЪПМЩЃЌШчGlenfiddichЁЃдкСэвЛИіМЋЖЫЃЌЭўЪПМЩЪЧОпгаИќгаЬиЩЋЕФЮЖЕРЃЌШчТѓПЈТзЁЃ
етАќКЌСЫЮвУЧЖдPCAЕФПЩЪгЛЏбаОПЁЃЮвУЧНЋдкБОЮФФЉЮВбаОПЪЙгУPCAНјаадЄВтЁЃ
КЫPCA
ФкКЫPCAЃЈKPCAЃЉЪЧPCAЕФРЉеЙЃЌЫќРћгУСЫФкКЫКЏЪ§ЃЌетаЉКЏЪ§дкжЇГжЯђСПЛњЩЯЪЧжкЫљжмжЊЕФЁЃЭЈЙ§НЋЪ§ОнгГЩфЕНдйЯжФкКЫHilbertПеМфЃЌМДЪЙЫќУЧВЛЪЧЯпадПЩЗжЕФЃЌвВПЩвдЗжРыЪ§ОнЁЃ
дкRжаЪЙгУKPCA
вЊжДааKPCAЃЌЮвУЧЪЙгУАќжаЕФkpcaКЏЪ§kernlabЁЃ
ЦфжаІвІвЪЧЗДЯђФкКЫПэЖШЁЃЪЙгУДЫФкКЫЃЌПЩвдАДШчЯТЗНЪНМѕЩйЮЌЪ§ЃК

МьЫїЕНаТЮЌЖШКѓЃЌЮвУЧЯждкПЩвддкзЊЛЛКѓЕФПеМфжаПЩЪгЛЏЪ§ОнЃК
ОЭПЩЪгЛЏЖјбдЃЌНсЙћБШЮвУЧЪЙгУГЃЙцPCRЛёЕУЕФНсЙћЩдЮЂДжВквЛаЉЁЃОЁЙмШчДЫЃЌРДздАЌРГЕКЕФЭўЪПМЩЗжРыЕУКмКУЃЌЮвУЧПЩвдПДЕНвЛШКЫЙХхШћЬиЭўЪПМЩЃЌЖјИпЕиЭўЪПМЩдђИпЖШДЋВЅЁЃ
T-SNE
t-SNEвбГЩЮЊвЛжжЗЧГЃСїааЕФЪ§ОнПЩЪгЛЏЗНЗЈЁЃ
ЪЙгУt-SNEПЩЪгЛЏЪ§Он
дкетРяЃЌЮвУЧНЋЭўЪПМЩЪ§ОнМЏЕФЮЌЖШНЕЕЭЕНСНИіЮЌЖШЃК

гыPCAЯрБШЃЌДиЕФЗжРыИќМгЧхЮњЃЌЬиБ№ЪЧЖдгкДи1КЭДи2ЁЃ
Ждгкt-SNEЃЌЮвУЧБиаыНјааНтЪЭЃК
- V1БэЪОЮЖЕРИДдгадЁЃетРяЕФвьГЃжЕЪЧгвВрЕФбЬбЌАЌРГЭўЪПМЩЃЈР§ШчLagavulinЃЉКЭзѓВрИДдгЕФИпЕиЭўЪПМЩЃЈР§ШчТѓПЈТзЃЉЁЃ
- V2БэЪОбЬбЌ/вЉгУЮЖЕРЁЃ
ЪЙгУPCAНјааМрЖНбЇЯА
PCAЪЧЖРСЂЭъГЩЕФЃЌетвЛЕужСЙиживЊЁЃвђДЫЃЌашвЊзёбвдЯТЗНЗЈЃК
- дкВтЪдЪ§ОнМЏЩЯжДааPCAВЂдкзЊЛЛКѓЕФЪ§ОнЩЯбЕСЗФЃаЭЁЃ
- НЋбЕСЗЪ§ОнжаЕФбЇЯАPCAБфЛЛгІгУгкВтЪдЪ§ОнМЏЃЌВЂЦРЙРФЃаЭдкБфЛЛЪ§ОнЩЯЕФадФмЁЃ
ЮЊДЫЃЌЮвУЧНЋЪЙгУ?зюНќСкФЃаЭЁЃДЫЭтЃЌвђЮЊЫљгаЕФБфСПЪЧдкЬиеїПеМфаЁ[0,4][0,4]ЁЃЮвУЧБиаыгХЛЏkkЃЌвђДЫЮвУЧЛЙдЄСєСЫгУгкШЗЖЈДЫВЮЪ§ЕФбщжЄМЏЁЃ
PCAзЊЛЛ
ЪзЯШЃЌЮвУЧБраДвЛаЉКЏЪ§РДбщжЄдЄВтЕФадФмЁЃ
get.accuracy <- <strong>function</strong>(preds, labels) { correct.idx <- which(preds == labels) accuracy <- length(correct.idx) / length(labels) return (accuracy) }
дкЯТУцЕФДњТыжаЃЌЮвУЧНЋЖдбЕСЗЪ§ОнжДааPCAВЂбаОПНтЪЭЕФЗНВювдбЁдёКЯЪЪЕФЮЌЪ§
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] ## N_dim 1 2 3 4 5 6 7 8 9 10 11 12 ## Cum_Var 22 41 52 63 72 79 85 90 94 97 99 100
гЩгкгазуЙЛАйЗжБШЕФЗНВюгУ3ЮЌНтЪЭЃЌЮвУЧНЋЪЙгУИУжЕРДЩшжУбЕСЗЃЌВтЪдКЭбщжЄЪ§ОнМЏЁЃ
ЯждкЮвУЧвбОНЋбЕСЗЃЌбщжЄКЭВтЪдМЏзЊЛЛЮЊPCAПеМфЃЌЮвУЧПЩвдЪЙгУkkзюНќСкОгЁЃ
## [1] "PCA+KNN accuracy for k = 9 is: 0.571"
ШУЮвУЧбаОПвЛЯТЪЙгУPCAЕФФЃаЭЪЧЗёгХгкЛљгкдЪМЪ§ОнЕФФЃаЭЃК
## [1] "KNN accuracy for k = 7 is: 0.524" # variances of whiskeys characteristics print(diag(var(data))) ## Body Sweetness Smoky Medicinal Tobacco Honey Spicy ## 0.8656635 0.5145007 0.7458276 0.9801642 0.1039672 0.7279070 0.6157319 ## Winey Nutty Malty Fruity Floral ## 0.8700410 0.6752394 0.3957592 0.6075239 0.7310534
ЯждкЮвУЧжЛФмИљОнЫћУЧЕФПкЮЖШЗЖЈЫеИёРМЭўЪПМЩЕФСљИіЧјгђЃЌЕЋЮЪЬтЪЧЮвУЧЪЧЗёШдФмЛёЕУИќКУЕФБэЯжЁЃЮвУЧжЊЕРКмФбдЄВтЪ§ОнМЏжаДњБэадВЛзуЕФЫеИёРМЕиЧјЁЃФЧУДЃЌШчЙћЮвУЧНЋздМКОжЯогкИќЩйЕФЕиЧјЃЌЛсЗЂЩњЪВУДЃП
- ЕКЭўЪПМЩгыАЌРГЕКЭўЪПМЩзщКЯдквЛЦ№
- Lowland / CampbeltownЭўЪПМЩгыHighlandЭўЪПМЩзщКЯдквЛЦ№
ЭЈЙ§етжжЗНЪНЃЌЮЪЬтМѕЩйЕНШ§ИіЧјгђЃКIsland / IslayЭўЪПМЩЃЌHighland / Lowland / CampbeltownЭўЪПМЩКЭSpeysideЭўЪПМЩЁЃдйДЮНјааЗжЮіЃК
## [1] "PCA+KNN accuracy for k = 13 is: 0.619"
ЮвУЧПЩвдЕУГі61.9ЃЅЕФзМШЗЖШЃЌЮвУЧПЩвдЕУГіНсТлЃЌНЋЮвУЧбљЦЗНЯЩйЕФЭўЪПМЩЧјгђЗжзщШЗЪЕЪЧжЕЕУЕФЁЃ
KPCAгУгкМрЖНбЇЯА
гІгУKPCAНјаадЄВтВЂВЛЯёгІгУPCAФЧбљМђЕЅЁЃдкPCAжаЃЌЬиеїЯђСПЪЧдкЪфШыПеМфжаМЦЫуЕФЃЌЕЋдкKPCAжаЃЌЬиеїЯђСПРДздКЫаФЯЃЖћВЎЬиПеМфЁЃвђДЫЃЌЕБЮвУЧВЛжЊЕРЫљЪЙгУЕФЯдЪНгГЩфКЏЪ§??ЃЌВЛПЩФмМђЕЅЕизЊЛЛаТЪ§ОнЕуЁЃ
# NB: this would overestimate the actual performanceaccuracy <- get. accuracy(preds.kpca, df$Region[samp.test])
еЊвЊ
дкетРяЃЌЮвУЧПДЕНСЫШчКЮЪЙгУPCAЃЌKPCAКЭt-SNEРДНЕЕЭЪ§ОнМЏЕФЮЌЪ§ЁЃPCAЪЧвЛжжЪЪгУгкПЩЪгЛЏКЭМрЖНбЇЯАЕФЯпадЗНЗЈЁЃKPCAЪЧвЛжжЗЧЯпадНЕЮЌММЪѕЁЃt-SNEЪЧвЛжжИќаТЕФЗЧЯпадЗНЗЈЃЌЩУГЄПЩЪгЛЏЪ§ОнЃЌЕЋШБЗІPCAЕФПЩНтЪЭадКЭЮШНЁадЁЃ
етПЩФмБэУївдЯТСНЕужЎвЛЃК
- ГЂЪдаТЕФЕФЭўЪПМЩШдгаКмДѓЕФЧБСІЁЃ
- гаКмЖржжЮЖЕРЕФзщКЯЪЧПЩФмЕФЃЌВЂЧвКмКУЕиНсКЯдквЛЦ№ЁЃ
ЮвЧуЯђгкбЁдёЕкЖўжжбЁдёЁЃЮЊЪВУДЃПдкPCAЭМжаЃЌгвЯТНЧЪЧУЛгабљБОЫљдкЕФзюДѓЧјгђЁЃПДзХППНќетИіЧјгђЕФЭўЪПМЩЃЌЮвУЧЗЂЯжФЧаЉЪЧyжсЩЯЕФMacallanКЭxжсЩЯЕФLagavulinЁЃТѓПЈТзвдЦфИДдгЕФПкЮЖЖјЮХУћЃЌLagavulinвдЦфбЬбЌЮЖЖјЮХУћЁЃ
ЮЛгкЖўЮЌPCAПеМфгвЯТЗНЕФЭўЪПМЩНЋЭЌЪБОпгаСНжжЬиадЃКЫќМШИДдггжбЬбЌЁЃЮвВТетжжОпгаСНжжЬиадЕФЭўЪПМЩЖдгкПкИаРДЫЕЬЋЙ§ЗжСЫЁЃ

