1. ЙЋЫОМђНщ
гУгбГЉНнЭЈЪЧжаЙњСьЯШЕФаЁЮЂЦѓвЕВЦЫАМАвЕЮёдЦЗўЮёЬсЙЉЩЬЃЌЙЋЫОГЩСЂгк2010ФъЃЌЪЧгУгбЦьЯТГЩдБЦѓвЕЃЌжТСІгкгУММЪѕКЭДДЯыЭЦЖЏаЁЮЂЦѓвЕОгЊЙмРэНјВНЁЃ
- 2012ФъжЎЧАШэМўАќЪБДњЃЌЭЦГіT1/T3/T6/T+ЃЛ
- 2013ММЪѕзЊаЭЃЌВПЪ№КЭЭЖШыбаЗЂзЊ SaaSЃЛ
- 2014-16Ъ§жЧВЦЫААхПщЭЛЦЦЃЌЭЦГіКУЛсМЦЁЂвзДњеЫЃЌ16-18ЭЦГіКУЩњвтЁЂT+CloudЃЛ
- 2019-жСНёЭъЩЦдЦдЩњЦНЬЈЁЂКУвЕВЦЁЃ
2. вЕЮёБГОА

ГЉНнЭЈЪЕЪБЪ§ВжашЧѓФЧУДЦШЧаЕФдвђЃЌжївЊгавдЯТЫФЕуЃК
ЪзЯШЪЧРњЪЗАќИЄЃЌЮвУЧЛсгавЛаЉЖрЮЌЗжЮіЁЂБъЧЉМЦЫуЕФНсЙћУПЭэЛиаДвЕЮёПтЃЌЛиаДаЇТЪВЛЮШЖЈОЭЛсЖддчИпЗхЕФвЕЮёгаГхЛїЃЌгааЉТ§ВщбЏЛсНЕЕЭвЕЮёПтЕФадФмЃЌЛЙгаЪ§ОнЙТЕКЯжЯѓЪЧБШНЯбЯжиЕФЃЛ
ЦфДЮвЕЮёЫпЧѓЃЌДЋЭГЕФT+1ГЁОАвбОВЛдйТњзувЕЮёашЧѓЃЌвЕЮёвЊЧѓЕФЪ§ОндНРДдНЪЕЪБЃЌСэЭтВњЦЗВрвВШБЗІДѓЪ§ОнЗжЮіЕФФмСІЃЛ
ШЛКѓОЭЪЧММЪѕВЛЭГвЛЃЌЙЋЫОФкВПВЛЭЌгІгУЖМдкЪЙгУВЛЭЌЕФЪ§ОнВжПтЃЌЖдгкПЊЗЂШЫдБЕФбЇЯАГЩБОЁЂЪЙгУГЩБОЖМБШНЯИпЃЌГіЯжЮЪЬтЪБЃЌЖЈЮЛЮЊЬтЪБМфБШНЯГЄЃЛ
зюКѓвЛЕуОЭЪЧБъзМЛЏНЈЩшЃЌећИіЙЋЫОФкВПЕФБъзМЛЏНЈЩшВЛзуЃЌбЬДбЪНПЊЗЂЯжЯѓБШНЯЦеБщЃЌЙВгаТпМУЛгаЯТГСЁЃ

дкНщЩмЪ§ВжбЁаЭжЎЧАЃЌЮвУЧЯШРДПДЯТГЉНнЭЈЕФећИіЪ§ВжЕФвЛИіЗЂеЙТЗЯпЃЌЪзЯШЪЧРыЯпНзЖЮЃЌЭЈЙ§РыЯпМЦЫуЦНЬЈЛузмзђШеЪ§ОнЃЌЪ§ВжЗжВуЃЌНјааМЦЫуЃЌНсЙћЛиаДЃЌЪ§ОнЧыЧѓЗжСїЃЛШЛКѓЪЧЕкЖўИіНзЖЮЃЌвВОЭЪЧГѕЪМНзЖЮЃЌИїИівЕЮёЯпПЊЪМбЁдёЪЪКЯздМКЕФЪ§ОнВжПтЃЌБШШч ClickHouseЃЌADBЃЌHologresЃЛНгЯТРДОЭЪЧЗЂеЙНзЖЮЃЌвВОЭЪЧФПЧАећИіЙЋЫОЕФвЕЮёЯпж№ВНЯђ StarRocks ППЦыЃЌРћгУ StarRocks РДзіЭГвЛЕФЪ§ВжНтОіЗНАИЁЃ
3. ММЪѕбЁаЭ

ЮвУЧЕБЪБдкзіЪ§ОнВжПтбЁаЭЕФЪБКђжївЊЕФЫМТЗЪЧДгвЕЮёБГОАЃЌПЩГжајвдМАЪЕМљШ§ИіЗНУцРДПМТЧЪ§ОнВжПтбЁаЭЃК
ЪзЯШЪЧвЕЮёБГОАЃЌЮвУЧашвЊИљОнЮвУЧЕФвЕЮёГЁОАНјаавЛИіећЬхПМТЧЃЌвВОЭЪЧбЁдёЕФЪ§ОнВжПтвЛЖЈвЊИВИЧзЁЮвУЧДѓЖрЪ§ЕФвЕЮёГЁОАЃЌВЂЧвВщбЏадФмвЊзуЙЛгХауЃЌЧвзюКУФмМцШн MySQL ЕФВщбЏгяЗЈЃЌетбљЕФЛАПЊЗЂШЫдБбЇЯАГЩБОПЩвдНЕЕЭЁЃ
ЦфДЮПЩГжајЃЌПЊдДЩчЧјвЊзуЙЛЛюдОЃЌШэМўжЪСПгаБЃеЯЃЌЪаГЁеМгаТЪНЯИпЃЌЩчЧјжЇГжНЯКУЁЃ
зюКѓЪЧЪЕМљЃЌЮвУЧЛсгУецЪЕЕФвЕЮёГЁОАНјаабщжЄЃЌШЛКѓЛЙашвЊПМТЧгыЮвУЧЕБЧАСДТЗЕФвЛИіЦѕКЯЖШЃЌБЯОЙЮвУЧУЛЗЈДг0ПЊЪМжиНЈЁЃ

етЪЧЮвУЧЕБЪБЪдгУКѓОѕЕУБШНЯгХауЕФШ§ИіЪЕЪБЪ§ВжЕФвЛИіЖдБШЃЌДѓМвПЩвдздааВщПДЁЃ
змжЎЃЌдкПЊдДавщЁЂЙІФмЭъЩЦЖШЁЂВњЦЗГЩЪьЖШЁЂПЭЛЇАИР§гыЗўЮёжЇГжЬхЯЕЕШЗНУцзлКЯПМТЧКѓЃЌЮвУЧбЁдёСЫ EMR StarRocksЁЃ
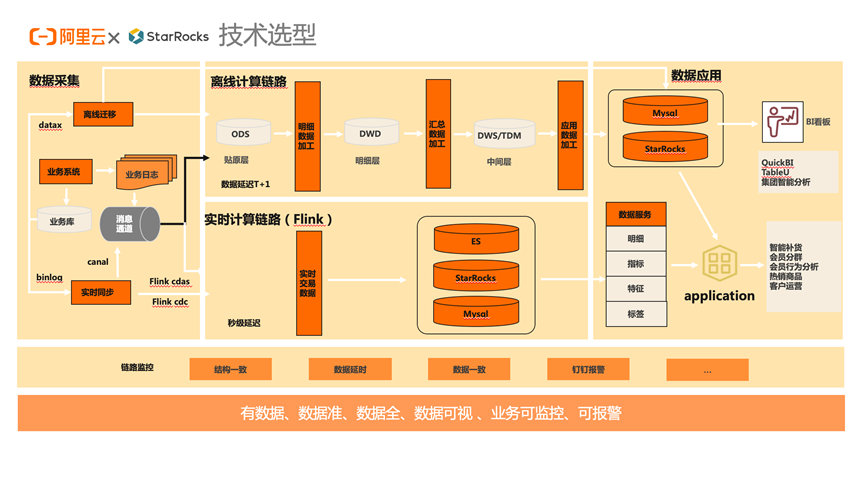
етЪЧЮвУЧдкзіЭъ EMR StarRocks ММЪѕбЁаЭКѓЕФећИіЪ§ОнВжПтЕФММЪѕМмЙЙЭМЃЌгЩгквЛаЉРњЪЗдвђЃЌЮвУЧФПЧАЕФећИіЪ§ОнВжПтЕФЭЌВНСДТЗЛЙгаКмДѓЕФОжЯовдМАЕїећПеМфЃЌЮвУЧвВдкВЛЙмЕФНјааЕќДњЕїећЃЌДгзѓВрЕФЪ§ОнВЩМЏФЃПщЕНгвВрЕФЪ§ОнгІгУФЃПщЮвУЧЗжЮЊРыЯпt+1Ъ§ОнСДТЗгыЪЕЪБЪ§ОнСДТЗЃК
РыЯпЕФ t+1 Ъ§ОнСДТЗЭЈЙ§ datax Ъ§ОнЧЈвЦЙЄОпЃЌЛђепРыЯпМЦЫуЦНЬЈжБНгЕН MySQL Лђеп StarRocksЁЃ
ЪЕЪБМЦЫуСДТЗжївЊЭЈЙ§ Flink DataStreamЁЂFlink CDC ЁЂFlink CDAS ЪЕЪБЭЌВНЕН ESЁЂStarRocksЁЂMySQL жаЁЃ
4. АИР§ЗжЯэ
НгЯТРДИјДѓМвЗжЯэвЛЯТЮвУЧвЕЮёФПЧАЕФМИИіАИР§ЁЃ
4.1 АИР§вЛ
ЪзЯШЪЧЪЕЪБДѓЦСЃЌетПщЕФећИіБГОАОЭЪЧЃЌЫцзХИїааИївЕЖдЪ§ОндНРДдНжиЪгЃЌЪЕЪБМЦЫуММЪѕвВдкВЛЖЯЕФбнНјЃЌДгЪБаЇадЩЯРДНВЃЌЖдгкT+1ЛђепаЁЪБМЖЕФМЦЫувбОВЛФмТњзуПЭЛЇЕФашвЊЃЌашЧѓж№НЅДгЪБДАЧ§ЖЏЩ§МЖЕНЪТМўЧ§ЖЏЃЌЩѕжСУПВњЩњвЛЬѕЪ§ОнЃЌЖМЯыОЁПьПДЕНЪ§ОнЁЃ

СэвЛИіБГОАОЭЪЧвЕЮёСьгђДцдкДѓСПЕФТ§ SQLЃЌБЈБэВщбЏжДаааЇТЪЕЭЯТЃЌЗжПтЗжБэЁЂЫїв§ЕїећЕШЪжЖЮвбОЮоЗЈЬсЩ§ВщбЏаЇТЪЁЃ
вђДЫЮвУЧЦШЧаЕФашвЊвЛПюЪЪКЯЕФЁЂВщбЏадФмгХауЕФ OLAP ВщбЏв§ЧцРДЬсЩ§ЮвУЧЕФВщбЏаЇТЪЁЃ

етЪЧЪЕЪБДѓЦСЕФМмЙЙЭМЃЌвЕЮёЪ§ОнЭЈЙ§ Flink CDAS / CDC ЭЌВНЕН StarRocks ЬљдДВуЃЌШЛКѓЬљдДВуЪ§ОнЭЈЙ§ЮяЛЏЪгЭМж№ВуНјааМгЙЄЃЈStarRocksЧПДѓЕФЮяЛЏЪгЭМФмСІШУЮвУЧИќФмзЈзЂгкФЃаЭЕФНЈЩшЖјВЛЪЧЪ§ОнСДТЗЕФДюНЈЃЉЃЌзюКѓгЩ ADS ВуЪ§ОнЖдЭтЬсЙЉЪ§ОнжЇГжЃЌБШШч BI ПДАхЃЌИїжжЯюФПБЈБэЁЃ
4.2 АИР§Жў
ЕкЖўИіАИР§дђЪЧ BC вЛЬхЛЏБЈБэеЙЪОЃЌГЉНнЭЈКУЩњвташвЊАяжњФГДѓЦЗХЦЩЬЙЙНЈЪ§ОндЫгЊжаЬЈЃЌДгЩЬЦЗжїЪ§ОнЭГвЛЯТЗЂЃЌЕНЖрЮЌЖШЗжЮівЛМЖОЯњЩЬЁЂЖўМЖОЯњЩЬЕФЩЬЦЗЪлТєЧщПіЁЂЯжгаПтДцЧщПіЃЌФмИќКУЕФИГФмОЯњЩЬЃЌДгдРДЕФЩюЖШЗжЯњЕНЖЏЯњФЃаЭЃЛЪЕЯжЪ§ОнМлжЕЕФЩюЖШгІгУЃЌДгЖјАяжњЦЗХЦЩЬзіИќКУЕФОіВпОгЊЁЃ

ИќЮЊживЊЕФвЛЕуЪЧЃЌеце§зіЕНСЫГЉНнЭЈЬхЯЕФкВњЦЗЕФЛЅЭЈЃЈCCКЭTCЃЉЃЌЪЕЯжСЫЩчЛсЛЏСДНгЁЃЪ§ОндЫгЊжаЬЈВњЦЗЮДРДПЩвдгыИќЖрЕФЦЗХЦЩЬЖдНгЃЌвдБъзМВњЦЗШЅНЛИЖЁЃСэЭтвЛЕуЪЧЛ§РлОбщПЩвдНјааКѓЦкХњСПЕФНЛИЖЃЌШЛКѓдкећИіЙ§ГЬжаЭъЩЦВњЦЗЕФРЉеЙФмСІКЭПЊЗХадЃЌДгЖјЬсЩ§ВњЦЗОКељСІЁЃ

ећИіВњЦЗМмЙЙЭМШчЩЯЭМЫљЪОЃЌЪ§ОндЫгЊжаЬЈПЩвдРэНтЮЊзмВПЃЌШЛКѓНјааЪ§ОнЯТЗЂЕНвЛМЖЁЂЖўМЖОЯњЩЬЃЌОЯњЩЬЕФЪ§ОнЭЈЙ§РыЯп T+1ЩЯДЋИјзмВПЁЃ

етЪЧвЛИіећЬхЕФММЪѕМмЙЙЭМЃЌвЛЖўМЖОЯњЩЬЭЈЙ§Ъ§ОнЗўЮёЩЯДЋИј OSSЃЌШЛКѓЭЈжЊЪ§ОндЫгЊжаЬЈШЅ OSS ЩЯРШЁЪ§ОнЃЌШЛКѓЩЯДЋИј StarRocksЃЌВЩгУ OSS ЗўЮёЦїзїЮЊжаМфДцДЂЃЌЪЕЯж T+1 ЕФЪ§ОнЧхРэЗўЮёгы CC ЕФЪ§ОнЩЯДЋЗўЮёЯрЛЅИєРыЃЌЯрЛЅНтёюЃЌЪ§ОнЩЯДЋЪЇАмКѓЃЌЛжИДИќЮЊБуНнЁЃ
4.3 АИР§Ш§
зюКѓвЛИіАИР§ЪЧгУЛЇЛЯёЕФАИР§
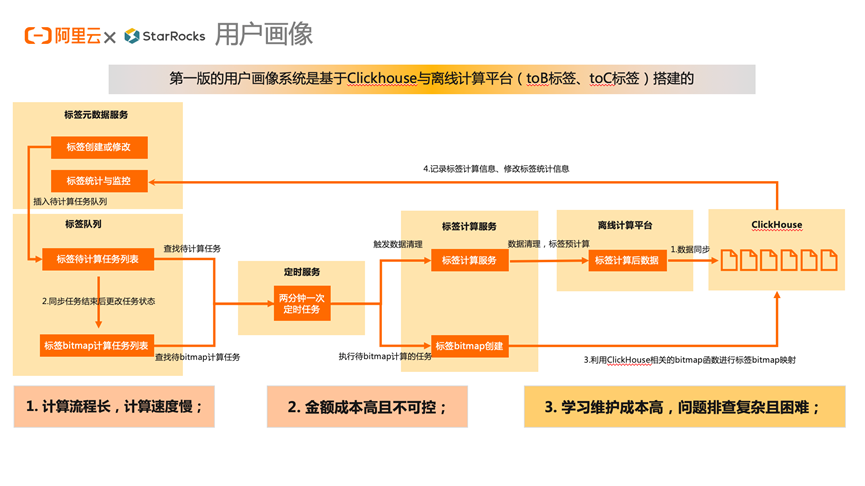
ЮвУЧзюПЊЪМЕФЕквЛАцЪЧЛљгк ClickHouse гыРыЯпМЦЫуЦНЬЈДюНЈЕФЃЌЮвУЧгаИіБъЧЉдЊЪ§ОнЗўЮёЛсНЋМЦЫуЕФБъЧЉВхШыЕїЖШЖгСаЃЌШЛКѓгЩЕїЖШЗўЮёНјааЕїЖШЃЌРыЯпМЦЫуЦНЬЈПЊЪММЦЫуЃЌМЦЫуНсЙћКѓЭЌВНЕН ClickHouseЃЌШЛКѓЕїећШЮЮёзДЬЌВхШы bitmap МЦЫуЕФШЮЮёСаБэЃЌдйгЩЕїЖШЗўЮёНјааЕїЖШНјаа bitmap ДДНЈЁЃ
гаКмЖрХѓгбПЩФмЛсЮЪЮЊЪВУДВЛФмжБНгЪЙгУ bitmap ЯрЙиКЏЪ§НјааМЦЫуЃЌжївЊЛЙЪЧвђЮЊЮвУЧЪЧвЛИі tob БъЧЉЯЕЭГЃЌаЁЮЂЦѓвЕгУЛЇПЩвдИљОнашвЊздМКЖЈвхздМКЕФБъЧЉЁЃ

ШЛКѓЮвУЧИјгш StarRocks ЪЕЪБЪ§ВжНјСЫЕкЖўАцЕФИФдьЩ§МЖЃЌЕкЖўАцЪЧЛљгк StarRocks ЕФЪ§ОнДІРэКЭМЦЫувЛЬхЛЏЕФИпадФмБъЧЉЬхЯЕЃЌвЕЮёЪ§ОнЭЈЙ§РыЯпМЦЫуЦНЬЈгы Flink ЭЌВНЕН StarRocksЃЌЪ§ОнзМБИЭъГЩКѓЃЌЗЂЫЭЯћЯЂЖгСаРћгУ StarRocks ЕФВщбЏФмСІгыЗсИЛЕФ bitmap КЏЪ§НјааМЦЫуЃЌМЦЫуЭъКѓЛсаДЕНдЊЪ§ОнЗўЮёЁЃ

гУ StarRocks ЬцДњжЎЧАЕФ ClickHouse+ РыЯпМЦЫуЦНЬЈЕФЗНАИЃЌЬсЩ§СЫБъЧЉЪБаЇадЃЌМђЛЏСЫБъЧЉЕФМЦЫуСїГЬЁЂЬсЩ§СЫБъЧЉМЦЫуЫйЖШЁЂЭЛЦЦСЫБъЧЉЕФЪ§СПЯожЦЁЂПижЦСЫБъЧЉМЦЫуГЩБОЁЂНјвЛВНЕФБЃжЄСЫБъЧЉЯЕЭГЕФЮШЖЈадЁЃ
5. зюМбЪЕМљЗжЯэ
АИР§ЗжЯэНсЪјЃЌНгЯТРДдйДгЪ§ОнВЩМЏЁЂЪ§ОнЗжЮіЗНУцРДзівЛИіРрЫЦзюМбЪЕМљЕФЗжЯэЁЃ

5.1 дкЪ§ОнВЩМЏЃЌРыЯпЪ§ОнЧЈвЦЗНУц
- Streamload ДњЬцДЋЭГ insert into ЕМШыЪ§ОнЃЌhttp авщЕМШыЃЌЫйЖШИќПьЃЌЧсСПМЖЃЌДгЖјБмУт insert into ДјРДЕФЖрАцБОЕМжТЕФВщбЏадФмЮЪЬтЁЃ
- ПижЦЩЯДЋЪ§ОнЬсНЛЕНЪ§ВжЕФЦЕТЪЃЌБмУтвђЮЊЬсНЛЦЕЗБГіЯж get writedb lock ЕФЧщПіГіЯжЁЃ
- Ъ§ОнЩЯДЋЪЇАмЃЈБШШчЭјТчЖЖЖЏЁЂЛёШЁЫјГЌЪБЃЉЃЌПЩвдНјааЖрДЮЩЯДЋжиЪдЃЌШчЙћзюжеЪЇАмЃЌНјааБЈОЏЃЌПДЕНКѓПЩвдСЂТэЛжИДЁЃ
5.2 дкЪ§ОнВЩМЏЃЌЪЕЪБЪ§ОнЭЌВНЗНУц
ЮвУЧОРњСЫДг Canal-ЯћЯЂЭЈЕРЃЌFlink CDC дйЕН Flink CDAS ећИіЭЌВНСДТЗЕФвЛИіБфЛЏЁЃ
5.2.1 Canal-ЯћЯЂЭЈЕР
- СДТЗГЄЃЌЪ§ОнбгГйНЯИпЃЌЮШЖЈадНЯВюЁЃ
- ЮЪЬтХХВщРЇФбЃЌПчдНСЫ canalЁЂЯћЯЂЭЈЕРЁЂгІгУВрЖрИіЭХЖгЃЌгаЪБКђХХВщЮЪЬтвЊРКмЖрШЫЃЌаЇТЪБШНЯЕЭЁЃ
- ЮоЗЈШЋдіСПздЖЏЧаЛЛЃЌвВОЭЪЧЮоЗЈСїХњвЛЬхЁЃ
5.2.2 Flink CDC
- Mysql ЕФ DDL ЪжЖЏгГЩфГЩ Flink ЕФ DDLЃЌЗБЫіЧввзГіДэЁЃ
- БэНсЙЙЕФБфИќЕМжТШыВжСДТЗФбвдЮЌЛЄЁЃ
- ЖрБэШыВжЃЌMySQL бЙСІЃЌIO ЭјТчбЙСІЃЌFlink зЪдДЯћКФЖМКмОоДѓЁЃ
5.2.3 Flink CDAS НјааЪЕЪБЪ§ОнЭЌВН
- СїХњвЛЬхЁЃ
- ПЊЗЂЮЌЛЄЗЧГЃМђЕЅЃЌМИааДњТыОЭПЩвдЭъГЩЭЌВНСДТЗЕФДюНЈЁЃ
- StarRocsk catalogЃЌздЖЏНЈБэЁЃ
- Schema EvolutionФкКЫЃЌздЖЏЭЌВНБфЛЏзжЖЮЁЃ
- SourceКЯВЂгХЛЏЃЌМѕЧсЖддДЖЫЪ§ОнПтЕФбЙСІЁЃ
5.2.4 Ъ§ОнЗжЮі
МШШЛЮвУЧАбвЛаЉБЈБэВщбЏжБНгБЉТЉИјСЫгУЛЇВщбЏЃЌПЯЖЈашвЊЕЃаФвЛИі QPS ЕФЮЪЬтЃЌЮвУЧЪЧЭЈЙ§ЯТУцСНЕуРДНјаа QPS ЕФПижЦ
- ЮяЛЏЪгЭМИФаДЬсЩ§ВщбЏаЇТЪгыВЂЗЂЃЈЮяЛЏЪгЭМЕФИФаДКѓЃЌЮоашЯжВщЯжЫуЃЌВщбЏаЇТЪЕУЕНИќНјвЛВНЬсЩ§ЃЌИќПьЕФЗЕЛиНсЙћЃЌИќИпЕФ QPSЃЉ
- АДзтЛЇПЊЗХЪ§ВжВщбЏЃЈжЛЮЊВПЗжзтЛЇПЊЗХЪ§ОнВжПтЕФВщбЏЃЌУЛгаВщбЏадФмЦПОБЕФзтЛЇЃЌЛЙЪЧВщбЏвЕЮёПтЃЉ

5.2.5 ВщбЏаЇТЪгХЛЏЗНЪН
- ашвЊЬсЧАОлКЯМЦЫуЕФБэДДНЈОлКЯФЃаЭЃЛ
- ашвЊзіРфШШДцДЂЕФБэЃЌвЛЖЈвЊЬсЧАНЈСЂЗжЧјЃЌЗЧЗжЧјБэВЛдЪаэНЈЗжЧјЃЛ
- жїМќФЃаЭРДЬцДњИќаТФЃаЭЃЌИќаТФЃаЭЃЌmerge on readЃЌЮоЗЈНјааЮНДЪЯТЭЦЃЌВщбЏаЇТЪВЛШчжїМќФЃаЭИпЃЛ
- ЖдгкОГЃВщбЏЕФзжЖЮЃЌПЩвдНЈСЂХХађМќЃЛ
- ЖдгкЛљЪ§БШНЯаЁЃЌЧвгжОГЃВщбЏЕФзжЖЮПЩвдДДНЈbitmapЫїв§ЃЌРћгУbitmapЫїв§РДМгПьВщбЏЫйЖШЃЛ
- Ждгкin КЭ = Й§ТЫЬѕМўЕФВщбЏЃЌвВПЩвдЪЙгУВМТЁЙ§ТЫЦїЫїв§РДЬсИпЫїв§ВщбЏЫйЖШЃЛ

6. ЮДРДЗЂеЙ
зюКѓЪЧЮДРДЗЂеЙЃЌЮДРДЗЂеЙетПщЃЌжївЊгаЫФИіЗНЯђЃК
ЪзЯШЃЌЮвУЧвЊзіЕФОЭЪЧжїгІгУВ№ПтЃЌФПЧАЪ§ВжЪЧАДеежааФНјааВ№ЗжЕФЪ§ОнПтЃЌКѓајАДжїгІгУВ№ЗжПтЃЌВЛЭЌЕФжїгІгУЖдгІВЛЭЌЕФЪ§ОнПтЃЌДгЖјЗжЩЂПтЫјЛёШЁбЙСІЁЃ
ЦфДЮЃЌlambda МмЙЙЕїећЃЌДѓМвПЩвдДгЮвЩЯУцЕФЪ§ОнВжПтФПЧАСДТЗЕФећЬхМмЙЙЭМжаПЩвдПДЕНЮвУЧВПЗжвЕЮёЛЙЮоЗЈзіЕНСїХњвЛЬхЃЌашвЊЮЌЛЄРњЪЗРыЯпЁЂЪЕЪБДІРэСНЬзДњТыЃЌКѓајашвЊЕїећlambdaЪ§ОнСДТЗЃЌБмУтЖрЬзДњТыЕФЮЌЛЄЁЃ
ШЛКѓСїГЬЛЏЙмРэЃЌStarRocks НХБОЩЯЯпЕїећЃЌЛЙгаЪЕЪБ Flink СДТЗЕїећЃЌКѓајОљФЩШыЩЯЯпСїГЬЙЄОпЃЌНтЗХШЫСІЃЌНЕЕЭСДТЗЙЪеЯИХТЪЁЃ
зюКѓКўВжвЛЬхЗНАИЕФЬНЫїЃЌЫЕЪЕЛАЃЌФПЧА EMR StarRocks ЪЕЪБЪ§ВждкЙЋЫОФкВПЛЙЪЧБШНЯЛ№ШШЕФЃЌаэЖрвЕЮёГЁОАЖМЯыНгШы StarRocksЃЌаТвЕЮёГЁОАПЩФмвбОВЛдйОжЯогкНіЪЙгУНсЙЙЛЏЪ§ОнЃЌАыНсЙЙЁЂЗЧНсЙЙЛЏЪ§ОнгІгУГЁОАдНРДдНЖрЃЌКўВжвЛЬхЗНАИвВашвЊЙцЛЎПМТЧЁЃ

зюКѓИааЛ EMR StarRocks ЭХЖгЭЌбЇЕФжЇГжЃЌЯЃЭћЮДРДМЬајНєУмКЯзїЃЌКЯзїЙВгЎЁЃ
ЛЖгЖЄЖЄЩЈТыМгШыEMR Serverless StarRocksНЛСїШКЃЈЫбЫїЖЄЖЄШККХМгШКЃК24010016636ЃЉ