дкетИіЪ§ОнЧ§ЖЏЕФЪБДњЃЌШчКЮПьЫйЁЂзМШЗЕиДгКЃСПЪ§ОнжаМьЫїЕНЫљашЕФаХЯЂЃЌЪЧЫљгаЦѓвЕУцСйЕФЙВЭЌЬєеНЁЃMilvus зїЮЊвЛПюдЦдЩњПЊдДЯђСПМьЫїв§ЧцЃЌЛљгк FaissЁЂAnnoyЁЂHNSW ЕШжЊУћПтЙЙНЈЃЌВЂНјааСЫгХЛЏЃЌЪЕЯжСЫИпПЩгУЁЂИпадФмЁЂвзРЉеЙЕФЬиадЃЌЪЪгУгкДІРэКЃСПЯђСПЪ§ОнЕФЪЕЪБейЛиЁЃ
АЂРядЦЯђСПМьЫї Milvus АцЪЧАЂРядЦЬсЙЉЕФ Serverless Milvus ШЋЭаЙмЗўЮёЃЌ100% МцШнПЊдД MilvusЃЌЬсЙЉИпадФмЁЂПЩРЉеЙЁЂДѓЙцФЃ AI ЯђСПЪ§ОнПтЯрЫЦадМьЫїЗўЮёЃЌОпБИПЊЯфМДгУЁЂЕЏадПЩРЉеЙЁЂШЋСДТЗМрПиИцОЏЕФФмСІЃЌЭЌЪБЬсЙЉПЊдД Attu ЕФПЩЪгЛЏЙЄОпЁЃЪЪгУгкИїжж AI гІгУГЁОАЃЌШчЃКЖрФЃЬЌЫбЫїЁЂRAGЁЂЙуИцЭЦМіЁЂФкШнЗчЯеЪЖБ№ЕШЁЃ
НќШеЃЌАЂРядЦЯђСПМьЫї Milvus Аце§ЪНПЊЦєЙЋВтЃЌГЯбћЙуДѓПЊЗЂепМАЦѓвЕгУЛЇВЮгыЙЋВтЃЌИГФмжЧФмМьЫїЃЌНтЫј AI ЧБФмЁЃ
ВњЦЗгХЪЦ
- дЦдЩњМЋЫйЯђСПМьЫїЗўЮё
АЂРядЦЯђСПМьЫї Milvus АцМЏГЩСЫ Vector МьЫїПтЃЌЦОНшЦфИпадФмЁЂИпПЩгУадЕФЬиЕуЃЌжЇГжЛьКЯВщбЏЃЌЮЊгУЛЇЬсЙЉИпаЇЧвЮШЖЈЕФЯђСПЪ§ОнМьЫїФмСІЁЃ
- ЦѓвЕМЖдЫЮЌМАвзгУад
дЦЩЯШЋЭаЙмЕФЯђСПЪ§ОнПтЗўЮёЃЌВЛНіМЋДѓЕиЫѕМѕСЫМЏШКЮЌЛЄГЩБОЃЌЖјЧвПЊЯфМДгУЃЌФкжУХфжУЙмРэЁЂАВШЋЙмРэЕШЙІФмЃЌВЂЭЈЙ§дЦдЩњМмЙЙЪЕЯжИпадФмЁЂПЩРЉеЙадЃЌжЇГжАДашНкЕуЛЏЩьЫѕФмСІЃЛЭЌЪБЃЌЛЙЬсЙЉСЫШЋУцПЩЪгЛЏЕФМрПиИцОЏСДТЗЃЌвдШЗБЃЯЕЭГЮШЖЈдЫааМАИпаЇдЫЮЌЁЃ
- МцШнПЊдД Milvus ЩњЬЌ
АЂРядЦЯђСПМьЫї Milvus АцШЋУцМцШнПЊдД Milvus ЯЕЭГЃЌЬсЙЉСЫ Attu ЕШЗсИЛЕФПЊдДЙмРэЙЄОпЃЌИќгЕгаЗсИЛЧвЛюдОЕФЩњЬЌЩчЧјзЪдДЁЃ
гІгУГЁОА
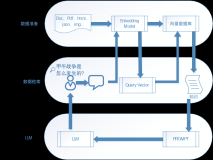
ЖрФЃЬЌМьЫї
НсКЯ AI ЭЦРэЁЂбЕСЗЕШЙЄГЬЦНЬЈКЭ Embedding ФЃаЭЕФФмСІЃЌMilvus ПЩИпаЇЫїв§КЭМьЫїВЛЭЌРраЭЕФЪ§ОнЃЌШчЃКЭМЦЌЁЂЪгЦЕЁЂЩљЮЦЁЂАьЙЋЮФЕЕКЭвЛаЉАыНсЙЙЛЏЮФЕЕЃЌжЇГжПьЫйОЋзМЕиПчУНЬхРраЭНјаааХЯЂМьЫїЃЌВЂЬсЙЉЧПДѓЕФРЉеЙадКЭСщЛюЕФНгПкЁЃ
жЧФмЮЪД№&ДѓФЃаЭ
Milvus НсКЯДѓаЭгябдФЃаЭЪЕЯжжЧФмЮЪД№ЯЕЭГЃЌЭЈЙ§ЯђСПЛЏДІРэгУЛЇВщбЏЃЌРћгУЦфИпаЇМьЫїЙІФмПьЫйЦЅХфЁАЫНгажЊЪЖПтЁБжаЕФаХЯЂЃЌВЂНсКЯДѓФЃаЭЃЌЩњГЩзМШЗЛигІЁЃДЫЗНАИЬсЙЉМДЪБЁЂОЋШЗЁЂНЛЛЅЪНЕФЩњГЩЪНЫбЫїЗўЮёЁЃ

ЙЋВтЫЕУї
АЂРядЦЯђСПМьЫї Milvus АцвбПЊЦєУтЗбЙЋВтЁЃФњПЩвддкE-MapReduceПижЦЬЈЃЌбЁдё EMR Serverless > MilvusЃЌНјШы Milvus вГУцДДНЈШыУХАцЕФЪЕР§ЁЃЙЋВтЦкМфФњПЩвдУтЗбЪдгУ Milvus ЗўЮёЃЌУтЗбЪдгУНсЪјКѓЃЌФњПЩвдајЗбЛђМАЪБЪЭЗХЪЕР§ЃЌБмУтВњЩњЗбгУЁЃ
*зЂвт ЯђСПМьЫї Milvus АцЪЕР§ДДНЈЪБЃЌашвЊвРРЕАЂРядЦOSSВњЦЗНјааЪ§ОнДцДЂЃЌЯрЙиЗбгУЧыВЮМћМЦЗбИХЪіЁЃ
ЙЋВтЯожЦ
- ЙЋВтЦкМфЃЌФњНіПЩвдДДНЈЪЕР§ЯЕСаЮЊШыУХАцЕФЪЕР§ЃЌЧвЯоДДНЈ3ИіЁЃ
ЕБФњЕФЯђСПЪ§ОнЙцФЃГЌЙ§500ЭђЃЌЛђепЕБЧАШыУХАцЕФЙцИёЮоЗЈТњзуФњЕФвЕЮёашЧѓЪБЃЌФњПЩвдЬюаДАЂРядЦЯђСПМьЫїMilvusБъзМАцВтЪдЩъЧыБэЩъЧыЪдгУЁЃЯрНЯгкШыУХАцБОЃЌMilvus БъзМАцЬсЙЉСЫИќДѓЗЖЮЇЕФЪЕР§ЙцИёбЁЯюКЭИќМгЖрбљЛЏЕФХфжУЃЌФњПЩвдИљОнЪЕМЪЪЙгУЧщПіСщЛюбЁдёзюЪЪКЯЕФЪЕР§ЙцИёЁЃ
- ЙЋВтЦкМфВЛБЃеЯЗўЮёЕШМЖавщ SLAЃЌЕЋЗўЮёВЛНЕМЖЁЃ
- ЙЋВтЦкМфжЇГжвдЯТЕигђКЭПЩгУЧјЁЃ
ЕигђУћГЦ |
ЕигђID |
ПЩгУЧј |
ЛЊЖЋ1ЃЈКМжнЃЉ |
cn-hangzhou |
ПЩгУЧјH ПЩгУЧјJ |
ЛЊЖЋ2ЃЈЩЯКЃЃЉ |
cn-shanghai |
ПЩгУЧјG |
ЛЊББ2ЃЈББОЉЃЉ |
cn-beijing |
ПЩгУЧјG |
ВйзїВНжш
- НјШы EMR Serverless Milvus вГУцЁЃ
- ЕЧТМE-MapReduceПижЦЬЈЁЃ
- дкзѓВрЕМКНРИЃЌбЁдёEMR Serverless > MilvusЁЃ
- дкЖЅВПВЫЕЅРИДІЃЌИљОнЪЕМЪЧщПібЁдёЕигђЁЃ
- дкMilvusвГУцЃЌЕЅЛїДДНЈЪЕР§ЁЃ

- дкMilvusЯђСПЫбЫївГУцЃЌЭъГЩЯрЙиХфжУЁЃ
ХфжУЯю |
ЪОР§ |
УшЪі |
ИЖЗбРраЭ |
АќФъАќдТ |
НіжЇГжАќФъАќдТРраЭЁЃ |
ИЖЗбЪБГЄ |
1ИідТ |
ФЌШЯЙКТђЪБГЄЮЊ1ИідТЃЌжЇГжЕФЙКТђЪБГЄвдЪЕМЪНчУцЮЊзМЁЃ |
ЕигђКЭПЩгУЧј |
ЛЊЖЋ1ЃЈКМжнЃЉ ПЩгУЧјH |
ЪЕР§ЫљдкЕФЮяРэЮЛжУКЭПЩгУЧјЁЃ *зЂвт ЪЕР§ДДНЈКѓЃЌЮоЗЈИќИФЕигђКЭПЩгУЧјЃЌЧыНїЩїбЁдёЁЃ |
VPC ID |
vpc_Hangzhou/vpc-bp1f4epmkvncimpgs**** |
зЈгаЭјТчЪЧФњдкАЂРядЦздМКЖЈвхЕФвЛИіИєРыЭјТчЛЗОГЃЌФњПЩвдЭъШЋеЦПиздМКЕФзЈгаЭјТчЁЃ бЁдёвбгаЕФзЈгаЭјТчЃЌЛђепШчашДДНЈаТЕФзЈгаЭјТчЃЌПЩвдЕЅЛїЧАЭљПижЦЬЈДДНЈЃЌЯъЧщЧыВЮМћДДНЈКЭЙмРэзЈгаЭјТчЁЃ |
vSwitch ID |
vsw_i/vsw-bp1e2f5fhaplp0g6p**** |
НЛЛЛЛњЃЈvSwitchЃЉЪЧзщГЩзЈгаЭјТчVPCЕФЛљДЁЭјТчФЃПщЃЌгУРДСЌНгВЛЭЌЕФдЦзЪдДЁЃ бЁдёвбгаЕФНЛЛЛЛњЃЌЛђепШчашДДНЈаТЕФНЛЛЛЛњЃЌПЩвдЕЅЛїПижЦЬЈДДНЈЃЌЯъЧщЧыВЮМћДДНЈКЭЙмРэНЛЛЛЛњЁЃ |
ЗўЮёЙиСЊНЧЩЋ |
AliyunServiceRoleForMilvus |
вбЪкгшФњЕФАЂРядЦеЫКХЕФAliyunServiceRoleForMilvusНЧЩЋЃЌвдМАгыЦфЙиСЊЕФAliyunServiceRolePolicyForMilvusВпТдЁЃ MilvusЪЙгУДЫНЧЩЋРДЗУЮЪФњдкЦфЫћдЦВњЦЗжаЕФзЪдДЁЃ |
в§ЧцАцБО |
2.3 |
MilvusЕФЩчЧјАцБОКХЁЃ |
OSSДцДЂ |
serverless-milvus-oss |
гУгкДцДЂЯђСПЪ§ОнЁЃ *зЂвт ашЮЊBucketДДНЈжИЖЈБъЧЉЃЌkeyЮЊProductЃЌvalueЮЊServerlessMilvusЃЌЯъЧщЧыВЮМћЙмРэДцДЂПеМфБъЧЉЁЃ ШчЙћУЛгаBucketЃЌдкOSSДцДЂЯТРСаБэжабЁдёШЅДДНЈЃЌЬјзЊжСЖдЯѓДцДЂOSSПижЦЬЈЩЯДДНЈЃЌОпЬхВйзїЧыВЮМћПижЦЬЈДДНЈДцДЂПеМфЁЃ |
ЙцИё |
ШыУХАц |
MilvusЪЕР§ЕФЙцИёЁЃ
бЁдёИУЙцИёЪБЃЌЛЙашХфжУStandaloneЙцИёВЮЪ§ЃЌИУВЮЪ§ЪЧШыУХАцНкЕуХфжУЃЌПЩвдЪЙгУФЌШЯЕФ1 vCPU 4 GiBЁЃ
|
rootгУЛЇУмТы |
ЧыФњздЖЈвх |
ЩшжУMilvusЪЕР§гУгкЕЧТМЪ§ОнПтЕФrootеЫКХУмТыЁЃ живЊ ЧыРЮМЧФњЩшЖЈЕФУмТыЃЌФПЧАВЛжЇГжаоИФУмТыЁЃ |

- ЕЅЛїСЂМДЙКТђЁЃ
ЕБЪЕР§зДЬЌЮЊдЫаажаЪБЃЌБэЪОЪЕР§ДДНЈГЩЙІЁЃ
СЊЯЕЮвУЧ
ШчЙћФњдкЪЙгУЯђСПМьЫї Milvus АцЕФЙ§ГЬжагіЕНШЮКЮвЩЮЪЃЌПЩМгШыЖЄЖЄШК59530004993зЩбЏЁЃ
ПьЫйЬјзЊ
- ЯђСПМьЫї Milvus АцЙйЭјЃКhttps://www.aliyun.com/product/bigdata/emapreduce/milvus
- ВњЦЗПижЦЬЈЃКhttps://emr-next.console.aliyun.com/
- ВњЦЗЮФЕЕЃКhttps://help.aliyun.com/zh/emr/serverless-milvus/
- БъзМАцЩъЧыЃКhttps://survey.aliyun.com/apps/zhiliao/JqRjGNFoS