БОЮФНщЩмШчКЮЭЈЙ§ећКЯАЂРядЦMilvusЁЂАЂРядЦDashScope EmbeddingФЃаЭгыАЂРядЦPAIЃЈEASЃЉФЃаЭЗўЮёЃЌЙЙНЈвЛИігЩLLMЃЈДѓаЭгябдФЃаЭЃЉЧ§ЖЏЕФЮЪЬтНтД№гІгУЃЌВЂзХжибнЪОСЫШчКЮДюНЈЛљгкетаЉММЪѕЕФRAGЖдЛАЯЕЭГЁЃ
ЧАЬсЬѕМў
- вбДДНЈMilvusЪЕР§ЁЃОпЬхВйзїЃЌЧыВЮМћПьЫйДДНЈMilvusЪЕР§ЁЃ
- вбПЊЭЈPAIЃЈEASЃЉВЂДДНЈСЫФЌШЯЙЄзїПеМфЁЃОпЬхВйзїЃЌЧыВЮМћПЊЭЈPAIВЂДДНЈФЌШЯЙЄзїПеМфЁЃ
- вбПЊЭЈЗўЮёВЂЛёЕУAPI-KEYЁЃОпЬхВйзїЃЌЧыВЮМћПЊЭЈDashScopeВЂДДНЈAPI-KEYЁЃ
ЪЙгУЯожЦ
- MilvusЪЕР§КЭPAIЃЈEASЃЉаыдкЯрЭЌЕигђЯТЁЃ
- ЧыШЗБЃФњЕФдЫааЛЗОГжавбАВзАPython 3.8ЛђвдЩЯАцБОЃЌвдБуЫГРћАВзАВЂЪЙгУDashScopeЁЃ
ЗНАИМмЙЙ
ИУЗНАИМмЙЙШчЯТЭМЫљЪОЃЌжївЊАќКЌвдЯТМИИіДІРэЙ§ГЬЃК
- жЊЪЖПтдЄДІРэЃКФњПЩвдНшжњLangChain SDKЖдЮФБОНјааЗжИюЃЌзїЮЊEmbeddingФЃаЭЕФЪфШыЪ§ОнЁЃ
- жЊЪЖПтДцДЂЃКбЁЖЈЕФEmbeddingФЃаЭЃЈDashScopeЃЉИКд№НЋЪфШыЮФБОзЊЛЛЮЊЯђСПЃЌВЂНЋетаЉЯђСПДцШыАЂРядЦMilvusЕФЯђСПЪ§ОнПтжаЁЃ
- ЯђСПЯрЫЦадМьЫїЃКEmbeddingФЃаЭДІРэгУЛЇЕФВщбЏЪфШыЃЌВЂНЋЦфЯђСПЛЏЁЃЫцКѓЃЌРћгУАЂРядЦMilvusЕФЫїв§ЙІФмРДЪЖБ№ГіЯргІЕФRetrievedЮФЕЕМЏЁЃ
- RAGЃЈRetrieval-Augmented GenerationЃЉЖдЛАбщжЄЃКФњЪЙгУLangChain SDKЃЌВЂНЋЯрЫЦадМьЫїЕФНсЙћзїЮЊЩЯЯТЮФЃЌНЋЮЪЬтЕМШыЕНLLMФЃаЭЃЈБОР§жагУЕФЪЧАЂРядЦPAI EASЃЉЃЌвдВњЩњзюжеЕФЛиД№ЁЃДЫЭтЃЌНсЙћПЩвдЭЈЙ§НЋЮЪЬтжБНгВщбЏLLMФЃаЭЕУЕНЕФД№АИНјааКЫЪЕЁЃ

ВйзїСїГЬ
ВНжшвЛЃКВПЪ№ЖдЛАФЃаЭЭЦРэЗўЮё
- НјШыФЃаЭдкЯпЗўЮёвГУцЁЃ
- ЕЧТМPAIПижЦЬЈЁЃ
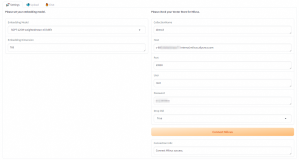
- дкзѓВрЕМКНРИЕЅЛїЙЄзїПеМфСаБэЃЌдкЙЄзїПеМфСаБэвГУцжаЕЅЛїД§ВйзїЕФЙЄзїПеМфУћГЦЃЌНјШыЖдгІЙЄзїПеМфФкЁЃ
- дкЙЄзїПеМфвГУцЕФзѓВрЕМКНРИбЁдёФЃаЭВПЪ№>ФЃаЭдкЯпЗўЮёЃЈEASЃЉЃЌНјШыФЃаЭдкЯпЗўЮёЃЈEASЃЉвГУцЁЃ

- дкPAI-EASФЃаЭдкЯпЗўЮёвГУцЃЌЕЅЛїВПЪ№ЗўЮёЁЃ
- дкВПЪ№ЗўЮёвГУцЃЌбЁдёДѓФЃаЭRAGЖдЛАЯЕЭГЁЃ
- дкВПЪ№ДѓФЃаЭRAGЖдЛАЯЕЭГвГУцЃЌХфжУвдЯТЙиМќВЮЪ§ЃЌЦфгрВЮЪ§ПЩЪЙгУФЌШЯХфжУЃЌИќЖрВЮЪ§ЯъЧщЧыВЮМћДѓФЃаЭRAGЖдЛАЯЕЭГЁЃ
ВЮЪ§ |
УшЪі |
|
ЛљБОаХЯЂ |
ЗўЮёУћГЦ |
ФњПЩвдздЖЈвхЁЃ |
ФЃаЭРДдД |
ЪЙгУФЌШЯЕФПЊдДЙЋЙВФЃаЭЁЃ |
|
зЪдДХфжУ |
ФЃаЭРрБ№ |
ЭЈГЃбЁдёЭЈвхЧЇЮЪ7BЁЃР§ШчЃЌQwen1.5-7bЁЃ |
зЪдДХфжУбЁдё |
АДашбЁдёGPUзЪдДХфжУЁЃР§ШчЃЌml.gu7i.c16m30.1-gu30ЁЃ |
|
ЯђСПМьЫїПтЩшжУ |
АцБОРраЭ |
бЁдёMilvusЁЃ |
Ъ§ОнПтЮФМўМаУћГЦ |
ФњдкMilvusжаздЖЈвхЕФCollectionУћГЦЁЃ |
|
ЗУЮЪЕижЗ |
MilvusЪЕР§ЕФФкЭјЕижЗЁЃФњПЩвддкMilvusЪЕР§ЕФЪЕР§ЯъЧщвГУцВщПДЁЃ |
|
ДњРэЖЫПк |
MilvusЪЕР§ЕФProxy PortЁЃФњПЩвддкMilvusЪЕР§ЕФЪЕР§ЯъЧщвГУцВщПДЁЃ |
|
еЫКХ |
ХфжУЮЊrootЁЃ |
|
УмТы |
ХфжУЮЊДДНЈMilvusЪЕР§ЪБЃЌФњздЖЈвхЕФrootгУЛЇЕФУмТыЁЃ |
|
CollectionЩОГ§ |
ЪЧЗёЩОГ§вбДцдкЕФCollectionЁЃШЁжЕШчЯТЃК
|
|
зЈгаЭјТчХфжУ |
VPC |
ДДНЈMilvusЪЕР§бЁдёЪБЕФVPCЁЂНЛЛЛЛњКЭАВШЋзщЁЃФњПЩвддкMilvusЪЕР§ЕФЪЕР§ЯъЧщвГУцВщПДЁЃ |
НЛЛЛЛњ |
||
АВШЋзщУћГЦ |
||
- ЕЅЛїВПЪ№ЁЃ
ЕБЗўЮёзДЬЌБфЮЊдЫаажаЪБЃЌБэЪОЗўЮёВПЪ№ГЩЙІЁЃ
- ЛёШЁVPCЕижЗЕїгУЕФЗўЮёЗУЮЪЕижЗКЭTokenЁЃ
- ЕЅЛїЗўЮёУћГЦЃЌНјШыЗўЮёЯъЧщвГУцЁЃ
- дкЛљБОаХЯЂЧјгђЃЌЕЅЛїВщПДЕїгУаХЯЂЁЃ
- дкЕїгУаХЯЂЖдЛАПђЕФVPCЕижЗЕїгУвГЧЉЃЌЛёШЁЗўЮёЗУЮЪЕижЗКЭTokenЃЌВЂБЃДцЕНБОЕиЁЃ
ВНжшЖўЃКДДНЈВЂжДааPythonЮФМў
- ЃЈПЩбЁЃЉдкECSПижЦЬЈДДНЈВЂЦєЖЏвЛИіПЊЭЈЙЋЭјЕФECSЪЕР§ЃЌгУгкдЫааPythonЮФМўЃЌЯъЧщЧыВЮМћЭЈЙ§ПижЦЬЈЪЙгУECSЪЕР§ЃЈПьНнАцЃЉЁЃ
ФњвВПЩвддкБОЕиЛњЦїжДааPythonЮФМўЃЌОпЬхЧыИљОнФњЕФЪЕМЪЧщПізіГіКЯЪЪЕФбЁдёЁЃ
- жДаавдЯТУќСюЃЌАВзАЯрЙивРРЕПтЁЃ
pip3 install pymilvus langchain dashscope beautifulsoup4
- жДаавдЯТУќСюЃЌДДНЈ
milvusr-llm.pyЮФМўЁЃ
vim milvusr-llm.py
milvusr-llm.pyЮФМўФкШнШчЯТЫљЪОЁЃ
from langchain_community.document_loaders import WebBaseLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores.milvus import Milvus from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.llms.pai_eas_endpoint import PaiEasEndpoint # ЩшжУMilvus CollectionУћГЦЁЃ COLLECTION_NAME = 'doc_qa_db' # ЩшжУЯђСПЮЌЖШЁЃ DIMENSION = 768 loader = WebBaseLoader([ 'https://milvus.io/docs/overview.md', 'https://milvus.io/docs/release_notes.md', 'https://milvus.io/docs/architecture_overview.md', 'https://milvus.io/docs/four_layers.md', 'https://milvus.io/docs/main_components.md', 'https://milvus.io/docs/data_processing.md', 'https://milvus.io/docs/bitset.md', 'https://milvus.io/docs/boolean.md', 'https://milvus.io/docs/consistency.md', 'https://milvus.io/docs/coordinator_ha.md', 'https://milvus.io/docs/replica.md', 'https://milvus.io/docs/knowhere.md', 'https://milvus.io/docs/schema.md', 'https://milvus.io/docs/dynamic_schema.md', 'https://milvus.io/docs/json_data_type.md', 'https://milvus.io/docs/metric.md', 'https://milvus.io/docs/partition_key.md', 'https://milvus.io/docs/multi_tenancy.md', 'https://milvus.io/docs/timestamp.md', 'https://milvus.io/docs/users_and_roles.md', 'https://milvus.io/docs/index.md', 'https://milvus.io/docs/disk_index.md', 'https://milvus.io/docs/scalar_index.md', 'https://milvus.io/docs/performance_faq.md', 'https://milvus.io/docs/product_faq.md', 'https://milvus.io/docs/operational_faq.md', 'https://milvus.io/docs/troubleshooting.md', ]) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=0) # ЪЙгУLangChainНЋЪфШыЮФЕЕАВееchunk_sizeЧаЗж all_splits = text_splitter.split_documents(docs) # ЩшжУembeddingФЃаЭЮЊDashScopeЃЈПЩвдЬцЛЛГЩздМКФЃаЭЃЉЁЃ embeddings = DashScopeEmbeddings( model="text-xxxx", dashscope_api_key="your_api_key" ) # ДДНЈconnectionЃЌhostЮЊАЂРядЦMilvusЕФЗУЮЪгђУћЁЃ connection_args = {"host": "c-xxxx.milvus.aliyuncs.com", "port": "19530", "user": "your_user", "password": "your_password"} # ДДНЈCollection vector_store = Milvus( embedding_function=embeddings, connection_args=connection_args, collection_name=COLLECTION_NAME, drop_old=True, ).from_documents( all_splits, embedding=embeddings, collection_name=COLLECTION_NAME, connection_args=connection_args, ) # РћгУMilvusЯђСПЪ§ОнПтНјааЯрЫЦадМьЫїЁЃ query = "What are the main components of Milvus?" docs = vector_store.similarity_search(query) print(len(docs)) # ЩљУїLLM ФЃаЭЮЊPAI EASЃЈПЩвдЬцЛЛГЩздМКФЃаЭЃЉЁЃ llm = PaiEasEndpoint( eas_service_url="your_pai_eas_url", eas_service_token="your_token", ) # НЋЩЯЪіЯрЫЦадМьЫїЕФНсЙћзїЮЊretrieverЃЌЬсГіЮЪЬтЪфШыЕНLLMжЎКѓЃЌЛёШЁМьЫїдіЧПжЎКѓЕФЛиД№ЁЃ retriever = vector_store.as_retriever() template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" rag_prompt = PromptTemplate.from_template(template) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | llm ) print(rag_chain.invoke("Explain IVF_FLAT in Milvus."))
вдЯТВЮЪ§ЧыИљОнЪЕМЪЛЗОГЬцЛЛЁЃ
ВЮЪ§ |
ЫЕУї |
COLLECTION_NAME |
ЩшжУMilvus CollectionУћГЦЃЌФњПЩвдздЖЈвхЁЃ |
model |
ФЃаЭЗўЮёСщЛ§ЕФФЃаЭУћГЦЁЃФњПЩвддкФЃаЭЗўЮёСщЛ§ПижЦЬЈЕФзмРРвГУцВщПДЁЃ БОЮФЪОР§ЪЙгУЕФЩшжУEmbeddingФЃаЭЮЊDashScopeЃЌФњвВПЩвдЬцЛЛГЩФњЪЕМЪЪЙгУЕФФЃаЭЁЃ |
dashscope_api_key |
ФЃаЭЗўЮёСщЛ§ЕФУмдПЁЃФњПЩвддкФЃаЭЗўЮёСщЛ§ПижЦЬЈЕФAPI-KEYЙмРэвГУцВщПДЁЃ |
connection_args |
|
eas_service_url |
ХфжУЮЊВНжш1жаЛёШЁЕФЗўЮёЗУЮЪЕижЗЁЃБОЮФЪОР§ЩљУїLLMФЃаЭЮЊPAIЃЈEASЃЉЃЌФњвВПЩвдЬцЛЛГЩФњЪЕМЪЪЙгУЕФФЃаЭЁЃ |
eas_service_token |
ХфжУЮЊВНжш1жаЛёШЁЕФЗўЮёTokenЁЃ |
- жДаавдЯТУќСюдЫааЮФМўЁЃ
python3 milvusr-llm.py
ЗЕЛиШчЯТРрЫЦаХЯЂЁЃ
4 IVF_FLAT is a type of index in Milvus that divides vector data into nlist cluster units and compares distances between the target input vector and the center of each cluster. It uses a smaller number of clusters than IVF_FLAT, which means it may have slightly higher query time but also requires less memory. The encoded data stored in each unit is consistent with the original data.
ЯђСПМьЫї Milvus АцгУЛЇНЛСїЖЄЖЄШК