ОрРыЖШСП
ОрРыЙЋЪНЕФЛљБОаджЪ
дкЛњЦїбЇЯАЙ§ГЬжаЃЌЖдгкКЏЪ§dist(Ё)ЃЌШєЫќЪЧвЛ"ОрРыЖШСП"(distance measure)ЃЌдђашвЊТњзувЛаЉЛљБОаджЪ

1 ХЗЪНОрРы(Euclidean Distance)
ХЗЪЯОрРыЪЧзюШнвзжБЙлРэНтЕФОрРыЖШСПЗНЗЈЃЌЮвУЧаЁбЇЁЂГѕжаКЭИпжаНгДЅЕНЕФСНИіЕудкПеМфжаЕФОрРывЛАуЖМЪЧжИХЗЪЯОрРыЁЃ

ОйР§:
X=[[1,1],[2,2],[3,3],[4,4]];
ОМЦЫуЕУ:
d = 1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
2 ТќЙўЖйОрРы(Manhattan Distance)
дкТќЙўЖйНжЧјвЊДгвЛИіЪЎзжТЗПкПЊГЕЕНСэвЛИіЪЎзжТЗПкЃЌМнЪЛОрРыЯдШЛВЛЪЧСНЕуМфЕФжБЯпОрРыЁЃ
етИіЪЕМЪМнЪЛОрРыОЭЪЧЁАТќЙўЖйОрРыЁБЁЃТќЙўЖйОрРывВГЦЮЊЁАГЧЪаНжЧјОрРыЁБ(City Block distance)ЁЃ

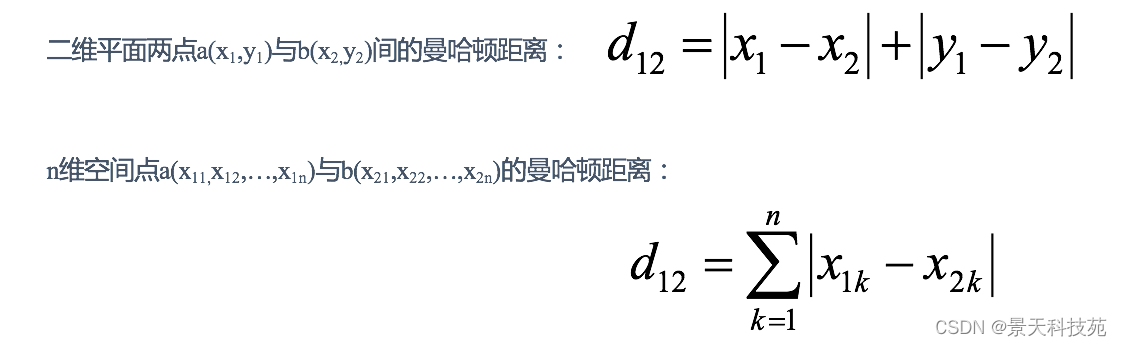
ОйР§:
X=[[1,1],[2,2],[3,3],[4,4]];
ОМЦЫуЕУ:
d = 2 4 6 2 4 2
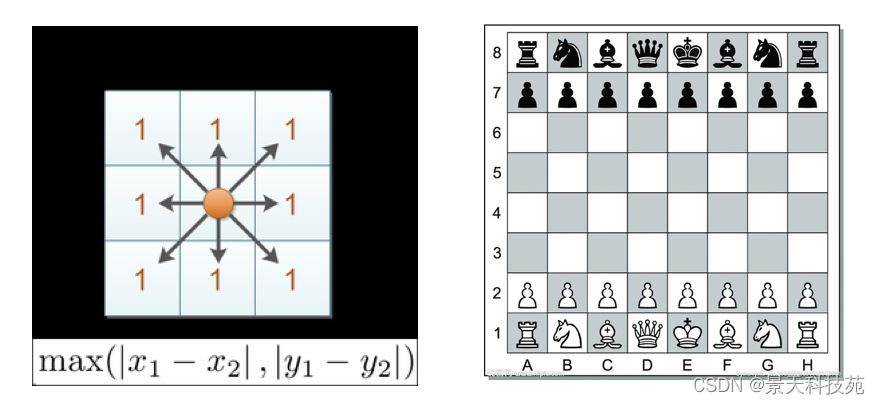
3 ЧаБШбЉЗђОрРы (Chebyshev Distance)
ЙњМЪЯѓЦхжаЃЌЙњЭѕПЩвджБааЁЂКсааЁЂаБааЃЌЫљвдЙњЭѕзпвЛВНПЩвдвЦЖЏЕНЯрСк8ИіЗНИёжаЕФШЮвтвЛИіЁЃ
ЙњЭѕДгИёзг(x1,y1)зпЕНИёзг(x2,y2)зюЩйашвЊЖрЩйВНЃПетИіОрРыОЭНаЧаБШбЉЗђОрРыЁЃ

ОйР§:
X=[[1,1],[2,2],[3,3],[4,4]];
ОМЦЫуЕУ:
d = 1 2 3 1 2 1
4 уЩПЩЗђЫЙЛљОрРы(Minkowski Distance)
уЩЪЯОрРыВЛЪЧвЛжжОрРыЃЌЖјЪЧвЛзщОрРыЕФЖЈвхЃЌЪЧЖдЖрИіОрРыЖШСПЙЋЪНЕФИХРЈадЕФБэЪіЁЃ
СНИіnЮЌБфСПa(x11,x12,Ё,x1n)гыb(x21,x22,Ё,x2n)МфЕФуЩПЩЗђЫЙЛљОрРыЖЈвхЮЊЃК
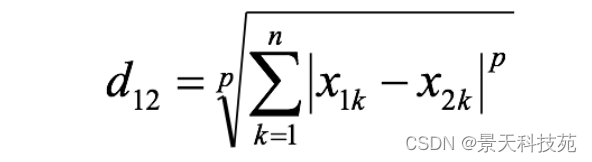
ЦфжаpЪЧвЛИіБфВЮЪ§ЃК
ЕБp=1ЪБЃЌОЭЪЧТќЙўЖйОрРыЃЛ
ЕБp=2ЪБЃЌОЭЪЧХЗЪЯОрРыЃЛ
ЕБpЁњЁоЪБЃЌОЭЪЧЧаБШбЉЗђОрРыЁЃ
ИљОнpЕФВЛЭЌЃЌуЩЪЯОрРыПЩвдБэЪОФГвЛРр/жжЕФОрРыЁЃ
аЁНсЃК
1 уЩЪЯОрРыЃЌАќРЈТќЙўЖйОрРыЁЂХЗЪЯОрРыКЭЧаБШбЉЗђОрРыЖМДцдкУїЯдЕФШБЕу:
e.g. ЖўЮЌбљБО(ЩэИп[ЕЅЮЛ:cm],Ьхжи[ЕЅЮЛ:kg]),ЯжгаШ§ИібљБОЃКa(180,50)ЃЌb(190,50)ЃЌc(180,60)ЁЃ
aгыbЕФуЩЪЯОрРыЃЈЮоТлЪЧТќЙўЖйОрРыЁЂХЗЪЯОрРыЛђЧаБШбЉЗђОрРыЃЉЕШгкaгыcЕФуЩЪЯОрРыЁЃЕЋЪЕМЪЩЯЩэИпЕФ10cmВЂВЛФмКЭЬхжиЕФ10kgЛЎЕШКХЁЃ
2 уЩЪЯОрРыЕФШБЕуЃК
(1)НЋИїИіЗжСПЕФСПИй(scale)ЃЌвВОЭЪЧЁАЕЅЮЛЁБЯрЭЌЕФПДД§СЫ;
(2)ЮДПМТЧИїИіЗжСПЕФЗжВМЃЈЦкЭћЃЌЗНВюЕШЃЉПЩФмЪЧВЛЭЌЕФЁЃ
5 БъзМЛЏХЗЪЯОрРы (Standardized EuclideanDistance)
БъзМЛЏХЗЪЯОрРыЪЧеыЖдХЗЪЯОрРыЕФШБЕуЖјзїЕФвЛжжИФНјЁЃ ЫМТЗЃКМШШЛЪ§ОнИїЮЌЗжСПЕФЗжВМВЛвЛбљЃЌФЧЯШНЋИїИіЗжСПЖМЁАБъзМЛЏЁБЕНОљжЕЁЂЗНВюЯрЕШЁЃ ? $S_k$БэЪОИїИіЮЌЖШЕФБъзМВю
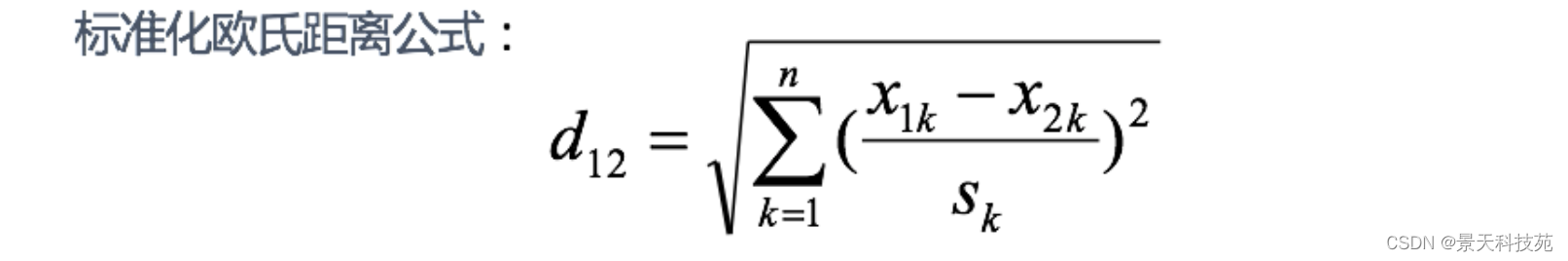
ШчЙћНЋЗНВюЕФЕЙЪ§ПДГЩвЛИіШЈжиЃЌвВПЩГЦжЎЮЊМгШЈХЗЪЯОрРы(Weighted Euclidean distance)ЁЃ
ОйР§:
X=[[1,1],[2,2],[3,3],[4,4]];ЃЈМйЩшСНИіЗжСПЕФБъзМВюЗжБ№ЮЊ0.5КЭ1ЃЉ
ОМЦЫуЕУ:
d = 2.2361 4.4721 6.7082 2.2361 4.4721 2.2361
6 грЯвОрРы(Cosine Distance)
МИКЮжаЃЌМаНЧгрЯвПЩгУРДКтСПСНИіЯђСПЗНЯђЕФВювьЃЛЛњЦїбЇЯАжаЃЌНшгУетвЛИХФюРДКтСПбљБОЯђСПжЎМфЕФВювьЁЃ
ЖўЮЌПеМфжаЯђСПA(x1,y1)гыЯђСПB(x2,y2)ЕФМаНЧгрЯвЙЋЪНЃК
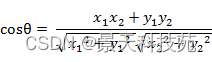
СНИіnЮЌбљБОЕуa(x11,x12,Ё,x1n)КЭb(x21,x22,Ё,x2n)ЕФМаНЧгрЯвЮЊЃК

МДЃК
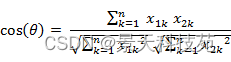
МаНЧгрЯвШЁжЕЗЖЮЇЮЊ[-1,1]ЁЃгрЯвдНДѓБэЪОСНИіЯђСПЕФМаНЧдНаЁЃЌгрЯвдНаЁБэЪОСНЯђСПЕФМаНЧдНДѓЁЃЕБСНИіЯђСПЕФЗНЯђжиКЯЪБгрЯвШЁзюДѓжЕ1ЃЌЕБСНИіЯђСПЕФЗНЯђЭъШЋЯрЗДгрЯвШЁзюаЁжЕ-1ЁЃ
ОйР§:
X=[[1,1],[1,2],[2,5],[1,-4]]
ОМЦЫуЕУ:
d = 0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.8107
7 ККУїОрРы(Hamming Distance)ЁОСЫНтЁП
СНИіЕШГЄзжЗћДЎs1гыs2ЕФККУїОрРыЮЊЃКНЋЦфжавЛИіБфЮЊСэЭтвЛИіЫљашвЊзїЕФзюаЁзжЗћЬцЛЛДЮЪ§ЁЃгУдкNLPжаБШНЯЖр
Р§Шч:
The Hamming distance between ЁА1011101ЁБ and ЁА1001001ЁБ is 2.
The Hamming distance between ЁА2143896ЁБ and ЁА2233796ЁБ is 3.
The Hamming distance between ЁАtonedЁБ and ЁАrosesЁБ is 3.

ККУїжиСПЃКЪЧзжЗћДЎЯрЖдгкЭЌбљГЄЖШЕФСузжЗћДЎЕФККУїОрРыЃЌвВОЭЪЧЫЕЃЌЫќЪЧзжЗћДЎжаЗЧСуЕФдЊЫиИіЪ§ЃКЖдгкЖўНјжЦзжЗћДЎРДЫЕЃЌОЭЪЧ 1 ЕФИіЪ§ЃЌЫљвд 11101 ЕФККУїжиСПЪЧ 4ЁЃвђДЫЃЌШчЙћЯђСППеМфжаЕФдЊЫиaКЭbжЎМфЕФККУїОрРыЕШгкЫќУЧККУїжиСПЕФВюa-bЁЃ
гІгУЃКККУїжиСПЗжЮідкАќРЈаХЯЂТлЁЂБрТыРэТлЁЂУмТыбЇЕШСьгђЖМгагІгУЁЃБШШчдкаХЯЂБрТыЙ§ГЬжаЃЌЮЊСЫдіЧПШнДэадЃЌгІЪЙЕУБрТыМфЕФзюаЁККУїОрРыОЁПЩФмДѓЁЃЕЋЪЧЃЌШчЙћвЊБШНЯСНИіВЛЭЌГЄЖШЕФзжЗћДЎЃЌВЛНівЊНјааЬцЛЛЃЌЖјЧввЊНјааВхШыгыЩОГ§ЕФдЫЫуЃЌдкетжжГЁКЯЯТЃЌЭЈГЃЪЙгУИќМгИДдгЕФБрМОрРыЕШЫуЗЈЁЃ
ОйР§:
X=[[0,1,1],[1,1,2],[1,5,2]]
зЂЃКвдЯТМЦЫуЗНЪНжаЃЌАб2ИіЯђСПжЎМфЕФККУїОрРыЖЈвхЮЊ2ИіЯђСПВЛЭЌЕФЗжСПЫљеМЕФАйЗжБШЁЃ
ОМЦЫуЕУ:
d = 0.6667 1.0000 0.3333
8 НмПЈЕТОрРы(Jaccard Distance)ЁОСЫНтЁП
НмПЈЕТЯрЫЦЯЕЪ§(Jaccard similarity coefficient)ЃКСНИіМЏКЯAКЭBЕФНЛМЏдЊЫидкAЃЌBЕФВЂМЏжаЫљеМЕФБШР§ЃЌГЦЮЊСНИіМЏКЯЕФНмПЈЕТЯрЫЦЯЕЪ§ЃЌгУЗћКХJ(A,B)БэЪОЃК
дкЭЦМіЯЕЭГРяУцгУЕФБШНЯЖр

НмПЈЕТОрРы(Jaccard Distance)ЃКгыНмПЈЕТЯрЫЦЯЕЪ§ЯрЗДЃЌгУСНИіМЏКЯжаВЛЭЌдЊЫиеМЫљгадЊЫиЕФБШР§РДКтСПСНИіМЏКЯЕФЧјЗжЖШЃК

ОйР§:
X=[[1,1,0][1,-1,0],[-1,1,0]]
зЂЃКвдЯТМЦЫужаЃЌАбНмПЈЕТОрРыЖЈвхЮЊВЛЭЌЕФЮЌЖШЕФИіЪ§еМЁАЗЧШЋСуЮЌЖШЁБЕФБШР§
ОМЦЫуЕУ:
d = 0.5000 0.5000 1.0000
9 ТэЪЯОрРы(Mahalanobis Distance)ЁОСЫНтЁП
ЯТЭМгаСНИіе§ЬЌЗжВМЭМЃЌЫќУЧЕФОљжЕЗжБ№ЮЊaКЭbЃЌЕЋЗНВюВЛвЛбљЃЌдђЭМжаЕФAЕуРыФФИізмЬхИќНќЃПЛђепЫЕAгаИќДѓЕФИХТЪЪєгкЫЃПЯдШЛЃЌAРызѓБпЕФИќНќЃЌAЪєгкзѓБпзмЬхЕФИХТЪИќДѓЃЌОЁЙмAгыaЕФХЗЪНОрРыдЖвЛаЉЁЃетОЭЪЧТэЪЯОрРыЕФжБЙлНтЪЭЁЃ
ТэЪЯОрРыЪЧЛљгкбљБОЗжВМЕФвЛжжОрРыЁЃ
ТэЪЯОрРыЪЧгЩгЁЖШЭГМЦбЇМвТэЙўРХЕБШЫЙЬсГіЕФЃЌБэЪОЪ§ОнЕФаЗНВюОрРыЁЃЫќЪЧвЛжжгааЇЕФМЦЫуСНИіЮЛжУбљБОМЏЕФЯрЫЦЖШЕФЗНЗЈЁЃ
гыХЗЪНОрРыВЛЭЌЕФЪЧЃЌЫќПМТЧЕНИїжжЬиаджЎМфЕФСЊЯЕЃЌМДЖРСЂгкВтСПГпЖШЁЃ
ТэЪЯОрРыЖЈвхЃКЩшзмЬхGЮЊmЮЌзмЬхЃЈПМВьmИіжИБъЃЉЃЌОљжЕЯђСПЮЊІЬ=ЃЈІЬ1ЃЌІЬ2ЃЌЁ ЁЃЌІЬmЃЌЃЉ`,аЗНВюеѓЮЊЁЦ=ЃЈІвijЃЉ,
дђбљБОX=ЃЈX1ЃЌX2ЃЌЁ ЁЃЌXmЃЌЃЉ`гызмЬхGЕФТэЪЯОрРыЖЈвхЮЊЃК

ТэЪЯОрРывВПЩвдЖЈвхЮЊСНИіЗўДгЭЌвЛЗжВМВЂЧвЦфаЗНВюОиеѓЮЊЁЦЕФЫцЛњБфСПЕФВювьГЬЖШЃКШчЙћаЗНВюОиеѓЮЊЕЅЮЛОиеѓЃЌТэЪЯОрРыОЭМђЛЏЮЊХЗЪНОрРыЃЛШчЙћаЗНВюОиеѓЮЊЖдНЧОиеѓЃЌдђЦфвВПЩГЦЮЊе§ЙцЛЏЕФХЗЪНОрРыЁЃ
ТэЪЯОрРыЬиадЃК
1.СПИйЮоЙиЃЌХХГ§БфСПжЎМфЕФЯрЙиадЕФИЩШХЃЛ
2.ТэЪЯОрРыЕФМЦЫуЪЧНЈСЂдкзмЬхбљБОЕФЛљДЁЩЯЕФЃЌШчЙћФУЭЌбљЕФСНИібљБОЃЌЗХШыСНИіВЛЭЌЕФзмЬхжаЃЌзюКѓМЦЫуЕУГіЕФСНИібљБОМфЕФТэЪЯОрРыЭЈГЃЪЧВЛЯрЭЌЕФЃЌГ§ЗЧетСНИізмЬхЕФаЗНВюОиеѓХіЧЩЯрЭЌЃЛ
3 .МЦЫуТэЪЯОрРыЙ§ГЬжаЃЌвЊЧѓзмЬхбљБОЪ§ДѓгкбљБОЕФЮЌЪ§ЃЌЗёдђЕУЕНЕФзмЬхбљБОаЗНВюОиеѓФцОиеѓВЛДцдкЃЌетжжЧщПіЯТЃЌгУХЗЪНОрРыМЦЫуМДПЩЁЃ
4.ЛЙгавЛжжЧщПіЃЌТњзуСЫЬѕМўзмЬхбљБОЪ§ДѓгкбљБОЕФЮЌЪ§ЃЌЕЋЪЧаЗНВюОиеѓЕФФцОиеѓШдШЛВЛДцдкЃЌБШШчШ§ИібљБОЕуЃЈ3ЃЌ4ЃЉЃЌЃЈ5ЃЌ6ЃЉЃЌЃЈ7ЃЌ8ЃЉЃЌетжжЧщПіЪЧвђЮЊетШ§ИібљБОдкЦфЫљДІЕФЖўЮЌПеМфЦНУцФкЙВЯпЁЃетжжЧщПіЯТЃЌвВВЩгУХЗЪНОрРыМЦЫуЁЃ
ХЗЪНОрРы&ТэЪЯОрРыЃК

ОйР§ЃК
вбжЊгаСНИіРрG1КЭG2ЃЌБШШчG1ЪЧЩшБИAЩњВњЕФВњЦЗЃЌG2ЪЧЩшБИBЩњВњЕФЭЌРрВњЦЗЁЃЩшБИAЕФВњЦЗжЪСПИпЃЈШчПМВьжИБъЮЊФЭФЅЖШXЃЉЃЌЦфЦНОљФЭФЅЖШІЬ1=80ЃЌЗДгГЩшБИОЋЖШЕФЗНВюІв2(1)=0.25;ЩшБИBЕФВњЦЗжЪСПЩдВюЃЌЦфЦНОљФЭФЅЫ№ЖШІЬ2=75ЃЌЗДгГЩшБИОЋЖШЕФЗНВюІв2(2)=4.
НёгавЛВњЦЗG0ЃЌВтЕФФЭФЅЫ№ЖШX0=78ЃЌЪдХаЖЯИУВњЦЗЪЧФФвЛЬЈЩшБИЩњВњЕФЃП
жБЙлЕиПДЃЌX0гыІЬ1ЃЈЩшБИAЃЉЕФОјЖдОрРыНќаЉЃЌАДОрРызюНќЕФддђЃЌЪЧЗёгІАбИУВњЦЗХаЖЯЩшБИAЩњВњЕФЃП
ПМТЧвЛжжЯрЖдгкЗжЩЂадЕФОрРыЃЌМЧX0гыG1ЃЌG2ЕФЯрЖдОрРыЮЊd1ЃЌd2,дђЃК

вђЮЊd2=1.5 < d1=4ЃЌАДетжжОрРызМдђЃЌгІХаЖЯX0ЮЊЩшБИBЩњВњЕФЁЃ
ЩшБИBЩњВњЕФВњЦЗжЪСПНЯЗжЩЂЃЌГіЯжX0ЮЊ78ЕФПЩФмадНЯДѓЃЛЖјЩшБИAЩњВњЕФВњЦЗжЪСПНЯМЏжаЃЌГіЯжX0ЮЊ78ЕФПЩФмадНЯаЁЁЃ
етжжЯрЖдгкЗжЩЂадЕФОрРыХаЖЯОЭЪЧТэЪЯОрРыЁЃ

10 ЁАСЌајЪєадЁБКЭЁАРыЩЂЪєадЁБЕФОрРыМЦЫу
ЮвУЧГЃНЋЪєадЛЎЗжЮЊЁАСЌајЪєад(continuous attribute)КЭ"РыЩЂЪєад(categorical attribute)ЃЌЧАепдкЖЈвхгђЩЯгаЮоЧюЖрИіПЩФмЕФШЁжЕЃЌКѓепдкЖЈвхгђЩЯЪЧгаЯоИіШЁжЕ
ШєЪєаджЕжЎМфДцдкађЙиЯЕЃЌдђПЩвдНЋЦфзЊЛЏЮЊСЌајжЕЃЌР§Шч: ЩэИпЪєадЁАИпЁБЁАжаЕШЁБЁААЋЁБЃЌПЩзЊЛЏЮЊ(1,0.5,0}ЁЃ
уЩПЩЗђЫЙЛљОрРыПЩвдгУгкгаађЪєадЁЃ
ШєЪєаджЕжЎМфВЛДцдкађЙиЯЕЃЌдђЭЈГЃНЋЦфзЊЛЏЮЊЯђСПЕФаЮЪНЃЌР§Шч:адБ№ЪєадЁАФаЁБЁАХЎЁБЁБЃЌПЩзЊЛЏЮЊ{ (1,0) ЃЌ(0,1) }ЁЃ
