2024Фъ1дТЃЌдкжЊКѕПЮЬУжБВЅМфжаЃЌАЂРядЦ-ЗЩЬьЪЕбщЪв-ММЪѕИКд№ШЫїшЭЁЗжЯэСЫДѓФЃаЭЗўЮёЦНЬЈжаФЃаЭбЕСЗгыЕїгХЕФЪЕМљЗжЯэЁЃдкжБВЅжаЗжБ№ДгШ§ИіЗНУцНщЩмСЫФЃаЭбЕСЗЃК
1.ЙЙНЈвЛеОЪНШЋСДТЗФЃаЭбЕСЗЕФБГОАКЭЯжзД
2.ДѓФЃаЭбЕСЗЛљБОРэФюгыЗНЗЈ
3.ДѓФЃаЭбЕСЗШЋЙ§ГЬКЭbadcaseЗжЯэ
ЯТУцЮвУЧЭЈЙ§ЙлПДЯТЗНЪгЦЕНјвЛВНЬНЫїФЃаЭбЕСЗРяУцЕФАТУиАЩ?~
ГЃМћЮЪЬт
аЁБрЛузмСЫжБВЅМфжаЬсЕНЕФЮЪЬтМАЛиД№ЃЌЧыВщПДЯТЗНФкШнСЫНтХЖ?
1ЁЂгаУЛгаАВШЋЗНЯђЕФДЙжБФЃаЭЃП
Д№ЃКФПЧАУЛгаАВШЋЗНЯђЕФДЙжБФЃаЭЃЌФњПЩвдЯШМгШыЖЄЖЄШКЃК65295003032ЃЌГжајЙизЂВњЦЗЖЏЬЌЁЃ
2ЁЂЭъаЮЬюПеДЪЕФЪ§ОнФмзїЮЊбЕСЗЬтТ№ЃП
Д№ЃКПЩвдЕФЃЌПЩвдЭЈЙ§ЩЯДЋбЕСЗМЏЪБЃЌжИЖЈКУЮЪЬтФкШнМАД№АИЃЌв§ЕМДѓФЃаЭбЇЯАЁЃ
3ЁЂФПЧААЂРядЦАйСЖжЛФмбЕСЗЮФзжТ№ЃПЭМЦЌПЩвдбЕСЗТ№ЃП
Д№ЃКФПЧАБШНЯВржигкЮФзжбЕСЗЃЌЖрФЃЬЌЕФФЃаЭБШНЯОлНЙЃЌПЩвдГжајЙизЂЁЃ
4ЁЂЭЈвхЧЇЮЪФЃаЭФмВЛФмжЛзіЭЦРэЃЌВЛзібЕСЗЃП
Д№ЃКПЩвдЕФЃЌФПЧАЭЦРэКЭбЕСЗЪЧЕЅЖРЕФФЃПщЃЌПЩвджЛЪЙгУЭЦРэЗўЮёЁЃ
5ЁЂЪЙгУИпНзФЃаЭЮЂЕїЃЌЕЭНзФЃаЭзіФмСІЯТГСЃЌЪЧЯызіеєСѓТ№ЃП
Д№ЃКФњЕФУшЪіЖдгІгкжЊЪЖеєСѓММЪѕЃЌИУММЪѕЭЈЙ§ЮЂЕїИпНзФЃаЭЛёШЁЧПДѓжЊЪЖЃЌШЛКѓНЋЦфзЊвЦжСЕЭНзФЃаЭЃЌЪЕЯжФЃаЭбЙЫѕгыадФмгХЛЏЃЌЪЙЕУЕЭНзФЃаЭдкБЃГжаЁЧЩЁЂИпаЇЕФЭЌЪБЃЌЛёЕУНгНќЛђГЌдНИпНзФЃаЭЕФадФмЁЃ
6ЁЂЫљЮНДѓФЃаЭВЮЪ§ЪЧдѕУДДцДЂЕФЃП
Д№ЃКПЩвдЭЈЙ§ФЇДюЯТдиФЃаЭЃЌЛсгаФЃаЭНсЙЙЕФjsonЃЌПЩвдВЮПМjsonФкШнЁЃвЛАуЧщПіЯТгУПЊдДЕФPythonзщМўЃЌШЅНтЮізщМўЃЌЛсгаЯђСПаХЯЂЃЌПЩФмРэНтЛсгаЕуФбЖШЁЃЕЋЪЧПЩвдСЫНтДцДЂЙ§ГЬЁЃ
7ЁЂгавЛИіашвЊНтД№Ъ§бЇЮЪЬтЕФгІгУЃЌашвЊЪВУДбљЕФФЃаЭЃП
Д№ЃКПЩвдГЂЪдЪЙгУЧЇЮЪФЃаЭЃЌдкВЛЭЌСьгђжаПЊдДСЫВЛЩйФЃаЭЃЌБШШчcodeжИЕФЪЧБрГЬЕФЗНЯђЃЌПЩвдШЅСЫНтЯТЪЧЗёФмНтОіФуЕФЮЪЬтЁЃ
8ЁЂДњТыЩњГЩШЮЮёПЩвдгУЪВУДжИБъРДЦРЙРФЃаЭаЇЙћЃП
Д№ЃКзюжБЙлЕФЗНЪНЪЧжДааДњТыЁЃПЩФмашвЊаДвЛЯТБрГЬбщжЄЁЃ
9ЁЂгяСЯЪ§ОнМЏЕФЖрбљаддѕУДЖЈвхЃП
Д№ЃКгяСЯЪ§ОнМЏЕФЖрбљадЪЧжИЦфдкгябдЬиеїЁЂФкШнжїЬтЁЂЮФБОРраЭЁЂаДзїЗчИёЁЂгябдБфЬхЁЂзїепБГОАЁЂЪБМфПчЖШЕШЖрИіЮЌЖШЩЯЬхЯжГіЕФЗсИЛГЬЖШКЭВювьадЃЌжМдкецЪЕЗДгГгябдЕФЪЕМЪЪЙгУЧщПіЃЌЬсЩ§NLPФЃаЭЕФЗКЛЏФмСІКЭЖдЖрдЊгІгУГЁОАЕФЪЪгІадЁЃ
10ЁЂгаУЛгаАьЗЈдіМгЪфШыtokensЕФГЄЖШЃП
Д№ЃКвЛАуЪЧФЃаЭГЇЩЬШЅзіЃЌИіШЫзіЕФЛАЛсгаФбЖШЁЃ
11ЁЂИіШЫЪЙгУДѓФЃаЭЪБЃЌqwen-turboКЭqwen-maxгІИУдѕУДбЁЃП
Д№ЃКqwen-turboзЂжиЫйЖШгызЪдДаЇТЪЃЌЪЪКЯЖдЯьгІЫйЖШКЭВПЪ№БуНнадгаНЯИпвЊЧѓЕФГЁОАЃЛqwen-maxдђОлНЙЖЅМЖадФмгыШЋУцжЊЪЖЃЌЪЪгУгкЖдФЃаЭОЋЖШКЭДІРэИДдгШЮЮёФмСІгабЯИёвЊЧѓЕФЛЗОГЁЃЦфжаqwen-turboЕФЗбгУвЊБШqwen-maxЕЭЁЃИљОнФњЕФОпЬхашЧѓКЭЬѕМўШЈКтЃЌбЁдёзюЪЪКЯздМКЕФФЃаЭАцБОЁЃвВПЩвдВщПДФЃаЭНщЩмЃКhttps://help.aliyun.com/document_detail/2713153.htmlСЫНтОпЬхВювьЁЃ
12ЁЂФЃаЭбЕСЗжаЕФздЖЈвхФЃаЭдѕУДЩЯДЋЃП
Д№ЃКФЃаЭЕїгХжаЕФздЖЈвхФЃаЭЪЧжИФњвббЕСЗЭъГЩЕФФЃаЭЃЌЯывЊЖўДЮбЕСЗЪБЃЌЫљбЁдёЕФздЖЈвхФЃаЭЁЃШєЪЧФњздМКдкБОЕибЕСЗЕФФЃаЭВЛжЇГжЩЯДЋЁЃ
13ЁЂДѓФЃаЭЕФСьгђжЊЪЖЪЧЮЂЕїЛЙЪЧдЄбЕСЗбЇРДЕФЃП
Д№ЃКЭЈГЃЪЧдЄбЕСЗЕФЃЌЮЂЕїЪЧаЁВПЗжЁЃ
14ЁЂбЕСЗЭъЕФПЊдДФЃаЭЪЧЗёжЇГжЕМГіЃП
Д№ЃКФПЧАВЛжЇГжЁЃ
ФЃаЭбЕСЗВйзїжИФЯ
ЭЈЙ§ЪгЦЕбЇЯАСЫФЃаЭЕїгХЕФИХФюЁЂЪЙгУЫЕУїгыЯрЙизюМбЪЕМљАИР§ЕФжИв§ЁЃФЧШУЮвУЧЕЧТМАЂРядЦАйСЖПижЦЬЈЃЌаЁЪдХЃЕЖвЛЯТЃЁ
вЛАуРДНВЃЌФЃаЭЕїгХгаЫФИіжївЊЙ§ГЬЃЌАќРЈЃК
- Ъ§ОнзМБИЃКЙЙНЈЪЪКЯбЕСЗЕФбЕСЗЪ§ОнМЏЃЌвЛАуРДЪЧЮЪД№PairЕФзщКЯЃЌЛљгкВЛЭЌШЮЮёгаВЛЭЌЕФГЪЯжаЮЬЌЁЃ
- ФЃаЭЕїгХЃКЭЈЙ§бЁдёКЯЪЪЕФЪ§ОнМЏЃЌЕїећВЮЪ§ЃЌбЕСЗЬиЖЈЕФФЃаЭвдЬсИпФЃаЭаЇЙћЃЌПЩЭЈЙ§бЕСЗЙ§ГЬ/НсЙћжИБъГѕВНХаЖЯбЕСЗаЇЙћЁЃ
- ФЃаЭВПЪ№ЃКбЕСЗКУЕФФЃаЭашвЊВПЪ№КѓЗНПЩЬсЙЉЭЦРэЗўЮёЃЈЦРВтЁЂгІгУЕїгУОљашЯШВПЪ№ФЃаЭЃЉЁЃ
- ФЃаЭЦРВтЃКЙЙНЈКЯЪЪЕФЦРВтЪ§ОнМЏЃЌеыЖдвбОбЕСЗКУЕФФЃаЭНјааЦРВтЃЌЭЈЙ§ЦРВтЯЕЭГНјааДђЗжЛђБъзЂЃЌбщжЄФЃаЭЕїгХЕФаЇЙћЁЃ
ЕквЛВНЃКЪ§ОнзМБИ
- евЕНФЃаЭЙЄОпЃЌбЁдёбЕСЗЪ§ОнЃЌЕуЛїЩЯДЋЪ§ОнМЏЃЌЯТдиФЃАхЃЈЪ§ОнМЏФЃАх/ЦРВтМЏФЃАхЃЉВЂдйЩЯДЋЪ§ОнФкШнЃЌЕуЛїЭъГЩЁЃЩЯДЋЭъГЩКѓЃЌдкСаБэжаВщПДЖдгІЕФЪ§ОнЃЌгУгкФЃаЭбЕСЗЁЃ
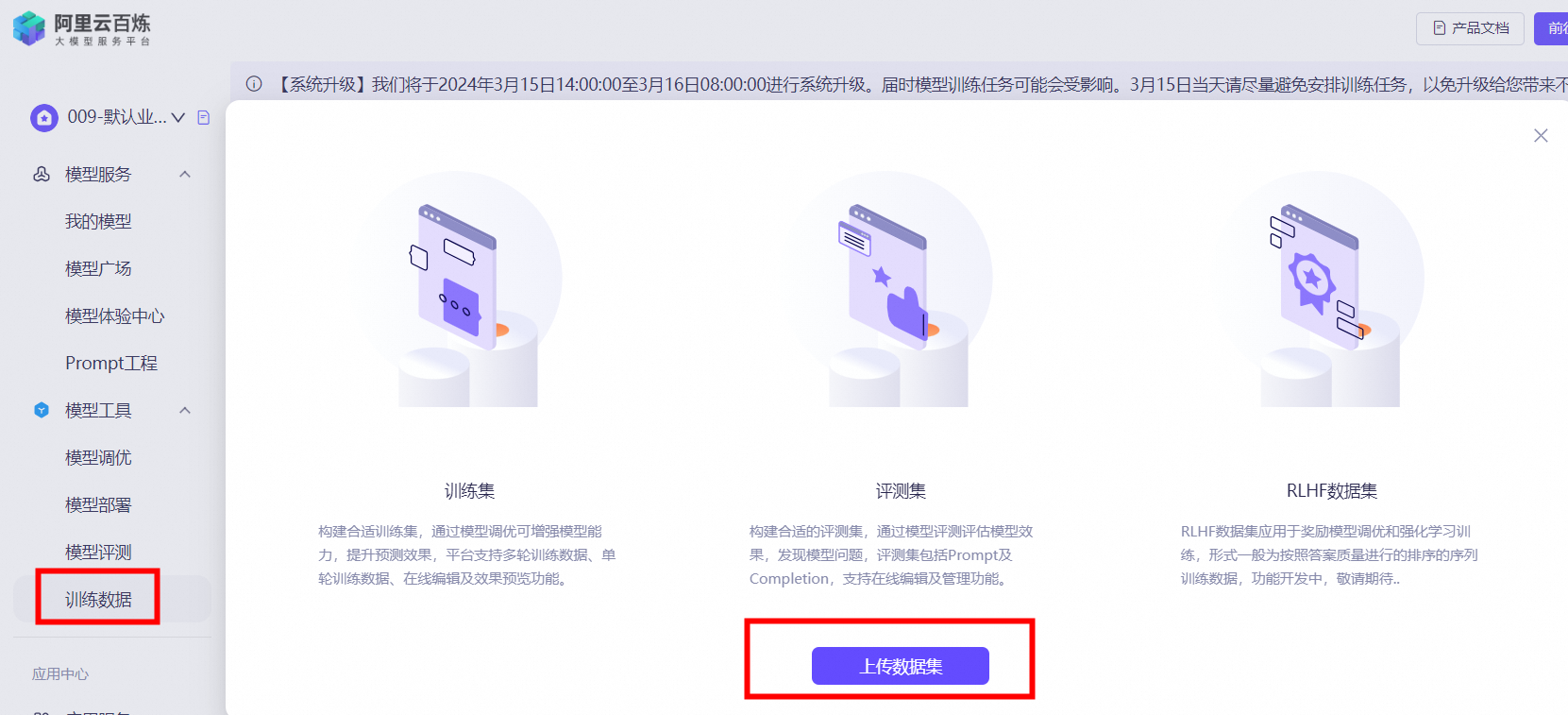

- ЕуЛїЦРВтМЏбЁдёЩЯДЋЪ§ОнМЏЃЌАДееЬсЪОДЋШыЪ§ОнЃЌЕуЛїЭъГЩЁЃЩЯДЋЕФЦРВтМЏжЇГжВщПДЁЂЯТдиЁЂЩОГ§ВйзїЁЃ
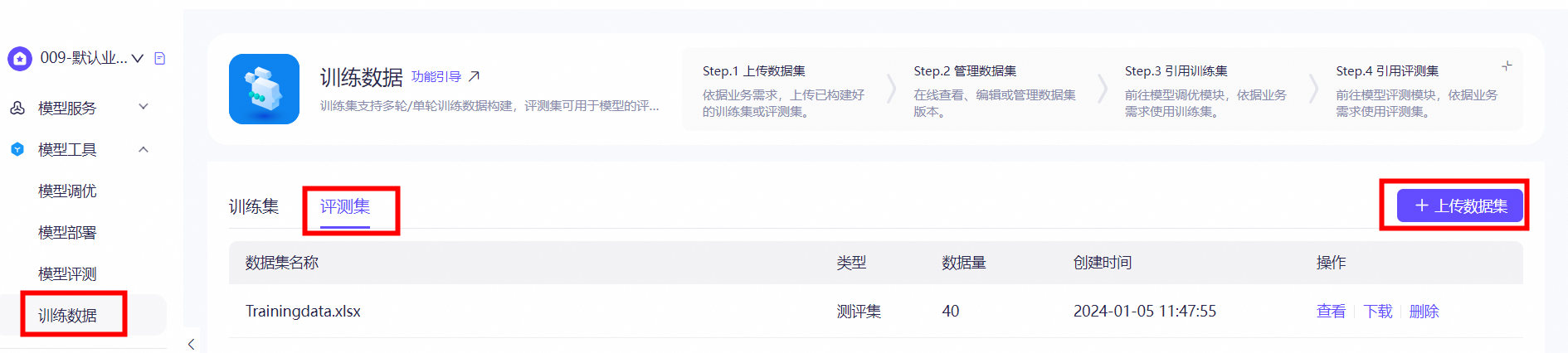
ЕкЖўВНЃКФЃаЭЕїгХ
аТдібЕСЗФЃаЭ
ЕуЛїЁОФЃаЭЕїгХЁПФЃПщЃЌбЁдёЁОбЕСЗаТФЃаЭЁПАДееЬсЪОНјааДДНЈЁЃаТдіЙ§ГЬЕФзЈвЕУћДЪПЩВщПДИХФюНтЪЭбЇЯАЁЃ

бЁдёФЃаЭАцБО
ФПЧАжЇГждЄжУФЃаЭКЭздЖЈвхФЃаЭЃЌЪзДЮаТдіФЃаЭбЕСЗЪБЮоПЩбЁздЖЈвхФЃаЭЁЃ
ШчКЮбЁдёФЃаЭtipsЃК
ЮЂЕїбЕСЗФЃаЭПЩвджЇГжЦѓвЕздЖЈвхбЕСЗЪ§ОнЃЌЭъГЩФЃаЭЕФЮЂЕїбЕСЗЃЌЮЂЕїбЕСЗНЋгАЯьФЃаЭЕФаЇЙћЃЌбЁдёКЯЪЪЕФЪ§ОнНЋЪЙЕУФЃаЭаЇЙћИќМгЪЪХфЦѓвЕЕФвЕЮёашЧѓЁЃЦѓвЕПЩвдбЁдёЛљгкЦѓвЕзЈЪєДѓФЃаЭЕФЛљЯпАцБОНјааЮЂЕїЃЌвВПЩвдбЁдёЛљгквбЮЂЕїЕФФЃаЭАцБОЩЯНјааНјвЛВНЮЂЕїЁЃ

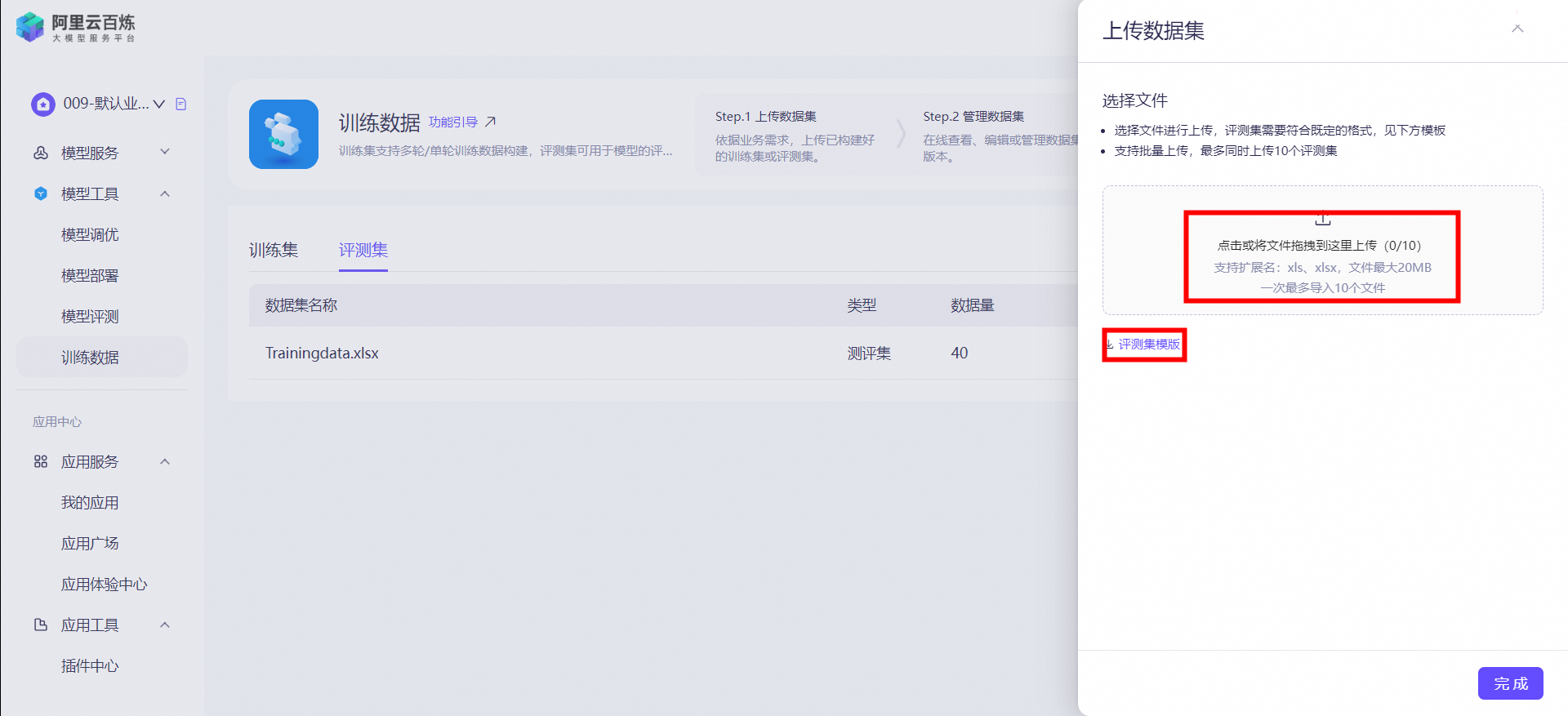
бЁдёФЃаЭЪ§Он
ЕуЛїЁОбЁдёЪ§ОнМЏЁПАДееВйзїв§ЕМЃЌЬјзЊЕНЁОбЕСЗЪ§ОнЁПвГУцЩЯДЋЪ§ОнФкШнЃЌЪ§ОнФкШнжСЩй40ЬѕФкШнЁЃжЇГжxlsЁЂxlslИёЪНЁЃашЯТдиФЃАхКѓНјааЩЯДЋЁЃ

зЂвтЃКбЁдёКЯЪЪЕФбЕСЗЪ§ОнНјааЮЂЕїбЕСЗЃЌбЕСЗЪ§ОнашвЊАДееМШЖЈЕФИёЪНЃЌ АќКЌ Prompt / CompletionЖдЃЌ ЯъЯИИёЪНЧыМћИёЪНВЮПМЃКexample.excelбЕСЗЪ§ОнжЇГжБОЕиЩЯДЋЛђбЁдёбЕСЗМЏЙмРэжаЕФЪ§ОнЃЌДЫДІЩЯДЋЕФбЕСЗМЏНЋЭЌЪББЃДцдкбЕСЗМЏЙмРэжаЁЃ
ЛьКЯбЕСЗ
ЭЈгУЛьКЯбЕСЗжЇГжгУЛЇНЋздЩэбЕСЗЪ§ОнгыВЩбљЕФЧЇЮЪЛљДЁФЃаЭЭЈгУЖрСьгђЁЂЖраавЕЁЂЖрГЁОАЪ§ОнЛьКЯЃЌНјаабЕСЗЃЌДгЖјЬсИпбЕСЗаЇЙћЃЌБмУтЛљДЁФЃаЭФмСІЕФвХЪЇЃЌзЂвтЃЌбЁдёЛьКЯбЕСЗКѓЃЌЛьКЯВЩбљЕФЪ§ОнНЋМЦШыбЕСЗTokenЪ§ОнСПжаЃЌвЛВЂМЦЗбЃЌЦНЬЈжЇГжбЁдёЖрИіЛљДЁбЕСЗЪ§ОнНјааЛьКЯбЕСЗЁЃ
ЪОР§ЃКжаЮФ-ЖдЛА 1.1БЖ >> зджїбЕСЗЪ§ОнЃКЛљДЁФЃаЭжаЮФЖдЛАЪ§Онвд1:1.1ЕФБШР§ЛьКЯбЕСЗ
ЪОР§ЃКжаЮФ-Ъ§бЇ 0.5БЖ >> зджїбЕСЗЪ§ОнЃКЛљДЁФЃаЭжаЮФЪ§бЇЪ§Онвд1:0.5ЕФБШР§ЛьКЯбЕСЗ

ГЌВЮХфжУ
ЦѓвЕПЩвдЭЈЙ§ВЮЪ§ХфжУРДгАЯьФЃаЭЕїгХЕФЙ§ГЬЃЌДгЖјгАЯьФЃаЭЕїгХЕФаЇЙћЃЌВЛЭЌЕФВЮЪ§ХфжУбЕСЗЕФНсЙћВЛЭЌЃЌвЛАуНЈвщЪЙгУФЌШЯХфжУЁЃ

здЖЈвхВЮЪ§УћДЪНтЪЭВЮПМИХФюНтЪЭЁЃ
ПЊЪМбЕСЗ
дЄРРФуЕФбЕСЗХфжУЃЌзМБИПЊЪМбЕСЗЃЌПЊЪМбЕСЗНЋНјШыЖгСаЃЌПЩдкФЃаЭЙмРэСаБэЫЂаТзДЬЌЃЌЭЌЪБЃЌПЩВщПДбЕСЗЙ§ГЬжаЕФЯрЙижИБъЃЌбЕСЗНсЪјКѓНЋЭЈЙ§ЭЦЫЭЭЈжЊЁЃ
живЊ
ФЃаЭЕїгХНЋВњЩњбЕСЗЗбгУЃЌбЕСЗМлИё 0.1дЊ/ЧЇtokens ЃЌЕуЛїВщПДВњЦЗМЦЗбЁЃ
МЦЫуЙЋЪНЃК
МЦЗбtokenЪ§= бЕСЗМЏtokenЪ§ * бЛЗДЮЪ§ЁЃ
ФЃаЭЕїгХПЊЪМКѓЃЌОЭЛсВњЩњЗбгУЃЈбЕСЗЪЇАмГ§ЭтЃЉЁЃ


ФЃаЭСаБэ
ЕБе§дкбЕСЗжаЪБЃЌПЩвдВйзїВщПДЁЂжежЙбЕСЗЁЃШєбЕСЗЭъГЩКѓЃЌПЩВйзїЩОГ§бЕСЗШЮЮёЁЃ


ВщПДЃКПЩвдВщПДе§дкбЕСЗжаЕФФЃаЭаХЯЂЃЛвВПЩвддквГУцжаЕуЛїЁОПЊЪМВПЪ№ЁП Traning lossЁЂValidation LossЁЂValidation Token Accuracy ЕФУћДЪНтЪЭЧыЛЌЕНЯТЗНЖЮТфВщПДЁЃПЩвдЕуЛїжежЙбЕСЗКЭЫЂаТбЕСЗНјеЙЁЃ

жежЙбЕСЗЃКНЋЭЃжЙбЕСЗШЮЮёЁЃзДЬЌЮЊжежЙбЕСЗЁЃ


ЩОГ§ЃКЕуЛїЩОГ§КѓИУФЃаЭНЋВЛЛсДцдкЃЛНїЩїВйзїЁЃ

ФЃаЭВПЪ№ЃКЕуЛїФЃаЭВПЪ№КѓЃЌЕуЛїПЊЪМВПЪ№ЃЌФЃаЭВПЪ№ФкШнЧыЗУЮЪФЃаЭВПЪ№НјааВщПДЁЃ
зЂвтЃКВПЪ№ФЃаЭНЋВњЩњФЃаЭВПЪ№ЗбгУЃЌВПЪ№МлИёВњЦЗМЦЗбЁЃФЃаЭПЊЪМВПЪ№КѓЃЌОЭЛсВњЩњЗбгУЃЈВПЪ№ЪЇАмГ§ЭтЃЉЁЃ
ЕкШ§ВНЃКФЃаЭВПЪ№
зЂвтЃКВПЪ№ФЃаЭНЋВњЩњФЃаЭВПЪ№ЗбгУЃЌВПЪ№МлИёЕуЛїВщПДВњЦЗМЦЗбЁЃФЃаЭВПЪ№ГЩЙІКѓЃЌЯЕЭГНЋПЊЪММЦЗбЃЌЪжЖЏЯТЯпКѓФЃаЭНЋВЛдйМЦЗбЃЈВПЪ№ЪЇАмГ§ЭтЃЉЃЌВЛЭЌзДЬЌЯТМЦЗбТпМЧыВЮПМЮФеТзюКѓЕФБэИёЁЃ
ТЗОЖЃКФЃаЭжааФ-ФЃаЭВПЪ№-ВПЪ№аТФЃаЭ

ЕуЛїЁОВПЪ№аТФЃаЭЁПКѓ--бЁдёКЯЪЪЕФФЃаЭНјааВПЪ№
- здЖЈвхФЃаЭЃКгЩгУЛЇздМКНјааSFTбЕСЗЕУЕНЕФФЃаЭЃЌВПЪ№КѓПЩЬсЙЉФЃаЭЗўЮёЃЌЪзДЮВПЪ№УЛгаПЩбЁздЖЈвхФЃаЭЁЃ
- дЄжУФЃаЭЃКЮДОбЕСЗЃЌЯЕЭГЬсЙЉЕФдЄжУЛљДЁДѓФЃаЭЃЌжБНгВПЪ№ЛљДЁФЃаЭЬсЙЉЗўЮёЁЃ

ЕуЛїЁОЯТвЛВНЁПбЁдёЖдгІЕФзЪдДХфжУ
- АќдТзЪдДЃКбЁдёвбЙКТђЕФАќдТдЄИЖЗбзЪдДзщЃЌВЛЭЌЕФФЃаЭЫљашвЊЕФзЪдДВЛЭЌЃЌбЁдёФЃаЭКѓЃЌЯЕЭГНЋздЖЏЩИбЁашвЊЕФзЪдДРраЭЃЌдЄИЖЗбзЪдДАДдТЪлТєЃЌадМлБШИќИп
- АДСПИЖЗбЃКбЁдёКѓИЖЗбЕФФЃЪНЃЌМДПЬЭъГЩВПЪ№ЃЌЯЕЭГНЋдкВПЪ№ГЩЙІКѓПЊЪММЦЗбЃЌИЖЗбФЃЪНИќМгЖЏЬЌЃЌЮоЕНЦкЪБМфЃЌЫцЪБЩЯЯТЯпЁЃ

зюКѓЕуЛїЁОПЊЪМВПЪ№ЁПЕШД§зДЬЌИќаТЮЊВПЪ№ГЩЙІЁЃ

ЯЕЭГНЋЕЏДАИцжЊВПЪ№ЫљашЕФЗбгУЃЌЕуЛїШЗШЯКѓЃЌЯЕЭГНЋПЊЪМВПЪ№ЃЌВПЪ№ГЩЙІКѓПЊЪМЪеЗб
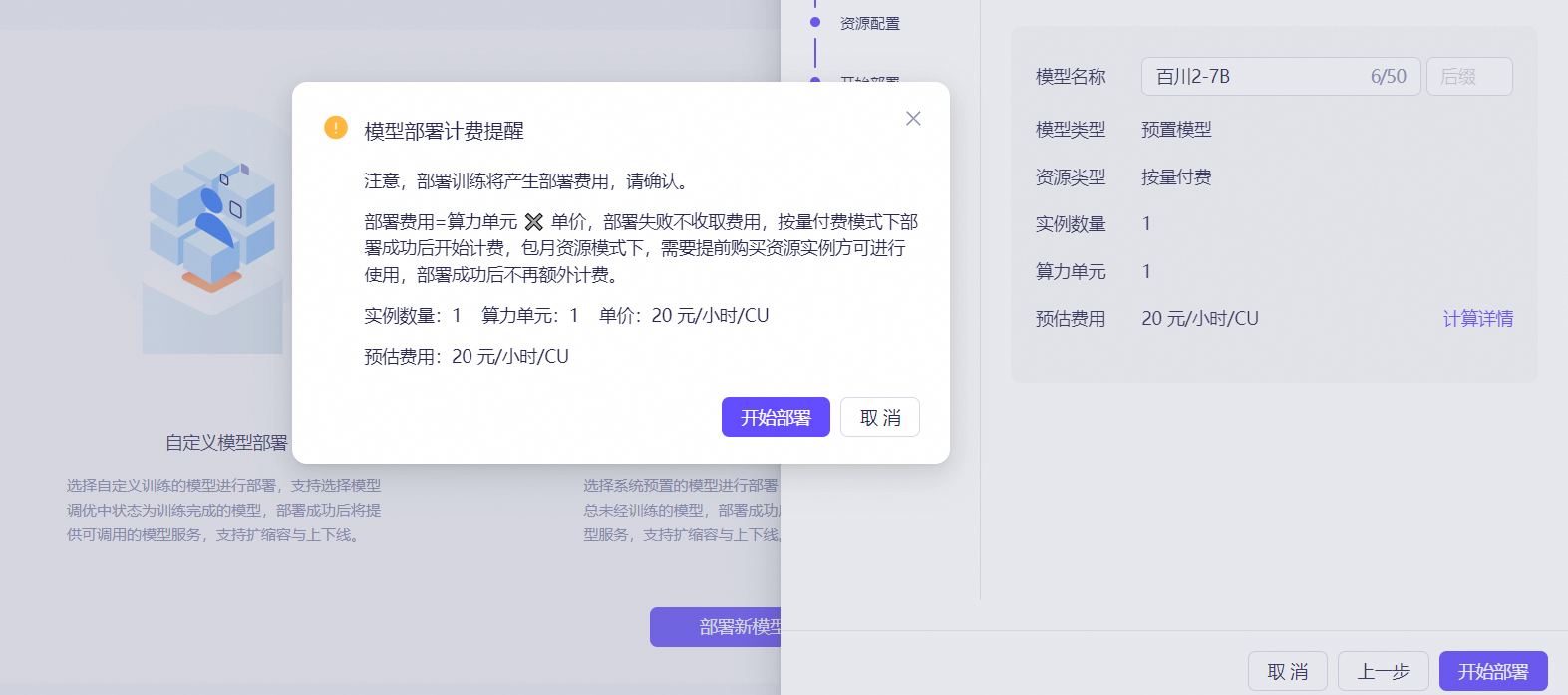

ВПЪ№ЭъГЩКѓЃЌФЃаЭдЫааЬЌНЋБфИќЮЊдЫаажаЃЌПЩвдВйзїВщПДЁЂРЉЫѕШнЁЂЯТЯпЁЃВПЪ№ЪЇАмжЇГжжиаТВПЪ№ЃЌИїВйзїЫЕУїШчЯТЃК
- ВщПДЃКВщПДФЃаЭВПЪ№ЕФЯъЧщЃЌАќРЈзЪдДЁЂФЃаЭРраЭЕШЁЃ
- жиаТВПЪ№ЃКВПЪ№ЪЇАмКѓЃЌПЩЕуЛїжиаТВПЪ№жиЦєВПЪ№ШЮЮёЃЌЭъГЩВПЪ№ШЮЮёЁЃ
- РЉЫѕШнЃКБфХфзЪдДХфжУЃЌПЩдіМгзЪдДЛђМѕЩйзЪдДЃЌБфИќГЩЙІКѓЃЌЯЕЭГНЋАДБфИќКѓЪЕМЪЪЙгУЕФзЪдДМЦЗбЁЃ
- ЯТЯпЃКПЩНЋВПЪ№жаЕФШЮЮёЯТЯпЃЌЯТЯпКѓИУШЮЮёНЋЛсздЖЏЩОГ§ЁЃ
- ЩОГ§ЃКВПЪ№ЪЇАмЁЂЧЗЗбЯТЯпКѓЃЌПЩЩОГ§ФЃаЭЃЌЩОГ§КѓВЛдйМЦЗбЁЃ
зДЬЌ |
Вйзї |
МЦЗбЧщПі |
ВПЪ№жа |
ВщПД |
ДЫзДЬЌВЛМЦЗб |
дЫаажа |
ВщПДЁЂРЉЫѕШнЁЂЯТЯп |
ДЫзДЬЌГжајМЦЗбЃЌЕуЛїЯТЯпКѓВПЪ№ШЮЮёЯћЪЇЃЌЭЃжЙМЦЗб |
ЧЗЗбЭЃЗў |
ВщПДЁЂЩОГ§ |
ДЫзДЬЌВЛМЦЗбЃЌЧЗЗбзДЬЌВЛЛсГжајМЦЗбЃЌЕЋГфжЕКѓЃЌФЃаЭНЋЛжИДЗўЮёЃЌздЖЏЛжИДКѓНЋПЊЪММЦЗбЃЌЕуЛїЩОГ§КѓВПЪ№ШЮЮёЯћЪЇЃЌВЛдйМЦЗб |
ЧЗЗбЛжИДжа |
ВщПД |
ДЫзДЬЌВЛМЦЗбЃЌБэЪОеЫЛЇвбГфжЕЃЌЯЕЭГздЖЏЛжИДЗўЮёжаЃЌЗўЮёЛжИДКѓЃЌзДЬЌБфЛЛЮЊдЫаажаНЋЛжИДМЦЗб |
ВПЪ№ЪЇАм |
ВщПДЁЂЩОГ§ЁЂжиаТВПЪ№ |
ДЫзДЬЌВЛМЦЗбЃЌжиаТВПЪ№ГЩЙІКѓБфЮЊдЫаажазДЬЌНЋНјааМЦЗбЃЌЕуЛїЩОГ§КѓВПЪ№ШЮЮёЯћЪЇЃЌВЛдйМЦЗб |
ЕкЫФВНЃКФЃаЭЦРВт
ЭЈЙ§ФЃаЭЦРВтЃЌРДМьбщбЕСЗГіРДЕФФЃаЭЪЧЗёФмЙЛИјГіздМКЫљЦкЭћЕФНсЙћЁЃ
ЭъГЩФЃаЭВПЪ№КѓЃЌШчашВтЪдФЃаЭЕФаЇЙћЃЌПЩдкФЃаЭЦРВтжаНјааЦРВтЃЌФЃаЭЦРВташвЊЪзЯШЙЙНЈЦРВтЕФЪ§ОнМЏЃЌЙЙНЈЗНЗЈРрЫЦгкбЕСЗМЏЕФЙЙНЈЃЌЪ§ОнИёЪНЭЌбљЪЧЮЪД№PairЖдЃЌЖдгкPromptЖјбдЭљЭљЪЧашвЊбщжЄЕФЮЪЬтЃЌЖдгкCompletionЖјбдЭљЭљЪЧЦРВтВЮПМЕФД№АИЃЌзюжеЭЈЙ§ЖдБШФЃаЭНсЙћгыВЮПМД№АИЃЌЭЌЪБзлКЯПМТЧФЃаЭНсЙћЕФе§ШЗадЃЌЖдФЃаЭНсЙћНјааДђЗжЛђХХађЃЌЕУЕНФЃаЭецЪЕаЇЙћЁЃ
ФЃаЭЦРВтгаСНжжФЃЪНЃЌНтЪЭШчЯТЃК
ЦРВтЗНЪН |
ЦРВтаЇЙћ |
ЕЅИіЦРВт |
ЕЅИіЦРВтжївЊгУРДЦРВтЕЅвЛФЃаЭЕФаЇЙћЃЌбЁдёЦРВтМЏКѓЃЌЦНЬЈНЋздЖЏЛљгкЦРВтМЏжаЕФPromptдЄВтФЃаЭНсЙћЃЌВЂЧвЭЌЪБеЙЪОЦРВтМЏжадЄжУЕФЦРВтНсЙћзїЮЊВЮПМЃЌеыЖдФЃаЭдЄВтНсЙћНјааДђЗжКѓЃЌПЩХаЖЯФЃаЭаЇЙћЁЃ |
ЖдБШЦРВт |
ЖдБШЦРВтжївЊгУРДЦРВтЖрИіФЃаЭЕФаЇЙћЃЌбЁдёЦРВтМЏКѓЃЌЦНЬЈНЋздЖЏЛљгкЦРВтМЏжаЕФPromptдЄВтУПИіФЃаЭЕФНсЙћЃЌВЂЧвЭЌЪБеЙЪОЦРВтМЏжадЄжУЕФЦРВтНсЙћзїЮЊВЮПМЃЌЖдБШЦРВтжЇГжеыЖдУПИіВЮгыЦРВтЕФФЃаЭНјааДђЗжЃЌЭЌЪБжЇГжФЃаЭХХађЃЌЭЈЙ§ЦРВтНсЙћПЩХаЖЯВЛЭЌФЃаЭжЎМфЕФаЇЙћВювь зЂвтЃЌЖдгкЖдБШЦРВтЖјбдЃЌНјааЖдБШЕФУПИіЮЂЕїФЃаЭОљашЖРСЂВПЪ№ЗНПЩНјааЦРВтЃЌеыЖдЛљДЁФЃаЭЕФЦРВтНЋМЦСПtokenЕїгУЗбгУЃЌЯъЧщЧыМћВњЦЗМлИёЯъЧщЁЃ |
вЛАубЕСЗЛђВПЪ№СЫЕЅИіФЃаЭЕФЧщПіЯТЃЌЮвУЧЛсНјааЕЅИіЦРВтЃЌШчЙћЮвУЧбЕСЗЛђВПЪ№СЫЖрИіФЃаЭЃЌЯЃЭћЖдБШВЛЭЌФЃаЭЕФаЇЙћЃЌдђПЩбЁдёЖдБШЦРВтФЃЪННјааЦРВтЁЃ
ВйзїЪОР§
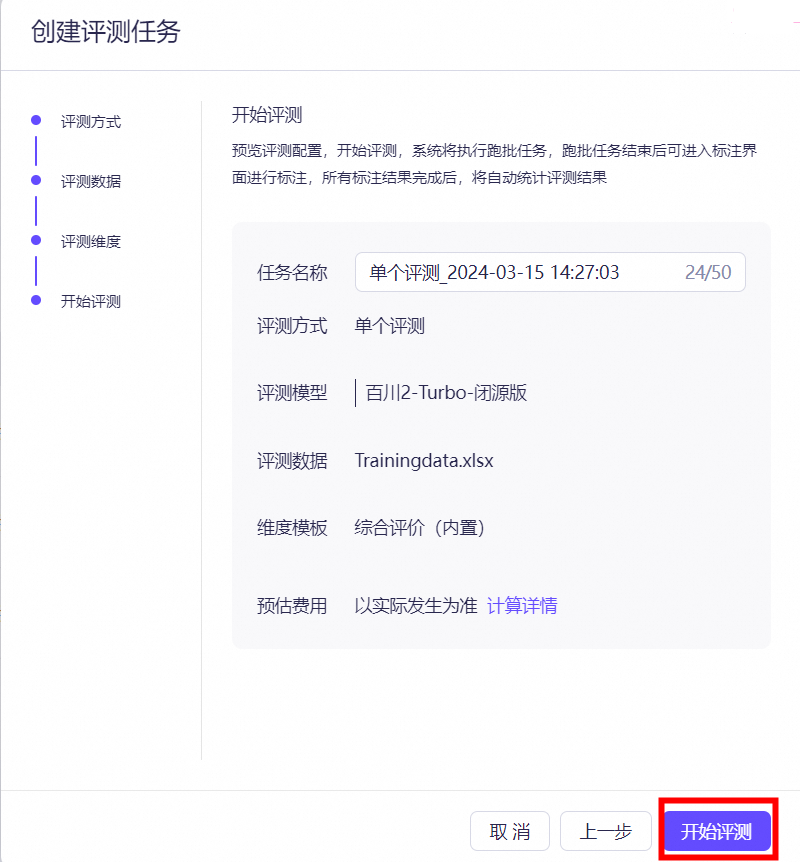
ТЗОЖЃКФЃаЭЙЄОп--ФЃаЭЦРВт--ДДНЈЦРВтШЮЮёЁЃ

бЁдёЦРВтЗНЪНЃЌвГУцЩЯЗНгаВЛЭЌЦРВтЗНЪННщЩмЃЌАДашбЁдёЃЌНЈвщбЁдёЕЅИіЦРВтЁЃ

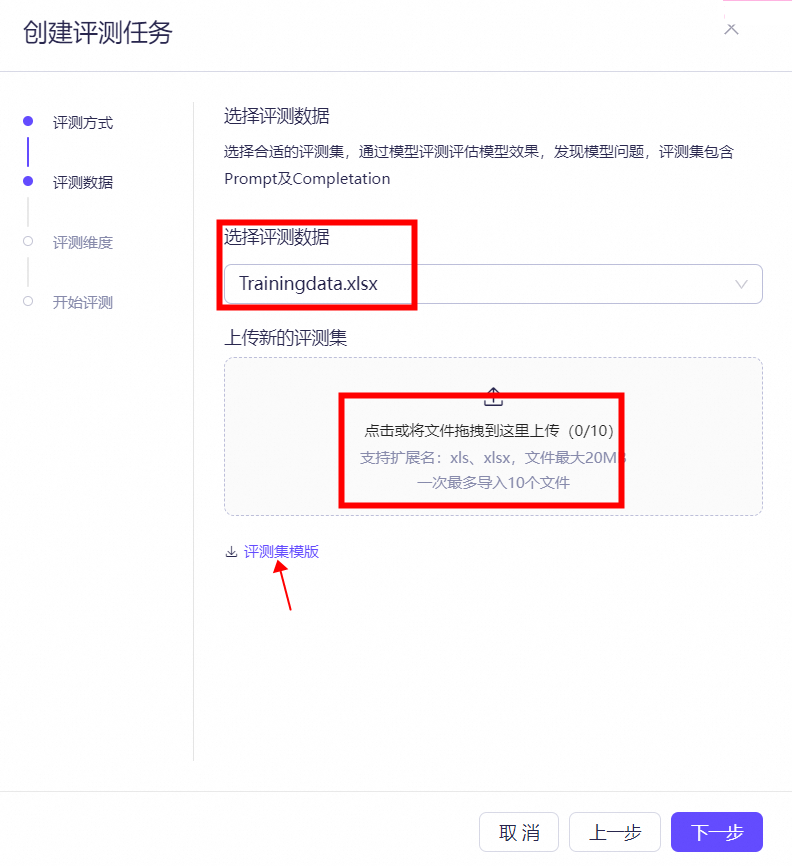
ЦРВтШЮЮёПЊЪМКѓЃЌЕуЛїЦРВтЃЌПЩвдздааЖдЪ§ОнНјааДђБъЁЃ


ЦРВтЭъГЩКѓПЩвдЕуЛїЯТдиВщПДЦРВтНсЙћЁЃ
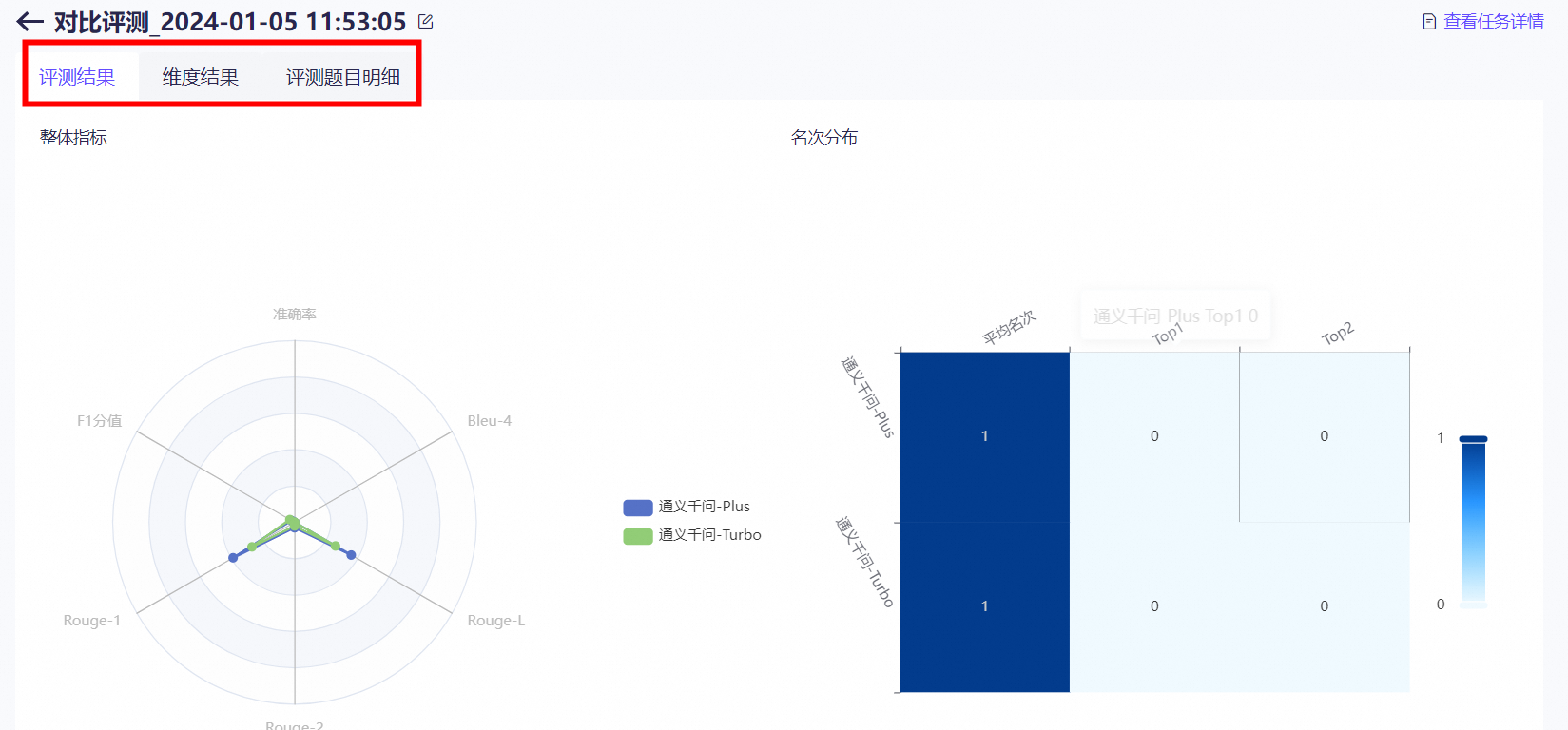
ФЃаЭЦРВтЛсВњЩњФЃаЭЗўЮёЕїгУЗбгУЃЌУПИіБЛЦРВтЕФФЃаЭОљЛсНјааМЦЗбЃЌМЦЗбТпМгыФЃаЭЭЦРэЗўЮёвЛжТЃЌАДееtokenСПНјааМЦЗбЁЃ
вдЩЯОЭЪЧФЃаЭЕїгХ&ВПЪ№ВЂВтЦРЕФШЋВПФкШнРВ~ ФњдкЬхбщЙ§ГЬжаЪЧЗёгагіЕНЪВУДЮЪЬташвЊЮвУЧНтД№ЃПЛЖгдкЦРТлЧјжаСєбдЬНЬжЃЁ
