етЦЊЮФеТНщЩмСЫвЛРрРыЩЂЫцЛњВЈЖЏТЪФЃаЭЃЌВЂНщЩмСЫвЛаЉЬиЪтЧщПіЃЌАќРЈ GARCH КЭ ARCH ФЃаЭЁЃБОЮФеЙЪОСЫШчКЮФЃФтетаЉЙ§ГЬвдМАВЮЪ§ЙРМЦЁЃетаЉЪЕбщБраДЕФ Python ДњТыдкЮФеТФЉЮВв§гУЁЃ
РыЩЂЫцЛњВЈЖЏТЪФЃаЭ
 ЪЧвЛИіЫцЛњЛљЃЌгавЛИіЭъећЕФ
ЪЧвЛИіЫцЛњЛљЃЌгавЛИіЭъећЕФ 
 ЕФПЩВтСПзгМЏ
ЕФПЩВтСПзгМЏ  , вЛИіИХТЪВтСП
, вЛИіИХТЪВтСП  КЭвЛИіЙ§ТЫ
КЭвЛИіЙ§ТЫ 
- вђДЫЃЌЪБМфЪЕР§ЪЙгУЗЧИКећЪ§НјааЫїв§

- ЛёШЁађСаЕФЕквЛИі tдЊЫи
 , МЧ
, МЧ 
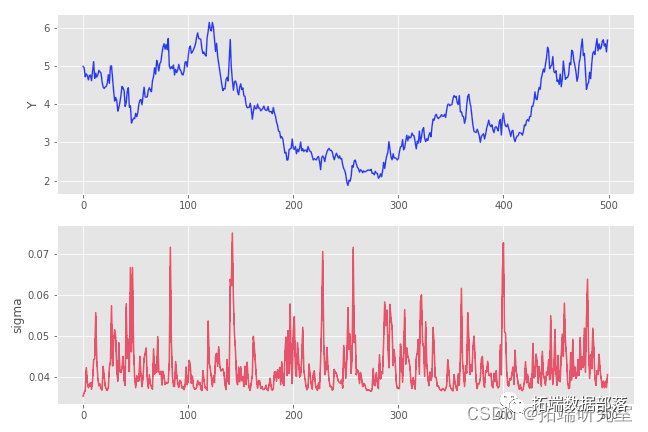
_РыЩЂЫцЛњВЈЖЏТЪ_( DSV) ФЃаЭжаЃЌ  ЪЧвЛИіЪЕжЕ stochastic process ЃЈвЛЯЕСаЫцЛњБфСПЃЉТњзувдЯТЗНГЬЃК
ЪЧвЛИіЪЕжЕ stochastic process ЃЈвЛЯЕСаЫцЛњБфСПЃЉТњзувдЯТЗНГЬЃК

ЦфжаЃК
- Z ЪЧ F ЕФдыЩљЙ§ГЬЁЃ
- Іеi ЪЧЪЕЪ§ЃЌЮвМйЩш
 ВЂЧв gi ,hi ЪЧЗЧИКжЕЁЃ
ВЂЧв gi ,hi ЪЧЗЧИКжЕЁЃ - fi ЁЂgi КЭ h_ihi ЪЧЙ§ГЬЕФШЗЖЈадКЏЪ§ЁЃ
- Й§ГЬ
 ЭЈГЃГЦЮЊ _ЦЋвЦ_ЃЌЖј Ів ГЦЮЊ XЕФ_ВЈЖЏТЪЁЃ_вђЮЊІв ЪЧвЛИіЫцЛњЙ§ГЬЃЌЫљвдЩЯУцЖЈвхЕФЙ§ГЬ X ЪєгквЛИіЫцЛњВЈЖЏТЪФЃаЭЕФДѓМвзхЁЃ
ЭЈГЃГЦЮЊ _ЦЋвЦ_ЃЌЖј Ів ГЦЮЊ XЕФ_ВЈЖЏТЪЁЃ_вђЮЊІв ЪЧвЛИіЫцЛњЙ§ГЬЃЌЫљвдЩЯУцЖЈвхЕФЙ§ГЬ X ЪєгквЛИіЫцЛњВЈЖЏТЪФЃаЭЕФДѓМвзхЁЃ - ЖдгкдыЩљЙ§ГЬ ZЃЌЪЙЕУУПИі Z_tЕФОљжЕКЭЗНВюЖМДцдкЃЌЮвУЧга
 КЭ
КЭ  .
.
АИР§
жЦЖЈЭЈгУ DSV ФЃаЭЕФЬиЛЏЃК
КѓвЦЫузг  ЃЌЖдгк
ЃЌЖдгк  ЃЌВњЩњЦфВЮЪ§Й§ГЬЕФжЭКѓАцБОЃЌМД
ЃЌВњЩњЦфВЮЪ§Й§ГЬЕФжЭКѓАцБОЃЌМД  ЃЌ КЭ
ЃЌ КЭ 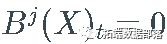 ЃЌ ШчЙћ
ЃЌ ШчЙћ 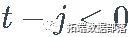 . Р§Шч
. Р§Шч

ЮЊЗНБуЦ№МћЃЌЮвЩшжУ  КЭ
КЭ 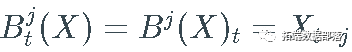 .
.
ЖдгкЯТУцСаБэжаЕФЫљгаЬиЪтЧщПіЃЌЮвМйЩшКЏЪ§ fi ЁЂgi КЭ h_i ДгВЮЪ§Й§ГЬжабЁдёвЛИідЊЫиЃЌМД 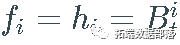 ЃЌ КЭ
ЃЌ КЭ  .
.
GARCH Й§ГЬЖЈвхСэЭтЩшжУ  ЁЃ
ЁЃ
_GARCH(1, 1)_Й§ГЬЗЧГЃСїааЃК

дк ARCH Й§ГЬжаЃЌВЈЖЏадОпгаМђЛЏаЮЪНЃЌЖдгкЫљга iЃЌІЫi = 0ЃЌВЂЧв  ЁЃ
ЁЃ

_ARCH(1)_Й§ГЬЛЙ Тњзу  ЖдЫљга
ЖдЫљга  :
:

ФЃФт
РыЩЂЫцЛњВЈЖЏТЪФЃаЭЭЈГЃгУгкЖдЙлВьЕНЕФЪБМфађСаЕФЖдЪ§ЪевцНјааНЈФЃЁЃвђДЫЃЌЮЊСЫФЃФтдЪМЪБМфађСаЕФТЗОЖЃЌЮвУЧашвЊФЃФтЦфЖдЪ§ЪевцВЂМЦЫу  .
.
гЩДјВЮЪ§ЕФИпЫЙдыЩљЧ§ЖЏЕФ GARCH(1,1) Й§ГЬЕФбљБОТЗОЖ  :
:
path( \[0.001, 0.2, 0.25\]) cumprod* repeat.reshape plt.subplots
зЂвт Ів Й§ГЬЮЊ  ВЛФмЕЭгк
ВЛФмЕЭгк  Ёж0.0353
Ёж0.0353
зюДѓЫЦШЛЙРМЦ
зюДѓЫЦШЛЃЈMLЃЉВЮЪ§ЙРМЦЪЧЫљгаЬжТлФЃаЭЕФбЁдёЗНЗЈЃЌвђЮЊзЊЛЛУмЖШЃЌМДИјЖЈЙ§ШЅаХЯЂЕФ X_t ЕФУмЖШ  ЪЧУїШЗвбжЊЕФЁЃвђДЫЃЌЙ§ГЬбљБОТЗОЖ x ЕФЖдЪ§ЫЦШЛКЏЪ§гЩЯТЪНИјГі
ЪЧУїШЗвбжЊЕФЁЃвђДЫЃЌЙ§ГЬбљБОТЗОЖ x ЕФЖдЪ§ЫЦШЛКЏЪ§гЩЯТЪНИјГі

Цфжа  ЃЌЖј
ЃЌЖј  ЪЧ ZЕФУмЖШЁЃНЋЩЯЪіЖдЪ§ЫЦШЛКЏЪ§зюаЁЛЏПЩЕУЕН
ЪЧ ZЕФУмЖШЁЃНЋЩЯЪіЖдЪ§ЫЦШЛКЏЪ§зюаЁЛЏПЩЕУЕН  ЕФзюДѓЫЦШЛЙРМЦ
ЕФзюДѓЫЦШЛЙРМЦ  ЃК
ЃК
 .
.
УЩЬиПЈТобаОП
ЮЊСЫВтЪд ML ВЮЪ§ЙРМЦЙ§ГЬЃЌЮвНјааСЫвдЯТУЩЬиПЈТоЪЕбщЁЃ
- ЪЙгУВЮЪ§ (0.001, 0.2, 0.25) ФЃФтГЄЖШЮЊ 5000 ЕФ 2500 ИіЖРСЂ GARCH(1,1) Й§ГЬТЗОЖЁЃЮвЪЙгУСЫИпЫЙдыЩљЃЌМД
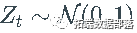 .
. - НЋетаЉТЗОЖжаЕФУПвЛИіЖМЪфШыЕН ML ЙРМЦВЂЛёЕУЙРМЦЕФВЮЪ§ЯђСП
 .
. - ДЫгХЛЏЙ§ГЬжаВЮЪ§ЕФЫбЫїЗЖЮЇЯожЦЮЊ [1e-8, 1]ЁЃ
- НЋдЪМ
 гыЙРМЦЕФ
гыЙРМЦЕФ 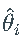 НјааБШНЯЁЃ
НјааБШНЯЁЃ - ЪЙгУВЮЪ§ЯђСП
 ФЃФт GARCH(1,1)ЃЌМЦЫуОљжЕКЭБъзМВюЃЌВЂНЋЫќУЧгыЁАецЪЕЁБОљжЕКЭБъзМВюЃЈЗжБ№ЮЊ 5.098 КЭ 1.084ЃЉНјааБШНЯЁЃ
ФЃФт GARCH(1,1)ЃЌМЦЫуОљжЕКЭБъзМВюЃЌВЂНЋЫќУЧгыЁАецЪЕЁБОљжЕКЭБъзМВюЃЈЗжБ№ЮЊ 5.098 КЭ 1.084ЃЉНјааБШНЯЁЃ
е§ШчЦкЭћЕФФЧбљЃЌЙРМЦСП 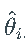 ЗЧГЃВЛзМШЗЃЌВЂЧвдкДѓЖрЪ§ЧщПіЯТЃЌЩѕжСВЛНгНќецЪЕЯђСП
ЗЧГЃВЛзМШЗЃЌВЂЧвдкДѓЖрЪ§ЧщПіЯТЃЌЩѕжСВЛНгНќецЪЕЯђСП  ЁЃЬиБ№ЪЧЃЌЙРМЦЕФ
ЁЃЬиБ№ЪЧЃЌЙРМЦЕФ  КЭ
КЭ  ЭЈГЃЩшжУЮЊСуЃЈВЮМћЯТУцЕФжБЗНЭМЃЉЁЃ
ЭЈГЃЩшжУЮЊСуЃЈВЮМћЯТУцЕФжБЗНЭМЃЉЁЃ
ps = \[0.001, 0.2, 0.25\] cumprod * repeat print, np.std

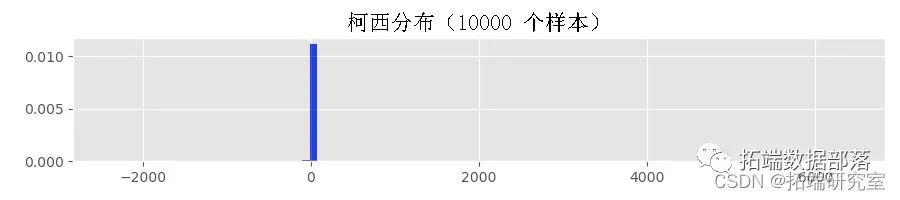
СэвЛЗНУцЃЌРДздЙРМЦЕФ  ЕФЙ§ГЬОљжЕКЭБъзМЦЋВювЊзМШЗЕУЖрЁЃетЪЧвЛМўКУЪТЃЌвђЮЊЮвУЧЭЈГЃИќЙиаФЛжИДЮДжЊЪ§ОнЩњГЩЙ§ГЬЕФЬиеїЃЌЖјВЛЪЧФЃаЭЕФецЪЕВЮЪ§жЕЁЃ
ЕФЙ§ГЬОљжЕКЭБъзМЦЋВювЊзМШЗЕУЖрЁЃетЪЧвЛМўКУЪТЃЌвђЮЊЮвУЧЭЈГЃИќЙиаФЛжИДЮДжЊЪ§ОнЩњГЩЙ§ГЬЕФЬиеїЃЌЖјВЛЪЧФЃаЭЕФецЪЕВЮЪ§жЕЁЃ
mes, stvs, esms ax\[1\].hist fig.tight_layout

ПТЮїдывє
дыЩљЙ§ГЬ ВЛБиЙщвЛЛЏЮЊОљжЕ 0 КЭЗНВю 1ЁЃЪЕМЪЩЯЃЌЮвУЧжЛашвЊШЗБЃЫцЛњБфСП Zt ЕФЗжВМОпгаУмЖШМДПЩЁЃШчЙћЪЧетжжЧщПіЃЌЙ§ГЬФЃФтКЭ ML ЙРМЦЖМПЩвдАДееУшЪіЕФЗНЪНЙЄзїЁЃ
ФЧУДШчКЮгУДгПТЮїЗжВМжаВЩбљЕФдыЩљЬцЛЛИпЫЙдыЩљФиЃПдкаэЖрИХТЪТлЪщМЎжаЃЌПТЮїЗжВМБЛгУзїЗДР§ЃЌвђЮЊЫќОпгааэЖрЁАВЁЬЌЁБЬиадЁЃР§ШчЃЌЫќУЛгаОљжЕЃЌвђДЫвВУЛгаЗНВюЁЃ
ЮвВЛжЊЕРПТЮїЗжВМжаЕФВЛЮШЖЈбљБОЪЧЪВУДбљзгЕФЁЃПДвЛЯТДјгаВЮЪ§ЯђСПЕФ GARCH(1,1) Й§ГЬЕФЪОР§ТЗОЖ  :
:

ШчЙћЪЙгУТЗОЖЩњГЩКЏЪ§ЕФЪБМфзуЙЛГЄЃЌЩѕжСПЩФмЛсЩњГЩвчГівьГЃЁЃвђДЫЃЌЮвгУРДЩњГЩЩЯУцЯдЪОЕФжБЗНЭМЕФ Python КЏЪ§ЪЇАмСЫЁЃЮЊСЫСЫНтдвђЃЌШУЮвУЧЪЙгУРДздПТЮїЗжВМЕФбљБОЩњГЩвЛаЉжБЗНЭМЃК


ПТЮїЗжВМОпгаЗжЮЛЪ§КЏЪ§

Жд  ЦРЙР
ЦРЙР  ИјГі
ИјГі

етвтЮЖзХЃЌР§ШчЃЌдк 0.0001 ЕФИХТЪЯТЃЌВЩбљжЕДѓгк 3183.10ЁЃЮЊСЫБШНЯЃЌШУЮвУЧМЦЫуБъзМе§ЬЌЗжВМЕФЯргІЗжЮЛЪ§ЃК
norm.ppf(0.99)

norm.ppf(0.999)

norm.ppf(0.9999)

