етРявдЪЕМЪЯюФПCIFAR-10ЮЊР§ЃЌЗжБ№ЪЙгУЕЭНзЃЌжаНзЃЌИпНз API ДюНЈФЃаЭЁЃ
етРявдCIFAR-10ЮЊЪ§ОнМЏЃЌCIFAR-10ЮЊаЁаЭЪ§ОнМЏЃЌвЛЙВАќКЌ10ИіРрБ№ЕФ RGB ВЪЩЋЭМЯёЃКЗЩЛњЃЈairplaneЃЉЁЂЦћГЕЃЈautomobileЃЉЁЂФёРрЃЈbirdЃЉЁЂУЈЃЈcatЃЉЁЂТЙЃЈdeerЃЉЁЂЙЗЃЈdogЃЉЁЂЭмРрЃЈfrogЃЉЁЂТэЃЈhorseЃЉЁЂДЌЃЈshipЃЉКЭПЈГЕЃЈtruckЃЉЁЃЭМЯёЕФГпДчЮЊ 32ЁС32ЃЈЯёЫиЃЉЃЌ3ИіЭЈЕР ЃЌЪ§ОнМЏжавЛЙВга 50000 еХбЕСЗрєЦЌКЭ 10000 еХВтЪдЭМЯёЁЃCIFAR-10Ъ§ОнМЏга3ИіАцБОЃЌетРяЪЙгУPythonАцБОЁЃ
Ъ§ОнЕМШыКЭЪ§ОнПЩЪгЛЏ
етРяВЛгУЪщжаИјЕФCIFAR-10Ъ§ОнЃЌжБНгЪЙгУTensorFlowздДјЕФЭцвтЕМШыЪ§ОнЃЌПЩФмашвЊФЇЗЈЃЌЦфЪЕTensorFlowжаЕФЪ§ОнЬиБ№ЕФОЕфЁЃ

НгЯТРДЕМШыcifar10Ъ§ОнМЏВЂНјааПЩЪгЛЏеЙЪО
import matplotlib.pyplot as plt import tensorflow as tf (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() # x_train.shape, y_train.shape, x_test.shape, y_test.shape # ((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1)) index_name = { 0:'airplane', 1:'automobile', 2:'bird', 3:'cat', 4:'deer', 5:'dog', 6:'frog', 7:'horse', 8:'ship', 9:'truck' } def plot_100_img(imgs, labels): fig = plt.figure(figsize=(20,20)) for i in range(10): for j in range(10): plt.subplot(10,10,i*10+j+1) plt.imshow(imgs[i*10+j]) plt.title(index_name[labels[i*10+j][0]]) plt.axis('off') plt.show() plot_100_img(x_test[:100])

Ъ§ОнМЏжЦзївдМАдЄДІРэ
Ъ§ОнМЏдЄДІРэКмМђЕЅОЭФмЪЕЯжЃЌжБНгвЛааДњТыЁЃ
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # ЬсШЁГівЛааЪ§Он # train_data.take(1).get_single_element()
етРяНгзХЖдЪ§ОндЄДІРэВйзїЃЌвВКмШнвзОЭФмЪЕЯжЁЃ
def process_data(img, label): img = tf.cast(img, tf.float32) / 255.0 return img, label train_data = train_data.map(process_data) # ЬсШЁГівЛааЪ§Он # train_data.take(1).get_single_element()
етРяЖдЪ§ОнЛЙгавЛаЉДцДЂКЭЬсШЁВйзї
dataset жа shuffle()ЁЂrepeat()ЁЂbatch()ЁЂprefetch()ЕШКЏЪ§ЕФжївЊЙІФмШчЯТЁЃ
1ЃЉrepeat(count=None) БэЪОжиИДДЫЪ§ОнМЏ count ДЮЃЌЪЕМЪЩЯЃЌЮвУЧПДЕН repeat ЭљЭљЪЧНгдк shuffle КѓУцЕФЁЃЮЊКЮвЊетУДзіЃЌЖјВЛЪЧЗДЙ§РДЃЌЯШ repeat дй shuffle ФиЃП ШчЙћshuffle дк repeat жЎКѓЃЌepoch гы epoch жЎМфЕФБпНчОЭЛсФЃК§ЃЌГіЯжЮДБщРњЭъЪ§ОнЃЌвбОМЦЫуЙ§ЕФЪ§ОнгжГіЯжЕФЧщПіЁЃ
2ЃЉshuffle(buffer_size, seed=None, reshuffle_each_iteration=None) БэЪОНЋЪ§ОнДђТвЃЌЪ§жЕдНДѓЃЌЛьТвГЬЖШдНДѓЁЃЮЊСЫЭъШЋДђТвЃЌbuffer_size гІЕШгкЪ§ОнМЏЕФЪ§СПЁЃ
3ЃЉbatch(batch_size, drop_remainder=False) БэЪОАДееЫГађШЁГі batch_size ДѓаЁЪ§ОнЃЌзюКѓвЛДЮЪфГіПЩФмаЁгкbatch ЃЌШчЙћГЬађжИЖЈСЫУПДЮБиаыЪфШыНјХњДЮЕФДѓаЁЃЌФЧУДгІНЋdrop_remainder ЩшжУЮЊ True вдЗРжЙВњЩњНЯаЁЕФХњДЮЃЌФЌШЯЮЊ FalseЁЃ
4ЃЉprefetch(buffer_size) БэЪОЪЙгУвЛИіКѓЬЈЯпГЬвдМАвЛИіbufferРДЛКДцbatchЃЌЬсЧАЮЊФЃаЭЕФжДааГЬађзМБИКУЪ§ОнЁЃвЛАуРДЫЕЃЌbufferЕФДѓаЁгІИУжСЩйКЭУПвЛВНбЕСЗЯћКФЕФbatchЪ§СПвЛжТЃЌвВОЭЪЧ GPU/TPU ЕФЪ§СПЁЃЮвУЧвВПЩвдЪЙгУAUTOTUNEРДЩшжУЁЃДДНЈвЛИіDatasetБуПЩДгИУЪ§ОнМЏжадЄЬсШЁдЊЫиЃЌзЂвтЃКexamples.prefetch(2) БэЪОНЋдЄШЁ2ИідЊЫиЃЈ2ИіЪОР§ЃЉЃЌЖјexamples.batch(20).prefetch(2) БэЪОНЋдЄШЁ2ИідЊЫиЃЈ2ИіХњДЮЃЌУПИіХњДЮга20ИіЪОР§ЃЉЃЌbuffer_size БэЪОдЄЬсШЁЪБНЋЛКГхЕФзюДѓдЊЫиЪ§ЗЕЛи DatasetЁЃ
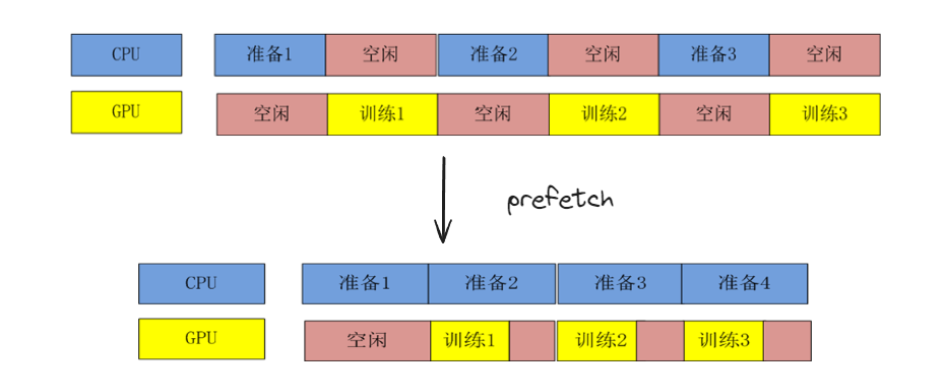
зюКѓЮвУЧЖдЪ§ОнНјаавЛаЉЛКДцВйзї
learning_rate = 0.0002 batch_size = 64 training_steps = 40000 display_step = 1000 AUTOTUNE = tf.data.experimental.AUTOTUNE train_data = train_data.map(process_data).shuffle(5000).repeat(training_steps).batch(batch_size).prefetch(buffer_size=AUTOTUNE)
ФПЧАЪ§ОнзМБИЭъБЯЃЁ
ФЃаЭНсЙЙ
ФЃаЭЕФНсЙЙШчЯТЃЌЯждкЪЙгУЕЭНзЃЌжаНзЃЌИпНз API РДЙЙНЈетвЛИіФЃаЭ

ЕЭНз API ЙЙНЈФЃаЭ
import matplotlib.pyplot as plt import tensorflow as tf ## ЖЈвхФЃаЭ class CustomModel(tf.Module): def __init__(self, name=None): super(CustomModel, self).__init__(name=name) self.w1 = tf.Variable(tf.initializers.RandomNormal()([32*32*3, 256])) self.b1 = tf.Variable(tf.initializers.RandomNormal()([256])) self.w2 = tf.Variable(tf.initializers.RandomNormal()([256, 128])) self.b2 = tf.Variable(tf.initializers.RandomNormal()([128])) self.w3 = tf.Variable(tf.initializers.RandomNormal()([128, 64])) self.b3 = tf.Variable(tf.initializers.RandomNormal()([64])) self.w4 = tf.Variable(tf.initializers.RandomNormal()([64, 10])) self.b4 = tf.Variable(tf.initializers.RandomNormal()([10])) def __call__(self, x): x = tf.cast(x, tf.float32) x = tf.reshape(x, [x.shape[0], -1]) x = tf.nn.relu(x @ self.w1 + self.b1) x = tf.nn.relu(x @ self.w2 + self.b2) x = tf.nn.relu(x @ self.w3 + self.b3) x = tf.nn.softmax(x @ self.w4 + self.b4) return x model = CustomModel() ## ЖЈвхЫ№ЪЇ def compute_loss(y, y_pred): y_pred = tf.clip_by_value(y_pred, 1e-9, 1.) loss = tf.keras.losses.sparse_categorical_crossentropy(y, y_pred) return tf.reduce_mean(loss) ## ЖЈвхгХЛЏЦї optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002) ## ЖЈвхзМШЗТЪ def compute_accuracy(y, y_pred): correct_pred = tf.equal(tf.argmax(y_pred, axis=1), tf.cast(tf.reshape(y, -1), tf.int64)) correct_pred = tf.cast(correct_pred, tf.float32) return tf.reduce_mean(correct_pred) ## ЖЈвхвЛДЮepoch def train_one_epoch(x, y): with tf.GradientTape() as tape: y_pred = model(x) loss = compute_loss(y, y_pred) accuracy = compute_accuracy(y, y_pred) grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) return loss.numpy(), accuracy.numpy() ## ПЊЪМбЕСЗ loss_list, acc_list = [], [] for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1): loss, acc = train_one_epoch(batch_x, batch_y) loss_list.append(loss) acc_list.append(acc) if i % 10 == 0: print(f'Ек{i}ДЮбЕСЗ->', 'loss:' ,loss, 'acc:', acc)
жаНз API ЙЙНЈФЃаЭ
## ЖЈвхФЃаЭ class CustomModel(tf.Module): def __init__(self): super(CustomModel, self).__init__() self.flatten = tf.keras.layers.Flatten() self.dense_1 = tf.keras.layers.Dense(256, activation='relu') self.dense_2 = tf.keras.layers.Dense(128, activation='relu') self.dense_3 = tf.keras.layers.Dense(64, activation='relu') self.dense_4 = tf.keras.layers.Dense(10, activation='softmax') def __call__(self, x): x = self.flatten(x) x = self.dense_1(x) x = self.dense_2(x) x = self.dense_3(x) x = self.dense_4(x) return x model = CustomModel() ## ЖЈвхЫ№ЪЇвдМАзМШЗТЪ compute_loss = tf.keras.losses.SparseCategoricalCrossentropy() train_loss = tf.keras.metrics.Mean() train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() ## ЖЈвхгХЛЏЦї optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002) ## ЖЈвхвЛДЮepoch def train_one_epoch(x, y): with tf.GradientTape() as tape: y_pred = model(x) loss = compute_loss(y, y_pred) grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) train_loss(loss) train_accuracy(y, y_pred) ## ПЊЪМбЕСЗ loss_list, accuracy_list = [], [] for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1): train_one_epoch(batch_x, batch_y) loss_list.append(train_loss.result()) accuracy_list.append(train_accuracy.result()) if i % 10 == 0: print(f"Ек{i}ДЮбЕСЗЃК loss: {train_loss.result()} accuarcy: {train_accuracy.result()}")
ИпНз API ЙЙНЈФЃаЭ
## ЖЈвхФЃаЭ model = tf.keras.Sequential([ tf.keras.layers.Input(shape=[32,32,3]), tf.keras.layers.Flatten(), tf.keras.layers.Dense(256, activation='relu'), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(10, activation='softmax'), ]) ## ЖЈвхoptimizerЃЌloss, accuracy model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.0002), loss = tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'] ) ## ПЊЪМбЕСЗ model.fit(train_data.take(10000))
БЃДцКЭЕМШыФЃаЭ
БЃДцФЃаЭ
tf.keras.models.save_model(model, 'model_folder')
ЕМШыФЃаЭ
model = tf.keras.models.load_model('model_folder')

