етДЮЃЌЮвУЧНЋЪЙгУk-ShapeЪБМфађСаОлРрЗНЗЈМьВщЙЋЫОЕФЙЩЦБЪевцТЪЕФЪБМфађСаЁЃ
ЦѓвЕЖдЦѓвЕНЛвзКЭЙЩЦБМлИё
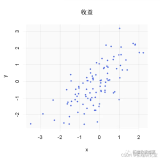
дкБОбаОПжаЃЌЮвУЧНЋбаОПОпгаНЛвзЙиЯЕЕФЙЋЫОЕФМлИёБфЛЏТЪЕФЪБМфађСаЕФЯрЫЦадЃЌЖјВЛЪЧЭјТчНсЙЙЕФЗжЮіЁЃ
гЩгкЬиЖЈПЭЛЇЕФЯњЪлЖюгыЙЉгІЩЬЙЋЫОЕФЯњЪлЖюжЎБШНЯДѓЃЌЕБПЭЛЇЙЋЫОЕФЙЩЦБМлИёЗЂЩњБфЛЏЪБЃЌЖдЙЉгІЩЬЙЋЫОЙЩЦБМлИёЕФЗДгІБЛШЯЮЊИќДѓЁЃ
k-Shape
k-Shape [PaparrizosКЭGravanoЃЌ2015]ЪЧвЛжжЙизЂЪБМфађСааЮзДЕФЪБМфађСаОлРрЗНЗЈЁЃдкЮвУЧНјШыk-ShapeжЎЧАЃЌШУЮвУЧЬИЬИЪБМфађСаЕФВЛБфадКЭГЃгУЪБМфађСажЎМфЕФОрРыЁЃ
ЪБМфађСаОрРыВтЖШ
ХЗМИРяЕТОрРыЃЈEDЃЉКЭЖЏЬЌЪБМфХЄЧњЃЈDTWЃЉЭЈГЃгУзїОрРыВтСПжЕЃЌгУгкЪБМфађСажЎМфЕФБШНЯЁЃ
DTWЪЧEDЕФРЉеЙЃЌдЪаэОжВПКЭЗЧЯпадЖдЦыЁЃ
k-ShapeЬсГіГЦЮЊЛљгкаЮзДЕФОрРыЃЈSBDЃЉЕФОрРыЁЃ
k-ShapeЫуЗЈ
k-ShapeОлРрВржигкЫѕЗХКЭвЦЮЛЕФВЛБфадЁЃk-ShapeгаСНИіжївЊЬиеїЃКЛљгкаЮзДЕФОрРыЃЈSBDЃЉКЭЪБМфађСааЮзДЬсШЁЁЃ
SBD
ЛЅЯрЙиЪЧдкаХКХДІРэСьгђжаОГЃЪЙгУЕФЖШСПЁЃЪЙгУFFTЃЈ+ІСЃЉДњЬцDFTРДЬсИпМЦЫуаЇТЪЁЃ
ЙщвЛЛЏЛЅЯрЙиЃЈЯЕЪ§ЙщвЛЛЏЃЉNCCcЪЧЛЅЯрЙиЯЕСаГ§вдЕЅИіЯЕСаздЯрЙиЕФМИКЮЦНОљжЕЁЃМьВтNCCcзюДѓЕФЮЛжУІиЁЃ
SBDШЁ0ЕН2жЎМфЕФжЕЃЌСНИіЪБМфађСадННгНќ0ОЭдНЯрЫЦЁЃ

аЮзДЬсШЁ
ЭЈЙ§SBDевЕНЪБМфађСаОлРрЕФжЪаФЯђСП гаЙиЯъЯИЕФБэЪОЗЈЃЌЧыВЮдФЮФеТЁЃ

k-ShapeЕФећИіЫуЗЈШчЯТЁЃ

k-ShapeЭЈЙ§Яёk-meansетбљЕФЕќДњЙ§ГЬЮЊУПИіЪБМфађСаЗжХфДиЁЃ
- НЋУПИіЪБМфађСагыУПИіОлРрЕФжЪаФЯђСПНјааБШНЯЃЌВЂНЋЦфЗжХфИјзюНќЕФжЪаФЯђСПЕФОлРр
- ИќаТШКМЏжЪаФЯђСП
жиИДЩЯЪіВНжш1КЭ2ЃЌжБЕНМЏШКГЩдБжаУЛгаЗЂЩњИќИФЛђЕќДњДЮЪ§ДяЕНзюДѓжЕЁЃ
R гябдk-Shape
> start <- "2014-01-01" > df_7974 %>% + filter(date > as.Date(start)) # A tibble: 1,222 x 10 date open high low close volume close_adj change rate_of_change code 1 2014-01-06 14000 14330 13920 14320 1013000 14320 310 0.0221 7974 2 2014-01-07 14200 14380 14060 14310 887900 14310 -10 -0.000698 7974 3 2014-01-08 14380 16050 14380 15850 3030500 15850 1540 0.108 7974 4 2014-01-09 15520 15530 15140 15420 1817400 15420 -430 -0.0271 7974 5 2014-01-10 15310 16150 15230 16080 2124100 16080 660 0.0428 7974 6 2014-01-14 15410 15755 15370 15500 1462200 15500 -580 -0.0361 7974 7 2014-01-15 15750 15880 15265 15360 1186800 15360 -140 -0.00903 7974 8 2014-01-16 15165 15410 14940 15060 1606600 15060 -300 -0.0195 7974 9 2014-01-17 15100 15270 14575 14645 1612600 14645 -415 -0.0276 7974 10 2014-01-20 11945 13800 11935 13745 10731500 13745 -9
ШБЪЇЖШСПгыЧАвЛИіЙЄзїШеЕФжЕЯрЛЅВЙГфЁЃЃЈK-ShapeдЪаэвЛаЉЦЋВюЃЌЕЋвдЗРЭђвЛЃЉ
УПжжЙЩЦБЕФЙЩЦБМлИёКЭЙЩЦБМлИёБфЛЏТЪЁЃ

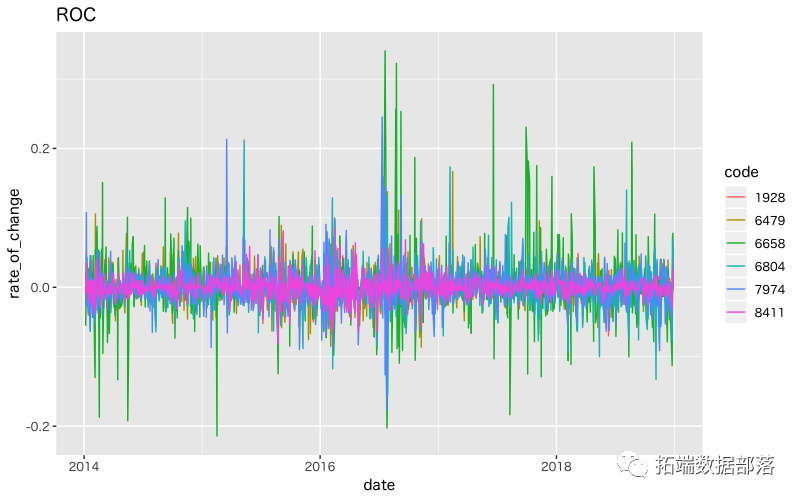
ОлРрНсЙћШчЯТЁЃ
> df_res %>% + arrange(cluster) cluster centroid_dist code 1 1 0.1897561 1928 2 1 0.2196533 6479 3 1 0.1481051 8411 4 2 0.3468301 6658 5 2 0.2158674 6804 6 2 0.2372485 7974
NintendoЃЌHosidenКЭSiray Electronics IndustriesБЛЗжХфЕНЭЌвЛИіМЏШКЁЃHosidenдк2016ФъЖдШЮЬьЬУЕФЯњЪлБШР§ЮЊ50.5ЃЅЃЌетБэУїЙЋЫОжЎМфЕФвЕЮёЙиЯЕвВЛсгАЯьЙЩМлЕФБфЖЏЁЃ
СэвЛЗНУцЃЌMinebeaMitsumiГЩЮЊСэвЛИіМЏШКЃЌЕЋЪЧдк2017ФъMitsumiгы2017ФъЕФMinebeaКЯВЂЃЌ УЛгаЖдгІ2016Фъ7дТPockemon GoЗЂВМЪБЙЩМльЩ§ЕФгАЯь ЁЃ