БОЫЕУїНщЩмСЫОпгаStudent-tИФНјЕФGARCHЃЈ1,1ЃЉФЃаЭЕФБДвЖЫЙЙРМЦЗНЗЈЁЃ
НщЩм
еЊвЊ
БОЫЕУїНщЩмЪЙгУStudent-tИФНјЕФGARCHЃЈ1,1ЃЉФЃаЭЖдЛуТЪЖдЪ§ЪевцНјааБДвЖЫЙЙРМЦЁЃ
здEngleЃЈ1982ЃЉЕФПЊДДадТлЮФвдРДЃЌЪЙгУЪБМфађСаФЃаЭИФБфВЈЖЏТЪЕФбаОПвЛжБКмЛюдОЁЃARCHЃЈздЛиЙщЬѕМўвьЗНВюЃЉКЭGARCHЃЈЙувхARCHЃЉРраЭФЃаЭбИЫйЗЂеЙГЩЮЊ80ФъДњдЄВтВЈЖЏТЪЕФОбщФЃаЭЕФЗсИЛМвзхЁЃетаЉФЃаЭЪЧН№ШкМЦСПОМУбЇЕФЙуЗКДЋВЅКЭБиВЛПЩЩйЕФЙЄОпЁЃдкBollerslevЃЈ1986ЃЉв§ШыЕФGARCHЃЈpЃЌqЃЉФЃаЭжаЃЌЃЈН№ШкзЪВњЛђН№ШкжИЪ§ЃЉЖдЪ§ЪевцytдкЪБМфtЕФЬѕМўЗНВюМйЩшгУhtБэЪОЃЌЫќЪЧЙ§ШЅqИіЖдЪ§ЗЕЛиКЭЙ§ШЅpИіЬѕМўЗНВюЕФЦНЗНЕФЯпадКЏЪ§ЁЃИќШЗЧаЕиЫЕЃК
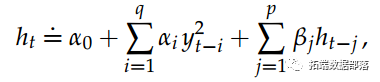
ДјгаStudent-tИФНјЕФGARCHЃЈ1,1ЃЉФЃаЭЛљгкNakatsumaЃЈ1998ЃЉЕФЙЄзїЃЌгЩMetropolis-HastingsЃЈMHЃЉЫуЗЈзщГЩЃЌЦфжаЗжВМЪЧИљОнЦНЗНЙлВтжЕгЩИЈжњARMAЙ§ГЬЙЙНЈЕФЁЃетжжЗНЗЈБмУтСЫбЁдёКЭЕїећВЩбљЫуЗЈЕФКФЪБЧвРЇФбЕФШЮЮёЃЌЬиБ№ЪЧЖдгкЗЧзЈМвЖјбдЁЃИУГЬађгУRБраДЃЌДјгавЛаЉгУCЪЕЯжЕФзгР§ГЬЃЌвдМгПьЗТецЙ§ГЬЁЃИУЫуЗЈЕФгааЇадвдМАМЦЫуЛњДњТыЕФе§ШЗадвбЭЈЙ§GewekeЃЈ2004ЃЉЕФЗНЗЈНјааСЫбщжЄЁЃ
ФЃаЭЃЌЯШбщКЭMCMCЗНАИ
ПЩвдЭЈЙ§Ъ§ОнРЉГфБраДОпгаStudent-tИФНјЕФGARCHЃЈ1,1ЃЉФЃаЭЃЌгУгкЖдЪ§ЪевцТЪfytgЁЃ

ЮвУЧЧПЕївдЯТЪТЪЕЃКдкMHЫуЗЈжаНіЪЕЯже§дМЪјЁЃдкЗТецЙ§ГЬжаУЛгаЪЉМгЦНЮШадЬѕМўЁЃ
ЮЊСЫБраДЫЦШЛКЏЪ§ЃЌЮвУЧЖЈвхЯђСПy =ЃЈy1ЃЌ...ЃЌyTЃЉ0ЃЌv =ЃЈv1ЃЌ...ЃЌvTЃЉ0КЭa =ЃЈ.a0ЃЌa1ЃЉЁЃЮвУЧНЋФЃаЭВЮЪ§жиаТзщКЯЮЊЯђСПy =ЃЈ.aЃЌbЃЌnЃЉЁЃШЛКѓЃЌдкЖЈвхTЁСTЖдНЧОиеѓЪБ

ЮвУЧПЩвдНЋЃЈyЃЌvЃЉБэЪОЮЊ

БДвЖЫЙЗНЗЈНЋЃЈyЃЌvЃЉЪгЮЊЫцЛњБфСПЃЌЦфЬиеїдкгквдpЃЈyЃЌvЃЉБэЪОЕФЯШбщУмЖШЁЃЯШбщЪЧдкГЦЮЊГЌВЮЪ§ЕФВЮЪ§ЕФАяжњЯТжИЖЈЕФЃЌетаЉВЮЪ§зюГѕМйЖЈЮЊвбжЊЧвКуЖЈЁЃЖјЧвЃЌИљОнбаОПШЫдБЕФЯШбщаХЯЂЃЌетжжУмЖШПЩФмЛђЖрЛђЩйЕиЬсЙЉаХЯЂЁЃШЛКѓЃЌЭЈЙ§НЋФЃаЭВЮЪ§ЕФЫЦШЛКЏЪ§гыЯШбщУмЖШёюКЯЃЌЮвУЧПЩвдЪЙгУБДвЖЫЙЙцдђЖдИХТЪУмЖШНјааБфЛЛЃЌвдЕУГіКѓбщУмЖШpЃЈyЃЌvjyЃЉЃЌШчЯТЫљЪОЃК

ИУКѓбщЪЧЙлВьЪ§ОнКѓЙигкФЃаЭВЮЪ§ЕФжЊЪЖЕФЖЈСПИХТЪУшЪіЁЃ
ЮвУЧдкGARCHВЮЪ§aКЭbЩЯЪЙгУСЫНиОрЕФЦеЭЈЯШбщ

Цфжаm?КЭS?ЪЧГЌВЮЪ§ЃЌ1fЁЄgЪЧжИБъКЏЪ§ЃЌfNdЪЧdЮЌЗЈЯђУмЖШЁЃПЩвдЗЂЯжвдnЮЊЬѕМўЕФЯђСПvЕФЯШбщЗжВМЃЌДгЖјЕУГі

дкбЁдёздгЩЖШВЮЪ§ЕФЯШбщЗжВМЪБЃЌЮвУЧзёбDeschampsЃЈ2006ЃЉЕФЗНЗЈЁЃЗжВМЪЧВЮЪ§l> 0ЧвdЁн2ЕФЦНвЦжИЪ§

ЖдгкНЯДѓЕФlжЕЃЌЯШбщжЪСПМЏжадкdИННќЃЌВЂЧвПЩвдЭЈЙ§етжжЗНЪНЖдздгЩЖШЪЉМгдМЪјЁЃ
ЪЕЯжЕФMCMCВЩбљЛљгкArdiaЃЈ2008ЃЉЕФЗНЗЈЃЌИУЗНЗЈЕФСщИаРДздNakatsumaЃЈ1998ЃЉЕФЯШЧАЙЄзїЁЃИУЫуЗЈгЩMHЫуЗЈзщГЩЃЌЦфжаGARCHВЮЪ§АДПщИќаТЃЈaЖдгІвЛИіПщЃЌbЖдгІвЛИіПщЃЉЃЌЖјздгЩЖШВЮЪ§ЪЧЪЙгУгХЛЏЕФОмОјММЪѕДгзЊЛЛКѓЕФжИЪ§дДУмЖШжаВЩбљЕФЁЃИУЗНЗЈОпгаШЋздЖЏЕФгХЕуЁЃ
ЪЕР§ЗжЮі
ЮвУЧНЋБДвЖЫЙЙРМЦЗНЗЈгІгУгкЃЈDEM / GBPЃЉЭтЛуЖдЪ§ЪевцТЪЕФУПШеЙлВьжЕЁЃбљБОЪБМфЮЊ1985Фъ1дТ3ШежС1991Фъ12дТ31ШеЃЌЙВ1974ИіЙлВтжЕЁЃДЫЪ§ОнМЏвбБЛЭЦЙуЮЊGARCHЪБМфађСаШэМўбщжЄЕФЗЧе§ЪНЛљзМЁЃДгетИіЪБМфађСажаЃЌЧА750ИіЙлВтжЕгУгкЫЕУїБДвЖЫЙЗНЗЈЁЃЮвУЧЕФЪ§ОнМЏжаЕФЙлВьДАПкеЊТМЛцжЦдкЭМ1жаЁЃ

ЮвУЧЖдДјгаStudent-tЕФGARCHЃЈ1,1ЃЉФЃаЭНјааСЫИФНјЃЌвдФтКЯДЫЙлВьДАЕФЪ§Он
function (y, mu.alpha = c(0, 0), Sigma.alpha = 1000 * diag(1,2), mu.beta = 0, Sigma.beta = 1000, lambda = 0.01, delta = 2, control = list())
КЏЪ§ЕФЪфШыздБфСПЪЧЪ§ОнЯђСПЃЌГЌВЮЪ§ЃЌР§ШчЃК
? вЊЩњГЩЕФMCMCСДЪ§ЃЛФЌШЯжЕ1ЁЃ
? УПИіMCMCСДЕФГЄЖШЃЛ?start.valЃКСДЕФЦ№ЪМжЕЕФЯђСПЃЛФЌШЯжЕЮЊ10000 ЁЃ
зїЮЊБДвЖЫЙЙРМЦЕФЯШбщЗжВМЁЃЭЈЙ§ЩшжУПижЦВЮЪ§жЕn.chain = 2КЭl.chain = 5000ЃЌЮвУЧЮЊ5000ДЮДЋЕнЩњГЩСЫСНЬѕСДЁЃ
> MCMC <- bayg(y, control = list( l.chain = 5000, n.chain = 2)) chain: 1 iteration: 10 parameters: 0.0441 0.212 0.656 115 chain: 1 iteration: 20 parameters: 0.0346 0.136 0.747 136 ... chain: 2 iteration: 5000 parameters: 0.0288 0.190 0.754 4.67
ЩњГЩMCMCСДЕФИњзйЭМЃЈМДЃЌЕќДњгыВЩбљжЕЕФЭМЃЉЁЃВЩбљЦїЕФЪеСВЃЈЪЙгУGelmanКЭRubinЃЈ1992ЃЉЕФеяЖЯВтЪдЃЉЃЌСДжаЕФНгЪмТЪКЭздЯрЙиПЩвдШчЯТМЦЫуЃК
diag Point est. 97.5% quantile alpha0 1.02 1.07 alpha1 1.01 1.05 beta 1.02 1.07 nu 1.02 1.06 Multivariate psrf 1.02 > 1 - rejectionRate alpha0 alpha1 beta nu 0.890 0.890 0.953 1.000 > autocorr.diag alpha0 alpha1 beta nu Lag 0 1.000 1.000 1.000 1.000 Lag 1 0.914 0.872 0.975 0.984 Lag 5 0.786 0.719 0.901 0.925 Lag 10 0.708 0.644 0.816 0.863 Lag 50 0.304 0.299 0.333 0.558
ЪеСВеяЖЯУЛгаЯдЪОзюКѓ2500ДЮЕќДњЕФЪеСВжЄОнЁЃMCMCВЩбљЫуЗЈЕФНгЪмТЪЗЧГЃИпЃЌДгЯђСПaЕФ89ЃЅЕНbЕФ95ЃЅВЛЕШЃЌетБэУїЗжВМНгНќгкШЋВПЬѕМўЁЃЮвУЧЖЊЦњСЫДгMCMCЕФећЬхЪфГіжаГщбљЧА2500ДЮзїЮЊдЄЩеЦкЃЌНіБЃСєЕкЖўДЮГщбљвдМѕЩйздЯрЙиЃЌ


> smpl n.chain : 2 l.chain : 5000 l.bi : 2500 batch.size: 2 smpl size : 2500
ЛљБОЕФКѓбщЭГМЦЃК
Iterations = 1:2500 Thinning interval = 1 Number of chains = 1 Sample size per chain = 2500 1. Empirical mean and standard deviation for each variable, plus standard error of the mean: Mean SD Naive SE Time-series SE alpha0 0.0345 0.0138 0.000277 0.00173 alpha1 0.2360 0.0647 0.001293 0.00760 beta 0.6832 0.0835 0.001671 0.01156 nu 6.4019 1.5166 0.030333 0.19833
УПИіБфСПЕФЗжЮЛЪ§ЃК
2.5% 25% 50% 75% 97.5% alpha0 0.0126 0.024 0.0328 0.0435 0.0646 alpha1 0.1257 0.189 0.2306 0.2764 0.3826 beta 0.5203 0.624 0.6866 0.7459 0.8343 nu 4.2403 5.297 6.1014 7.2282 10.1204
ЭЈЙ§ЪзЯШНЋЪфГізЊЛЛЮЊОиеѓЃЌШЛКѓЪЙгУКЏЪ§histЃЌПЩвдЛёШЁФЃаЭВЮЪ§ЕФБпМЪЗжВМЁЃ
БпдЕКѓВПУмЖШЯдЪОдкЭМ3жаЁЃЮвУЧЧхГўЕизЂвтЕНжБЗНЭМЕФВЛЖдГЦаЮзДЁЃЖдгкВЮЪ§nгШЦфШчДЫЁЃКѓЦНОљжЕКЭжаЮЛЪ§жЎМфЕФВювьвВЗДгГСЫетвЛЕуЁЃетаЉНсЙћгІИУОЏИцЮвУЧЃЌВЛвЊРФгУНЅНќТлжЄЁЃдкЕБЧАЧщПіЯТЃЌМДЪЙЪЧ750ДЮЙлВтвВВЛзувджЄУїВЮЪ§ЙРМЦСПЗжВМЕФНЅНќЖдГЦе§ЬЌНќЫЦЁЃ
ПЩвдЭЈЙ§ДгСЊКЯКѓбщбљБОжаНјааЗТецРДжБНгЛёЕУЙигкФЃаЭВЮЪ§ЕФЗЧЯпадКЏЪ§ЕФИХТЪГТЪіЁЃ
ЬиБ№ЪЧЃЌЮвУЧПЩвдВтЪдаЗНВюЦНЮШадЬѕМўЃЌВЂдкТњзуИУЬѕМўЪБЙРМЦЮоЬѕМўЗНВюЕФУмЖШЁЃИљОнGARCHЃЈ1,1ЃЉЙцЗЖЃЌШчЙћa1 + b <1ЃЌдђЙ§ГЬЪЧаЗНВюЦНЮШЕФЁЃжЕНгНќ1ЪБЃЌЙ§ШЅЕФГхЛїКЭЙ§ШЅЕФЗНВюНЋЖдЮДРДЕФЬѕМўЗНВюВњЩњИќГЄЕФгАЯьЁЃ
ЮЊСЫЭЦЖЯЦНЗНЙ§ГЬЕФГжОУадЃЌЮвУЧНіЪЙгУКѓбщбљБОЃЌВЂЮЊКѓбщбљБОжаЕФУПИіЛцжЦy [j]ЩњГЩЃЈa1 [j] + b [j]ЃЉЁЃГжОУадЕФКѓВПУмЖШЛцжЦдкЭМ4жаЁЃжБЗНЭМЯђзѓЧуаБЃЌжажЕЮЊ0.923ЃЌзюДѓжЕЮЊ1.050ЁЃМйЩшa1 + b <1ЃЌдђGARCHЃЈ1,1ЃЉФЃаЭЕФЮоЬѕМўЗНВюЮЊa0 /ЃЈ1- a1- bЃЉЁЃЬѕМўЪЧДцдкЪБЃЌКѓбщОљжЕЮЊ0.387ЃЌ90ЃЅПЩаХЧјМфЮЊ[0.274,1.378 ]ЁЃОбщЗНВюЮЊ0.323ЁЃ
ЪЙгУСЊКЯКѓбщбљБОПЩвдЛёЕУЙигкФЃаЭВЮЪ§ЕФЦфЫћИХТЪГТЪіЁЃЪЙгУКѓбщбљБОЃЌЮвУЧЙРМЦЬѕМўЗхЖШДцдкЕФКѓбщИХТЪЮЊ0.994ЁЃдкДцдкЬѕМўЯТЃЌЗхЖШЕФКѓОљжЕЮЊ8.21ЃЌжаЮЛЪ§ЮЊ5.84ЃЌЖдЧјМфЕФ95ЃЅжУаХЖШЮЊ[4.12,15.81]ЃЌБэУїЮВВПБШе§ЬЌЗжВМИќжиЁЃЬѕМўЗхЖШЕФКѓбще§ЦЋЪЧгЩМИИіЗЧГЃДѓЕФжЕЃЈзюДѓФЃФтжЕЮЊ404.90ЃЉв§Ц№ЕФЁЃ

ЯШЧАЕФЯожЦКЭГЃЙцИФНј
ПижЦВЮЪ§addPriorConditionsПЩгУгкдкЙРМЦЦкМфЖдФЃаЭВЮЪ§yЪЉМгШЮКЮРраЭЕФдМЪјЁЃР§ШчЃЌЮЊСЫШЗБЃЙРМЦаЗНВюЦНЮШGARCHЃЈ1,1ЃЉФЃаЭЃЌгІНЋКЏЪ§ЖЈвхЮЊ
p<-function(psi) + psi[2] + psi[3] < 1
ЪЕгУНЈвщ
ИУЫуЗЈжаЪЕЪЉЕФЙРЫуВпТдЪЧШЋздЖЏЕФЃЌВЛашвЊЖдMCMCВЩбљЦїНјааШЮКЮЕїећЁЃЖдгкДгвЕепРДЫЕЃЌетЮовЩЪЧвЛИіЮќв§ШЫЕФЙІФмЁЃЕЋЪЧЃЌТэЖћПЩЗђСДЕФЩњГЩЗЧГЃКФЪБЃЌвђДЫУПЬьдкЖрИіЪ§ОнМЏЩЯЙРЫуФЃаЭПЩФмЛсЛЈЗбДѓСПЪБМфЁЃдкетжжЧщПіЯТЃЌЭЈЙ§дкЖрИіДІРэЦїЩЯдЫааЕЅСДПЩвдЧсЫЩЕиЪЙЫуЗЈВЂааЛЏЁЃР§ШчЃЌПЩвдЪЙгУforeachАќЧсЫЩЪЕЯжДЫФПБъЃЈRevolution ComputingЃЌ2010ЃЉЁЃЭЌбљЃЌЕБЙРМЦжЕдкИќаТЕФЪБМфађСаЃЈМДОпгазюНќЙлВтжЕЕФЪБМфађСаЃЉЩЯжиИДЪБЃЌУїжЧЕФзіЗЈЪЧЪЙгУдкЧАвЛИіЙРМЦВНжшЛёЕУЕФВЮЪ§ЕФКѓбщОљжЕЛђжажЕРДЦєЖЏЫуЗЈЁЃГѕЪМжЕЃЈдЄЩеНзЖЮЃЉЕФгАЯьПЩФмНЯаЁЃЌвђДЫЪеСВЫйЖШИќПьЁЃзюКѓЃЌЧызЂвтЃЌгыШЮКЮMHЫуЗЈвЛбљЃЌВЩбљЦїПЩФмЛсПЈдкИјЖЈЕФжЕЩЯЃЌвђДЫСДВЛдйвЦЖЏЁЃ


змНс
БОЫЕУїНщЩмСЫStudent-tИФНјЖдGARCHЃЈ1,1ЃЉФЃаЭЕФБДвЖЫЙЙРМЦЁЃЮвУЧОйР§ЫЕУїСЫдкЛуТЪЖдЪ§ЪевцТЪЩЯЕФЪЕжЄгІгУЁЃ


