fast.ai ЛњЦїбЇЯАБЪМЧЃЈЫФЃЉЃЈ1ЃЉ/article/1482643
ЛљЯпКЭЖўдЊзщЃКМђЕЅЁЂСМКУЕФЧщИаКЭжїЬтЗжРр
етжжММЪѕзюГѕЪЧдк 2012 ФъЬсГіЕФЁЃChris Manning ЪЧЫЙЬЙИЃДѓбЇГіЩЋЕФздШЛгябдДІРэбаОПШЫдБЃЌЖј Sida Wang ЮвВЛШЯЪЖЃЌЕЋЮвШЯЮЊЫћКмАєЃЌвђЮЊЫћЕФТлЮФКмАєЁЃЫћУЧЛљБОЩЯЬсГіСЫетИіЯыЗЈЁЃЫћУЧЫљзіЕФЪЧНЋЦфгыЦфЫћЗНЗЈдкЦфЫћЪ§ОнМЏЩЯНјааБШНЯЁЃЦфжавЛМўЪТЪЧЫћУЧГЂЪдСЫ IMDB Ъ§ОнМЏЁЃетРяЪЧДѓЖўдЊзщЩЯЕФЦгЫиБДвЖЫЙ SVMЃК
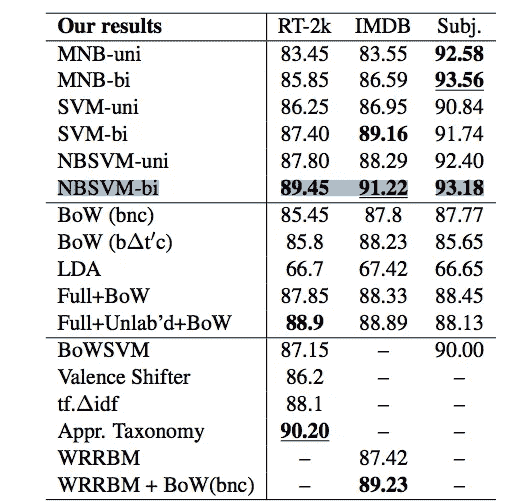
е§ШчФуЫљПДЕНЕФЃЌетжжЗНЗЈЪЄЙ§СЫЫћУЧбаОПЕФЦфЫћЛљгкЯпадЕФЗНЗЈЃЌвдМАЫћУЧбаОПЕФвЛаЉЪмЯоВЃЖћзШТќЛњЕФЩёОЭјТчЗНЗЈЁЃШчНёЃЌгаИќКУЕФЗНЗЈРДзіетИіЃЌЪТЪЕЩЯдкЩюЖШбЇЯАПЮГЬжаЃЌЮвУЧеЙЪОСЫЮвУЧдк Fast AI ИеИеПЊЗЂЕФзюаТГЩЙћЃЌПЩвдДяЕН 94%вдЩЯЕФзМШЗТЪЁЃЕЋЪЧЬиБ№ЪЧЖдгквЛжжМђЕЅЁЂПьЫйЁЂжБЙлЕФЯпадММЪѕРДЫЕЃЌетЛЙЪЧЯрЕБВЛДэЕФЁЃФуЛсзЂвтЕНЃЌЕБЫћУЧетбљзіЪБЃЌЫћУЧжЛЪЙгУСЫЖўдЊзщЁЃЮвВТетЪЧвђЮЊЮвПДСЫЫћУЧЕФДњТыЃЌЗЂЯжЫќЯрЕБТ§ЧвФбПДЁЃЮвевЕНСЫвЛжжИќгХЛЏЕФЗНЗЈЃЌе§ШчФуЫљПДЕНЕФЃЌЫљвдЮвУЧФмЙЛЪЙгУШ§дЊзщЃЌвђДЫЮвУЧЕУЕНСЫИќКУЕФНсЙћЃЌЮвУЧЕФзМШЗТЪЪЧ 91.8%ЃЌЖјВЛЪЧ 91.2%ЃЌЕЋГ§ДЫжЎЭтЃЌЫќЪЧЯрЭЌЕФЁЃХЖЃЌЫћУЧЛЙЪЙгУСЫжЇГжЯђСПЛњЃЌдкетжжЧщПіЯТМИКѕгыТпМЛиЙщЯрЭЌЃЌЫљвдгавЛаЉЯИЮЂЕФВювьЁЃЫљвдЮвШЯЮЊетЪЧвЛИіЯрЕБПсЕФНсЙћЁЃ
ЮввЊЬсвЛЯТЃЌдкПЮЬУЩЯФуПДЕНЕФЪЧЮвОЙ§ЖржмЩѕжСЖрИідТЕФбаОПЕУГіЕФНсЙћЁЃЫљвдЮвВЛЯЃЭћФуШЯЮЊетаЉЖЋЮїЪЧЯдЖјвзМћЕФЁЃЭъШЋВЛЪЧЁЃОЭЯёдФЖСетЦЊТлЮФЃЌТлЮФжаУЛгаУшЪіЮЊЪВУДЫћУЧЪЙгУетИіФЃаЭЃЌЫќгыЦфЫћФЃаЭгаКЮВЛЭЌЃЌЮЊЪВУДЫћУЧШЯЮЊЫќгааЇЁЃЮвЛЈСЫвЛСНжмЕФЪБМфВХвтЪЖЕНЫќдкЪ§бЇЩЯЕШЭЌгкЦеЭЈЕФТпМЛиЙщЃЌШЛКѓгжЛЈСЫМИжмЕФЪБМфВХвтЪЖЕНЧјБ№ЪЕМЪЩЯдкгке§дђЛЏЁЃетгаЕуЯёЛњЦїбЇЯАЃЌЮвЯраХФуДгФуВЮМгЕФ Kaggle ОКШќжавбОзЂвтЕНСЫЁЃОЭЯёФуЬсГіСЫвЛЧЇИіКУжївтЃЌЦфжа 999 ИіЮоТлФугаЖрУДздаХЫќУЧЛсКмАєЃЌзюжеЖМЛсБфГЩРЌЛјЁЃШЛКѓзюжедкЫФжмКѓЃЌЦфжавЛИіжегкзраЇЃЌИјСЫФуМЬајЖШЙ§СэЭтЫФжмЕФЭДПрКЭДьелЕФШШЧщЁЃетЪЧе§ГЃЕФЁЃЖјЧвЮвПЩвдШЗЖЈЃЌЮвЫљШЯЪЖЕФЛњЦїбЇЯАСьгђзюгХауЕФДгвЕепЖМгавЛИіЙВЭЌЕФЬиЕуЃЌФЧОЭЪЧЫћУЧЗЧГЃЭчЧПЃЌвВБЛГЦЮЊЙЬжДКЭжДзХЃЌетОјЖдЪЧЮвЫЦКѕгЕгаЕФЩљгўЃЌПЩФмЪЧЙЋЦНЕФЃЌЛЙгаСэвЛЕуЃЌЫћУЧЖМЪЧЗЧГЃЩУГЄБрТыЕФЁЃЫћУЧЗЧГЃЩУГЄНЋЫћУЧЕФЯыЗЈзЊЛЏЮЊаТЕФДњТыЁЃЖдЮвРДЫЕЃЌМИИідТЧАЭЈЙ§етИіЙЄзїЪЧвЛИіЗЧГЃгаШЄЕФОРњЃЌЪдЭМжСЩйХЊЧхГўЮЊЪВУДетИіЕБЪБЕФзюаТГЩЙћДцдкЁЃ
ИќКУЕФАцБОЃКNBSVM++ [43:31]
ЫљвдвЛЕЉЮвХЊЧхГўСЫЃЌЮвЪЕМЪЩЯФмЙЛдкДЫЛљДЁЩЯНјааИФНјЃЌВЂЧвЮвЛсЯђФуеЙЪОЮвзіСЫЪВУДЁЃетОЭЪЧЮвЗЧГЃавдЫФмЙЛЪЙгУ PyTorch ЕФдвђЃЌвђЮЊЮвФмЙЛДДНЈГіЮвЯывЊЕФЖЈжЦЛЏФкШнЃЌВЂЧвЭЈЙ§ЪЙгУ GPU вВЗЧГЃПьЫйЁЃетОЭЪЧ Fast AI АцБОЕФ NBSVMЁЃЪЕМЪЩЯЃЌЮвЕФХѓгб Stephen Merity ЪЧвЛЮЛдкздШЛгябдДІРэСьгђГіЩЋЕФбаОПШЫдБЃЌЫћНЋЦфУќУћЮЊ NBSVM++ЃЌЮвОѕЕУетКмПЩАЎЃЌЫљвдетОЭЪЧЃЌОЁЙмУЛга SVMЃЌЕЋЪЧЫќЪЧвЛИіТпМЛиЙщЃЌЕЋе§ШчЮвЫљЫЕЃЌМИКѕЭъШЋЯрЭЌЁЃ
ЫљвдЪзЯШШУЮвЯђФуеЙЪОДњТыЁЃвЛЕЉЮвХЊЧхГўетЪЧЮвФмЯыЕНЕФзюКУЕФЯпадДЪДќФЃаЭЕФЗНЗЈЃЌЮвНЋЦфЧЖШыЕН Fast AI жаЃЌетбљФужЛашаДМИааДњТыОЭПЩвдСЫЁЃ
sl=2000 # Here is how we get a model from a bag of words md = TextClassifierData.from_bow( trn_term_doc, trn_y, val_term_doc, val_y, sl )
ЫљвдДњТыЛљБОЩЯЪЧЃЌКйЃЌЮвЯыЮЊЮФБОЗжРрДДНЈвЛИіЪ§ОнРрЃЌЮвЯыДгДЪДќЃЈfrom_bowЃЉжаДДНЈЫќЁЃетЪЧЮвЕФДЪДќЃЈtrn_term_docЃЉЃЌетЪЧЮвУЧЕФБъЧЉЃЈtrn_yЃЉЃЌетЪЧбщжЄМЏЕФЯрЭЌФкШнЃЌВЂЧвУПИіЦРТлзюЖрЪЙгУ 2000 ИіЖРЬиЕФЕЅДЪЃЌетвбОзуЙЛСЫЁЃ
ШЛКѓДгФЧИіФЃаЭЪ§ОнжаЃЌЙЙНЈвЛИібЇЯАЦїЃЌетЪЧ Fast AI ЖдЛљгкЦгЫиБДвЖЫЙЕуЛ§ЕФФЃаЭЕФЗКЛЏЃЌШЛКѓФтКЯИУФЃаЭЁЃ
learner = md.dotprod_nb_learner() learner.fit(0.02, 1, wds=1e-6, cycle_len=1) ''' [ 0\. 0.0251 0.12003 0.91552] ''' learner.fit(0.02, 2, wds=1e-6, cycle_len=1) ''' [ 0\. 0.02014 0.11387 0.92012] [ 1\. 0.01275 0.11149 0.92124] ''' learner.fit(0.02, 2, wds=1e-6, cycle_len=1) ''' [ 0\. 0.01681 0.11089 0.92129] [ 1\. 0.00949 0.10951 0.92223] '''
ОЙ§ 5 ИіЪБДњЃЌЮвЕФзМШЗТЪвбОДяЕНСЫ 92.2ЁЃЫљвдЯждквбОдЖдЖГЌЙ§СЫЯпадЛљзМЃЈдкдЪМТлЮФжаЃЉЁЃЫљвдШУЮвИјФуеЙЪОвЛЯТФЧЖЮДњТыЁЃ

ЫљвдДњТыЗЧГЃМђЖЬЁЃОЭЪЧетбљЁЃетПДЦ№РДвВЗЧГЃЪьЯЄЁЃетРягавЛаЉаЁЕїећЃЌМйзАетИіаДзХEmbeddingЕФЖЋЮїЪЕМЪЩЯаДзХLinearЁЃЮвТэЩЯЛсеЙЪОИјФуПД embeddingЁЃЫљвдЮвУЧЛљБОЩЯгавЛИіЯпадВуЃЌЬиеїЕФЪ§СПзїЮЊааЃЌМЧзЁЃЌsklearn ЬиеївтЮЖзХЛљБОЩЯЪЧЕЅДЪЕФЪ§СПЁЃШЛКѓЖдгкУПИіЕЅДЪЃЌЮвУЧНЋДДНЈвЛИіШЈжиЃЌетЪЧгаЕРРэЕФЁЊЁЊТпМЛиЙщЃЌУПИіЕЅДЪгавЛИіШЈжиЁЃШЛКѓЮвУЧНЋЫќГЫвдrжЕЃЌЫљвдУПИіЕЅДЪЃЌЮвУЧгавЛИіrжЕУПИіРрЁЃЫљвдЮвЪЕМЪЩЯзіСЫетИіЃЌетбљПЩвдДІРэВЛНіНіЪЧе§УцКЭИКУцЃЌЛЙПЩвдевГіЪЧФФИізїепДДзїСЫетИізїЦЗЁЊЁЊР§ШчПЩФмгаЮхСљИізїепЁЃ
ЛљБОЩЯЮвУЧЪЙгУетаЉЯпадВуРДЕУЕНШЈжиКЭrЕФжЕЃЌШЛКѓЮвУЧШЁШЈжиГЫвдrЃЌШЛКѓЯрМгЁЃЫљвдетжЛЪЧвЛИіМђЕЅЕФЕуЛ§ЃЌОЭЯёЮвУЧЮЊШЮКЮТпМЛиЙщЫљзіЕФФЧбљЃЌШЛКѓНјаа softmaxЁЃЮвУЧЮЊСЫЛёЕУИќКУЕФНсЙћЫљзіЕФЗЧГЃаЁЕФЕїећЪЧетИі+self.w_adjЃК

ЮвЬэМгЕФЖЋЮїЪЧЃЌетЪЧвЛИіВЮЪ§ЃЌЕЋЮвМИКѕзмЪЧЪЙгУетИіФЌШЯжЕ 0.4ЁЃФЧУДетЪЧзіЪВУДЕФФиЃПетдйДЮИФБфСЫЯШбщЁЃШчЙћФуПМТЧвЛЯТЃЌМДЪЙЮвУЧНЋетИіrГЫвдЮФЕЕОиеѓзїЮЊЫќУЧЕФздБфСПЃЌФуецЕФЯыДгвЛИіЮЪЬтПЊЪМЃЌКУЕФЃЌГЭЗЃЯюШдШЛдкНЋwЭЦЯђСуЁЃ

ФЧУДwЮЊСувтЮЖзХЪВУДЃПШчЙћЮвУЧЕФЯЕЪ§ЖМЪЧ 0 ЛсдѕУДбљЃП

ЕБЮвУЧНЋетИіОиеѓгыетаЉЯЕЪ§ЯрГЫЪБЃЌЮвУЧШдШЛЕУЕНСуЁЃЫљвдШЈжиЮЊСузюжеЛсЫЕЁАЮвЖдетИіЪТЧщЪЧе§УцЛЙЪЧИКУцУЛгавтМћЁЃЁБСэвЛЗНУцЃЌШчЙћЫќУЧЖМЪЧ 1ЃЌФЧУДЛљБОЩЯОЭЪЧЫЕЮвЕФвтМћЪЧЦгЫиБДвЖЫЙЯЕЪ§ЪЧЭъШЋе§ШЗЕФЁЃЫљвдЮвЫЕСуМИКѕПЯЖЈВЛЪЧе§ШЗЕФЯШбщЁЃЮвУЧВЛгІИУецЕФЫЕШчЙћУЛгаЯЕЪ§ЃЌФЧОЭвтЮЖзХКіТдЦгЫиБДвЖЫЙЯЕЪ§ЁЃ1 ПЩФмЬЋИпСЫЃЌвђЮЊЮвУЧЪЕМЪЩЯШЯЮЊЦгЫиБДвЖЫЙжЛЪЧД№АИЕФвЛВПЗжЁЃЫљвдЮвГЂЪдСЫМИИіВЛЭЌЕФЪ§ОнМЏЃЌЛљБОЩЯЪЧЫЕШЁетаЉШЈжиВЂМгЩЯвЛаЉГЃЪ§ЁЃЫљвдСудкетжжЧщПіЯТЛсБфГЩ 0.4ЁЃЛЛОфЛАЫЕЃЌе§дђЛЏГЭЗЃНЋШЈжиЭЦЯђетИіжЕЖјВЛЪЧСуЁЃЮвЗЂЯждкаэЖрЪ§ОнМЏжаЃЌ0.4 аЇЙћЗЧГЃКУЧвЗЧГЃЮШНЁЁЃдйДЮЃЌЛљБОЫМЯыЪЧдкЪЙгУМђЕЅФЃаЭДгЪ§ОнжабЇЯАЕФЭЌЪБЃЌОЁПЩФмЕиШкШыЮвУЧЕФЯШбщжЊЪЖЁЃЫљвдНсЙћЪЧЃЌЕБФуЫЕШУШЈжиОиеѓЕФСуЪЕМЪЩЯвтЮЖзХФугІИУЪЙгУДѓдМвЛАыЕФrжЕЪБЃЌетБШШЈжигІИУШЋВПЮЊСуЕФЯШбщаЇЙћИќКУЁЃ
ЮЪЬтЃКwЪЧБэЪОЫљаше§дђЛЏСПЕФЕуТ№ЃПwЪЧШЈжиЁЃЫљвдx = ((w+self.w_adj)*r/self.r_adj).sum(1)е§дкМЦЫуЮвУЧЕФМЄЛюЁЃЮвУЧМЦЫуЮвУЧЕФМЄЛюЕШгкШЈжиГЫвдrЃЌШЛКѓЧѓКЭЁЃЫљвдетжЛЪЧЮвУЧЕФе§ГЃЯпадКЏЪ§ЁЃБЛГЭЗЃЕФЪЧЮвЕФШЈжиОиеѓЁЃетОЭЪЧЪмЕНГЭЗЃЕФЕиЗНЁЃЫљвдЭЈЙ§ЫЕЃЌКйЃЌФужЊЕРЃЌВЛвЊжЛЪЙгУw ЁЊЁЊ ЪЙгУw+0.4ЁЃ0.4ЃЈМДself.w_adjЃЉВЛЪмГЭЗЃЁЃЫќВЛЪЧШЈжиОиеѓЕФвЛВПЗжЁЃвђДЫЃЌШЈжиОиеѓЪЕМЪЩЯУтЗбЛёЕУСЫ 0.4ЁЃ
ЮЪЬтЃКЭЈЙ§етбљзіЃЌМДЪЙОЙ§е§дђЛЏЃЌУПИіЬиеїЖМЛсЛёЕУвЛаЉаЮЪНЕФзюаЁШЈжиТ№ЃПВЛвЛЖЈЃЌвђЮЊЫќзюжеПЩФмЛсЮЊвЛИіЬиеїбЁдёвЛИіЯЕЪ§ЮЊ-0.4ЃЌетНЋБэЪОЁАФужЊЕРЃЌМДЪЙЦгЫиБДвЖЫЙЫЕЖдгкетИіЬиеїrгІИУЪЧЪВУДЃЌЮвШЯЮЊФугІИУЭъШЋКіТдЫќЁБЁЃ
анЯЂЦкМфгаМИИіЮЪЬтЁЃЕквЛИіЪЧЙигкетРяе§дкЗЂЩњЕФЪТЧщЕФзмНсЃК

етРягаwМгЩЯШЈжиЕїећГЫвдrЃК

ЫљвдЭЈГЃЃЌЮвУЧЫљзіЕФЪЧЫЕТпМЛиЙщЛљБОЩЯЪЧwxЃЈЮвНЋКіТдЦЋВюЃЉЁЃШЛКѓЮвУЧНЋЦфИќИФЮЊrxЁЄwЁЃШЛКѓЮвУЧЫЕШУЮвУЧЯШзіxЁЄwетВПЗжЁЃетРяЕФетИіЖЋЮїЃЌЮвЪЕМЪЩЯГЦжЎЮЊ wЃЌетПЩФмКмдуИтЃЌЪЕМЪЩЯЪЧwГЫвдxЃК

ЫљвдЃЌЮвУЛгаr(xЁЄw)ЃЌЮвгаwЁЄxМгЩЯвЛИіГЃЪ§ГЫвдrЁЃЫљвдетРяЕФЙиМќЫМЯыЪЧе§дђЛЏЯЃЭћШЈжиЮЊСуЃЌвђЮЊЫќЪдЭММѕЩйІВw?ЁЃЫљвдЮвУЧЫљЫЕЕФЪЧЃЌКУАЩЃЌЮвУЧЯЃЭћНЋШЈжиЭЦЯђСуЃЌвђЮЊетЪЧЮвУЧЕФФЌШЯЦ№ЕуЦкЭћЁЃЫљвдЮвУЧЯЃЭћДІгкетбљвЛжжЧщПіЃЌМДШчЙћШЈжиЮЊСуЃЌФЧУДЮвУЧгавЛИіЖдЮвУЧРДЫЕдкРэТлЩЯЛђжБЙлЩЯгавтвхЕФФЃаЭЁЃетИіФЃаЭЃЈr(xЁЄw)ЃЉЃЌШчЙћШЈжиЮЊСуЃЌЖдЮвУЧРДЫЕУЛгажБЙлвтвхЁЃвђЮЊЫќдкЫЕЃЌКйЃЌНЋЫљгаЖЋЮїГЫвдСуЛсЯћГ§вЛЧаЁЃЮвУЧЪЕМЪЩЯдкЫЕЁАВЛЃЌЮвУЧЪЕМЪЩЯШЯЮЊЮвУЧЕФrЪЧгагУЕФЃЌЮвУЧЪЕМЪЩЯЯыБЃСєЫќЁЃЁБЫљвдЃЌШУЮвУЧШЁ(xЁЄw)ВЂМгЩЯ 0.4ЁЃЫљвдЯждкЃЌШчЙће§дђЛЏЦїНЋШЈжиЭЦЯђСуЃЌФЧУДЫќНЋНЋзмКЭЕФжЕЭЦЯђ 0.4ЁЃ
вђДЫЃЌЫќНЋећИіФЃаЭЭЦЯђ 0.4 БЖrЁЃЛЛОфЛАЫЕЃЌШчЙћФњНЋЫљгаШЈживЛЦ№е§дђЛЏЕН 0.4 БЖrЃЌФЧУДЮвУЧЕФФЌШЯЦ№ЕуЪЧЫЕЁАЪЧЕФЃЌФњжЊЕРЃЌШУЮвУЧЪЙгУвЛЕуrЁЃетПЩФмЪЧвЛИіКУжївтЁЃЁБетОЭЪЧетИіЯыЗЈЁЃетИіЯыЗЈЛљБОЩЯЪЧЕБШЈжиЮЊСуЪБЛсЗЂЩњЪВУДЁЃФњЯЃЭћФЧЪЧгавтвхЕФЃЌЗёдђе§дђЛЏШЈжиГЏзХФЧИіЗНЯђвЦЖЏОЭВЛЪЧвЛИіКУжївтЁЃ
ЕкЖўИіЮЪЬтЪЧЙигк n-gramsЁЃЫљвд n-gram жаЕФ N ПЩвдЪЧ uniЃЌbiЃЌtriЃЌЕШЕШЁЃ1ЃЌ2ЃЌ3ЃЌЕШЕШИі gramsЁЃЫљвдЁАThis movie is goodЁБгаЫФИі unigramsЃКThisЃЌmovieЃЌisЃЌgoodЁЃЫќгаШ§Иі bigramsЃКThis movieЃЌmovie isЃЌis goodЁЃЫќгаСНИі trigramsЃКThis movie isЃЌmovie is goodЁЃ
ЮЪЬтЃКФњНщвтЛиЕНw_adjЛђ0.4ЕФФкШнТ№ЃПЮвдкЯыетжжЕїећЛсВЛЛсЫ№КІФЃаЭЕФПЩдЄВтадЃЌвђЮЊЯыЯѓвЛЯТМЋЖЫЧщПіЃЌШчЙћВЛЪЧ 0.4ЃЌШчЙћЪЧ 4,000ЃЌФЧУДЫљгаЯЕЪ§ЛљБОЩЯЛсЪЧЁЃПШЗЧаЕиЫЕЁЃвђДЫЃЌЮвУЧЕФЯШбщашвЊгавтвхЁЃетОЭЪЧЮЊЪВУДЫќБЛГЦЮЊ DotProdNBЃЌвђДЫЯШбщЪЧЮвУЧШЯЮЊЦгЫиБДвЖЫЙЪЧвЛИіКУЕФЯШбщЕФЕиЗНЁЃвђДЫЃЌЦгЫиБДвЖЫЙШЯЮЊr = p/qЪЧвЛИіКУЕФЯШбщЃЌЮвУЧВЛНіШЯЮЊетЪЧвЛИіКУЕФЯШбщЃЌЖјЧвЮвУЧШЯЮЊrx+bЪЧвЛИіКУЕФФЃаЭЁЃетОЭЪЧЦгЫиБДвЖЫЙФЃаЭЁЃЛЛОфЛАЫЕЃЌЮвУЧЦкЭћЯЕЪ§ЮЊ 1 ЪЧвЛИіКУЕФЯЕЪ§ЃЌЖјВЛЪЧ 4,000ЁЃОпЬхРДЫЕЃЌЮвУЧШЯЮЊСуПЩФмВЛЪЧвЛИіКУЕФЯЕЪ§ЁЃЕЋЮвУЧвВШЯЮЊвВаэЦгЫиБДвЖЫЙАцБОгаЕуЙ§гкздаХЁЃЫљвдвВаэ 1 гаЕуИпЁЃвђДЫЃЌЮвУЧЯрЕБШЗЖЈЃЌМйЩшЦгЫиБДвЖЫЙФЃаЭЪЧЪЪЕБЕФЃЌе§ШЗЕФЪ§зждк 0 КЭ 1 жЎМфЁЃ

ЮЪЬтМЬајЃКЕЋЮвдкЯыЕФЪЧжЛвЊВЛЪЧСуЃЌФњОЭЛсНЋФЧаЉгІИУЮЊСуЕФЯЕЪ§ЭЦЕНЗЧСуЕФЕиЗНЃЌВЂЪЙИпЯЕЪ§гыСуЯЕЪ§жЎМфЕФВювьБфаЁЁЃрХЃЌЕЋЪЧФњПДЃЌЫќУЧБОРДОЭВЛгІИУЪЧСуЁЃЫќУЧгІИУЪЧrЁЃЧыМЧзЁЃЌетЪЧдкЮвУЧЕФЧАЯђКЏЪ§жаЃЌЫљвдетЪЧЮвУЧе§дкМЦЫуЬнЖШЕФвЛВПЗжЁЃЫљвдЛљБОЩЯЪЧЫЕЃЌКУАЩЃЌФњШдШЛПЩвдНЋ self.w ЩшжУЮЊФњЯВЛЖЕФШЮКЮжЕЁЃЕЋЪЧе§дђЛЏЦїЯЃЭћЫќЮЊСуЁЃЫљвдЮвУЧЫљЫЕЕФЪЧЃЌКУАЩЃЌШчЙћФњЯЃЭћЫќЮЊСуЃЌФЧУДЮвНЋГЂЪдЪЙСуИјГівЛИіКЯРэЕФД№АИЁЃ
УЛгаШЫЫЕ 0.4 ЖдгкУПИіЪ§ОнМЏЖМЪЧЭъУРЕФЁЃЮвГЂЪдСЫвЛаЉВЛЭЌЕФЪ§ОнМЏЃЌВЂЗЂЯждк 0.3 КЭ 0.6 жЎМфгавЛаЉзюМбжЕЁЃЕЋЮвДгЮДЗЂЯжвЛИіБШСуИќКУЕФЪ§ОнМЏЃЌетВЂВЛЦцЙжЁЃЮввВДгЮДЗЂЯжвЛИіИќКУЕФЪ§ОнМЏЁЃвђДЫЃЌетИіЯыЗЈЪЧвЛИіКЯРэЕФФЌШЯжЕЃЌЕЋетЪЧСэвЛИіФњПЩвдЭцЫЃЕФВЮЪ§ЃЌЮвгаЕуЯВЛЖЁЃетЪЧСэвЛМўФњПЩвдЪЙгУЭјИёЫбЫїЛђЦфЫћЗНЗЈРДевГіЖдФњЕФЪ§ОнМЏзюМбЕФЖЋЮїЁЃЪЕМЪЩЯЃЌЙиМќдкгкдкетИіФЃаЭжЎЧАЕФУПИіФЃаЭЃЌОнЮвЫљжЊЃЌЖМвўКЌЕиМйЩшЫќгІИУЮЊСуЃЌвђЮЊЫќУЧУЛгаетИіВЮЪ§ЁЃЫГБуЫЕвЛОфЃЌЮвЪЕМЪЩЯЛЙгаЕкЖўИіВЮЪ§ЃЈr_adj=10ЃЉЃЌЫќЪЧЮвЖд r зіЕФЯрЭЌЕФЪТЧщЃЌЪЕМЪЩЯЪЧЭЈЙ§вЛИіВЮЪ§Г§вд rЃЌЮвЯждкВЛЛсЬЋЕЃаФЃЌЕЋетЪЧСэвЛИіФњПЩвдгУРДЕїеће§дђЛЏаджЪЕФВЮЪ§ЁЃзюжеЃЌЮвЪЧвЛИіЪЕжЄжївхепЃЌЖјВЛЪЧвЛИіРэТлМвЁЃЮвШЯЮЊетЫЦКѕЪЧвЛИіКУжївтЁЃМИКѕЫљгаЮвШЯЮЊЪЧвЛИіКУжївтЕФЪТЧщзюжеЖМБЛжЄУїЪЧгоДРЕФЁЃетИіЬиЖЈЕФЯыЗЈдкетИіЪ§ОнМЏЩЯИјГіСЫСМКУЕФНсЙћЃЌвВдкЦфЫћвЛаЉЪ§ОнМЏЩЯИјГіСЫСМКУЕФНсЙћЁЃ
**ЮЪЬтЃК**ЮвШдШЛЖдw + w_adjИаЕНРЇЛѓЁЃФуЬсЕНЮвУЧжДааw + w_adjЪЧЮЊСЫВЛШУЯЕЪ§ЩшЮЊСуЃЌЮвУЧЖдЯШбщИГгшСЫвЛаЉживЊадЁЃЕЋФувВЫЕЙ§бЇЯАЕФаЇЙћПЩФмЪЧwБЛЩшЮЊИКжЕЃЌетПЩФмЛсЪЙw + w_adjЮЊСуЁЃЫљвдШчЙћЮвУЧдЪаэбЇЯАЙ§ГЬШЗЪЕНЋЯЕЪ§ЩшЮЊСуЃЌФЧЮЊЪВУДетгыжЛгаwВЛЭЌФиЃПвђЮЊе§дђЛЏЁЃвђЮЊЮвУЧЭЈЙ§ІВw?ЖдЦфНјааГЭЗЃЁЃЛЛОфЛАЫЕЃЌЮвУЧдкЫЕЃЌФужЊЕРЃЌШчЙћКіТдrЪЧзюКУЕФбЁдёЃЌФЧНЋЛсЛЈЗбФуЃЈІВw?ЃЉЁЃФуНЋВЛЕУВЛНЋwЩшЮЊИКЪ§ЁЃЫљвджЛгадкетЯдШЛЪЧвЛИіКУжївтЕФЧщПіЯТВХетбљзіЁЃГ§ЗЧетЯдШЛЪЧвЛИіКУжївтЃЌЗёдђФугІИУНЋЦфБЃСєдкдДІЁЃетЪЧЮЈвЛЕФдвђЁЃНёЬьЮвУЧЫљзіЕФЫљгаЪТЧщЛљБОЩЯЖМЪЧЮЊСЫзюДѓЛЏЮвУЧДге§дђЛЏжаЛёЕУЕФгХЪЦЃЌВЂЧвЫЕе§дђЛЏНЋЮвУЧЭЦЯђФГжжФЌШЯМйЩшЃЌМИКѕЫљгаЕФЛњЦїбЇЯАЮФЯзЖММйЩшФЌШЯМйЩшЪЧЫљгаЪТЮяЖМЪЧСуЁЃЮвдкЫЕЕФЪЧЃЌДгРэТлЩЯНВетЪЧгаЕРРэЕФЃЌЖјДгОбщЩЯНВЃЌЪТЪЕжЄУїФугІИУОіЖЈФуЕФФЌШЯМйЩшЪЧЪВУДЃЌетНЋИјФуДјРДИќКУЕФНсЙћЁЃ
**ЮЪЬтМЬајЃК**ФЧУДПЩвдетбљЫЕЃЌдкФГжжГЬЖШЩЯФуЪЧдкЧАЭљНЋЫљгаЯЕЪ§ЩшЮЊСуЕФЙ§ГЬжаЩшжУСЫвЛИіЖюЭтЕФеЯАЃЌШчЙћШЗЪЕжЕЕУЕФЛАЃЌЫќНЋФмЙЛзіЕНетвЛЕуТ№ЃПЪЧЕФЃЌШЗЪЕШчДЫЁЃЫљвдЮвЛсЫЕЃЌУЛгаетИіФЌШЯеЯАЃЌЪЙЯЕЪ§ЗЧСуЪЧеЯАЁЃЯждкЮввЊЫЕЕФЪЧЃЌВЛЃЌеЯАЪЧЪЙЯЕЪ§ВЛЕШгк 0.4rЁЃ
**ЮЪЬтЃК**ЫљвдетЪЧ w?ГЫвдФГИіГЃЪ§ЕФзмКЭЁЃШчЙћГЃЪ§ЪЧЃЌБШШчЫЕ 0.1ЃЌФЧУДШЈжиПЩФмВЛЛсЧїЯђгкСуЁЃФЧУДЮвУЧПЩФмОЭВЛашвЊШЈжиЫЅМѕСЫЃПШчЙћГЃЪ§ЕФжЕЮЊСуЃЌФЧУДОЭУЛгае§дђЛЏЁЃЕЋШчЙћетИіжЕДѓгкСуЃЌФЧУДОЭЛсгавЛаЉГЭЗЃЁЃЖјЧвПЩвдЭЦВтЃЌЮвУЧНЋЦфЩшжУЮЊЗЧСуЪЧвђЮЊЮвУЧЙ§ФтКЯСЫЁЃЫљвдЮвУЧЯывЊвЛаЉГЭЗЃЁЃЫљвдШчЙћгавЛаЉГЭЗЃЃЌФЧУДЮвЕФЙлЕуЪЧЮвУЧгІИУГЭЗЃФЧаЉгыЮвУЧЕФЯШбщВЛЭЌЕФЪТЮяЃЌЖјВЛЪЧГЭЗЃФЧаЉгыСуВЛЭЌЕФЪТЮяЁЃЮвУЧЕФЯШбщЪЧЪТЮягІИУДѓжТЕШгкrЁЃ
ЧЖШы[1:05:17]
ЮвЯыЬИЬИЧЖШыЁЃЮвЫЕМйзАЫќЪЧЯпадЕФЃЌЪЕМЪЩЯЮвУЧПЩвдМйзАЫќЪЧЯпадЕФЁЃШУЮвЯђФуеЙЪОЮвУЧПЩвдЖрУДЕиМйзАЫќЪЧЯпадЕФЃЌОЭЯёnn.LinearЃЌДДНЈвЛИіЯпадВуЁЃ
етЪЧЮвУЧЕФЪ§ОнОиеѓЃЌетЪЧЮвУЧЕФЯЕЪ§rШчЙћЮвУЧе§дкНјааrАцБОЁЃЫљвдШчЙћЮвУЧНЋrЗХШыСаЯђСПжаЃЌФЧУДЮвУЧПЩвдЭЈЙ§ЯЕЪ§ЖдЪ§ОнОиеѓНјааОиеѓГЫЗЈЁЃ
вђДЫЃЌетИіздБфСПОиеѓГЫвдетИіЯЕЪ§ОиеѓЕФОиеѓГЫЗЈНЋИјЮвУЧвЛИіД№АИЁЃЫљвдЮЪЬтЪЧЃЌКУАЩЃЌЮЊЪВУД Jeremy УЛгааДnn.LinearЃПЮЊЪВУД Jeremy аДСЫnn.EmbeddingЃПдвђЪЧЃЌШчЙћФуЛивфвЛЯТЃЌЮвУЧЪЕМЪЩЯВЂВЛЪЧетбљДцДЂЕФЁЃвђЮЊетЪЕМЪЩЯЪЧПэЖШЮЊ 800,000ЃЌИпЖШЮЊ 25,000ЁЃЫљвдЮвУЧЪЕМЪЩЯЪЧетбљДцДЂЕФЃК

ЮвУЧЕФДцДЂЗНЪНЪЧЃЌетИіДЪДќАќКЌФФаЉЕЅДЪЫїв§ЁЃетЪЧвЛжжЯЁЪшЕФДцДЂЗНЪНЁЃЫќжЛСаГіУПИіОфзгжаЕФЫїв§ЁЃМјгкДЫЃЌЮвЯждкЯывЊжДааЮвИеИеЯђФуеЙЪОЕФФЧжжОиеѓГЫЗЈЃЌвдДДНЈЯрЭЌЕФНсЙћЁЃЕЋЮвЯывЊДгЯЁЪшБэЪОжажДааЁЃетЛљБОЩЯЪЧвЛжжЖРШШБрТыЃК

етгаЕуЯёвЛИіащФтОиеѓАцБОЁЃЫќгавЛИіЕЅДЪЁАthisЁБТ№ЃПЫќгавЛИіЕЅДЪЁАmovieЁБТ№ЃПЕШЕШЁЃЫљвдШчЙћЮвУЧВЩгУМђЕЅАцБОЕФгаУЛгаЕЅДЪЁАthisЁБЃЈМД 1, 0, 0, 0, 0, 0ЃЉЃЌШЛКѓЮвУЧНЋЦфГЫвдrЃЌФЧУДЫќжЛЛсЗЕЛиЕквЛИіЯюФПЃК

змЕФРДЫЕЃЌвЛИіЖРШШБрТыЯђСПГЫвдвЛИіОиеѓЕШЭЌгкВщевИУОиеѓжаЕФЕк n ааЁЃ ЫљвдетжЛЪЧЫЕевЕНЕк 0ЁЂЕквЛИіЁЂЕкЖўИіКЭЕкЮхИіЯЕЪ§ЃК

ЫќУЧЭъШЋЯрЭЌЁЃ дкетжжЧщПіЯТЃЌУПИіЬиеїжЛгавЛИіЯЕЪ§ЃЌЕЋЪЕМЪЩЯЮветбљзіЕФЗНЪНЪЧЮЊУПИіРрБ№ЕФУПИіЬиеїЖМгавЛИіЯЕЪ§ЁЃ ЫљвддкетжжЧщПіЯТЃЌРрБ№ЪЧе§УцКЭИКУцЁЃ ЫљвдЮвЪЕМЪЩЯга r е§Уц (p/q)ЃЌr ИКУц (q/r)ЃК

дкЖўНјжЦЧщПіЯТЃЌЯдШЛЭЌЪБгЕгаСНепЪЧЖргрЕФЁЃ ЕЋЪЧШчЙћЪЧЯёетИіЮФБОЕФзїепЪЧЫЃП ЪЧ JeremyЃЌSavannah ЛЙЪЧ TerrenceЃП ЯждкЮвУЧгаШ§ИіРрБ№ЃЌЮвУЧЯывЊШ§Иі r ЕФжЕЁЃ ЫљвдзіетИіЯЁЪшАцБОЕФКУДІЪЧЃЌФуПЩвдВщевЕк 0ЁЂЕквЛИіЁЂЕкЖўИіКЭЕкЮхИіЁЃ

дйДЮЧПЕїЃЌДгЪ§бЇЩЯНВЃЌетгыГЫвдвЛИіЖРШШБрТыОиеѓЪЧЯрЭЌЕФЁЃ ЕЋЪЧЃЌЕБЪфШыЯЁЪшЪБЃЌаЇТЪЯдШЛвЊИпЕУЖрЁЃ вђДЫЃЌетИіМЦЫуММЧЩдкЪ§бЇЩЯгыГЫвдвЛИіЖРШШБрТыОиеѓЪЧЯрЭЌЕФЃЌЖјВЛЪЧИХФюЩЯРрЫЦгкЁЃ етБЛГЦЮЊЧЖШыЁЃ ЮвЯраХДѓЖрЪ§ШЫПЩФмвбОЬ§ЫЕЙ§ЧЖШыЃЌБШШчДЪЧЖШыЃКWord2VecЃЌGloVe ЕШЁЃ ШЫУЧЯВЛЖАбЫќУЧЫЕГЩЪЧетжжСюШЫОЊЬОЕФаТИДдгЩёОЭјТчЖЋЮїЁЃ ЕЋЪТЪЕВЂЗЧШчДЫЁЃ ЧЖШывтЮЖзХЭЈЙ§МђЕЅЕФЪ§зщВщевРДМгПьГЫвдвЛИіЖРШШБрТыОиеѓЕФЙ§ГЬЁЃ етОЭЪЧЮЊЪВУДЮвЫЕФуПЩвдАбетИіЯыЯѓГЩЫЕ self.w = nn.Linear(nf+1, 1)ЃК

вђЮЊЫќЪЕМЪЩЯзіЕФЪЧЯрЭЌЕФЪТЧщЁЃ ЫќЪЕМЪЩЯЪЧвЛИіОпгаетаЉЮЌЖШЕФОиеѓЁЃ етЪЧвЛИіЯпадВуЃЌЕЋЫќЦкЭћЮвУЧвЊИјЫќЕФЪфШыЪЕМЪЩЯВЛЪЧвЛИіЖРШШБрТыОиеѓЃЌЖјЪЧвЛИіећЪ§СаБэ ЁЊЁЊ УПИіЯюФПЕФУПИіЕЅДЪЕФЫїв§ЁЃ ЫљвдФуПЩвдПДЕН Fast AI жаЕФ forward КЏЪ§здЖЏЛёШЁЃЈЖдгк DotProdNB leanerЃЉЬиеїЫїв§ЃЈfeature_idxЃЉЃК

ЫљвдЫќУЧздЖЏРДздЯЁЪшОиеѓЁЃ Numpy ЪЙЕУКмШнвзжЛашзЅШЁетаЉЫїв§ЁЃ ЛЛОфЛАЫЕЃЌЮвУЧдкетРяЃЈfeat_idxЃЉгавЛИіАќКЌетИіЮФЕЕжаЕФ 800,000 ИіЕЅДЪЫїв§ЕФСаБэЁЃ ЫљвдетРяЃЈself.w(feat_idx)ЃЉЫЕЕФЪЧВщевЮвУЧЕФЧЖШыОиеѓжаЕФУПвЛИіЃЌИУОиеѓга 800,000 ааЃЌВЂЗЕЛиФуевЕНЕФУПвЛИіЖЋЮїЁЃ ДгЪ§бЇЩЯНВЃЌетгыГЫвдвЛИіЖРШШБрТыОиеѓЪЧЯрЭЌЕФЁЃ етОЭЪЧЫљгаЧЖШыЕФКЌвхЁЃ етвтЮЖзХЮвУЧЯждкПЩвдДІРэЙЙНЈШЮКЮРраЭЕФФЃаЭЃЌБШШчШЮКЮРраЭЕФЩёОЭјТчЃЌЦфжаЮвУЧЕФЪфШыПЩФмЪЧЗЧГЃИпЛљЪ§ЕФЗжРрБфСПЁЃ ШЛКѓЮвУЧжЛашНЋЫќУЧзЊЛЛЮЊНщгкСуКЭМЖБ№Ъ§жЎМфЕФЪ§зжДњТыЃЌШЛКѓЮвУЧПЩвдбЇЯАвЛИіЯпадВуЃЌОЭКУЯёЮвУЧвбОЖдЦфНјааСЫЖРШШБрТыЃЌЖјЪЕМЪЩЯВЂУЛгаЙЙНЈЖРШШБрТыАцБОЃЌвВУЛгаНјааОиеѓГЫЗЈЁЃ ЯрЗДЃЌЮвУЧНЋжЛДцДЂЫїв§АцБОВЂМђЕЅЕиНјааЪ§зщВщевЁЃ вђДЫЃЌЛиСїЕФЬнЖШЛљБОЩЯЪЧдкЖРШШБрТыАцБОжаЃЌЫљгаЮЊСуЕФЖЋЮїЖМУЛгаЬнЖШЃЌвђДЫЛиСїЕФЬнЖШжЛЛсИќаТЮвУЧЪЙгУЕФЧЖШыОиеѓЕФЬиЖЈааЁЃ етЖдгкздШЛгябдДІРэЗЧГЃживЊЃЌОЭЯёдкетРявЛбљЃЌЮвЯыДДНЈвЛИі PyTorch ФЃаЭЃЌИУФЃаЭНЋЪЕЯжетИіЗЧГЃМђЕЅЕФЗНГЬЁЃ

ШчЙћУЛгаетИіММЧЩЃЌФЧвтЮЖзХЮввЊЪфШывЛИі 25,000 x 80,000 дЊЫиЕФЪ§зщЃЌетНЋгаЕуЗшПёЁЃ ЫљвдетИіММЧЩШУЮваДЯТСЫетИіЁЃ ЮвжЛЪЧгУ Embedding ЬцЛЛСЫ LinearЃЌгУвЛаЉжЛЪфШыЫїв§ЖјВЛЪЧЪфШыЖРШШБрТыЕФЖЋЮїРДЬцЛЛФЧИіЃЌОЭетбљЁЃ ШЛКѓЫќМЬајЙЄзїЃЌЫљвдЯждкУПИіЪБДњЕФбЕСЗЪБМфДѓдМЪЧвЛЗжжгЁЃ
ЯждкЮвУЧПЩвдАбетИіЯыЗЈгІгУЕНВЛНіНіЪЧгябдЃЌЖјЪЧШЮКЮЖЋЮїЩЯЁЃ Р§ШчЃЌдЄВтдгЛѕЕъЩЬЦЗЕФЯњЪлЧщПіЁЃ
ЮЪЬтЃКЮвУЧЪЕМЪЩЯВЂУЛгаВщевШЮКЮЖЋЮїЃЌЖдАЩЃПЮвУЧжЛЪЧПДЕНСЫФЧИіДјгаЫїв§ЕФЪ§зщБэЪОЃПЫљвдЮвУЧе§дкВщевЁЃЯждкДцДЂЕФДЪДќЕФБэЪОВЛдйЪЧ 1 1 1 0 0 1ЃЌЖјЪЧ 0 1 2 5ЁЃвђДЫЃЌЮвУЧЪЕМЪЩЯБиаыНјааОиеѓГЫЗЈЁЃЕЋЪЧЮвУЧВЛЪЧНјааОиеѓГЫЗЈЃЌЖјЪЧВщевЕкСуИіЖЋЮїЃЌЕквЛИіЖЋЮїЃЌЕкЖўИіЖЋЮїКЭЕкЮхИіЖЋЮїЁЃ
ЮЪЬтМЬајЃКетвтЮЖзХЮвУЧШдШЛБЃСєСЫЖРШШБрТыОиеѓТ№ЃПВЛЃЌЮвУЧУЛгаЁЃетРяУЛгаЪЙгУЖРШШБрТыОиеѓЁЃФПЧАУЛгаЭЛГіЯдЪОЖРШШБрТыОиеѓЁЃЮвУЧФПЧАЭЛГіЯдЪОЕФЪЧЫїв§СаБэКЭШЈжиОиеѓжаЕФЯЕЪ§СаБэЃК

ЫљвдЯждкЮвУЧвЊзіЕФЪЧИќНјвЛВНЃЌЮвУЧвЊЫЕИљБОВЛЪЙгУЯпадФЃаЭЃЌШУЮвУЧЪЙгУвЛИіЖрВуЩёОЭјТчЁЃШУЮвУЧЕФЪфШыПЩФмАќРЈвЛаЉЗжРрБфСПЁЃетаЉЗжРрБфСПЃЌЮвУЧНЋжЛНЋЦфзїЮЊЪ§жЕЫїв§ЁЃвђДЫЃЌетаЉЕФЕквЛВуВЛЛсЪЧвЛИіЦеЭЈЕФЯпадВуЃЌЫќУЧНЋЪЧвЛИіЧЖШыВуЃЌЮвУЧжЊЕРдкЪ§бЇЩЯЫќЕФааЮЊгыЯпадВуЭъШЋЯрЭЌЁЃвђДЫЃЌЮвУЧЕФЯЃЭћЪЧЯждкЮвУЧПЩвдЪЙгУетИіРДЮЊШЮКЮРраЭЕФЪ§ОнДДНЈвЛИіЩёОЭјТчЁЃ
ТоЫЙТќОКШќ
МИФъЧАдк Kaggle ЩЯгавЛИіУћЮЊ Rossmann ЕФОКШќЃЌетЪЧвЛИіЕТЙњЕФдгЛѕСЌЫјЕъЃЌЫћУЧвЊЧѓдЄВтЫћУЧЩЬЕъжаЩЬЦЗЕФЯњЪлЧщПіЁЃетАќРЈЗжРрКЭСЌајБфСПЕФЛьКЯЁЃдк Guo/Berkhahn ЕФетЦЊТлЮФжаЃЌЫћУЧУшЪіСЫЫћУЧЕФЕкШ§УћзїЦЗЃЌетБШЕквЛУћзїЦЗМђЕЅЕУЖрЃЌЕЋМИКѕвЛбљКУЃЌЕЋМђЕЅЕУЖрЃЌвђЮЊЫћУЧРћгУСЫетИіЫљЮНЕФЪЕЬхЧЖШыЕФЯыЗЈЁЃдкТлЮФжаЃЌЫћУЧШЯЮЊЫћУЧЗЂУїСЫетИіЃЌЪЕМЪЩЯдчаЉЪБКђгЩ Yoshua Bengio КЭЫћЕФКЯжјепдкСэвЛИі Kaggle ОКШќжааДЙ§ЁЃОЁЙмШчДЫЃЌЮвОѕЕУ Guo дкУшЪіетИіШчКЮдкаэЖрЦфЫћЗНУцЪЙгУЩЯзпЕУИќдЖЃЌЫљвдЮвУЧвВЛсЬИТлетИіЁЃ
БЪМЧБОдкЩюЖШбЇЯАДцДЂПтжаЃЌвђЮЊЮвУЧдкЩюЖШбЇЯАПЮГЬжаЬжТлСЫвЛаЉЩюЖШбЇЯАЬиЖЈЗНУцЃЌдкетУХПЮГЬжаЃЌЮвУЧжївЊНЋЬжТлЬиеїЙЄГЬЃЌЮвУЧЛЙНЋЬжТлетИіЧЖШыЕФЯыЗЈЁЃ

ШУЮвУЧДгЪ§ОнПЊЪМЁЃЫљвдЪ§ОнЪЧЃЌ2015 Фъ 7 дТ 31 ШеЃЌЕк 1 КХЕъПЊвЕЁЃЫћУЧе§дкНјааДйЯњЛюЖЏЁЃгабЇаЃМйЦкЁЃВЛЪЧЙњМвМйЦкЃЌЫћУЧТєГіСЫ 5263 МўЩЬЦЗЁЃетЪЧЫћУЧЬсЙЉЕФЙиМќЪ§ОнЁЃЫљвдФПБъЯдШЛЪЧдкУЛгаЯњЪлаХЯЂЕФВтЪдМЏжадЄВтЯњЪлЖюЁЃЫћУЧЛЙИцЫпФуЃЌЖдгкУПМвЩЬЕъЃЌЫќЪЧФГжжЬиЖЈРраЭЕФЃЌЯњЪлФГжжЬиЖЈжжРрЕФЩЬЦЗЃЌЦфзюНќЕФОКељЖдЪжОрРывЛЖЈОрРыЃЌОКељЖдЪждк 2008 Фъ 9 дТПЊвЕЃЌЛЙгавЛаЉЙигкДйЯњЕФИќЖраХЯЂЃЌЮвВЛжЊЕРетвтЮЖзХЪВУДЁЃОЭЯёаэЖр Kaggle ОКШќвЛбљЃЌЫћУЧдЪаэФњЯТдиЭтВПЪ§ОнМЏЃЌжЛвЊФњгыЦфЫћОКељепЗжЯэЁЃЫћУЧЛЙИцЫпФњУПМвЩЬЕъЫљдкЕФжнЃЌвђДЫШЫУЧЯТдиСЫЕТЙњВЛЭЌжнЕФУћГЦЃЌЫћУЧЮЊЕТЙњУПжмЯТдиСЫвЛаЉЙШИшЧїЪЦЪ§ОнЁЃЮвВЛжЊЕРЫћУЧЕУЕНСЫЪВУДОпЬхЕФЙШИшЧїЪЦЃЌЕЋЪЧгаЕФЁЃЖдгкУПИіШеЦкЃЌЫћУЧЯТдиСЫвЛЖбЮТЖШаХЯЂЁЃОЭЪЧетбљЁЃ
етРявЛИігаШЄЕФМћНтЪЧЃЌRossmann ПЩФмдкФГжжГЬЖШЩЯЗИСЫвЛИіДэЮѓЃЌЩшМЦетИіБШШќЪЧвЛИіПЩвдЪЙгУЭтВПЪ§ОнЕФБШШќЁЃвђЮЊЪЕМЪЩЯЃЌФуВЂВЛФмжЊЕРЯТжмЕФЬьЦјЛђЯТжмЕФЙШИшЧїЪЦЁЃЕЋЕБФуВЮМг Kaggle БШШќЪБЃЌФуВЂВЛдкКѕетаЉЁЃФужЛЪЧЯыгЎЃЌЫљвдФуЛсРћгУвЛЧаПЩвдЕУЕНЕФЁЃ
Ъ§ОнЧхРэ
ЪзЯШШУЮвУЧЬИЬИЪ§ОнЧхРэЁЃдкетИіЛёЕУЕкШ§УћЕФВЮШќзїЦЗжаЃЌЪЕМЪЩЯВЂУЛгаНјааЬЋЖрЕФЬиеїЙЄГЬЃЌЬиБ№ЪЧАДее Kaggle ЕФБъзМЃЌЭЈГЃУПвЛИіЯИНкЖМКмживЊЁЃетЪЧвЛИіКмКУЕФР§згЃЌеЙЪОСЫЪЙгУЩёОЭјТчПЩвдШЁЕУЖрДѓЕФГЩОЭЃЌетШУЮвЯыЦ№СЫзђЬьЮвУЧЬИЕНЕФЫїХтдЄВтБШШќЃЌЛёЪЄепУЛгаНјааШЮКЮЬиеїЙЄГЬЃЌЭъШЋвРРЕЩюЖШбЇЯАЁЃЗПМфРяЕФаІЩљЃЌЮвВТЃЌЪЧРДздФЧаЉдкБШШќжаНјааСЫвЛЕуЕуЬиеїЙЄГЬЕФШЫУЧ?
ЫГБуЬсвЛЯТЃЌЮвЗЂЯждкБШШќжаХЌСІЙЄзїЃЌШЛКѓБШШќНсЪјСЫФуУЛгагЎЕУБШШќЁЃШЛКѓЛёЪЄепГіРДЫЕетОЭЪЧЮвгЎЕУБШШќЕФЗНЗЈЁЃетЪЧФубЇЕНзюЖрЕФЪБКђЁЃгаЪБКђетжжЧщПіЗЂЩњдкЮвЩэЩЯЃЌЮвЛсЯыЃЌХЖЃЌЮвЯыЕНСЫФЧИіЃЌЮвЪдЙ§СЫЃЌШЛКѓЮвЛиШЅЗЂЯжЮвФЧРягаИі bugЃЌЮвУЛгае§ШЗВтЪдЃЌШЛКѓЮввтЪЖЕНЃЌХЖЃЌКУАЩЃЌЮвецЕФашвЊбЇЛсвдВЛЭЌЕФЗНЪНВтЪдетИіЖЋЮїЁЃгаЪБКђОЭЯёЃЌХЖЃЌЮвЯыЕНСЫФЧИіЃЌЕЋЮвМйЩшЫќВЛЛсЦ№зїгУЃЌЮвецЕФвЊМЧзЁдкзіШЮКЮМйЩшжЎЧАМьВщвЛЧаЁЃФужЊЕРЃЌгаЪБКђОЭЯёЃЌХЖЃЌЮвУЛгаЯыЕНФЧИіММЪѕЃЌЭлЃЌЯждкЮвжЊЕРЫќБШЮвИеИеГЂЪдЕФвЛЧаЖМвЊКУЁЃЗёдђЃЌШчЙћгаШЫЫЕЃЌКйЃЌФужЊЕРетЪЧвЛИіЗЧГЃКУЕФММЪѕЃЌФуЛсЫЕКУЕФЁЃЕЋЪЧЕБФуЛЈСЫМИИідТЕФЪБМфГЂЪдзіФГЪТЃЌШЛКѓБ№ШЫгУФЧИіММЪѕзіЕУИќКУЪБЃЌФЧОЭЯрЕБгаЫЕЗўСІСЫЁЃЫљвдетгаЕуРЇФбЃЌЮвеОдкФуУцЧАЫЕетРягавЛЖбЮвгУЙ§ЕФММЪѕЃЌЮвгЎЕУСЫвЛаЉ Kaggle БШШќЃЌЮвЕУЕНСЫвЛаЉзюЯШНјЕФНсЙћЁЃЕЋЪЧЕБетаЉаХЯЂДЋДяИјФуЪБЃЌвбОЪЧЖўЪжаХЯЂСЫЁЃЫљвдГЂЪдвЛаЉЖЋЮїецЕФКмАєЁЃЖјЧвгШЦфЪЧдкЩюЖШбЇЯАПЮГЬжаЃЌЮвзЂвтЕНЃЌЮвЕФвЛаЉбЇЩњГЂЪдСЫЮвЫЕЕФетИіММЪѕЃЌЫћУЧЕкЖўЬьОЭНјШыСЫ Kaggle БШШќЕФЧАЪЎУћЃЌЫћУЧЫЕЃЌКУЕФЃЌетЫуЪЧЗЧГЃгааЇЁЃKaggle БШШќгаКмЖрдвђЪЧгаАяжњЕФЁЃЕЋЦфжавЛИізюКУЕФЗНЪНЪЧБШШќНсЪјКѓЗЂЩњЕФЪТЧщЃЌЫљвдЖдгкЯждкМДНЋНсЪјЕФБШШќЃЌШЗБЃФуЙлПДТлЬГЃЌПДПДШЫУЧдкЗжЯэНтОіЗНАИЗНУцЗжЯэСЫЪВУДЃЌШчЙћФуЯыСЫНтИќЖрЃЌПЩвдздгЩЕиЮЪЮЪЛёЪЄепЃЌКйЃЌФуФмИцЫпЮвИќЖрЙигкетИіЛђФЧИіТ№ЁЃШЫУЧЭЈГЃКмРжвтНтЪЭЁЃШЛКѓзюКУЪЧГЂЪдздМКИДжЦвЛЯТЁЃетПЩвдБфГЩвЛИіКмАєЕФВЉПЭЮФеТЛђКмАєЕФФкКЫЃЌПЩвдЫЕЃЌФГФГЫЕЫћУЧЪЙгУСЫетИіММЪѕЃЌетРяЪЧетИіММЪѕЕФвЛИіЗЧГЃМђЖЬЕФНтЪЭЃЌетРяЪЧвЛЕуДњТыеЙЪОЫќЪЧШчКЮЪЕЯжЕФЃЌетРяЪЧНсЙћеЙЪОФуПЩвдЕУЕНЯрЭЌЕФНсЙћЁЃетвВПЩвдЪЧвЛИіЗЧГЃгаШЄЕФаДзїЁЃ
Ъ§ОнОЁПЩФмвзгкРэНтзмЪЧКмКУЕФЁЃвђДЫЃЌдкетжжЧщПіЯТЃЌРДзд Kaggle ЕФЪ§ОнЪЙгУИїжжећЪ§БэЪОМйЦкЁЃЮвУЧПЩвджЛЪЙгУвЛИіВМЖћжЕРДБэЪОЪЧЗёЪЧМйЦкЁЃЫљвджЛашЧхРэвЛЯТЃК
train.StateHoliday = train.StateHoliday!='0' test.StateHoliday = test.StateHoliday!='0'
ЮвУЧгаКмЖрВЛЭЌЕФБэашвЊНЋЫќУЧШЋВПКЯВЂдквЛЦ№ЁЃЮвгавЛжжгУ Pandas КЯВЂЪТЮяЕФБъзМЗНЗЈЁЃЮвжЛЪЧЪЙгУСЫ Pandas ЕФКЯВЂКЏЪ§ЃЌОпЬхРДЫЕЮвзмЪЧНјаазѓСЌНгЁЃзѓСЌНгЪЧБЃСєзѓБэжаЕФЫљгаааЃЌФугавЛИіЙиМќСаЃЌНЋЦфгыгвВрБэжаЕФЙиМќСаЦЅХфЃЌШЛКѓКЯВЂФЧаЉвВДцдкгкгвБэжаЕФааЁЃ
def join_df(left, right, left_on, right_on=None, suffix='_y'): if right_on is None: right_on = left_on return left.merge( right, how='left', left_on=left_on, right_on=right_on, suffixes=("", suffix) )
ЮвзмЪЧНјаазѓСЌНгЕФЙиМќдвђЪЧЃЌдкНјааСЌНгжЎКѓЃЌЮвзмЪЧМьВщгвВрЪЧЗёгаЯждкЮЊПеЕФФкШнЃК
store = join_df(store, store_states, "Store") len(store[store.State.isnull()])
вђЮЊШчЙћЪЧетбљЃЌФЧОЭвтЮЖзХЮвТЉЕєСЫвЛаЉЖЋЮїЁЃЮвУЛгадкетРяеЙЪОЃЌЕЋЮввВМьВщСЫааЪ§дкжЎЧАКЭжЎКѓЪЧЗёгаБфЛЏЁЃШчЙћгаБфЛЏЃЌФЧОЭвтЮЖзХгвВрБэВЛЪЧЮЈвЛЕФЁЃЫљвдМДЪЙЮвШЗЖЈФГМўЪТЪЧецЕФЃЌЮввВзмЪЧМйЩшЮвИудвСЫЁЃЫљвдЮвзмЪЧМьВщЁЃ
ЮвПЩвдМЬајНЋжнУћКЯВЂЕНЬьЦјжаЃК
weather = join_df(weather, state_names, "file", "StateName")
ШчЙћФуПДвЛЯТЙШИшЧїЪЦБэЃЌЫќгаетИіжмЗЖЮЇЃЌЮвашвЊНЋЦфзЊЛЛЮЊШеЦквдБуМгШыЫќЃК

дк Pandas жаетбљзіЕФКУДІЪЧЃЌPandas ШУЮвУЧПЩвдЗУЮЪЫљгаЕФ PythonЁЃР§ШчЃЌдкЯЕСаЖдЯѓФкВПЃЌгавЛИі.strЪєадЃЌПЩвдШУФуЗУЮЪЫљгаЕФзжЗћДЎДІРэКЏЪ§ЁЃОЭЯё.catШУФуЗУЮЪЗжРрКЏЪ§вЛбљЃЌ.dtШУФуЗУЮЪШеЦкЪБМфКЏЪ§ЁЃЫљвдЯждкЮвПЩвдВ№ЗжИУСажаЕФЫљгаФкШнЁЃ
googletrend['Date']=googletrend.week.str.split(' - ',expand=True)[0] googletrend['State']=googletrend.file.str.split('_', expand=True)[2] googletrend.loc[googletrend.State=='NI', "State"] = 'HB,NI'
ЪЙгУетаЉ Pandas КЏЪ§ЗЧГЃживЊЃЌвђЮЊЫќУЧНЋБЛЯђСПЛЏЃЌМгЫйЃЌЭЈГЃЭЈЙ§ SIMD жСЩйЭЈЙ§ C ДњТыЃЌвдБудЫааЕУгжПьгжЫГРћЁЃ
КЭЭљГЃвЛбљЃЌШУЮвУЧЮЊЮвУЧЕФШеЦкЬэМгШеЦкдЊЪ§ОнЃК
add_datepart(weather, "Date", drop=False) add_datepart(googletrend, "Date", drop=False) add_datepart(train, "Date", drop=False) add_datepart(test, "Date", drop=False)
зюКѓЃЌЮвУЧЛљБОЩЯЪЧдкЖдЫљгаетаЉБэНјааШЅЙцЗЖЛЏЁЃЮвУЧНЋАбЫќУЧШЋВПЗХШывЛИіБэжаЁЃвђДЫЃЌдкЙШИшЧїЪЦБэжаЃЌЫќУЧжївЊЪЧАДжнЛЎЗжЕФЧїЪЦЃЌЕЋвВгаећИіЕТЙњЕФЧїЪЦЃЌЫљвдЮвУЧНЋећИіЕТЙњЕФЧїЪЦЗХШывЛИіЕЅЖРЕФЪ§ОнПђжаЃЌвдБуЮвУЧПЩвдМгШыЫќЃК
trend_de = googletrend[googletrend.file == 'Rossmann_DE']
вђДЫЃЌЮвУЧНЋгаетИіжнЕФЙШИшЧїЪЦКЭећИіЕТЙњЕФЙШИшЧїЪЦЁЃ
ЯждкЮвУЧПЩвдМЬајЮЊбЕСЗМЏКЭВтЪдМЏЭЌЪБМгШыЁЃШЛКѓМьВщСНепЖМУЛгаПежЕЁЃ
store = join_df(store, store_states, "Store") len(store[store.State.isnull()]) ''' 0 ''' joined = join_df(train, store, "Store") joined_test = join_df(test, store, "Store") len(joined[joined.StoreType.isnull()]),len(joined_test[joined_test.StoreType.isnull()]) ''' (0, 0) ''' joined = join_df(joined, googletrend, ["State","Year", "Week"]) joined_test = join_df(joined_test, googletrend, ["State","Year", "Week"]) len(joined[joined.trend.isnull()]),len(joined_test[joined_test.trend.isnull()]) ''' (0, 0) ''' joined = joined.merge(trend_de, 'left', ["Year", "Week"], suffixes=('', '_DE')) joined_test = joined_test.merge(trend_de, 'left', ["Year", "Week"], suffixes=('', '_DE')) len(joined[joined.trend_DE.isnull()]),len(joined_test[joined_test.trend_DE.isnull()]) ''' (0, 0) ''' joined = join_df(joined, weather, ["State","Date"]) joined_test = join_df(joined_test, weather, ["State","Date"]) len(joined[joined.Mean_TemperatureC.isnull()]),len(joined_test[joined_test.Mean_TemperatureC.isnull()]) ''' (0, 0) '''
ЮвЕФКЯВЂКЏЪ§ЃЌШчЙћгаСНСаЪЧЯрЭЌЕФЃЌЮвНЋзѓВрЕФКѓзКЩшжУЮЊПеЃЌетбљЫќОЭВЛЛсгАЯьУћГЦЃЌгвВрЩшжУЮЊ_yЁЃ

дкетжжЧщПіЯТЃЌЮвВЛЯывЊШЮКЮжиИДЕФФкШнЃЌЫљвдЮвжЛЪЧфЏРРВЂЩОГ§СЫЫќУЧЃК
for df in (joined, joined_test): for c in df.columns: if c.endswith('_y'): if c in df.columns: df.drop(c, inplace=True, axis=1) for df in (joined,joined_test): df['CompetitionOpenSinceYear'] = \ df.CompetitionOpenSinceYear.fillna(1900).astype(np.int32) df['CompetitionOpenSinceMonth'] = \ df.CompetitionOpenSinceMonth.fillna(1).astype(np.int32) df['Promo2SinceYear'] = \ df.Promo2SinceYear.fillna(1900).astype(np.int32) df['Promo2SinceWeek'] = \ df.Promo2SinceWeek.fillna(1).astype(np.int32)
етМвЩЬЕъЕФжївЊОКељЖдЪжздФГИіШеЦквдРДвЛжБПЊвЕЁЃвђДЫЃЌЮвУЧПЩвдЪЙгУ Pandas ЕФto_datetimeЃЌЮвДЋШыФъЁЂдТКЭШеЁЃЫљвдетНЋИјЮвУЧвЛИіДэЮѓЃЌГ§ЗЧЫќУЧЖМгаФъКЭдТЃЌЫљвдЮвУЧНЋШБЪЇЕФВПЗжЬюГфЮЊ 1900 ФъКЭ 1 дТЃЈМћЩЯЮФЃЉЁЃЖјЮвУЧеце§ЯыжЊЕРЕФЪЧетМвЩЬЕъдкетИіЬиЖЈМЧТМЪБвбОПЊвЕЖрОУСЫЃЌЫљвдЮвУЧПЩвдНјааШеЦкЯрМѕЃК
for df in (joined,joined_test): df["CompetitionOpenSince"] = \ pd.to_datetime(dict( year=df.CompetitionOpenSinceYear, month=df.CompetitionOpenSinceMonth, day=15 )) df["CompetitionDaysOpen"] = \ df.Date.subtract(df.CompetitionOpenSince).dt.days
ЯждкШчЙћФуПМТЧвЛЯТЃЌгаЪБОКељЖдЪжЕФПЊвЕЪБМфЭэгкетвЛааЃЌЫљвдгаЪБЛсЪЧИКЪ§ЁЃЖјЧвПЩФмУЛгавтвхгаИКЪ§ЃЈМДНЋдк x ЬьКѓПЊвЕЃЉЁЃЯждкЛАЫфШчДЫЃЌЮвОјВЛЛсдкУЛгаЯШдЫааАќКЌЫќКЭВЛАќКЌЫќЕФФЃаЭЕФЧщПіЯТЗХШыетбљЕФЖЋЮїЁЃвђЮЊЮвУЧЖдЪ§ОнЕФМйЩшЭљЭљЪЧВЛе§ШЗЕФЁЃдкетжжЧщПіЯТЃЌЮвУЛгаЗЂУїШЮКЮетаЉдЄДІРэВНжшЁЃЮваДСЫЫљгаЕФДњТыЃЌЕЋЫќЖМЪЧЛљгкЕкШ§УћЛёНБепЕФ GitHub ДцДЂПтЁЃвђДЫЃЌжЊЕРдк Kaggle ОКШќжаЛёЕУЕкШ§УћашвЊзіЪВУДЃЌЮвЯрЕБПЯЖЈЫћУЧЛсМьВщУПвЛИіетаЉдЄДІРэВНжшЃЌВЂШЗБЃЫќЪЕМЪЩЯЬсИпСЫЫћУЧЕФбщжЄМЏЗжЪ§ЁЃ
for df in (joined,joined_test): df.loc[df.CompetitionDaysOpen<0, "CompetitionDaysOpen"] = 0 df.loc[df.CompetitionOpenSinceYear<1990,"CompetitionDaysOpen"]=0
[1:30:44]
вђДЫЃЌЮвУЧНЋДДНЈвЛИіЩёОЭјТчЃЌЦфжавЛаЉЪфШыЪЧСЌајЕФЃЌЖјСэвЛаЉЪЧЗжРрЕФЁЃетвтЮЖзХдкЮвУЧЕФЩёОЭјТчжаЃЌЮвУЧЛљБОЩЯЛсгаетжжГѕЪМШЈжиОиеѓЁЃЮвУЧНЋгаетИіЪфШыЬиеїЯђСПЁЃвЛаЉЪфШыНЋжЛЪЧЦеЭЈЕФСЌајЪ§зжЃЈР§ШчзюИпЮТЖШЃЌЕНзюНќЩЬЕъЕФЙЋРяЪ§ЃЉЃЌЖјСэвЛаЉНЋБЛгааЇЕиЖРШШБрТыЁЃЕЋЮвУЧЪЕМЪЩЯВЛЛсНЋЦфДцДЂЮЊЖРШШБрТыЁЃЮвУЧЪЕМЪЩЯЛсНЋЦфДцДЂЮЊЫїв§ЁЃ
вђДЫЃЌЩёОЭјТчФЃаЭашвЊжЊЕРетаЉСажаЕФФФаЉгІИУЛљБОЩЯДДНЈвЛИіЧЖШыЃЈМДФФаЉгІИУБЛЪгЮЊЖРШШБрТыЃЉЃЌФФаЉгІИУжБНгЪфШыЕНЯпадВужаЁЃЕБЮвУЧЕНДяФЧРяЪБЃЌЮвУЧНЋИцЫпФЃаЭФФИіЪЧФФИіЃЌЕЋЪЕМЪЩЯЮвУЧашвЊЬсЧАПМТЧФФаЉЮвУЧЯывЊЪгЮЊЗжРрБфСПЃЌФФаЉЪЧСЌајБфСПЁЃЬиБ№ЪЧЃЌЮвУЧвЊНЋЦфЪгЮЊЗжРрЕФЖЋЮїЃЌЮвУЧВЛЯЃЭћДДНЈБШЮвУЧашвЊЕФИќЖрЕФРрБ№ЁЃШУЮвИцЫпФуЮвЕФвтЫМЁЃ
етДЮБШШќЕФЕкШ§УћОіЖЈНЋБШШќПЊЗХЕФдТЪ§зїЮЊвЛИіЫћУЧвЊгУзїЗжРрБфСПЕФЖЋЮїЁЃЮЊСЫБмУтДДНЈБШашвЊЕФИќЖрЕФРрБ№ЃЌЫћУЧНЋЦфНиЖЯЕН 24 ИідТЁЃЫћУЧЫЕЃЌГЌЙ§ 24 ИідТЕФШЮКЮЖЋЮїЃЌНиЖЯЕН 24 ИіЁЃвђДЫЃЌетРяЪЧБШШќПЊЗХЕФЮЈвЛжЕЃЌДгСуЕН 24ЁЃетвтЮЖзХНЋЛсгавЛИіЧЖШыОиеѓЃЌЛљБОЩЯЛсгавЛИіЧЖШыЯђСПЃЌгУгкЩаЮДПЊЗХЕФЪТЮяЃЈ0ЃЉЃЌгУгквЛИідТПЊЗХЕФЪТЮяЃЈ1ЃЉЃЌвРДЫРрЭЦЁЃ
for df in (joined,joined_test): df["CompetitionMonthsOpen"] = df["CompetitionDaysOpen"]//30 df.loc[df.CompetitionMonthsOpen>24,"CompetitionMonthsOpen"] = 24 joined.CompetitionMonthsOpen.unique() ''' array([24, 3, 19, 9, 0, 16, 17, 7, 15, 22, 11, 13, 2, 23, 12, 4, 10, 1, 14, 20, 8, 18, 6, 21, 5] '''
ЯждкЃЌЫћУЧОјЖдПЩвдНЋЦфзїЮЊвЛИіСЌајБфСПРДДІРэ[1:33:14]ЁЃЫћУЧБОПЩвджЛЪЧдкетРяЗХвЛИіЪ§зжЃЌБэЪОПЊЗХСЫЖрЩйИідТЃЌШЛКѓНЋЦфЪгЮЊСЌајБфСПЃЌжБНгЪфШыЕНГѕЪМШЈжиОиеѓжаЁЃЕЋЮвЗЂЯжЃЌЯдШЛетаЉОКељЖдЪжвВЗЂЯжСЫЃЌОЁПЩФмЕиНЋЪТЮяЪгЮЊЗжРрБфСПЪЧзюКУЕФЁЃетбљзіЕФдвђЪЧЃЌЕБФуЭЈЙ§вЛИіЧЖШыОиеѓДЋЕнвЛаЉФкШнЪБЃЌвтЮЖзХУПИіМЖБ№ПЩвдБЛЭъШЋВЛЭЌЕиДІРэЁЃР§ШчЃЌдкетжжЧщПіЯТЃЌФГЮяЪЧЗёПЊЗХСЫСуИідТЛђвЛИідТЪЧЗЧГЃВЛЭЌЕФЁЃвђДЫЃЌШчЙћФуНЋЦфзїЮЊСЌајБфСПЪфШыЃЌЩёОЭјТчНЋКмФбевЕНОпгаетжжОоДѓВювьЕФЙІФмаЮЪНЁЃетЪЧПЩФмЕФЃЌвђЮЊЩёОЭјТчПЩвдзіШЮКЮЪТЧщЁЃЕЋШчЙћФуВЛШУЫќБфЕУШнвзЁЃСэвЛЗНУцЃЌШчЙћФуЪЙгУЧЖШыЃЌНЋЦфЪгЮЊЗжРрБфСПЃЌФЧУДСуКЭвЛНЋгаЭъШЋВЛЭЌЕФЯђСПЁЃвђДЫЃЌгШЦфЪЧдкФугазуЙЛЕФЪ§ОнЪБЃЌОЁПЩФмЕиНЋСаЪгЮЊЗжРрБфСПЪЧвЛИіИќКУЕФжївтЁЃЕБЮвЫЕОЁПЩФмЪБЃЌЛљБОЩЯвтЮЖзХЛљЪ§ВЛвЊЬЋИпЁЃвђДЫЃЌШчЙћетЪЧУПвЛааЩЯЮЈвЛВЛЭЌЕФЯњЪл ID КХТыЃЌФуВЛФмНЋЦфЪгЮЊЗжРрБфСПЁЃвђЮЊФЧНЋЪЧвЛИіОоДѓЕФЧЖШыОиеѓЃЌЖјЧвУПбљЖЋЮїжЛГіЯжвЛДЮЃЌЛђепЪЧОрРызюНќЩЬЕъЕФЙЋРяЪ§ЕНаЁЪ§ЕуКѓСНЮЛЃЌФувВВЛЛсНЋЦфзїЮЊЗжРрБфСПЁЃ
етЪЧЫћУЧдкетДЮБШШќжаЖМЪЙгУЕФОбщЗЈдђЁЃЪТЪЕЩЯЃЌШчЙћЮвУЧЙіЖЏЕНЫћУЧЕФбЁдёЃЌетЪЧЫћУЧЕФзіЗЈЃК

ЫћУЧЕФСЌајБфСПЪЧеце§СЌајЕФЖЋЮїЃЌБШШчЕНОКељЖдЪжЕФЙЋРяЪ§ЃЌЮТЖШЕШЁЃЖјЦфЫћвЛЧаЃЌЛљБОЩЯЃЌЫћУЧЖМЪгЮЊЗжРрБфСПЁЃ
НёЬьОЭЕНетРяЁЃЯТДЮЃЌЮвУЧНЋНсЪјетИіЛАЬтЁЃЮвУЧНЋПДПДШчКЮНЋетИізЊЛЏЮЊЩёОЭјТчЃЌВЂзмНсвЛЯТЁЃЕНЪБМћЃЁ
ЛњЦїбЇЯА 1ЃКЕк 12 ПЮ
дЮФЃК
medium.com/@hiromi_suenaga/machine-learning-1-lesson-12-6c2512e005a3выепЃКЗЩСњ
авщЃКCC BY-NC-SA 4.0
РДздЛњЦїбЇЯАПЮГЬЕФИіШЫБЪМЧЁЃЫцзХЮвМЬајИДЯАПЮГЬвдЁАеце§ЁБРэНтЫќЃЌетаЉБЪМЧНЋМЬајИќаТКЭИФНјЁЃЗЧГЃИааЛ Jeremy КЭ Rachel ИјСЫЮветИібЇЯАЕФЛњЛсЁЃ
ЮвЯыНёЬьЮвУЧПЩвдЭъГЩдкетИі Rossmann БЪМЧБОжаЕФЙЄзїЃЌПДвЛЯТЪБМфађСадЄВтКЭНсЙЙЛЏЪ§ОнЗжЮіЁЃШЛКѓЮвУЧПЩФмЛсЖдЮвУЧбЇЕНЕФвЛЧаНјаавЛИіаЁаЁЕФИДЯАЃЌвђЮЊаХВЛаХгЩФуЃЌетОЭЪЧНсЮВЁЃЙигкЛњЦїбЇЯАУЛгаИќЖрашвЊжЊЕРЕФЖЋЮїЃЌжЛгаФуНЋдкЯТИібЇЦкКЭгрЩњжабЇЕНЕФвЛЧаЁЃЕЋЮоТлШчКЮЃЌЮвУЛгаБ№ЕФвЊНЬЕФСЫЁЃЫљвдЮвЛсзівЛИіаЁаЁЕФИДЯАЃЌШЛКѓЮвУЧНЋКИЧПЮГЬжазюживЊЕФВПЗжЃЌФЧОЭЪЧЫМПМШчКЮе§ШЗЁЂгааЇЕиЪЙгУетжжММЪѕЃЌвдМАШчКЮШУЫќЖдЩчЛсВњЩњЛ§МЋгАЯьЕФЗНЪНЁЃ
ЩЯДЮЃЌЮвУЧЬИЕНСЫетбљвЛИіЯыЗЈЃЌЕБЮвУЧЪдЭМЙЙНЈетИі CompetitionMonthsOpen ХЩЩњБфСПЪБЃЌЪЕМЪЩЯЮвУЧНЋЦфНиЖЯЮЊВЛГЌЙ§ 24 ИідТЃЌЮвУЧЬИЕНСЫдвђЃЌвђЮЊЮвУЧЪЕМЪЩЯЯЃЭћНЋЦфгУзїЗжРрБфСПЃЌвђЮЊЗжРрБфСПЃЌгЩгкЧЖШыЃЌОпгаИќЖрЕФСщЛюадЃЌЩёОЭјТчПЩвдШчКЮЪЙгУЫќУЧЁЃЫљвдетОЭЪЧЮвУЧРыПЊЕФЕиЗНЁЃ
for df in (joined,joined_test): df["CompetitionMonthsOpen"] = df["CompetitionDaysOpen"]//30 df.loc[df.CompetitionMonthsOpen>24, "CompetitionMonthsOpen"]= 24 joined.CompetitionMonthsOpen.unique() ''' array([24, 3, 19, 9, 0, 16, 17, 7, 15, 22, 11, 13, 2, 23, 12, 4, 10, 1, 14, 20, 8, 18, 6, 21, 5]) '''
ШУЮвУЧМЬајНјааЯТШЅЁЃвђЮЊетИіБЪМЧБОжаЗЂЩњЕФЪТЧщПЩФмЪЪгУгкФуДІРэЕФДѓЖрЪ§ЪБМфађСаЪ§ОнМЏЁЃе§ШчЮвУЧЫљЬжТлЕФЃЌЫфШЛЮвУЧдкетРяЪЙгУСЫdf.applyЃЌЕЋетЪЧдкУПвЛааЩЯдЫаавЛЖЮ Python ДњТыЃЌЫйЖШЗЧГЃТ§ЁЃЫљвджЛгадкевВЛЕНПЩвдвЛДЮЖдећСаНјааВйзїЕФЪИСПЛЏ pandas Лђ numpy КЏЪ§ЪБВХетбљзіЁЃЕЋдкетжжЧщПіЯТЃЌЮвевВЛЕНвЛжжЗНЗЈПЩвддкВЛЪЙгУШЮвт Python ЕФЧщПіЯТНЋФъЗнКЭжмЪ§зЊЛЛЮЊШеЦкЁЃ
ЛЙжЕЕУМЧзЁетИі lambda КЏЪ§ЕФИХФюЁЃУПЕБФуГЂЪдНЋвЛИіКЏЪ§гІгУЕНФГИіЖЋЮїЕФУПвЛааЛђеХСПЕФУПИідЊЫиЪБЃЌШчЙћУЛгавбОДцдкЕФЪИСПЛЏАцБОЃЌФуНЋВЛЕУВЛЕїгУЯёDataFrame.applyетбљЕФЖЋЮїЃЌЫќНЋдЫааФуДЋЕнИјУПИідЊЫиЕФКЏЪ§ЁЃЫљвдетЛљБОЩЯЪЧКЏЪ§ЪНБрГЬжаЕФгГЩфЃЌвђЮЊКмЖрЪБКђФуЯывЊДЋЕнИјЫќЕФКЏЪ§ЪЧФужЛЛсЪЙгУвЛДЮШЛКѓЖЊЦњЕФЖЋЮїЁЃЪЙгУетжж lambda ЗНЗЈЗЧГЃГЃМћЁЃЫљвдетИі lambda ЪЧЮЊСЫИцЫпdf.applyвЊЪЙгУЪВУДЖјДДНЈЕФКЏЪ§ЁЃ
for df in (joined,joined_test): df["Promo2Since"] = pd.to_datetime(df.apply( lambda x: Week(x.Promo2SinceYear, x.Promo2SinceWeek).monday(), axis=1 ).astype(pd.datetime)) df["Promo2Days"] = df.Date.subtract(df["Promo2Since"]).dt.days
ЮвУЧвВПЩвдгУВЛЭЌЕФЗНЪНРДаДетИі [3:16]ЁЃвдЯТСНИіЕЅдЊИёЪЧЯрЭЌЕФЃК

вЛжжЗНЗЈЪЧЖЈвхКЏЪ§ЃЈcreate_promo2since(x)ЃЉЃЌШЛКѓЭЈЙ§УћГЦДЋЕнЫќЃЌСэвЛжжЗНЗЈЪЧЪЙгУ lambda дкЯжГЁЖЈвхКЏЪ§ЁЃЫљвдШчЙћФуВЛЪьЯЄДДНЈКЭЪЙгУ lambdaЃЌСЗЯАКЭЭцХЊdf.applyЪЧвЛИіКмКУЕФСЗЯАЗНЗЈЁЃ
fast.ai ЛњЦїбЇЯАБЪМЧЃЈЫФЃЉЃЈ3ЃЉ/article/1482646
