ШЋЮФСДНгЃКhttp://tecdat.cn/?p=32646
ЗжЮіЪІЃКJunjun Li
дкетЦЊЮФеТжаЃЌЮвУЧНЋзХжиЬНЬжИпЮЌЪ§ОнЯТЕФЛњЦїбЇЯАгІгУЃЌвдЗПЮнЪаГЁзтН№МлИёдЄВтЮЊР§ЁЃ
дкЪЕМЪЩњЛюжаЃЌЗПЮнзтН№зїЮЊвЛИіживЊЕФОМУжИБъЃЌБЛЙуЗКгІгУгкГЧЪаЙцЛЎЁЂВЦЮёЭЖзЪЕШЗНУцЕФОіВпжаЁЃШЛЖјЃЌШчКЮзМШЗЕидЄВтЗПЮнзтН№МлИёШДвЛжБЪЧвЛИіОпгаЬєеНадЕФЮЪЬтЁЃ
БОЮФНЋНщЩмШчКЮЪЙгУLassoЛиЙщКЭНЛВцбщжЄЗНЗЈРДНтОіИпЮЌЪ§ОнЯТЕФЗПЮнЪаГЁзтН№МлИёдЄВтЮЪЬтЃЌВЂЯъЯИВћЪіRгябддкДЫЙ§ГЬжаЕФгІгУММЧЩКЭЪЕЯжЗНЗЈЁЃ
БГОА
Goal: РћгУжїЬхЮявЕКЭзтЛЇЕФИїжжЬиеїРДдЄВтЗПЮнЪаГЁзтН№МлИё
Data: дкInter-University Consortium for Politicaland Social Research(ICPSR)Ъ§ОнПтжаевЕНЕФ2007ФъУРЙњзЁЗПЕїВщЃЈШЋЙњЮЂЙлЪ§ОнЃЉга65,000ИіЙлВтжЕКЭГЌЙ§500ИіБфСП
Limitation: ФГаЉЬиеїЕФВЛПЩЙлВт
гаВПЗжЬиеїдкГЌЙ§80%ЕФЙлВтжЕжаУЛгаЪ§ОнЕФЃЌЕМжТУЛгаАьЗЈХфКЯдЄВтФЃаЭНјааБфСПЕФЩИбЁ
Model used:
Regularization: 10.fold Lasso & AICc Lasso
ЪЪКЯгкДѓСПЪ§ОнДІРэЃЈИпЮЌЖШЖрБфСП)

Ъ§ОнЧхРэ
ЪЙгУRгябдДІРэЮоЗЈЙлВтЕНЕФБфСПЉU
- ЙлВтcodebookШЅГ§ЮоЙиЕФБфСП
- бЁдёШЅГ§50%вдЩЯЪЇзйЕФБфСПЃЈПЩвдЗДИДЖдБШШЅГ§СЫВЛЭЌБфСПКѓЕФФЃаЭ)
- ЖдгкЪЃЯТЕФБфСПШЅГ§КЌгаNAЕФЙлВтжЕ
- visualizeВПЗжживЊБфСПЪЧЗёКЯРэ

ЙлВтЪ§Он
ДѓЖрЪ§зтН№МЏжадквЛЧЇУРдЊзѓгвЃЌЦфЦНОљзтН№ЃЈгЩКьЯпБъЪО)ЮЊ1025УРдЊ(жБЗНЭМГЪЯжГіТдЮЂгвЦЋЕФНќЫЦе§ЬЌЗжВМ)ЁЃ
ЙлВтвЛаЉЙиМќЬиеїЕФаХЯЂЃЌетаЉЬиеїгажњгкдЄВтЙЋЦНЪаГЁзтН№ЃЌАќРЈЮдЪвЪ§СПЁЂТЅВуЪ§СПЁЂЕиПщУцЛ§КЭжїЬхЕЅЮЛЕФЦНЗНгЂГпУцЛ§ЁЃ

ЕуЛїБъЬтВщдФЭљЦкФкШн

БДвЖЫЙЗжЮЛЪ§ЛиЙщЁЂlassoКЭздЪЪгІlassoБДвЖЫЙЗжЮЛЪ§ЛиЙщЗжЮіУтвпЧђЕААзЁЂЧАСаЯйАЉЪ§Он
01
02

03

04

ФЃаЭЗжЮі
Regularization - Lasso Model

ЪЙгУK-Fold cross validationШЗЖЈзюМбЕФlamdaжЕ:
Ъ§ОнБЛЗжГЩKИіЯрЕШЕФВПЗжЃЌГ§СЫЕкkИіелЕўжЎЭтЕФЫљгаЪ§ОнЖМгУгкбЕСЗФЃаЭЃЌЕкkИіелЕўгУгкВтЪдФЃаЭЃЌМЧТМРыбљБОЭтЕФЦЋВюЁЃ
жиИДДЫЙ§ГЬЃЌвджСУПИіелЕўЖМгаЛњЛсГЩЮЊВтЪдМЏЁЃЕМжТРыбљБОЭтЦЋВюзюаЁЕФlamdaЪЧзюгХlamdaжЕЃЌдкАИР§жаЮвВЩгУK-10ЃК
зюжеМЦЫузюаЁdevianceжаЕФбљБОФкR^2гыЭЈЙ§10 Fold cross validationМЦЫуГіЕФбљБОЭтR^2ЁЃ

зѓВрЪЧЬзЫїе§дђЛЏТЗОЖЕФЛцЭМЁЃЮвУЧПЩвдПДЕНЫцзХlamdaЕФдіМгЃЌЯЕЪ§ж№НЅЧїНќгкСуЁЃ
гвВрЕФЭМБэЯдЪОСЫ10Fold crossvalidationЕФРыбљБОЭтЦЋВюЮѓВюЙРМЦЁЃзюгХlamdaгЩзюзѓБпЕФДЙжБащЯпБэЪОЁЃЭМБэЩЯЕФзюЕЭЕуЪЕМЪЩЯЮЛгкЭМБэЕФзюзѓВрЃЌlamdaЕФжЕзюаЁЁЃ
гыЕфаЭЕФЭМБэВЛЭЌЃЌетИіЭМБэВЛЪЧГЪЁАuаЮЁЃ
дкетжжЧщПіЯТЃЌетвтЮЖзХбЁдёСЫзюИДдгЕФФЃаЭзїЮЊзюгХНтЁЃ

ФЃаЭЗжЮі
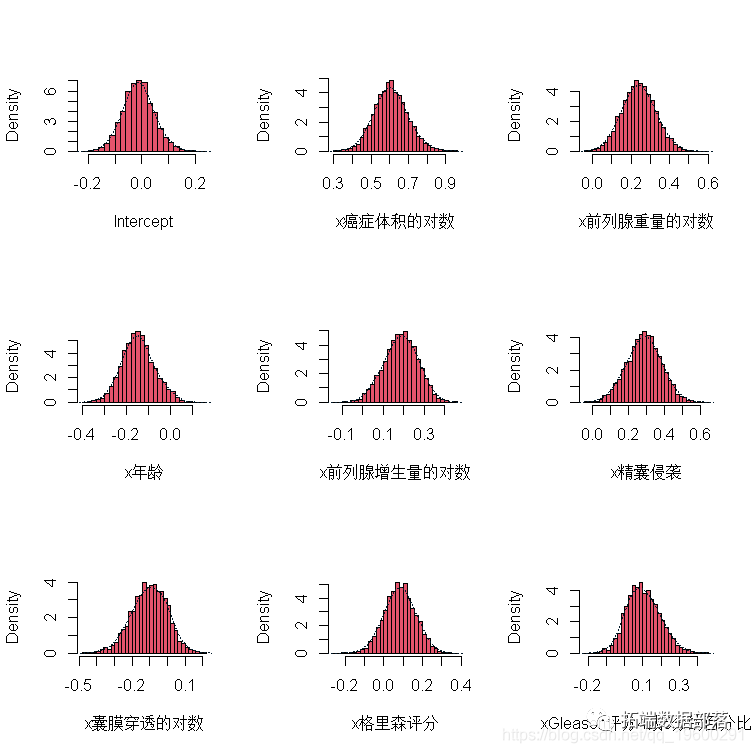
гвЭМЕФжЕБэЪОЗЧСуЯЕЪ§МАЦфжЕЃЌШЁживЊБфСПНјааКЯРэадЗжЮі: ЮдЪвЪ§СП:УПдіМгЁЊИіЮдЪвЃЌдТзтН№МлИёЬьдМдіМг143.51УРдЊЃЌЦфЫћБфСПКЭЬиеїБЃГжВЛБфЁЃетИіжЕЪЧКЯРэЕФЃЌвђЮЊ2ИіЮдЪвЕФЕЅЮЛЕФзтН№МлИёКмПЩФмДѓгк1ИіЮдЪвЕФЕЅЮЛЕФзтН№МлИёЁЃТЅВуЪ§ЕФЯЕЪ§ЪЧИКЪ§:ЖдгкУПдіМгИіТЅВуЕФЕЅЮЛЛђЮявЕЃЌдТзтН№МлИёНЋМѕЩйдМ10.55УРдЊЃЌЦфЫћБфСПКЭЯЕЪ§БЃГжВЛБфЁЃетИіИКЯЕЪ§ЪЧКЯРэЕФЃЌвђЮЊТЅВуЪ§НЯЖрЕФЮявЕИќгаПЩФмЪЧНєДеаЭЕФЁЃ

ФЃаЭЗжЮі
гы10-Fold cross validationЯрБШЃЌЮвЛЙЪЙгУСЫвЛИіМЦЫуЩЯНЯЮЊМђБуЕФЬцДњЗНЗЈЪЧAkaike Information Criterion(AICc)ЁЃ
дкИпЮЌЪ§ОнжаЃЌAICcЧуЯђгкВњЩњЙ§гкИДдгЕФФЃаЭЃЌЕМжТЙ§ФтКЯЁЃШЛЖјЃЌAICcЕУЕНЕФЗЧСуЯЕЪ§МАЦфжЕгыжЎЧАЯрЭЌЁЃ
дкгвЭМжаЃЌЮвУЧеЙЪОСЫдкЮвУЧЕФЧщПіЯТЃЌгЩAIC ЁЂ AICcКЭ10-Fold cross validationбЁдёЕФзюгХlamdaЪЧЯрЭЌЕФЃЌМДКкЩЋЁЂГШЩЋКЭРЖЩЋащЯпжиЕўЕФВПЗж.

змНс
дкжДааLasso RegularizationКѓЃЌЮвУЧПДЕНФЃаЭДгЪ§ОнМЏжабЁдёСЫ186ИіБфСПжаЕФ76ИіБфСПЁЃЕЋгавЛаЉживЊБфСПЕиУЛгаАќКЌдкФЃаЭжаЃЌР§ШчжїЬхЮявЕЕФНЈдьФъЗнКЭдЁЪвЪ§СПЃЌвђЮЊЦфжаШБЪЇСЫДѓСПЕФЙлВтжЕЁЃ
вђЮЊЪ§ОнШБЪЇНЯЖрЫљвдФЃаЭжЛФмгУзїПЭЙлдЄВтЃЌВЛФмКмКУЕФЗДгІИїИіБфСПжЎМфЕФЯрЙиадЃЌ дкЪ§ОнЧхРэЗНУцЃЌбЁдёШЅГ§КЌ50%МАвдЩЯЪ§ОнШБЪЇЕФБфСПвВЪЧвЛИіашвЊШЈКтЕФЗНЯђЃЌвђЮЊетИіУХМїбЁдёЬЋЕЭгжПЩФмЕМжТЪ§ОнЩйЮоЗЈе§ШЗЗДгІБфСПжЎМфЕФЙиЯЕзїгУЃЌЖјУХМїЬЋИпОЭЛсГіЯжУЛАьЗЈбЁдёЕНвЛаЉБШНЯживЊЕФБфСПЁЃ
ДЫФЃаЭВЛОпБИздЪЪгІадЃЌЫљвдашвЊаТЪ§ОнЕФИќаТжЇГжВХФмИќКУЕФБЃжЄЦфдЄВтЕФзМШЗадЁЃ

