ШЋЮФСДНгЃКhttp://tecdat.cn/?p=32604
ЗжЮіЪІЃКBailey ZhengКЭLijie Zhang
МДЪЙЪЧЭЌвЛжжжВЮяЃЌгЩгкЩњГЄЕФЕиРэЛЗОГЕФВЛЭЌЃЌЫќУЧЕФЬиеїЛсгаЫљВювьЁЃР§Шч№АЮВЛЈЃЌПЩЗжЮЊЩН№АЮВЁЂдгЩЋ№АЮВЁЂЮЌМЊФсбЧ№АЮВЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
МйЩшДЫЪБФњЕУЕНСЫвЛЖф№АЮВЛЈЃЌШчКЮХаЖЯЫќЪєгкФФвЛРрФи?

жЇГжЯђСПЛњЫуЗЈдРэ
ЁЄЦфжївЊЫМЯыЪЧевЕНПеМфжаЕФвЛИіФмЙЛНЋЫљгаЪ§ОнбљБОЛЎПЊЕФГЌЦНУцЃЌВЂЧвЪЙЕУбљБОМЏжаЫљгаЪ§ОнЕНетИіГЌЦНУцЕФОрРызюЖЬЁЃ
ЁЄжЇГжЯђСПЛњПЩвдЗжЮЊЯпадКЭЗЧЯпадСНДѓРрЁЃ

жЇГжЯђСПЛњЕФБъзМ:

ЗЧЯпаджЇГжЯђСПЛњ
ЁЄИпЫЙКЫ:ГпЖШВЮЪ§gamma
ЁЄЖрЯюЪНКЫ:НзЪ§degree
ЃЈЯпаджЇГжЯђСПЛњ:е§дђЛЏВЮЪ§C) ЕїВЮ

Ъ§ОнжИБъ:
SLЛЈз№ГЄЖШ(cm) ,SWЛЈмКПэЖШ(cm)PLЛЈБцГЄЖШЃЈcm),PWЛЈАъПэЖШЃЈcm)№АЮВЛЈжжРр: Iris Setosa;
Iris Versicolour;Iris Virginica
Ъ§ОнЪ§СП:ЙВ150ИіЪ§ОнЕу
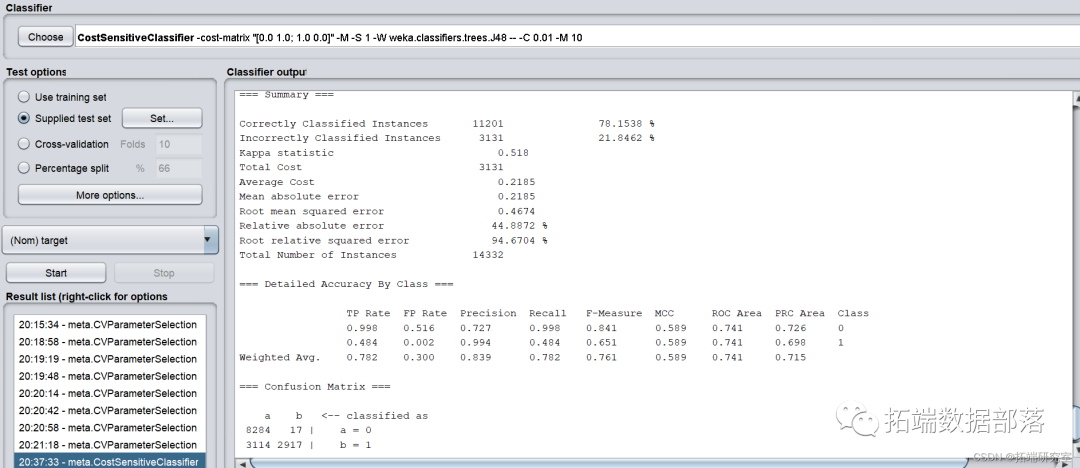
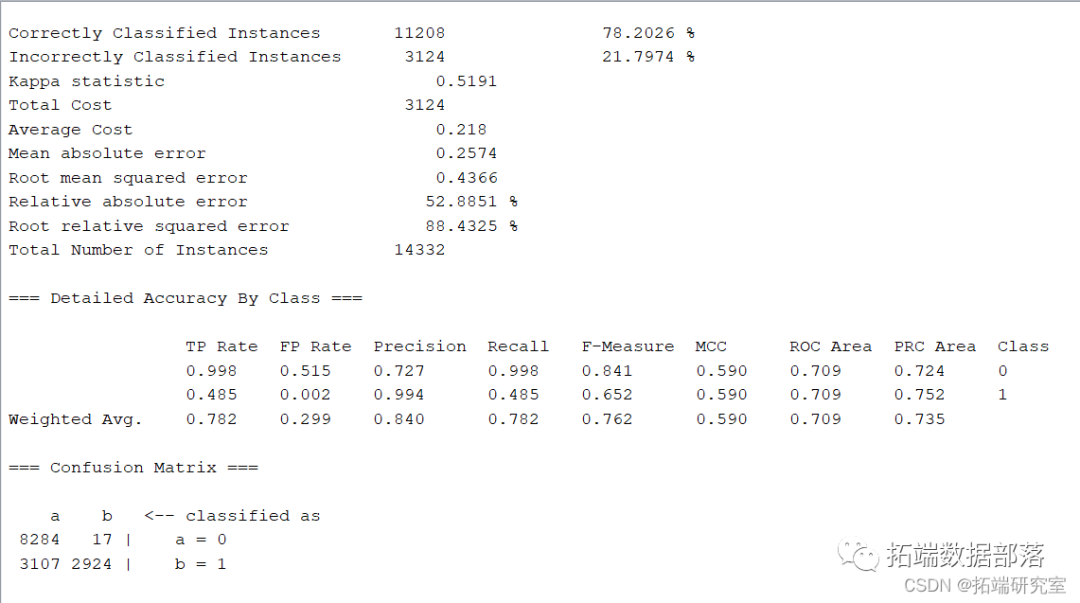
ЪЙгУЖрЯюЪНКЫКЏЪ§ЕФЗЧЯпаджЇГжЯђСПЛњбЕСЗЗжРрФЃаЭ

ЕуЛїБъЬтВщдФЭљЦкФкШн

Ъ§ОнЗжЯэ|WEKAаХДћЮЅдМдЄВтБЈИцЃКгУОіВпЪїЁЂЫцЛњЩСжЁЂжЇГжЯђСПЛњSVMЁЂЦгЫиБДвЖЫЙЁЂТпМЛиЙщ
01

02
03
04

PythonгУЛЇСїЪЇЪ§ОнЭкОђЃКНЈСЂжЇГжЯђСПЛњЁЂТпМЛиЙщЁЂXGboostЁЂЫцЛњЩСжЁЂОіВпЪїЁЂЦгЫиБДвЖЫЙФЃаЭКЭKmeansгУЛЇЛЯё
дкНёЬьВњЦЗИпЖШЭЌжЪЛЏЕФЦЗХЦгЊЯњНзЖЮЃЌЦѓвЕгыЦѓвЕжЎМфЕФОКељМЏжаЕиЬхЯждкЖдПЭЛЇЕФељЖсЩЯ
ЁАгУЛЇОЭЪЧЩЯЕлЁБДйЪЙжкЖрЕФЦѓвЕВЛЯЇДњМлШЅељЖсОЁПЩФмЖрЕФПЭЛЇЁЃЕЋЪЧЦѓвЕдкВЛЯЇДњМлЗЂеЙаТгУЛЇЕФЙ§ГЬжаЃЌЭљЭљЛсКіЪгЛђЮоЯОЙЫМАвбгаПЭЛЇЕФСїЪЇЧщПіЃЌНсЙћОЭЕМжТГіЯжетбљвЛжжОНПіЃКвЛБпЪЧаТПЭЛЇдкдДдДВЛЖЯЕидіМгЃЌЖјСэвЛЗНУцЪЧаСаСПрПревРДЕФПЭЛЇШДдкЧФШЛЮоЩљЕиСїЪЇЁЃвђДЫЖдРЯгУЛЇЕФСїЪЇНјааЪ§ОнЗжЮіДгЖјЭкОђГіживЊаХЯЂАяжњЦѓвЕОіВпепВЩШЁДыЪЉРДМѕЩйгУЛЇСїЪЇЕФЪТЧщжСЙиживЊЃЌЦШдкУМНоЁЃ

1.2 ФПЕФЃК
ЩюШыСЫНтгУЛЇЛЯёМАааЮЊЦЋКУЃЌЭкОђГігАЯьгУЛЇСїЪЇЕФЙиМќвђЫиЃЌВЂЭЈЙ§ЫуЗЈдЄВтПЭЛЇЗУЮЪЕФзЊЛЏНсЙћЃЌДгЖјИќКУЕиЭъЩЦВњЦЗЩшМЦЁЂЬсЩ§гУЛЇЬхбщЁЃ
1.3 Ъ§ОнЫЕУїЃК
ДЫДЮЪ§ОнЪЧаЏГЬгУЛЇвЛжмЕФЗУЮЪЪ§ОнЃЌЮЊБЃЛЄПЭЛЇвўЫНЃЌвбОНЋЪ§ОнОЙ§СЫЭбУєЃЌКЭЪЕМЪЩЬЦЗЕФЖЉЕЅСПЁЂфЏРРСПЁЂзЊЛЏТЪЕШгавЛаЉВюОрЃЌВЛгАЯьЮЪЬтЕФПЩНтадЁЃ
2 ЖСШЁЪ§Он
# ЯдЪОШЋВПЬиеї df.head()

3 ЧаЗжЪ§Он
# ЛЎЗжбЕСЗМЏЃЌВтЪдМЏ X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
3.1 РэНтЪ§Он
ПЩвдПДЕНБфСПБШНЯЕФЖрЃЌЯШНјааЗжРрЃЌГ§ШЅФПБъБфСПlabelЃЌДЫЪ§ОнМЏЕФзжЖЮПЩвдЗжГЩШ§ИіРрБ№ЃКЖЉЕЅЯрЙижИБъЁЂПЭЛЇааЮЊЯрЙижИБъЁЂОЦЕъЯрЙижИБъЁЃ


4 ЬиеїЙЄГЬ
# гУбЕСЗМЏНјааЪ§ОнЬНЫї train = pd.concat([X_train,y_train],axis=1)
4.1 Ъ§ОндЄДІРэ


4.1.1 ЩОГ§ВЛБивЊЕФСа
X_train.pop("sampleid") X_test.pop("sampleid") train.pop("sampleid")
4.1.2 Ъ§ОнРраЭзЊЛЛ
зжЗћДЎРраЭЕФЬиеїашвЊДІРэГЩЪ§жЕаЭВХФмНЈФЃ,НЋarrivalКЭdЯрМѕЕУЕН"ЬсЧАдЄЖЈЕФЬьЪ§",зїЮЊаТЕФЬиеї
# діМгСа # НЋСНИіШеЦкБфСПгЩзжЗћДЎзЊЛЛЮЊШеЦкИёЪНРраЭ train["arrial"] = pd.to_datimetain["arrval"]) X_tst["arival"] = d.to_daetime(X_est["arival"]) # ЩњГЩЬсЧАдЄЖЈЪБМфСаЃЈбмЩњБфСПЃЉ X_trin["day_adanced"] = (X_rain["arival"]-Xtrain["d"]).dt.days ## ЩОГ§Са X_tran.dro(columns="d","arrivl"],inpace=True)
4.1.3 ШБЪЇжЕЕФБфСПЩњГЩвЛИіжИЪОбЦБфСП
zsl = tain.isnll().sum()[tain.isnll(.sum()!=0].inex
4.1.4 ИљОнвЕЮёОбщЬюВЙПеШБжЕ
ordernum_oneyear гУЛЇФъЖЉЕЅЪ§ЮЊ0 ,lasthtlordergap 11%гУ600000ЬюГф 88%гУ600000ЬюГф вЛФъФкОрРыЩЯДЮЯТЕЅЪБГЄ,ordercanncelednum гУ0ЬюГф гУЛЇвЛФъФкШЁЯћЖЉЕЅЪ§,ordercanceledprecent гУ0tЬюГф гУЛЇвЛФъФкШЁЯћЖЉ
ЕЅТЪ 242114 242114 -ЮЊПе га2жжЧщПі 1ЃКаТгУЛЇЮДЯТЖЉЕЅЕФПе-88.42% 214097 2.РЯгУЛЇ1ФъвдЩЯЮДЯћЗбЕФПе діМгБрТыСаЮДЯТЖЉЕЅаТгУЛЇКЭ 1ФъЮДЯТЖЉЕЅЕФРЯгУЛЇ
price_sensitive -0 ,жаЮЛЪ§ЬюГф МлИёУєИажИЪ§,consuming_capacity -0 жаЮЛЪ§ЬюГф ЯћЗбФмСІжИЪ§ 226108 -ЮЊПеЧщПі 1.ДгЮДЯТЙ§ЕЅЕФаТгУЛЇ214097 2.12011ИіШЫЮЊПедвђднВЛУїШЗ
uv_pre -24аЁЪБРњЪЗфЏРРДЮЪ§зюЖрОЦЕъРњЪЗuv. cr_pre -0,жаЮЛЪ§ЬюГф -24аЁЪБРњЪЗфЏРРДЮЪ§зюЖрОЦЕъРњЪЗcr -0,жаЮЛЪ§ЬюГф 29397 -ЮЊПе 1.гУЛЇЕБЬьЮДЕЧТМAPP 28633 2.ИеЩЯЯпЕФаТОЦЕъ178 586 ЮоuvЃЌcrМЧТМ БрТыЬэМг ИУAPPИеЩЯЯпЕФаТОЦЕъ 764 29397
customereval_pre2 гУ0ЬюГф-24аЁЪБРњЪЗфЏРРОЦЕъПЭЛЇЦРЗжОљжЕ, landhalfhours -24аЁЪБФкЕЧТНЪБГЄ -гУ0ЬюГф28633 -ЮЊПеЃКгУЛЇЕБЬьЮДЕЧТМAPP 28633
hotelcr ,hoteluv -жаЮЛЪ§ЬюГф 797
ЁОЪгЦЕЁПжЇГжЯђСПЛњЫуЗЈдРэКЭPythonгУЛЇСїЪЇЪ§ОнЭкОђSVMЪЕР§ЃЈЯТЃЉЃК/article/1496761
