RгябдAprioriЫуЗЈЙиСЊЙцдђЖджавЉгУвЉИДЗНХфЮщЙцТЩвЉЗНЭкОђПЩЪгЛЏЃЈЩЯЃЉ:/article/1496501
ВщПДзюИпЕФжЇГжЖШбљБОЙцдђ
ules::inspect(head(rules
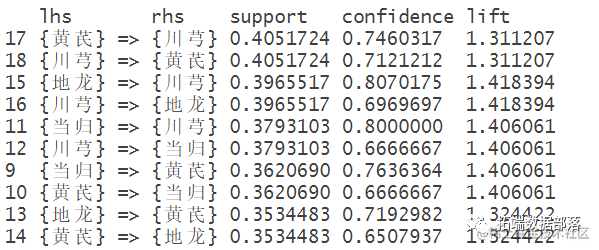
ВщПДзюИпжУаХЖШбљБОЙцдђ
sort(rules, by="confidenc nspect(head(rules

sort(rules, by="lift

ЕУЕНгаМлжЕЙцдђзгМЏ
rules,subset=confidence>0.3 & support>0.2 & lift>=1 summary(x)

АДеежЇГжЖШХХађ
sort(x,by="support

АДеежУаХЖШХХађ
inspect(sort(x,by="confide

ЖдгаМлжЕЕФxМЏКЯНјааЪ§ОнПЩЪгЛЏЁЃ
method="grouped")

зщКЯЭкОђ
at(dat1,parameter=list(support=0.22,minlen=3,maxle

ЕУЕНЦЕЗБЙцдђЭкОђ
nspect(frequents

ВщПДЧѓЕУЕФЦЕЗБЯюМЏ
nspect(sort(frequentsets,by="sup

ИљОнжЇГжЖШЖдЧѓЕУЕФЦЕЗБЯюМЏХХађВЂВщПДЃЈЕШМлгкinspect(sort(frequentsets)[1:10]ЃЉ
НЈСЂФЃаЭ
apriori(dat1,parameter=list(support=0.24

ЩшжУжЇГжЖШЮЊ0.01ЃЌжУаХЖШЮЊ0.3ЁЃ
summary(rules)#ВщПДЙцдђ

ВщПДВПЗжЙцдђ

ВщПДжУаХЖШЁЂжЇГжЖШКЭЬсЩ§ЖШ
ПЩЪгЛЏ





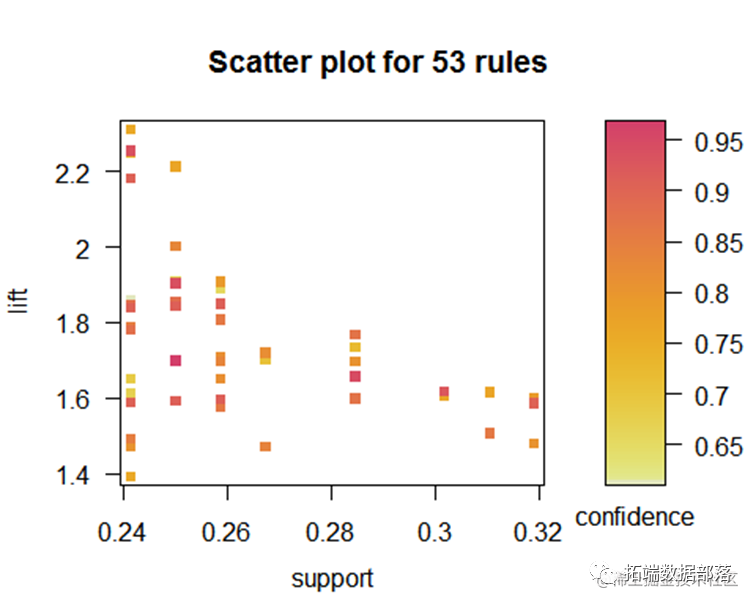
ДгИУЭМПЩвдПДЕНжЇГжЖШКЭжУаХЖШЕФЙиЯЕЃЌЬсЩ§ЖШдНИпжУаХЖШвВдНИпЁЃ



ВщПДзюИпЕФжЇГжЖШбљБОЙцдђ

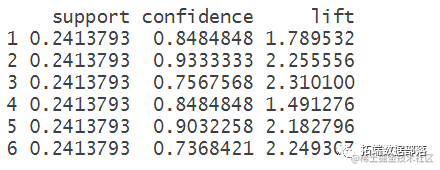
ВщПДзюИпжУаХЖШбљБОЙцдђ

ВщПДзюИпЬсЩ§ЖШбљБОЙцдђ

confidence>0.3 & support>0.3 & lift>=1) #ЕУЕНгаМлжЕЙцдђзгМЏ summary(x)

aspect(sort(x,by="support")) #АДеежЇГжЖШХХађ ## lhs rhs support confidence lift ## 45 {ДЈмК,ЛЦмЮ} => {ЕиСњ} 0.3189655 0.7872340 1.602090 ## 43 {ЕиСњ,ЛЦмЮ} => {ДЈмК} 0.3189655 0.9024390 1.586105 ## 44 {ДЈмК,ЕиСњ} => {ЛЦмЮ} 0.3189655 0.8043478 1.481021 ## 42 {ДЈмК,ЛЦмЮ} => {ЕБЙщ} 0.3103448 0.7659574 1.615474 ## 41 {ДЈмК,ЕБЙщ} => {ЛЦмЮ} 0.3103448 0.8181818 1.506494 ## 40 {ЕБЙщ,ЛЦмЮ} => {ДЈмК} 0.3103448 0.8571429 1.506494 ## 37 {ЕБЙщ,ЕиСњ} => {ДЈмК} 0.3017241 0.9210526 1.618820 ## 38 {ДЈмК,ЕБЙщ} => {ЕиСњ} 0.3017241 0.7954545 1.618820 ## 39 {ДЈмК,ЕиСњ} => {ЕБЙщ} 0.3017241 0.7608696 1.604743 pect(sort(x,by="confidence")) #АДеежУаХЖШХХађ ## lhs rhs support confidence lift ## 37 {ЕБЙщ,ЕиСњ} => {ДЈмК} 0.3017241 0.9210526 1.618820 ## 43 {ЕиСњ,ЛЦмЮ} => {ДЈмК} 0.3189655 0.9024390 1.586105 ## 40 {ЕБЙщ,ЛЦмЮ} => {ДЈмК} 0.3103448 0.8571429 1.506494 ## 41 {ДЈмК,ЕБЙщ} => {ЛЦмЮ} 0.3103448 0.8181818 1.506494 ## 44 {ДЈмК,ЕиСњ} => {ЛЦмЮ} 0.3189655 0.8043478 1.481021 ## 38 {ДЈмК,ЕБЙщ} => {ЕиСњ} 0.3017241 0.7954545 1.618820 ## 45 {ДЈмК,ЛЦмЮ} => {ЕиСњ} 0.3189655 0.7872340 1.602090 ## 42 {ДЈмК,ЛЦмЮ} => {ЕБЙщ} 0.3103448 0.7659574 1.615474 ## 39 {ДЈмК,ЕиСњ} => {ЕБЙщ} 0.3017241 0.7608696 1.604743
ЖдгаМлжЕЕФxМЏКЯНјааЪ§ОнПЩЪгЛЏ



