дЮФСДНгЃКhttp://tecdat.cn/?p=5312
дкБОЮФжаЃЌЮвУЧЭЈЙ§вЛИіУћЮЊWinBUGSЕФУтЗбБДвЖЫЙШэМўЃЌПЩвдКмШнвзЕиЭъГЩЛљгкЫЦШЛЕФЖрБфСПЫцЛњВЈЖЏТЪЃЈSVЃЉФЃаЭЕФЙРМЦКЭБШНЯЁЃЭЈЙ§ФтКЯУПжмЛуТЪЕФЫЋБфСПЪБМфађСаЪ§ОнЃЌЖрБфСПSVФЃаЭЃЌАќРЈВЈЖЏТЪжаЕФИёРМНмвђЙћЙиЯЕЃЌЪББфЯрЙиадЃЌжиЮВЮѓВюЗжВМЃЌМгадвђзгНсЙЙКЭГЫЗЈвђзгНсЙЙРДЫЕУїЯыЗЈЁЃ
ЕЅБфСПЫцЛњВЈЖЏТЪЃЈSVЃЉФЃаЭЮЊARCHРраЭФЃаЭЬсЙЉСЫгааЇЕФЬцДњЗНАИЃЌПЩвдНтЪЭВЈЖЏТЪЕФЬѕМўКЭЮоЬѕМўЪєадЁЃ
ЖрдЊSVФЃаЭ
Н№ШкзЪВњЪевцЕФГЬЪНЛЏЪТЪЕ
ПМТЧЕНЖрБфСПSVФЃаЭЖдгкУшЪіН№ШкзЪВњЪевцЕФЖЏЬЌзюгагУЃЌЮвУЧЪзЯШзмНсвЛаЉМЧТМСМКУЕФН№ШкзЪВњЪевцЕФГЬЪНЛЏЪТЪЕЃК
- зЪВњЪевцЗжХфЪЧМтЗхКёЮВЬиеїЁЃ
- зЪВњЪевцТЪВЈЖЏТЪМЏШКЁЃ
- ЪевцТЪЪЧНЛВцЯрЙиЕФЁЃ
- ВЈЖЏадЪЧНЛВцвРРЕЕФЁЃ
- вЛжжзЪВњИёРМНмЕФВЈЖЏЕМжТСэвЛжжзЪВњЕФВЈЖЏЁЃ
- ЭЈГЃДцдкНЯЕЭЮЌЖШвђзгНсЙЙЃЌПЩвдНтЪЭДѓВПЗжЯрЙиадЁЃ
- ЯрЙиадЪЧЫцЪБМфБфЛЏЕФЁЃ
Г§СЫетЦпИіЪТЪЕжЎЭтЃЌжюШчВЮЪ§ПеМфЕФЮЌЪ§КЭаЗНВюОиеѓЕФе§АыШЗЖЈаджЎРрЕФЮЪЬтОпгаЪЕМЪживЊадЁЃЕБЮвУЧЩѓВщЯжгаФЃаЭВЂНщЩмЮвУЧЕФаТФЃаЭЪБЃЌЮвУЧНЋЦРТлЫќУЧДІРэГЬЪНЛЏЪТЪЕКЭЩЯЪіСНИіЮЪЬтЕФЪЪЕБадЁЃ
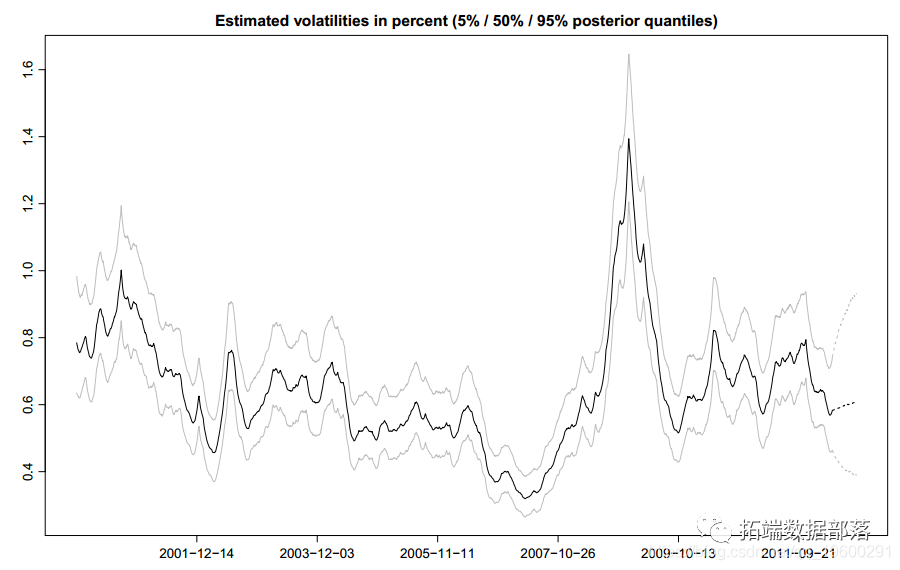
ЮЊСЫЫЕУїЬцДњЖрБфСПSVФЃаЭжЎМфЕФВювьКЭСЊЯЕЃЌЮвУЧЙизЂБОЮФжаЕФЫЋБфСПЧщПіЁЃЬиБ№ЪЧЃЌЮвУЧПМТЧСЫОХжжВЛЭЌЕФЫЋБфСПSVФЃаЭЃЈДјДжЬхЕФЪззжФИЫѕТдДЪЃЉЁЃДЫЭтЃЌетаЉФЃаЭжаЕФДѓЖрЪ§ЖМЪЪгУгкЖрЮЌБфСПЃЌЖјФЃаЭ5ЪЧЮЈвЛЕФР§ЭтЁЃ
ФЃаЭ1ЃЈЛљБОMSVЛђMSVЃЉЁЃ ИУФЃаЭЯрЕБгкНЋСНИіЛљБОЕЅБфСПSVФЃаЭзщКЯдквЛЦ№ЁЃЯдШЛЃЌИУФЃаЭВЛдЪаэНЛВцЪевцЛђВЈЖЏТЪжЎМфЕФЯрЙиадЃЌвВВЛдЪаэGrangerвђЙћЙиЯЕЁЃЕЋЪЧЃЌЫќдЪаэМтЗхКёЮВЬиеїЪевцТЪЗжВМКЭВЈЖЏТЪОлРрЁЃ
ФЃаЭ2ЃЈГЃЪ§ЯрЙиMSVЛђCC-MSVЃЉ дкИУФЃаЭжаЃЌдЪаэЪевцТЪГхЛїЯрЙиЃЌвђДЫИУФЃаЭРрЫЦгкBollerslevЕФГЃЪ§ЬѕМўЯрЙиЃЈCCCЃЉARCHФЃаЭЁЃвђДЫЃЌЪевцТЪЪЧЯрЛЅвРРЕЕФЁЃ
ФЃаЭ3ЃЈОпгаИёРМНмвђЙћЙиЯЕЛђGC-MSVЕФMSVЃЉЁЃ гЩгкІе 21ПЩвдЪЧВЛЭЌгкСуЃЌЕкЖўзЪВњЕФВЈЖЏдЪаэЪЧИёРМНмгЩЕквЛзЪВњЕФВЈЖЏЁЃвђДЫЃЌЪевцТЪКЭВЈЖЏТЪЖМЪЧЯрЛЅвРРЕЕФЁЃШЛЖјЃЌВЈЖЏТЪЕФНЛВцвРРЕадЪЧЭЈЙ§ИёРМНмвђЙћЙиЯЕКЭВЈЖЏТЪОлРрЙВЭЌЪЕЯжЕФЁЃДЫЭтЃЌЕБСНИіІе 12КЭІе 21ЪЧЗЧСуЃЌдкСНжжзЪВњжЎМфВЈЖЏЫЋЯђGrangerвђЙћЙиЯЕЪЧдЪаэЕФЁЃОнЮвУЧЫљжЊЃЌИУФЃаЭЪЧSVЮФЯзЕФаТдіФкШнЁЃ
ЪЙгУWinBUGSНјааБДвЖЫЙЙРМЦ
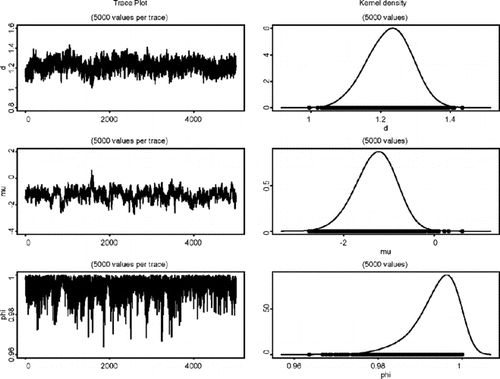
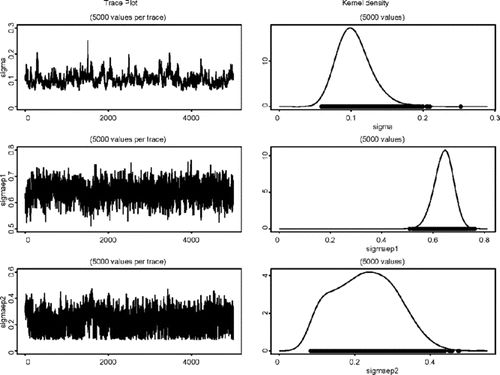
ФЃаЭЭЈЙ§ЖдЫљгаЮДжЊВЮЪ§a =ЃЈ_a 1ЃЌ...ЃЌ_a __p_ЃЉЕФЯШбщЗжВМЕФЩшжУРДЭъГЩЁЃР§ШчЃЌдкФЃаЭ1ЃЈMSVЃЉжаЃЌ_p = 6КЭЮДжЊВЮЪ§ЕФЪИСПaЁЃБДвЖЫЙЭЦЖЯЛљгкФЃаЭжаЫљгаЮДЙлВьСПІШЕФСЊКЯКѓбщЗжВМЁЃЪИСПІШАќРЈЮДжЊВЮЪ§КЭЧБдкЖдЪ§ВЈЖЏТЪЕФЪИСПЃЌМДІШ =ЃЈaЃЌh 1ЃЌ...ЃЌh _T_ЃЉЁЃ
ЪЕжЄЫЕУї
Ъ§Он
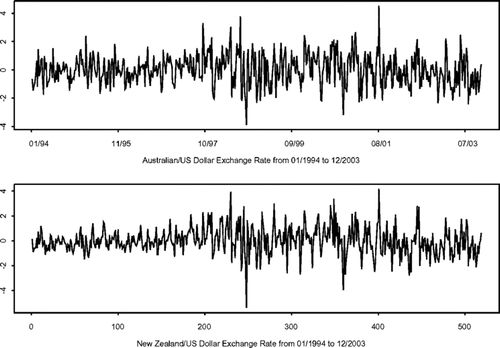
дкБОНкжаЃЌЮвУЧНЋНщЩмЕФФЃаЭФтКЯЪЕМЪОМУЪБМфађСаЪ§ОнЁЃДг1994Фъ1дТЕН2003Фъ12дТЃЌЫљЪЙгУЕФЪ§ОнЪЧУПжмАФДѓРћбЧКЭаТЮїРМЛуТЪЕФЦНОљЕїећЖдЪ§ЪевцТЪЁЃетСНИіађСаЕФбЁдёЪЧвђЮЊетСНИіОМУЬхБЫДЫНєУмЯрСЌЃЌвђДЫ_ЪТЯШ_дЄМЦСНжжЛуТЪжЎМфЕФвРРЕадКмЧПЁЃетСНИіЯЕСадкЭМжаЛцжЦЃЌЦфжаЪевцТЪКЭВЈЖЏТЪЕФНЛВцвРРЕадШЗЪЕЯдЕУКмЧПЁЃ
ЛуТЪЪевцТЪЕФЪБМфађСаЭМЁЃ
ЕуЛїБъЬтВщдФЭљЦкФкШн

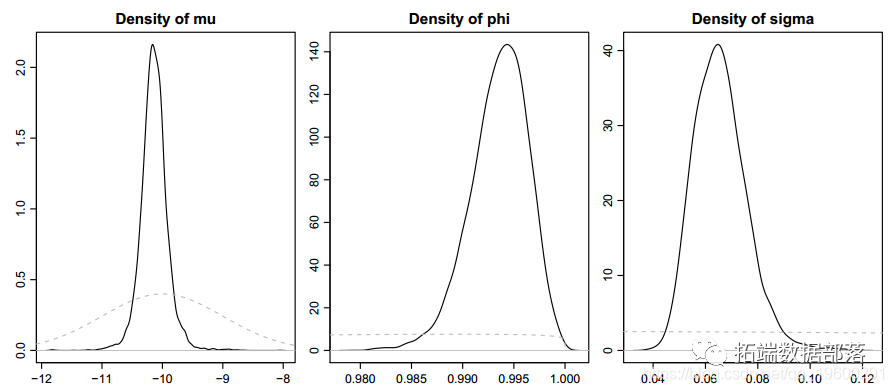
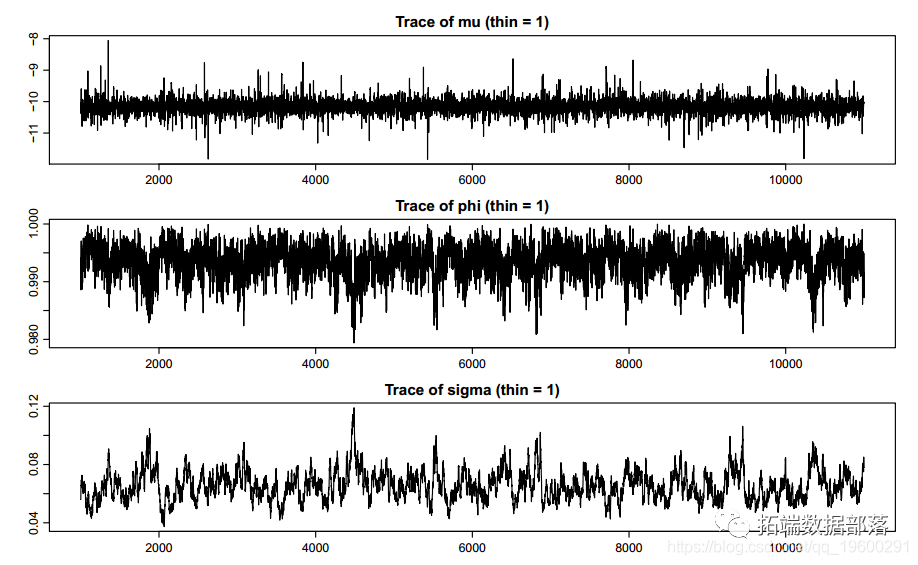
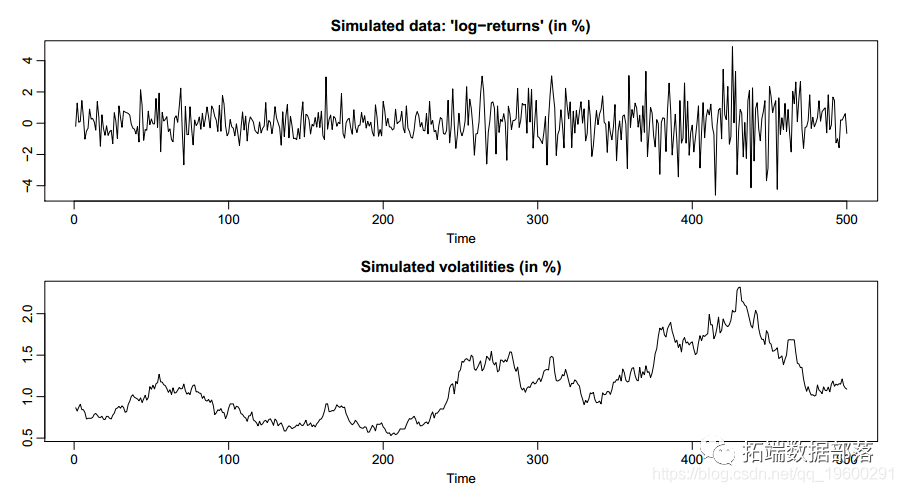
ЪЙгУRгябдЫцЛњВЈЖЏФЃаЭSVДІРэЪБМфађСажаЕФЫцЛњВЈЖЏТЪ
01
02
03
04
Basis MSV
ЛљДЁmsv

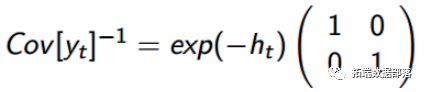
гЩгкЗЧБъзМЛЏЕФВЮЪ§ЩшжУЃЌФЃФт
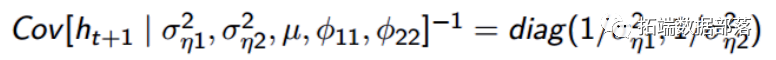
ДњТыЦЌЖЮЃК
model volatility; {for (i in 1:N) { Yisigma2a\[i\] <- exp(-th\[i,1\]); Yisigma2b\[i\] <- exp(-th\[i,2\]); Y\[i,1\]~ dnorm(0,Yisigma2a\[i\]); Y\[i,2\]~ dnorm(0,Yisigma2b\[i\] th\[1,1\]~dnorm(thmean\[1,1\],itaua2); th\[1,2\]~dnorm(thmean\[1,2\],itaub2 for (i in 2:N) { thmean\[i,1\] <- mu1 + phi1*(th\[i-1,1\]-mu1); thmean\[i,2\] <- mu2 + phi2*(th\[i-1,2\]-mu2
MSV Granger Causality GC-MSV
ДњТыЦЌЖЮЃК
model volatility; { for (i in 1:N) { ysigmadet\[i\]<-exp(th\[i,1\]+th\[i,2\])*(1-rhoep*rhoep; Yisigma2\[i,1,1\] <- exp(th\[i,2\])/ysigmadet\[i; Yisigma2\[i,2,1\] <- Yisigma2\[i,1,2; for (i in 2:N) { thmean\[i,1\] <- mu1 + phi1*(th\[i-1,1\]-mu1)+phi12*(th\[i-1,2\]-mu2); thmean\[i,2\] <- mu2 + phi2*(th\[i-1,2\]-mu2)
НсЙћ
ЮвУЧБЈИцЧАСљИіФЃаЭЕФКѓбщЗжВМЕФЦНОљжЕЃЌБъзМЮѓВюКЭ95ЃЅПЩаХЧјМфвдМАзюКѓШ§ИіФЃаЭЕФКѓбщЗжВМЃЌвдМАЮЊОХИіжаЕФУПвЛИіЩњГЩ100ДЮЕќДњЕФМЦЫуЪБМфЁЃ
ФЃаЭЃЈAFactor-t-MSVЃЉжа_d_ЃЌІЬКЭІе ЕФБпдЕЗжВМЕФЧњЯпЭМКЭУмЖШЙРМЦжЕЁЃ
ІвЕФБпдЕЗжВМЕФУмЖШЙРМЦІЧЃЌІв ІХ1 ЃЌКЭІв ІХ2дкФЃаЭЃЈAFactor MSVЃЉЁЃ
ІЭЕФБпдЕЗжВМЕФУмЖШЙРМЦ1ЃЌІЭ 2ЃЌКЭІидкФЃаЭЃЈAFactor MSVЃЉЁЃ

ЫљгаФЃаЭЕФDIC
ЮЊСЫИќКУЕиРэНтФЃаЭЖЈвхЕФКЌвхЃЌЮвУЧЛёЕУСЫФЃаЭЃЈAFactor-t-MSVЃЉКЭФЃаЭЃЈDC-MSVЃЉЕФВЈЖЏТЪКЭЯрЙиадЕФЦНЛЌЙРМЦЁЃ
НсТл
дкБОЮФжаЃЌЮвУЧЬсГіЭЈЙ§WinBUGSЪЙгУБДвЖЫЙMCMCММЪѕЙРМЦКЭБШНЯЖрБфСПSVФЃаЭЁЃMCMCЪЧвЛжжЙІФмЧПДѓЕФЗНЗЈЃЌгыЦфЫћЗНЗЈЯрБШОпгааэЖргХЪЦЁЃЕЋЪЧЃЌБраДгУгкЙРМЦЖрБфСПSVФЃаЭЕФЕквЛИіMCMCГЬађВЂВЛШнвзЃЌВЂЧвБШНЯЬцДњЕФЖрБфСПSVЙцЗЖдкМЦЫуЩЯЪЧИДдгЕФЁЃWinBUGSЧПМгСЫвЛИіМђЖЬЖјУєШёЕФбЇЯАЧњЯпЁЃдкЫЋБфСПЩшжУжаЃЌЮвУЧБэУїЦфЪЕЯжМђЕЅЧвМЦЫуЫйЖШЯрЕБПьЁЃДЫЭтЃЌДІРэЗсИЛЕФФЃаЭвВЗЧГЃСщЛюЁЃШЛЖјЃЌгЩгкWinBUGSЬсЙЉGibbsВЩбљЫуЗЈЃЌЮвУЧЗЂЯжЛьКЯВЩбљЭЈГЃКмТ§ЃЌвђДЫашвЊГЄЪБМфВЩбљЁЃ