ВЮЪ§МьбщЪмжЦгкЪ§ОнЪєадЕФМйЩшЁЃР§ШчЃЌtМьбщЪЧжкЫљжмжЊЕФВЮЪ§МьбщЃЌМйЩшбљБООљжЕОпгае§ЬЌЗжВМЁЃгЩгкжааФМЋЯоЖЈРэЃЌШчЙћбљБОСПзуЙЛЃЌВтЪдвВПЩвдгІгУгкЗЧе§ЬЌЗжВМЕФВтСПЁЃдкетРяЃЌЮвУЧНЋбаОПtМьбщгааЇЫљашЕФДѓжТбљБОЪ§ЁЃ
НЋе§ЬЌЗжВМФтКЯЕНВЩбљОљжЕ
ЮЊСЫбаОПТњзуtМьбщвЊЧѓЫљашЕФбљБОЪ§СПЃЌЮвУЧЕќДњИїжжбљБОСПЁЃЖдгкУПИібљБОДѓаЁЃЌЮвУЧДгМИИіЗжВМжаГщШЁбљБОЁЃШЛКѓЃЌМЦЫубљБОЕФЦНОљжЕЃЌВЂНЋе§ЬЌЗжВМФтКЯЕНЦНОљжЕЕФЗжВМЁЃдкУПДЮЕќДњжаЃЌЮвУЧМЧТМУшЪіе§ЬЌЗжВМгыВЩбљОљжЕФтКЯГЬЖШЕФЖдЪ§ЫЦШЛЁЃЕБЖдЪ§ЫЦШЛБфЮЊе§ЪБЃЌЮвУЧНЋПМТЧВЩбљОљжЕНгНќе§ЬЌЗжВМЁЃ
ФтКЯЕФИХТЪ
ЕїВщНсЙћЃЌЮвУЧПЩвдПДЕНвЛаЉЗжВМЫЦКѕБШЦфЫћЗжВМИќПьЕиНгНќе§ЬЌЗжВМЃК
print(result) ## Sample_Size Beta Normal Chi Poisson Student ## 1 5 694.9139 -299.81161 -496.33474 -702.94076 -1971.203 ## 2 10 823.0384 -126.68806 -297.08253 -515.18702 -3806.447 ## 3 15 909.4417 -30.63266 -199.77525 -455.64737 -2119.944 ## 4 20 1045.1414 46.45709 -136.21868 -375.75690 -2263.025 ## 5 50 1235.7655 278.66189 84.44694 -117.56140 -3427.721 ## 6 100 1397.7265 443.81523 281.68706 47.87537 -2178.871 ## 7 1000 1996.2198 1019.70692 845.26837 619.25871 -3636.674 ## 8 5000 2398.4267 1402.41433 1260.47873 1018.24454 -3231.983
ИљОне§ЖдЪ§ЫЦШЛЃЌІТЗжВМВњЩњЕФе§ЬЌЗжВМОљжЕвбОЮЊ5ЕФбљБОДѓаЁЁЃе§ЬЌЗжВМЃЌПЈЗНЗжВМКЭВДЫЩЗжВМдкбљБОДѓаЁЗжБ№ЮЊ20,50КЭ100ЪБВњЩње§ЬЌЗжВМОљжЕЁЃзюКѓЃЌбЇЩњЗжВМЕФЗНЪНгРдЖВЛЛсе§ГЃЃЌвђЮЊОпгавЛИіздгЩЖШЕФЗжВМОпгаЮоЯоЕФЗхЖШЃЈЗЧГЃжиЕФЮВВПЃЉЃЌЪЙЕУжааФМЋЯоЖЈРэВЛГЩСЂЁЃ
бщжЄЖдЪ§ЫЦШЛБъзМ
зїЮЊНсЙћЕФбщжЄЃЌШУЮвУЧЛцжЦбљБОДѓаЁЮЊ5ЕФжБЗНЭМКЭЦНОљЗжВМБфЮЊе§ГЃЕФбљБОДѓаЁЃК
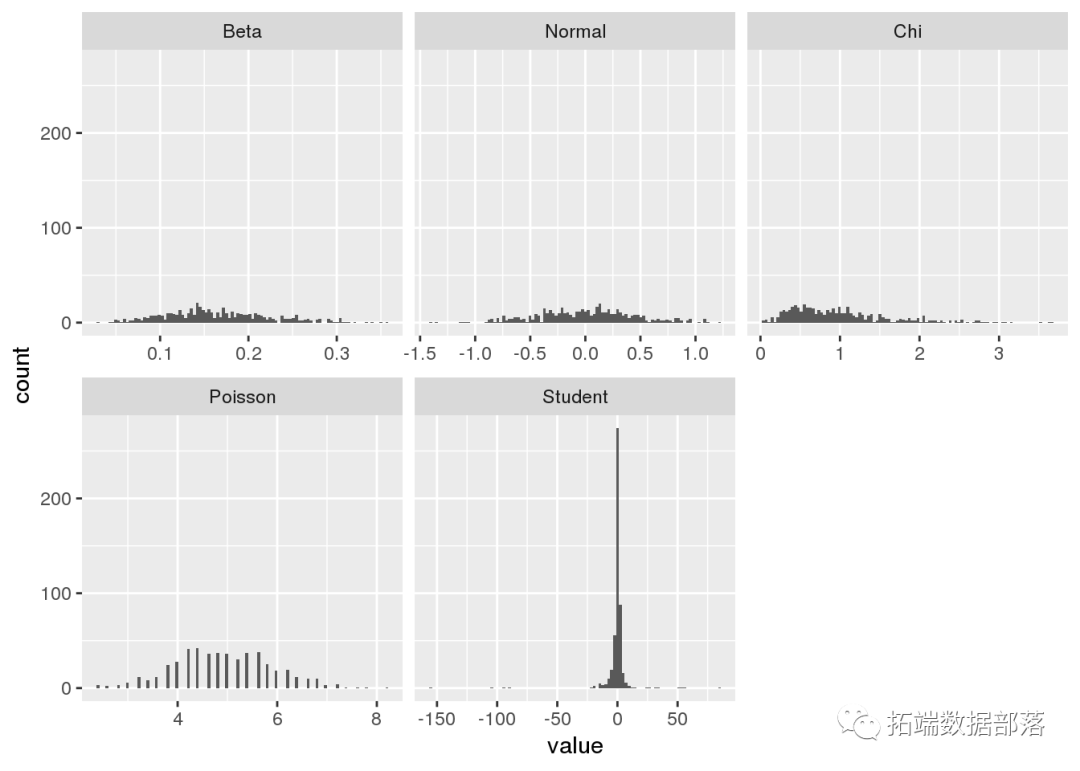
plot.means(norm.means)

етаЉНсЙћБэУїЖдЪ§ЫЦШЛзМдђЪЧе§ЬЌадЕФГфЗжДњРэЁЃЕЋЧызЂвтЃЌДгФПЪгМьВщРДПДЃЌЦНОљжЕЕФГѕЪМБДЫўЗжВМЫЦКѕВЛБШе§ЬЌЗжВМИќе§ГЃЁЃЫљвдетИіНсЙћПЩФмЪЧгУвЛСЃбЮЁЃПДПДбЇЩњЕФtЗжВМЃЌЮвУЧПЩвдПДГіЮЊЪВУДЫќЕФЪжЖЮВЛЪЧе§ЬЌЗжВМЕФЃК
round(quantile(means$Student), 2) ## 0% 25% 50% 75% 100% ## -495.61 -0.95 0.00 0.98 3422.66
ЖдгквЛаЉбљБОЃЌЦНОљЗжВМдкЗжВМЕФСНИіЮВВПОпгаМЋЖЫвьГЃжЕЁЃ
НсТл
етаЉЪЕбщЕФНсЙћБэУїЃЌЖдгкаЁгк20ЕФбљБОЃЌОјЖдгІИУБмУтбЇЩњtМьбщЁЃЕБбљБОСПжСЩйЮЊ100ЪБЃЌДѓЖрЪ§ЗжВМЫЦКѕЖМТњзуСЫВтЪдЕФМйЩшЁЃ
змжЎЃЌЬиБ№НЈвщМьВщбљБОДѓаЁЕЭгк100ЕФВтСПЗжВМЁЃгЩгкжааФМЋЯоЖЈРэВЛЪЪгУгкОпгаЮоЧюЗНВюЕФЗжВМЃЌвђДЫбщжЄДѓбљБОДѓаЁЕФВтСПЗжВМвВЪЧКЯРэЕФЁЃХХГ§етжжЗжХфЕФПЩФмадЁЃе§ШчЮвУЧдкетРяПДЕНЕФЃЌМДЪЙдк5000ЕФбљБОДѓаЁЯТЃЌИљОнОпгавЛИіздгЩЖШЕФtЗжВМЗжВМЕФВтСПвВВЛТњзуВтЪдЕФМйЩшЁЃ

