本文整理自阿里云高级专家喻良,在 Flink Forward Asia 2023 主会场的分享。本次分享将为大家介绍 Flink + Paimon + Hologres 构建湖仓一体数据分析。Hologres 是阿里云自研一站式实时数仓产品,通过和 Paimon 的深度合作,提供分钟级/秒级时效性+秒级 OLAP 性能,实现流式湖仓的分层建模,降低开发运维成本,打破数据孤岛,实现业务洞察。内容主要分为以下五部分:
数据分析架构的实时性演进
Hologres 湖仓架构的三个能力创新
Flink+Paimon+Hologres:实时湖仓五个典型应用场景
Hologres 湖仓分析未来规划
Hologres+Flink:企业级实时数仓最佳实践
一、数据分析架构的实时性演进

目前很多用户都在考虑将湖仓分析从 Hive 架构迁移到 Lakehouse,在 Lakehouse 上出现了 Iceberg、 Dalta Lake、Hudi 三剑客,让传统方式改善了很多,比如操作更方便、有 ACID、Time Travel、查询效率更高、 Upsert 能力更强等。

随着企业对于数据更新处理的时效性要求越来越高,同时又提出了高吞吐入湖、低延时数据、具备流式的订阅、高性能的实时查询等需求,这类需求可以归为流式数仓。
湖仓架构中 Table Format 层要应对这些需求,需要更加面向流式湖仓设计,另外从引擎上来看,需要更高性能的查询分析能力。

Paimon 是为实时而生的 Table Format,最主要的特点是引入了 LSM Tree。Paimon 和 Hudi 相比, Upsert 性能提升了 4 倍,Scan 性能提升了 10 倍,具备低延时、低成本入湖、开发效率高等特点。另外大家对 Paimon 适配热情都非常高,各家产品适配工作都推进地比较快,所以它的生态较其他几个Table Format 发展得更快。

Hologres 是面向数据服务层设计的统一的数据平台,可以将 OLAP 引擎查询、即席分析、在线服务、向量计算等多个数据应用构建在统一存储上,实现一份数据多种计算。在性能上,Hologres 在 TPC-H 30TB 上排名世界第一,近两年的双十一 Hologres 在集团内部的峰值写入达到 10 亿每秒。在信通院的测试中,Hologres 基于 Serverless 能力,可以把节点的规模推到 8192 节点,实现了超大规模的 OLAP 引擎。

Flink + Paimon + Hologres 流式湖仓方案是将 3 个产品做了非常紧密的结合,首先使用 Flink 将数仓以 Paimon 这种 Table Format 在湖上构建,使用 Flink 进行流计算、使用 Hologres 对各层数仓做统一的 OLAP 查询和 ADS 层在线分析。基于 Paimon 可以实现高吞吐入湖;基于 Flink 可以实现全链路的实时计算,基于 Hologres 可以实现高性能的 OLAP 查询,所以整个链路从实时性、时效性、成本几个方面都可以取得比较好的平衡。
二、Hologres 流式湖仓架构的三个能力创新

Hologres 是标准的 MPP 数据库,主要由两个模块组成, FE(Frontend) 和 QE(Query Engine), FE 负责接收 SQL,并通过优化器生成物理 Plan, QE 负责高效率运行 Plan。为了适配 LakeHouse, 引入 DLF-FDW,这个组件在元数据上打通了 DLF 和 HMS,在数据链路上打通了 OSS 和 OSS-HDFS ,支持访问湖上 Paimon、Hudi 、Delta 等数据格式。

针对实时湖仓场景,Hologres 专门设计了一些新特性,以满足用户对实时湖仓成本、性能、隔离方面的需求。
第一个特性,基于 Serverless 湖加速的能力。当用户的数据在以 Paimon 格式在湖上构建好后, 希望 OLAP 引擎能以更低成本去做加速查询,为此我们推出 Serverless 方案。首先为用户免费提供一个 Frontend 节点,用于存储元数据和权限等,每个用户独享 Frontend 节点,用户的元数据是独立的、完全隔离的。后端提供多组共享资源池,为 SQL 提供实际的计算资源。在实际 SQL 运行中,应用层 SQL 提交到 Frontend 上, 经过优化器生成物理 Plan,根据负载选择一个后端共享资源池进行运行,完成后会原路返回执行结果。基于这个方案可以实现高性能数据湖查询加速,该方案最大的特点是用户的查询成本低,用户手上不需要持有资源,当 SQL 运行时,系统会自动记录 SQL 读取了多少数据,根据实际处理的数据量进行计费,根据实际使用付费,不使用不付费。

第二个特性,弹性与隔离。数仓上有各种各样的业务,各业务负载的类型不一样,有的 App 在线查询,查询响应要求毫秒级,要求数百数千 QPS,有的业务是 ETL 数据加工作业,执行时间长,消耗资源多,有的业务是复杂的聚合指标等等,为了更好解决这个问题,Hologres 提供了弹性计算资源组模式,这是一种彻底的计算负载和存储能力解耦的架构。
首先在实例中引入 Gateway 作为统一 SQL 网关接入层,下层把资源分成了多个独立的计算组,每组都可以独立运行 SQL。比如说第一个计算资源组用于加工和计算、第二个用于 OLAP 查询、第三个用于在线的业务查询。另外计算资源组是共享同一份存储,计算资源组在授权后可以访问所有的数据,在实际运行过程中 SQL 通过 Gateway 接入进来,提前配置好路由规则(定义好用户与计算资源组的对应关系),它会根据这个规则去路由到具体的计算组。
基于弹性计算资源组可以实现按需扩容。当业务高峰时,可以对其中任意计算组扩容,也可以对这个实例增加资源组,当业务低峰期,可以直接对资源组进行删除、缩容操作。相关变更操作对查询没有影响,对实时写入仅有 5 秒钟的影响。通过这种方式用户持有的资源可以做到最小化,从而达到降本增效。因为计算组天然物理隔离,所以避免了业务和业务相互干扰,让查询更稳定。

第三个特性, JSON 数据列式存储优化。在支持用户处理数据湖查询的时候会遇到大量半结构化数据,主要是 JSON 数据,处理 JSON 数据有两种方式:
- 第一种方式在入库的时候把 JSON 打成大宽表,该方案存在一些缺点,如一旦业务上有变化,要加字段的时候整个业务就得停下来,然后全链路改完后再上线
- 第二种方式直接往库里写入 JSON,在业务上方便,任务也简单,业务直接在 JSON 中增加字段即可,但引擎查询的时候就会非常慢,因为在读数据的时候,需要将 JSON 展开去分析
Hologres JSON 数据列式存储优化方案可以同时解决入库方便,满足压缩存储、高性能计算需求,方案具体为:
- 应用直接以 JSON 方式写到数据库
- Hologres 有超高的实时性,数据直接写入到内存里,并生成 WAL Log,当内存攒到一定大小后会落成文件
- 后台异步启动 Compaction 任务分析文件中的 JSON 字段,字段重复率低于阈值就会被重新放到新的 JSON 里面,重复率高于标准的字段抽出来形成列存,以 ORC 格式存成文件,Compaction 后就可以当做列存处理,对它的各列进行自动索引、压缩。这种抽取是底层存储层的自动转换,在逻辑上仍然是同一个 JSON 字段,不改变原有用户原有使用 JSON 的函数和操作符。
- 基于索引和压缩,可以高效处理数据读取、Filter 等操作,这些操作对业务无感,后台异步进行且整个查询过程中数据也是一致的
2022 年双十一期间,淘宝搜索部门使用了该方案,查询效率有 400% 提升,同时列存化使压缩率大幅提升,存储成本下降 45%。
三、Flink+Paimon+Hologres 构建实时湖仓的五个典型应用场景
下面介绍基于 Flink+Paimon+Hologres 实践湖仓一体数据分析的经典场景。

第一个场景数据湖查询加速
上图展示通过 SQL 实现数据湖查询加速的 Demo:
- 首先上图最左边是 Flink 的 SQL 脚本,先创建 Paimon 表,再去对 Paimon 表进行数据写入。
- 中间是 Hologres 查询加速 SQL 展示
- 批量导入外表,可以同步 DLF 下所有的表信息,这只是关联元数据信息,没有做实际数据入库
- 使用图中查询 SQL 对它进行直接查询,也可以用 Insert Into Select 语句把数据导入到 Hologres 的内部存储中进行查询。
使用图中查询 SQL 对它进行直接查询,也可以用 Insert Into Select 语句把数据导入到 Hologres 的内部存储中进行查询。

第二个场景为湖仓联合查询
左边是联合查询的物理 Plan,可以看到下面是 Hologres 内表的 Scan 算子,中间是 Paimon 外表 Scan 算子,最上面为 Join。

第三个场景为湖仓冷热分层
业务在进行湖仓查询的时候,会频繁查询最近七天的数据,偶尔查询七天以前的数据。因此需要低成本的冷热分层查询方案。
上图右侧提供了 SQL Demo 例子
创建外表,将 Paimon 这个表的元数据信息导入进来,Paimon 里存了全量的历史数据
创建 Hologres 内表,里面存放了最近 7 天的业务热数据
通过视图将近 7 天的热数据和 7 天前的冷数据做视图关联起来
基于这个视图进行范围查询,当查询范围落到了热数据上,就会直接去查询 Hologres 内表,当这个时间范围落到了 7 天以前,就会直接查询 Paimon 表。当两个范围都包含了,就会形成上图左边的查询计划,下面是 Paimon 外表 Scan,中间是 Hologres 的 Scan 算子,上面会有 Append 将它们 Union 起来。
该方案可以降本增效,提升开发效率。再补充一下,在 Hologres 内表上有自动冷热分层功能,在分区表上定义热数据保留时间,超期后系统会自动搬迁到冷数据中,对运维和查询无感。Holo 的冷存存储成本几乎与 OSS 是一致的,且无需手动搬迁,体验更优。

第四个场景为基于湖数据构建 Dynamic Table
Dynamic Table 是 Hologres 近期内部的邀测功能,类似于物化视图,融合了实时更新与批量更新,具备批流一体的更新体验。
基于Dynamic Table 构建湖仓分层过程:
在 DWS 层数仓使用 Paimon 在湖上构建数据表和维表
在 ADS 层、DWD 层使用 Dynamic Table 逐层构建数仓
基于Dynamic Table,可以提供高 QPS、 高性能查询。当希望对 Dynamic Table 进行更新的时候,就可以用 Refresh Table 命令去刷新。
Dynamic Table 更新能力:如果数据源为 Hologres 内表,可以提供增量更新能力,如果是 Paimon 表可以提供全量更新能力。后面计划将 Paimon Binlog 日志接上,之后湖上的数据也可以去做增量更新场景。

第五个场景为流式湖仓的分层实践
通过 Flink 的流计算能力,将数仓的 ODS 层、 DWD 直接构建在湖上,以 Paimon 来存储,后面两层可以构建在 Hologres 上,上层业务层通过 Flink 提供流计算的能力,通过 Hologres 提供 OLAP 在线查询的能力。Hologres 和 Paimon 都具备流式访问能力,故数仓分层可以根据存储成本和数据时效性进行选择。直接将数据放在 Hologres 上,可以提供秒级时效性以及极致 OLAP 性能;如果将数据构建在 Paimon 上,使用 Hologres 来进行查询加速,可以提供分钟级的时效性和秒级 OLAP 性能。
四、Hologres 湖仓分析未来规划

Hologres 湖仓一体规划重点将围绕 Paimon 格式展开,有两个目标,希望把基于 Paimon 的查询性能从秒级推向亚秒级体验。
通过支持如下功能优化查询性能
C ++ Native Reader
引入多级的智能缓存
支持更多统计信息,帮助优化器生成更好 Plan
我们希望对 Paimon 的接入功能更完整
支持Paimon格式入湖
支持消费Paimon的 Binlog 能力
适配元数据:自动发现Maxcompute元数据在云上已是标配能力,但对Paimon还未支持,后面需要适配。
五、Hologres+Flink:企业级实时数仓最佳实践

这是 Hologres 加 Flink 流式分层方案,和湖仓分层的方案是比较类似的,区别是整个数仓都构建在了 Hologres 上。这个方案可以支持高性能的数据实时写入、实时更新、实时查询,将数据的新鲜度保持在秒级甚至毫秒级,帮助有极致需求的企业实现业务分析的极致实时化。
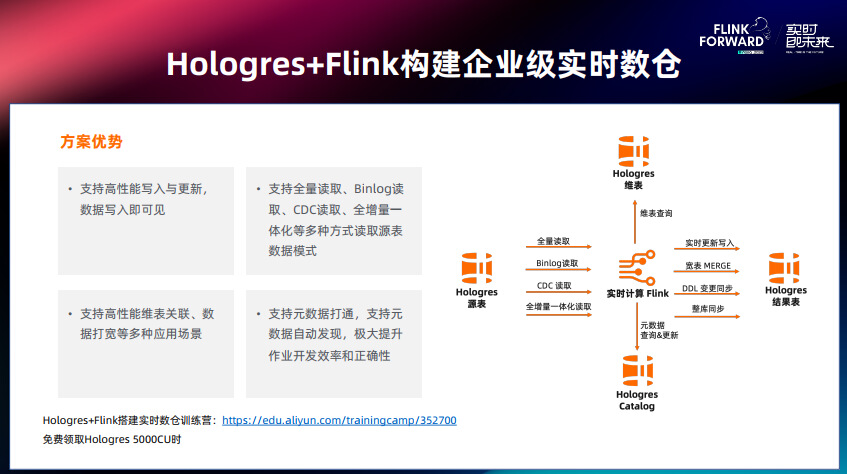
Hologres+Flink 这套组合是在阿里集团内部经过多年实时化场景打磨探索出来的最佳架构,例如淘天用户增长团队成功让 3-5min 的画像分析提升到 10s 左右,CCO 客户服务团队数据分析效率提升 10 倍,淘菜菜一年成本降低几百万。通过多年的积累,Hologres+Flink 产品功能逐渐互补,以实时计算 Flink 为中心,实时数仓 Hologres 围绕其有多项产品使用路径:Hologres 能够作为 Flink 的维表来使用;通过 Flink 能够把加工好的结果写入 Hologres;Hologres 提供 binlog 能够被 Flink 消费;Hologres Catalog 支持元数据服务、整库同步、SchemaEvolution 等。

Hologres 搭配 Flink 可以支持非常高性能的实时写入与更新,第一支持 PK 查询,提供高性能的 Upsert 能力; 第二支持宽表 merge 和局部列更新;第三新增 Check And Put 操作,乱序数据也能保证和上游最终一致性;第四新增 Fixed_Copy 模式,写入性能更好。 Flink 都是实时入库,增加了基于 Hologres 的批量入库的能力。右图展示 128 Core 的 Hologres 性能:在 Append Only 的情况下无主键表的时候可以达到 230 万的 RPS; 在 Insert 有主键表,冲突就丢弃新行的模式下可以达到 200 万RPS;在 Update 的场景下,根据主键冲突比例不一样,可以达到 70-80 万的 RPS。

随着大数据从规模化走向实时化,实时数据的需求覆盖互联网、交通、传媒、金融、政府等各个领域。实时计算在企业大数据平台的比重也在不断提高,部分行业已经达到了 50%。Hologres+Flink 通过丰富企业级能力,替换开源复杂的各类技术组件,减少多种技术栈学习、多种集群运维、多处数据一致性维护等成本,让企业专注于业务,实现降本增效。
小红书 OLAP 场景通过 Hologres 替换 Clickhouse,查询性能大幅提升,在推荐场景下基于 Hologres+Flink 实时分析用户 A/B 分组测试结果,实时调整推荐策略,更新推荐模型。
小迈科技通过 Hologres+Flink 构建百亿级广告实时数仓,满足高性能写入、极速复杂查询、高可用等需求,让用户行为分析实现秒级响应,快速响应业务需求。
金蝶管易云升级实时数仓到 Hologres+Flink,数据延迟从 30S+ 降低到秒级,借助 Hologres 强大的实时分析聚合能力,解决数据统计延迟问题,并且整体资源成本降低 50%。
好未来将 Kudu 作为 OLAP 引擎,使用 Impala 进行数据加载、运算,通过 Hologres 同时替换 Kudu/Impala 实现百万级写入和毫秒级查询能力,降低成本近百万/年。
乐元素通过测试发现对比 Presto 性能提升了 5~10 倍,64 核 Holgores 可直接替换 96 核 Presto 集群,升级数仓架构,让业务运营效率提升 10 倍+。

最后总结一下,使用 Flink+Paimon+Hologres 让我们在流式湖仓、实时数仓都有一站式的体验。全链路都用 SQL 来进行操作,每层数据都是可修改、可复用,整个方案组件比较少,整个开发以及维护的难度都比较低。这个方案最大的特色是让开发者、业务方在数据的新鲜度、成本、时效三个维度有更大范围的选择,可以自由选择分钟级、秒级的方案。从性能上,基于直读和向量引擎可以实现高效湖加速,Paimon+Hologres 提供分钟级的时效性和秒级的 OLAP 能力。最后 Hologres + Flink 具备整套企业级能力,在高可用、资源弹性、故障处理、运维、负载隔离、可观测、安全性都是非常完备的。希望后续 Hologres 携手 Paimon 可以在湖仓分析中实现更高的性能,更丝滑的用户体验。
阿里云官网搜索 Hologres 进入官网查看详情,复制下方链接领取 5000 CU时,100 GB 存储免费试用资源进行使用。
https://free.aliyun.com/?pipCode=hologram
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可微信扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
59 元试用 实时计算 Flink 版(3000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc