01
ДЋЭГЪ§ОнВжПтЗжЮіЪЕЯжЗНАИМђНщ
ДЋЭГЪ§ОнВжПтЗжЮіЕФЪЕЯжЪЧвЛИіЕфаЭ Lambda МмЙЙЃЌЭЈЙ§ЯТЭМЮвУЧПЩвдПДГіДЋЭГМмЙЙжївЊЗжЮЊСНВуЃКЩЯВуЪЧЪЕЪБСДТЗВуЃЌЯТВуЪЧРыЯпСДТЗВуЁЃЫќУЧЕФЪ§ОнЭЈЙ§зѓВрЕФЪ§ОнЩуШыВуЃЌЭЈЙ§ВЛЭЌТЗОЖНЋЪ§ОнЭГвЛећКЯЕНЯё Kafka етбљЕФЯћЯЂЖгСажаМфМўжаЃЌШЛКѓНЋЪ§ОнЗжЮЊСНЗнЯрЭЌЕФЪ§ОнЃЌЗжБ№гЩЪЕЪБСДТЗКЭХњСПСДТЗНјааДІРэЃЌзюжеЛузмЕНЪ§ОнЗўЮёВуЃЌЪЕЯжЖдгУЛЇЬсЙЉЪ§ОнЗжЮіЗўЮёЕФФмСІЁЃ
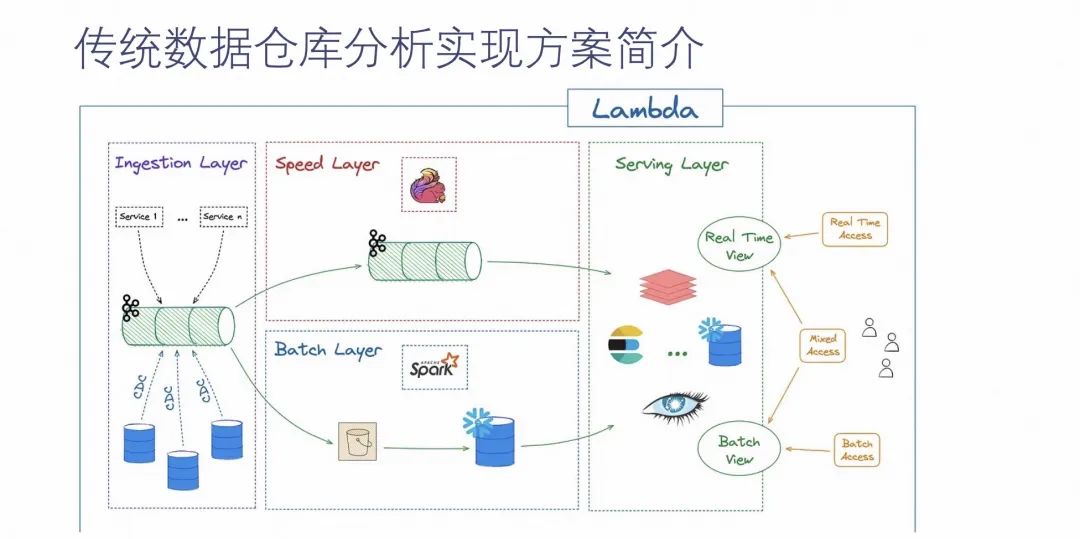
Lambda МмЙЙЕФГіЯжжївЊЪЧвђЮЊгУЛЇЖдгкЪЕЪБЗжЮіашЧѓЕФГіЯжЃЌвдМАСїДІРэММЪѕЕФж№НЅГЩЪьЁЃЕЋЪЧЫќвВгавЛаЉУїЯдЕФБзЖЫЃЌШчЩЯЭМЫљЪОЃЌЫќашвЊЮЌЛЄСНЬзЯЕЭГЃЌетОЭЛсЕМжТВПЪ№ГЩБОКЭШЫСІГЩБОЖМЛсдіМгЁЃЕБвЕЮёБфИќЕФЪБКђЃЌвВашвЊаоИФСНЬзЯЕЭГРДЪЪгІвЕЮёЕФБфЛЏЁЃ
ЫцзХСїДІРэММЪѕЕФж№НЅГЩЪьЃЌLambda МмЙЙжЎКѓгжЭЦГіСЫ Kappa МмЙЙЃЌШчЯТЭМЫљЪОЁЃ
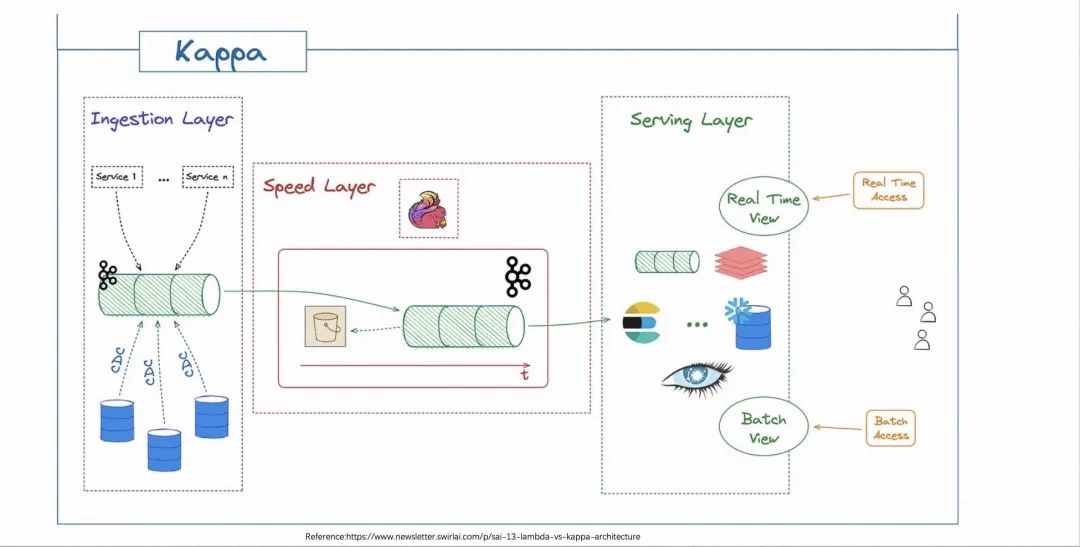
Kappa МмЙЙЪЧЪЙгУСїДІРэСДТЗРДДњЬцдРДЕФ Lambda МмЙЙЃЌвђЮЊСїДІРэЕФГЩЪьЃЌЫљвдЭЈЙ§вЛЬзЯЕЭГШЅЭъГЩЪЕЪБКЭРыЯпЕФМЦЫуГЩЮЊПЩФмЁЃ
Kappa МмЙЙгавЛИіЧАЬсЃЌЫќШЯЮЊЖдгкРњЪЗЪ§ОнЕФжиИДМЦЫуЃЌдкЗЧБивЊЕФЧщПіЯТЪЧВЛгУНјааЕФЁЃетОЭЪЙЕУЕБгУЛЇашвЊжиаТМЦЫуРњЪЗЪ§ОнЛђЪЧГіЯжаТвЕЮёБфЖЏЕФЪБКђЃЌЭљЭљашвЊНЋећИіЪ§ОнЩуШыНзЖЮЕФЙ§ГЬжиЗХвЛДЮЁЃдкДѓСПЯћЗбРњЪЗЪ§ОнЕФЧщПіЯТЃЌБиШЛдьГЩзЪдДРЫЗбЃЌВЂгіЕНвЛаЉЦПОБЁЃ
02
Paimon+StarRocks
ЙЙНЈКўВжвЛЬхЪ§ОнЗжЮіЪЕЯжЗНАИ
2.1 Ъ§ОнКўжааФ
ЕквЛИіЗНАИЪЧ Paimon КЭ StarRocks ЙЙНЈКўВжвЛЬхЪ§ОнЗжЮіЕФЪ§ОнКўжааФЗНАИЁЃ
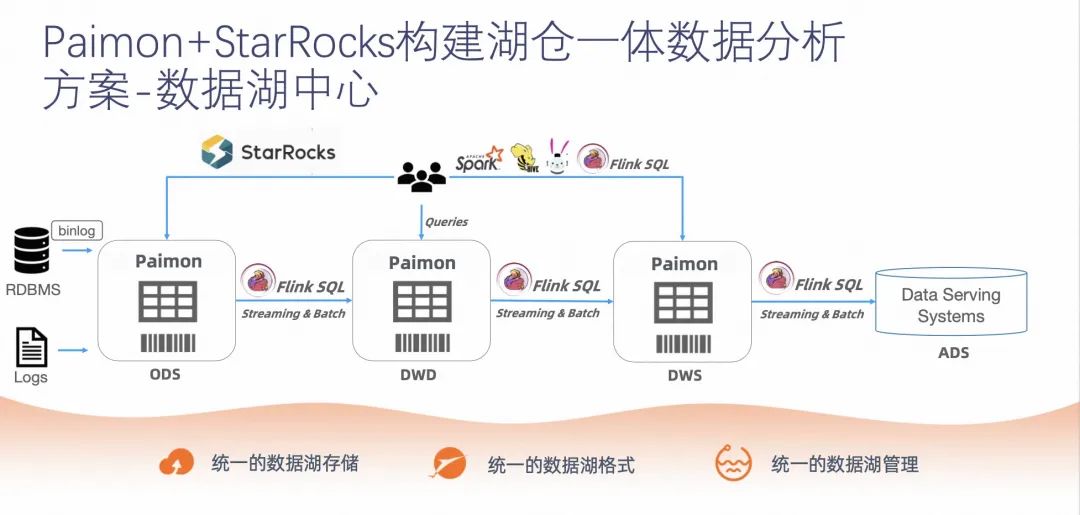
StarRocks БОЩэЪЧвЛИі MPP ЕФЪ§ОнПтЃЌЭЌЪБПЩвдЭтНгЖржжИёЪНЕФЪ§ОнКўзщМўЃЌПЩвдвдЕЅДПзїЮЊВщбЏв§ЧцШЅЭтНгЪ§ОнКўзщМўЃЌЪЕЯжВщбЏЙІФмЁЃШчЩЯЭМЃЌЭЈЙ§ StarRocks Лђ Spark ЖМПЩвдЖд ODS ЕШЪ§ОнВуЕФ Paimon зщМўНјааВщбЏЁЃ
дкетИіМмЙЙРяЃЌPaimon ЭЈЙ§ЖдЪ§ОнЕФТфХЬКЭЫїв§ЃЌУжВЙСЫЩЯЮФНщЩмЕФ Kappa МмЙЙжаЯћЯЂЖгСажаМфМўдкЪ§ОнЕФаоИФЁЂЛиЫнЁЂВщбЏЕШЗНУцЕФВЛзуЃЌДгЖјЪЙЕУетИіМмЙЙЕФШнДэТЪИќИпЃЌжЇГжЕФФмСІвВИќЙуЗКЁЃЭЌЪБдкХњДІРэЗНУцЃЌPaimon вВПЩвдЭъШЋМцШн HIVE ЕФФмСІЁЃ
2.2 МгЫйВщбЏ
ЕкЖўИіЗНАИЪЧ Paimon КЭ StarRocks ЙЙНЈКўВжвЛЬхЪ§ОнЗжЮіЕФМгЫйВщбЏЗНАИЁЃ
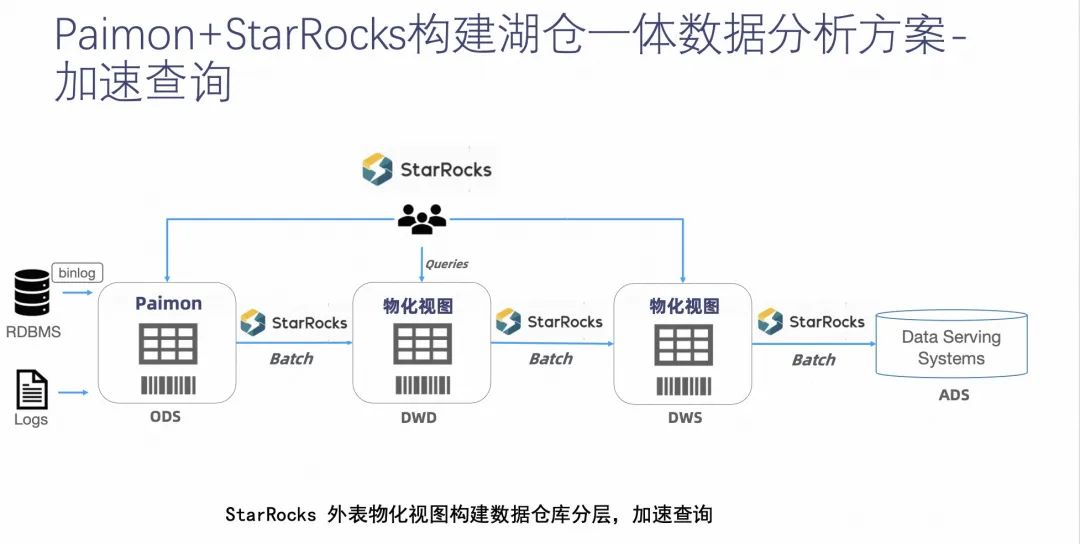
ЫќгыЕквЛИіЗНАИЕФЧјБ№ЪЧМИКѕећИіЯЕЭГЖМгЩ StarRocks ЕЅЖРЭъГЩЁЃЕБЪ§ОнНгШы PaimonЃЌЪЙЫќзїЮЊ ODS ВужЎКѓЃЌЭЈЙ§ StarRocks ЕФЭтБэЬиадРДЖСШЁ Paimon ЩЯЕФЪ§ОнЃЌНЈСЂвЛВуЮяЛЏЪгЭМРДзїЮЊ DWD ВуЁЃ
StarRocks ЕФЮяЛЏЪгЭМОпгавЛЖЈЕФ ETL ЕФФмСІЃЌЕБЫќзїЮЊ DWD ВужЎКѓЃЌгжЭЈЙ§ЕкЖўВуЧЖЬзЮяЛЏЪгЭМРДзїЮЊ DWS ВуЃЌзюжеЬсЙЉИјЪ§ОнЗўЮёВуНјааЪ§ОнЗжЮіЁЃ
ЭЈЙ§ StarRocks ЕФетЬзЯЕЭГХфКЯ Paimon етИіМмЙЙЕФСНИігХЕуЪЧЃК
- МђЛЏСЫдЫЮЌЃЌвђЮЊЫќВЛгУдйШЅЮЌЛЄИїжжзщМўЃЌжЛашвЊ StarRocks КЭ Paimon ОЭПЩвдЭъГЩЪ§ОнЗжЮіЗНАИЕФЙЙНЈЃЛ
- ВщбЏЫйЖШПьЃЌвђЮЊ StarRocks ЪЧвЛЬзДгЙЙНЈЫїв§ЁЂЪ§ОнДцДЂЁЂВщбЏгХЛЏЖМздГЩЬхЯЕЕФвЛИіЪ§ОнКўв§ЧцЃЌЫљвдЫќЯрБШЩЯЮФНщЩмЕФЦфЫћИїжжВщбЏв§ЧцЫйЖШИќПьЁЃ
2.3 ЮяЛЏЪгЭМ

ЩЯЭМгвВр SQL ЪЧУшЪіШчКЮНЈСЂвЛИі StarRocks вьВНЮяЛЏЪгЭМЁЃЫќжївЊгавдЯТМИИіЬиЕуЃК
- ЭЈЙ§ SQL ЖЈвхЃЌЩЯЪжМђЕЅЃЌЗНБуЮЌЛЄЃЛ
- дЄМЦЫуЃЌНЕЕЭВщбЏбгЪБЃЌМѕЩйжиИДМЦЫуПЊЯњЃЛ
- здЖЏВщбЏТЗгЩЃЌЮоашИФаД SQLЃЌЭИУїМгЫйЃЛ
- жЇГжвьВНздЖЏЫЂаТЪ§ОнЃЌЖЈЪБЫЂаТЃЌжЧФмАДЗжЧјЫЂаТЃЛ
- жЇГжЖрБэЙЙНЈЃЌЛљБэПЩРДздФкБэЁЂЭтБэКЭвбгаЕФЮяЛЏЪгЭМЁЃ
2.4 РфШШЗжРы
етЪЧЭЈЙ§ Paimon + StarRocks ЪЕЯжРфШШЗжРыЕФЬиадЁЃ
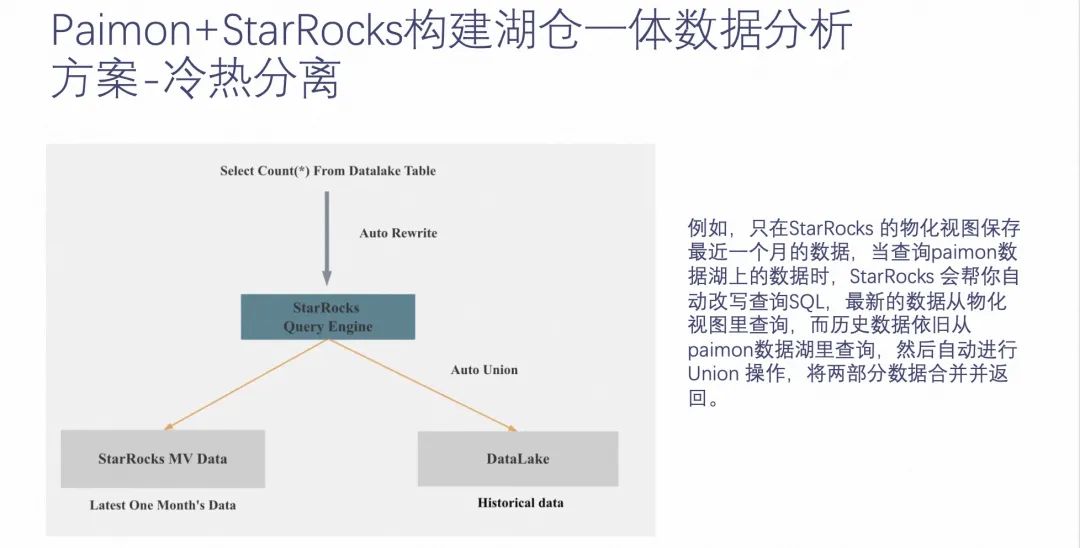
РфШШЗжРыЕФИХФюЃЌЪЧЯЃЭћПЩвдНЋОГЃВщбЏЕФШШЪ§ОнДцДЂЕНВщбЏПьЕФЯё StarRocks етжж OLAP в§ЧцЩЯЃЌВЛОГЃВщбЏЕФРфЪ§ОнДцДЂЕНБШНЯСЎМлЕФдЖГЬЮФМўДцДЂзщМўЃЌБШШч OSS КЭ HDFSЁЃ
ШчЩЯЭМ Paimon + StarRocks РфШШЗжРыЕФР§згЃЌШчЙћЙЙНЈСЫетбљвЛИіРфШШЗжРыЕФ MV БэЃЌЕБВщбЏЕНетеХБэЕФЪБКђЃЌЛсздЖЏбЁдёдк StarRocks ЩЯЗжВМЕФетИіШШЪ§ОнКЭдк Paimon ЗжВМЕФРфЪ§ОнЁЃШЛКѓЖдВщбЏНсЙћКЯВЂЃЌВЂЗЕЛиИјгУЛЇЁЃ
03
StarRocks гы Paimon
НсКЯЕФЪЙгУЗНЪНгыЪЕЯждРэ
3.1 Paimon ЭтБэЪЙгУ
ЕУвцгк StarRocks ЖдЭтБэ Catalog ЕФГщЯѓЃЌдк Paimon ЭЦГіВЛОУЃЌStarRocks ОЭвдЪЕЯжЯргІНгПкЕФЗНЪНЃЌЪЕЯжСЫЖдгк Paimon ЭтБэЕФжЇГжЁЃдкЖдНг Paimon ЭтБэЪБЃЌжЛашвЊдк StarRocks ЩЯжДааЯТУцетЬѕ Create External Catalog гяОфЃЌЖд Type жИЖЈЮЊ PaimonЃЌЬюаДЩЯЖдгІЕФТЗОЖжЎКѓОЭПЩвджБНгВщбЏ Paimon жаЕФЪ§ОнСЫЁЃ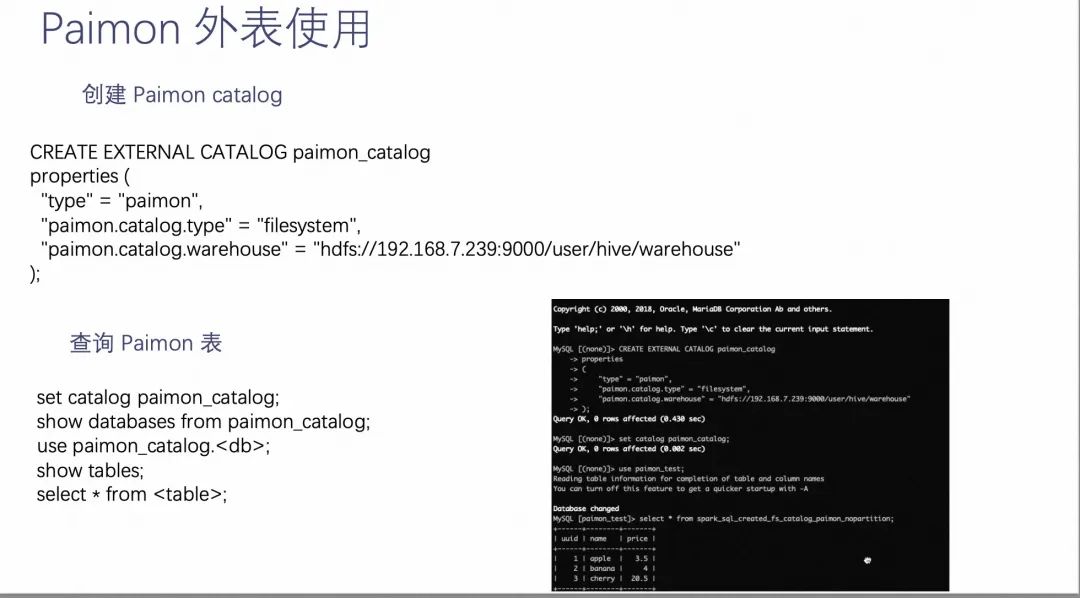
3.2 JNI Connector
JNI Connector ЪЧЪЙЕУ StarRocks КЭ Paimon НсКЯЕФвЛИіБШНЯживЊЕФЬиадЁЃ
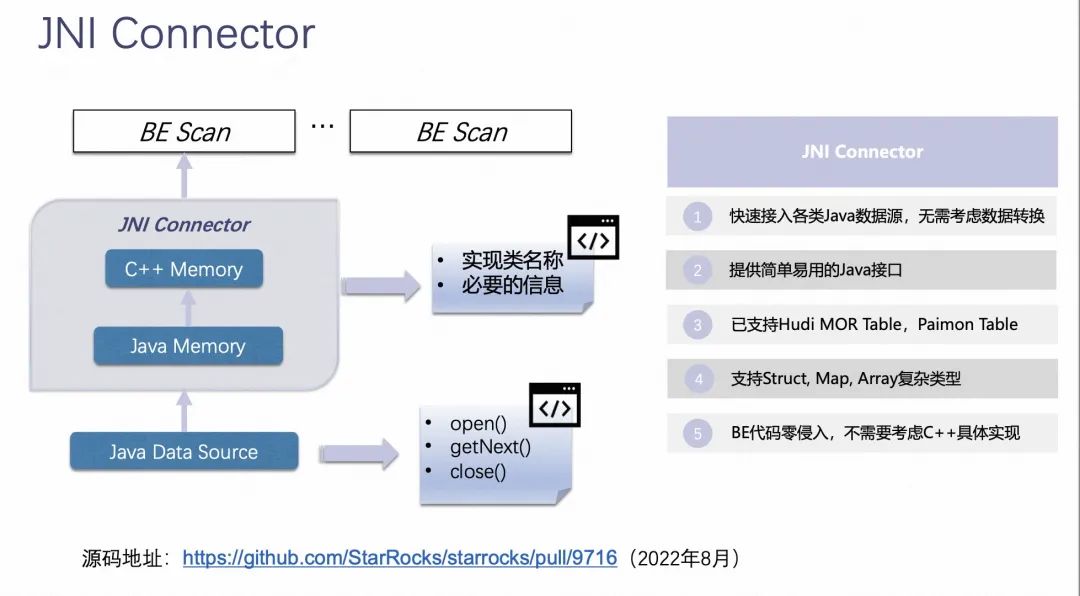
JNI Connector ЕФБГОАЪЧ StarRocks ЖдгкЪ§ОнДІРэЕФзщМўЪЧ C++ ГЬађБраДЕФЃЌЕЋЪЧЪ§ОнКўзщМўЬсЙЉЕФ SDK ДѓЖрЪ§ЪЧ Java ЕФЃЌУЛга C++ ЕФ SDKЃЌШчЙћ StarRocks ЯывЊЭЈЙ§ BE ЗУЮЪЪ§ОнКўзщМўЕзВуЪ§ОнЕФЛАЃЌжЛФмЗУЮЪЫќдЩњЕФ ORC/Parquet ЕШИёЪНЃЌЮоЗЈгІгУетаЉзщМўЫљЬсЙЉЕФИпМЖЙІФмЁЃ
JNI Connector ЪЧвЛИіГщЯѓЕФЃЌеыЖдЫљгаЭтБэ Java SDK ЖМПЩвдЪЪгУЕФ ConnectorЁЃЫќгУгк StarRocks ЕФ BE зщМўЩЯЃЌЪЧДІгк BE КЭЪ§ОнКўзщМў Java SDK жЎМфЕФжаМфВуЁЃ
JNI Connector ЕФжївЊЙІФмЪЧЕїгУЪ§ОнКўзщМўЕФ Java SDK ШЅЖСШЁЪ§ОнКўЕФЪ§ОнЃЌШЛКѓНЋЖСШЁЕНЕФЪ§Онвд StarRocks ЕФ BE ПЩЪЖБ№ЕФФкДцХХСаЗНЪНаДШыЕНвЛПщЖбЭтФкДцЩЯЃЌШЛКѓНЋетИіФкДцНЛНгИј BE C++ГЬађШЅдЫааЃЌетбљОЭЪЙЕУЫќПЩвдНЋ BE КЭ Java SDK НјааЯЮНгЁЃ
JNI Connector гавдЯТМИИіЬиЕуЃК
- ПьЫйНгШыИїРр Java Ъ§ОндДЃЌЮоашПМТЧЪ§ОнзЊЛЛЃЛ
- ЬсЙЉМђЕЅвзгУЕФ Java НгПкЃЛ
- вбжЇГж Hudi MOR TableЃЌPaimon TableЃЛ
- жЇГж Struct, Map, Array ИДдгРраЭЃЛ
- BE ДњТыСуЧжШыЃЌВЛашвЊПМТЧ C++ОпЬхЪЕЯжЁЃ
ЯТЭМЪЧ JNI Connector ЕБжавЛаЉЯИНкЕФНщЩмЁЃ

ЩЯУцЪЧЖЈГЄзжЖЮДцДЂИёЪНЃЌЯТУцЪЧБфГЄзжЖЮЕФДцДЂИёЪНЁЃ
- ЖЈГЄзжЖЮДцДЂИёЪН
- ЕквЛВПЗжЪЧЖдгкетвЛСажаУПвЛааЪ§ОнЪЧЗёЮЊ Null ЕФЖЈвхЁЃ
- ЕкЖўВПЗжЪЧЪ§ОнВПЗжЃЌетРяДцДЂЖЈГЄЕФОпЬхЕФЪ§ОнЁЃ
- БфГЄзжЖЮДцДЂИёЪН
- ЕквЛВПЗжЪЧЖдгкетвЛСажаУПвЛааЪЧЗё Null ЕФЪ§зщЃЛ
- ЕкЖўВПЗжЪЧУшЪіЕкШ§ВПЗжОпЬхЪ§ОнжаУПвЛааЪ§ОнПЊЪМЖСШЁЕФЦ№ЪМЕижЗЃЛ
- ЕкШ§ВПЗжЪЧОпЬхЪ§ОнЁЃ
04
StarRocks ЩчЧјКўВжЗжЮіЮДРДЙцЛЎ
ЕБЧА StarRocks вбОжЇГжСЫ Paimon ЕФвЛВПЗжЬиадЃЌЛЙгавЛаЉднЮДЪЕЯжЁЃФЧУДЮДРДМЦЛЎЭъЩЦ Paimon БэЗжЮіЕФЬиадШчЯТЃК
- жЇГжЗжЮіИДдгРраЭ
- жЇГжСаЭГМЦаХЯЂ
- жЇГждЊЪ§ОнЛКДц
- жЇГж time travel
- жЇГжЛљгк Paimon ЭтБэЕФСїЪНЮяЛЏЪгЭМ
Q&A
QЃКЧыЮЪЮяЛЏЪгЭМШчКЮзіЕНгааЇЙмРэЃП
AЃКЮяЛЏЪгЭМдкНЈСЂжЎКѓЪЧПЩвдздЖЏЫЂаТКЭЕїЖШЕФЃЌВЛашвЊвРРЕЭтВПзщМўШЅДЅЗЂЫЂаТЁЃВщбЏИФаДФмСІЪЙЕУгУЛЇПЩвджЛВщ base БэЃЌВЛашвЊШЅжИЖЈВщФГИіЮяЛЏЪгЭМЁЃетСНИіЬиадМѕЩйСЫВЛЩйЙмРэЗНУцЕФЮЪЬтЁЃЖјЖдгкЮяЛЏЪгЭМгы base БэжЎМфЁЂвдМАЧЖЬзЮяЛЏЪгЭМжЎМфЕФвРРЕЙиЯЕЃЌEMR-Serverless-StarRocks КѓајЛсЭЦГівЛИіШЮЮёЕїЖШгыБэвРРЕЙиЯЕЕФ web еЙЪОЙІФмЁЃ
QЃКPaimon+StarRocks КўВжвЛЬхЪ§ОнЗжЮіЗНАИЃЌдкЪ§ОнАВШЋЃЌБШШчЗУЮЪПижЦЁЂЪ§ОнЩѓМЦЕШЃЌЪЧЗёгаОпЬхЕФЙцЛЎЃПAЃКФПЧАЮвСЫНтЕНЕФ StarRocks ЙигкЪ§ОнЙмРэШЈЯоЪЧЛљгкНЧЩЋЗжХфЕФВщПДЁЂаоИФЕШШЈЯоЃЌЖдгкВЛЭЌНЧЩЋИГгшВЛЭЌШЈЯоЁЃСэЭтЃЌЖдгк OSS Лђ HDFS ЩЯЕФЪ§ОнЛсгаЖдгІЕФзщМўШЯжЄЙІФмЁЃ
QЃКЧыЮЪвд StarRocks ЮЊжїЬхЕФКўВжвЛЬхМмЙЙжаЃЌдкДг Paimon ЖСШЁЪ§ОнжЎКѓЃЌЛсаДЛиЕН Paimon Т№ЃПAЃКдкДг Paimon ЖСШЁЭъ ODS ВуЕФЪ§ОнКѓЃЌЛсСїШы StarRocks ЕФЮяЛЏЪгЭМЃЌжЎКѓЪЧвЛВуЧЖЬзЕФ StarRocks ЮяЛЏЪгЭМЃЌВЂВЛЛсаДЛиЕН PaimonЁЃ
ЛюЖЏЪгЦЕЛиЙЫ & PPT ЛёШЁ
PC ЖЫ
НЈвщЧАЭљ Apache Flink бЇЯАЭјЃК
https://flink-learning.org.cn/activity/detail/69d2ec07bc2f664d000a954f49ed33aa
вЦЖЏЖЫ
ЪгЦЕЛиЙЫ/PPT ЯТдиЃКЙизЂ Apache Flink ЙЋжкКХ/ Apache Paimon ЙЋжкКХЃЌЛиИД 0729
ЖЏЪжЪЕМљЃќЪЙгУ Flink ЪЕЪБЗЂЯжзюШШ GitHub ЯюФП
ЯывЊСЫНтШчКЮЪЙгУ Flink дк GitHub жаЗЂЯжзюШШУХЕФЯюФПТ№ЃПБОЪЕбщЪЙгУАЂРядЦЪЕЪБМЦЫу Flink АцФкжУЕФ GitHub ЙЋПЊЪТМўЪ§ОнМЏЃЌЭЈЙ§ Flink SQL ЪЕЪБЬНЫїЗжЮі Github ЙЋПЊЪ§ОнМЏжавўВиЕФВЪЕАЃЁ
ЭъГЩБОЪЕбщКѓЃЌФњНЋеЦЮеЕФжЊЪЖгаЃК
- СЫНт Flink КЭСїЪНМЦЫуЕФгХЪЦ
- Жд Flink SQL ЛљДЁФмСІКЭ Flink ЪЕЪБДІРэЬиадгаГѕВНЬхбщ
ЪЕбщЯъЧщЃКШчКЮЪЙгУ Flink SQL ЬНЫї GitHub Ъ§ОнМЏЃќFlink-Learning ЪЕеНгЊ


