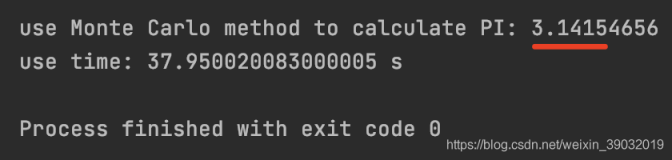
??БОЮФНщЩмЛљгкPythonгябдЃЌЖдДѓСПВЛЭЌЕФExcelЮФМўМгвдПчЮФМўЁЂж№ЕЅдЊИёЦНОљжЕМЦЫуЕФЗНЗЈЁЃ
??ЪзЯШЃЌЮвУЧРДУїШЗвЛЯТБОЮФЕФОпЬхашЧѓЁЃЯжгавЛИіЮФМўМаЃЌЦфжагаШчЯТЫљЪОЕФДѓСПExcelЮФМўЃЌЮвУЧетРяОЭвд.csvЮФМўЮЊР§РДНщЩмЁЃЦфжаЃЌУПвЛИі.csvЮФМўЕФУћГЦЖМЪЧШчЯТЭМЫљЪОЕФRef_XXX_Y.csvИёЪНЕФЃЌЦфжаXXXБэЪОШ§ИізжФИЃЌКѓУцЕФYдђБэЪОШєИЩЮЛЪ§зжЁЃ
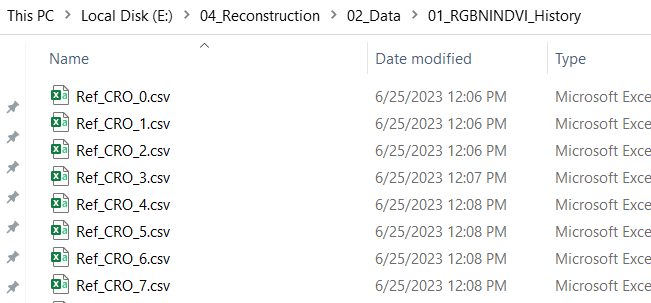
??ЖдгкЦфжаЕФУПвЛИі.csvЮФМўЃЌЖМгазХШчЯТЭМЫљЪОЕФЪ§ОнИёЪНЁЃ
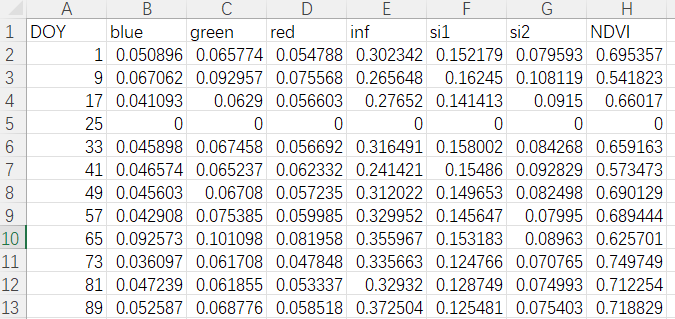
??ЮвУЧЯждкЕФашЧѓЪЧЃЌЯЃЭћЖдгкУПвЛИіУћГЦЮЊRef_GRA_Y.csvИёЪНЕФ.csvЮФМўЃЌЧѓШЁЦфжаУПвЛИіЕЅдЊИёдкЫљгаЮФМўжаЪ§ОнЕФЦНОљжЕЁЃР§ШчЃЌЖдгкЩЯЭМжаDOYЮЊ1ЕФblueетИіЕЅдЊИёЃЌФЧУДЧѓГіРДЕФЦНОљжЕОЭЪЧдкШЋВПУћГЦЮЊRef_GRA_Y.csvИёЪНЕФ.csvЮФМўжЎжаЃЌDOYЮЊ1ЧвСаУћЮЊblueЕФЕЅдЊИёЕФЦНОљжЕЁЃДЫЭтЃЌШчЙћЯёЩЯЭМвЛбљЃЌГіЯжСЫВПЗжЕЅдЊИёЪ§жЕЮЊ0ЕФЧщПіЃЌБэУїдкЕБЧАЮФМўМаЯТЃЌетИіЕЅдЊИёЪЧУЛгаЪ§ОнЕФЃЌвђДЫашвЊдкМЦЫуЕФЪБКђЩсШЅЃЈВЂЧвШЁЦНОљжЕЪБКђЕФЗжФИвВвЊМѕаЁ1ЃЉЁЃ
??жЊЕРСЫашЧѓЃЌЮвУЧОЭПЩвдПЊЪМДњТыЕФЪщаДЁЃЦфжаЃЌБОЮФгУЕНЕФОпЬхДњТыШчЯТЫљЪОЁЃДЫЭтЃЌБОЮФЪЕЯжЕФашЧѓвВКЭЮвУЧжЎЧАЕФЮФеТЛљгкPythonЖСШЁЖрИіExcelЮФМўЪ§ОнВЂПчдНВЛЭЌxlsxБэИёЮФМўМЦЫуЦНОљжЕЃЈhttps://blog.csdn.net/zhebushibiaoshifu/article/details/115533619ЃЉгааЉРрЫЦЃЌДѓМвШчЙћгаашвЊЃЌвВПЩвдВЮПМжЎЧАЕФетвЛЦЊЮФеТЁЃ
# -*- coding: utf-8 -*- """ Created on Fri Oct 6 13:07:48 2023 @author: fkxxgis """ import os import glob import pandas as pd folder_path = "E:/04_Reconstruction/02_Data/01_RGBNINDVI_History" output_path = "E:/04_Reconstruction/02_Data" file_pattern = "Ref_GRA_*.csv" file_paths = glob.glob(os.path.join(folder_path, file_pattern)) combined_data = pd.DataFrame() for file_path in file_paths: df = pd.read_csv(file_path) df_filtered = df[df != 0] combined_data = pd.concat([combined_data, df_filtered]) average_values = combined_data.groupby('DOY').mean() output_file = "04_Data_YearAverage.csv" average_values.to_csv(os.path.join(output_path,output_file), index=True)
??ЦфжаЃЌЩЯЪіДњТыЕФОпЬхНщЩмШчЯТЁЃ
??ЪзЯШЃЌЮвУЧЕМШыБивЊЕФПтЁЊЁЊosПтгУгкЮФМўТЗОЖВйзїЃЌglobПтгУгкЮФМўЦЅХфЃЌpandasПтгУгкЪ§ОнДІРэКЭЗжЮіЁЃЭЌЪБЃЌЮвУЧЖЈвхЮФМўМаТЗОЖfolder_pathЃЌДњБэДцДЂ.csvЮФМўЕФЮФМўМаТЗОЖЃЛЖЈвхЪфГіТЗОЖoutput_pathЃЌДњБэБЃДцНсЙћЮФМўЕФТЗОЖЃЛЖЈвхЮФМўЦЅХфФЃЪНfile_patternЃЌгУгкЦЅХфашвЊДІРэЕФ.csvЮФМўЕФЮФМўУћФЃЪНЁЃ
??ЫцКѓЃЌЮвУЧЪЙгУglob.glob()КЏЪ§НсКЯЮФМўМаТЗОЖКЭЮФМўЦЅХфФЃЪНЃЌЛёШЁТњзуЬѕМўЕФ.csvЮФМўЕФТЗОЖСаБэЃЌДцДЂдкfile_pathsБфСПжаЁЃДДНЈвЛИіПеЕФЪ§ОнПђcombined_dataЃЌгУгкДцДЂЫљгаЮФМўЕФЪ§ОнЁЃ
??НгЯТРДЃЌЮвУЧЪЙгУвЛИібЛЗЃЌБщРњfile_pathsСаБэжаЕФУПИіЮФМўТЗОЖЁЃЖдгкУПИіЮФМўТЗОЖЃЌЪЙгУpd.read_csv()КЏЪ§Мгди.csvЮФМўЃЌВЂНЋЦфДцДЂдкУћЮЊdfЕФЪ§ОнПђжаЁЃЦфДЮЃЌЪЙгУЬѕМўЩИбЁгяОфdf[df != 0]ХХГ§жЕЮЊ0ЕФЪ§ОнЃЌВЂНЋНсЙћДцДЂдкУћЮЊdf_filteredЕФЪ§ОнПђжаЁЃНєНгзХЃЌНЋЕБЧАЮФМўЕФЪ§ОнПђdf_filteredКЯВЂЕНзмЪ§ОнПђcombined_dataжаЃЌетвЛВНжшЪЙгУpd.concat()КЏЪ§ЪЕЯжЁЃ
??ЭъГЩЫљгаЮФМўЕФДІРэКѓЃЌЪЙгУcombined_data.groupby('DOY').mean()МЦЫуЫљгаЮФМўЕФЦНОљжЕЃЌАДееDOYСаНјааЗжзщВЂЧѓЦНОљжЕЁЃЫцКѓЃЌЖЈвхЪфГіЮФМўУћoutput_fileЃЌДњБэБЃДцЦНОљжЕНсЙћЕФЮФМўУћЁЃ
??зюКѓЃЌЪЙгУos.path.join()КЏЪ§НсКЯЪфГіТЗОЖКЭЪфГіЮФМўУћЃЌЩњГЩБЃДцТЗОЖЃЌВЂЪЙгУaverage_values.to_csv()КЏЪ§НЋЦНОљжЕЪ§ОнПђaverage_valuesБЃДцЮЊвЛИіаТЕФ.csvЮФМўЃЌжИЖЈindex=TrueвдАќКЌЫїв§СаЁЃ
??дЫааЩЯЪіДњТыЃЌЮвУЧМДПЩЕУЕННсЙћЮФМўЁЃШчЯТЭМЫљЪОЃЌПЩвдПДЕННсЙћЮФМўжаЃЌвбОЪЧМЦЫужЎКѓЕФЦНОљжЕНсЙћСЫЁЃ

??жСДЫЃЌДѓЙІИцГЩЁЃ
ЛЖгЙизЂЃКЗшПёбЇЯАGIS