1 в§бд
ЛњЦїбЇЯАФЃаЭЦРЙРЪЧЛњЦїбЇЯАСьгђжаЕФвЛИіживЊбаОПЗНЯђЃЌЦфбаОПБГОАдкгкЫцзХДѓЪ§ОнЪБДњЕФЕНРДЃЌШЫУЧУцСйзХдНРДдНЖрЕФЪ§ОнЗжЮіКЭДІРэШЮЮёЃЌЖјЛњЦїбЇЯАзїЮЊвЛжжИпаЇЕФЪ§ОнДІРэММЪѕЃЌдкКмЖрСьгђЖМЕУЕНСЫЙуЗКгІгУЁЃШЛЖјЃЌЛњЦїбЇЯАФЃаЭЕФаЇЙћЦРЙРЪЧЛњЦїбЇЯАгІгУЙ§ГЬжавЛИіЗЧГЃЙиМќЕФЮЪЬтЃЌвђДЫЛњЦїбЇЯАФЃаЭЦРЙРЕФбаОПОпгаЗЧГЃживЊЕФвтвхЁЃ
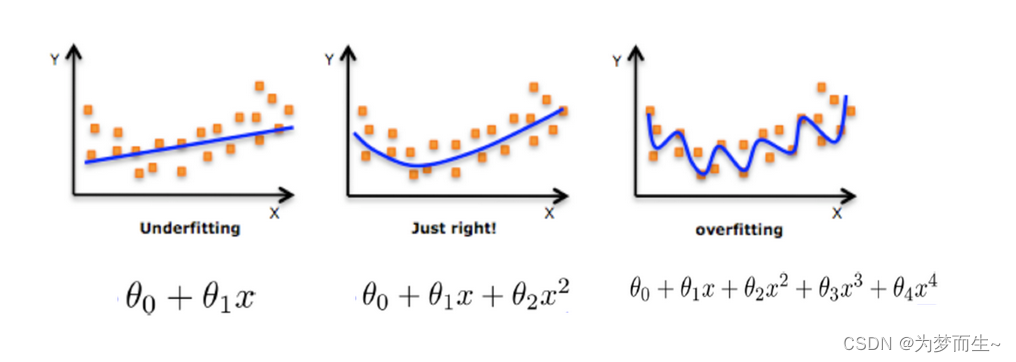
- баОПЮЪЬтЃК
ЛњЦїбЇЯАФЃаЭЦРЙРЕФбаОПЮЪЬтжївЊАќРЈЃКШчКЮбЁдёКЯЪЪЕФЦРЙРжИБъЁЂШчКЮШЗЖЈЦРЙРЕФЪЕбщЩшМЦЁЂШчКЮРћгУЦРЙРНсЙћЖдФЃаЭНјаагХЛЏЕШЁЃДЫЭтЃЌгЩгкЛњЦїбЇЯАФЃаЭЕФИДдгадКЭЖрбљадЃЌЦРЙРЗНЗЈЕФбЁдёКЭЩшМЦвВЪЧашвЊНтОіЕФживЊЮЪЬтЁЃ
- баОПвтвхЃК
ЛњЦїбЇЯАФЃаЭЦРЙРЕФбаОПвтвхдкгкЃК
- ЬсИпФЃаЭЕФдЄВтОЋЖШКЭЗКЛЏФмСІЃЛ
- АяжњЮвУЧИќКУЕиРэНтФЃаЭЕФФкВПЛњжЦКЭадФмЃЛ
- ЮЊФЃаЭгХЛЏКЭИФНјЬсЙЉвРОнЃЛ
- гІгУгкЪЕМЪЮЪЬтЕФНтОіЃЌЬсИпЩњВњСІКЭаЇТЪЁЃ
2 ЯрЙиЮФЯззлЪі
- ЛњЦїбЇЯАФЃаЭЦРЙРИХЪіЃК
ЛњЦїбЇЯАФЃаЭЦРЙРЪЧЖдФЃаЭадФмНјааСПЛЏКЭгХЛЏЕФЙ§ГЬЁЃЦРЙРВЛНіЩцМАЖдФЃаЭдкбЕСЗМЏЩЯЕФадФмПМВьЃЌЛЙАќРЈдкВтЪдМЏЩЯЕФБэЯжЦРЙРЁЃбЕСЗМЏгУгкбЕСЗФЃаЭЃЌВтЪдМЏдђгУгкбщжЄФЃаЭдкаТЪ§ОнЩЯЕФЗКЛЏФмСІЁЃДЫЭтЃЌЮЊСЫГфЗжСЫНтФЃаЭЕФадФмЃЌЛЙГЃГЃВЩгУНЛВцбщжЄЕШММЪѕНјааЦРЙРЁЃ
- ФЃаЭЦРЙРЕФадФмЖШСПжИБъЃК
адФмЖШСПжИБъЪЧЦРЙРЛњЦїбЇЯАФЃаЭадФмЕФЙиМќЙЄОпЁЃГЃгУЕФадФмЖШСПжИБъАќРЈзМШЗТЪЁЂОЋШЗТЪЁЂейЛиТЪЁЂF1ЗжЪ§ЁЂROC AUCУцЛ§ЕШЁЃетаЉжИБъПЩгУгкЖўЗжРрЁЂЖрЗжРрКЭЛиЙщЕШВЛЭЌРраЭЕФЛњЦїбЇЯАЮЪЬтЁЃ
зМШЗТЪБэЪОдЄВте§ШЗЕФбљБОЪ§еМзмбљБОЪ§ЕФБШР§ЃЌОЋШЗТЪКЭейЛиТЪдђЗжБ№БэЪОдЄВтЮЊе§ЧвШЗЪЕЮЊе§ЕФбљБОЪ§вдМАдЄВтЮЊИКЧвШЗЪЕЮЊИКЕФбљБОЪ§ЫљеМЕФБШР§ЁЃ
F1ЗжЪ§ЪЧОЋШЗТЪКЭейЛиТЪЕФЕїКЭЦНОљЪ§ЃЌгУгкзлКЯПМТЧЖўепЕФадФмЁЃ
ROCЁЂAUCУцЛ§дђЪЧвЛжжГЃгУЕФЗжРрадФмжИБъЃЌЫќБэЪОдкЫљгаПЩФмЕФЗжРруажЕЯТФЃаЭЕФROCЧњЯпгыy=xЯпжЎМфЕФУцЛ§ЁЃ

- жївЊФЃаЭЦРЙРЗНЗЈЃК
жївЊЕФФЃаЭЦРЙРЗНЗЈАќРЈФкВПЦРЙРКЭЭтВПЦРЙРЁЃ
ФкВПЦРЙРжївЊЛљгкбЕСЗМЏКЭВтЪдМЏНјааЃЌШчзМШЗТЪЁЂОЋШЗТЪЁЂейЛиТЪКЭF1ЗжЪ§ЕШЁЃ
ЭтВПЦРЙРдђЭЈЙ§БШНЯФЃаЭгыЦфЫћЛљзМФЃаЭЕФадФмРДНјааЦРЙРЃЌШчROC AUCУцЛ§КЭНЛВцбщжЄЕШЁЃДЫЭтЃЌЮЊСЫГфЗжСЫНтФЃаЭЕФадФмЃЌЛЙГЃГЃВЩгУНЛВцбщжЄЕШММЪѕНјааЦРЙРЁЃ
- ЯжгабаОПВЛзугыЮЪЬтЃК
ОЁЙмвбОгаКмЖрЙигкЛњЦїбЇЯАФЃаЭЦРЙРЕФбаОПЃЌЕЋШдДцдквЛаЉВЛзуКЭЮЪЬтЁЃЪзЯШЃЌВЛЭЌЕФЦРЙРжИБъПЩФмЕМжТЦРЙРНсЙћЕФВювьКЭЮѓНтЃЌвђДЫашвЊНїЩїбЁдёКЯЪЪЕФжИБъЁЃЦфДЮЃЌгЩгкЪ§ОнЕФИДдгадКЭФЃаЭЕФЖрбљадЃЌЯжгаЦРЙРЗНЗЈПЩФмЮоЗЈШЋУцЗДгГФЃаЭЕФадФмЃЌвђДЫашвЊПЊЗЂИќМгТГАєКЭЗКЛЏЕФЦРЙРЗНЗЈЁЃ
ДЫЭтЃЌЯжгабаОПЛЙШБЗІЖдВЛЭЌФЃаЭЦРЙРЗНЗЈЕФБШНЯКЭЗжЮіЃЌвђДЫашвЊНјааИќМгЩюШыЕФбаОПвдевГізюМбЕФЦРЙРВпТдЁЃ
3 ФЃаЭЦРЙРжївЊРэТлЁЂЦРЙРЗНЗЈМАадФмЖШСП
3.1 ФЃаЭЦРЙРЕФв§ГіМАЫМПМ
- ОЋЖШгыДэЮѓТЪ
ЮвУЧЭЈГЃНЋЗжРрДэЮѓЕФбљБОЪ§еМзмбљБОЪ§ЕФБШР§ГЦЮЊЁАДэЮѓТЪЁБЃЌвВМДЕБдкmИібљБОжагаІСИібљБОЗжРрДэЮѓЪБЃЌДэЮѓТЪEЕШгкІСГ§вдmЁЃЯргІЕиЃЌ1МѕШЅДэЮѓТЪОЭЪЧОЋЖШЃЌвВМДЁАОЋЖШ=1-ДэЮѓТЪЁБЁЃИќвЛАуЕиЃЌЮвУЧНЋбЇЯАЦїЕФЪЕМЪдЄВтЪфГігыбљБОЕФецЪЕЪфГіжЎМфЕФВювьГЦЮЊЁАЮѓВюЁБЁЃ
- бЕСЗЮѓВюКЭЗКЛЏЮѓВюЁЊЁЊЮввЊЕУЕНЪВУДЃП
ЮвУЧЛЙПЩвдНЋбЇЯАЦїдкбЕСЗМЏЩЯЕФЮѓВюГЦЮЊЁАбЕСЗЮѓВюЁБЛђЁАОбщЮѓВюЁБЃЌдкаТбљБОЩЯЕФЮѓВюГЦЮЊЁАЗКЛЏЮѓВюЁБЁЃЯдШЛЃЌЮвУЧЯЃЭћЕУЕНЗКЛЏЮѓВюаЁЕФбЇЯАЦїЁЃШЛЖјЃЌгЩгкЮвУЧЪТЯШВЂВЛжЊЕРаТбљБОЪЧЪВУДбљЕФЃЌЫљвдЪЕМЪЩЯЮвУЧжЛФмОЁСІЪЙОбщЮѓВюзюаЁЛЏЁЃ
- ОЋЖШдНДѓдНКУЃП
дкКмЖрЧщПіЯТЃЌЮвУЧПЩвдбЇЯАЕНОбщЮѓВюКмаЁЁЂдкбЕСЗМЏЩЯБэЯжКмКУЕФбЇЯАЦїЁЃ
Р§ШчЃЌЩѕжСПЩвдЖдЫљгабЕСЗбљБОЖМЗжРре§ШЗЃЌвВМДЗжРрДэЮѓТЪЮЊСуЃЌЗжРрОЋЖШЮЊ100%ЁЃШЛЖјЃЌетбљЕФбЇЯАЦїЪЧЗёЪЧЮвУЧЯывЊЕФФиЃПвХКЖЕФЪЧЃЌетбљЕФбЇЯАЦїдкЖрЪ§ЧщПіЯТЖМВЛРэЯыЁЃ
3.2 бЇЯАЦїецЕФШчЮвУЧЯывЊЕФвЛбљТ№
ЮвУЧЪЕМЪЯЃЭћЕФЃЌЪЧдкаТбљБОЩЯФмБэЯжЕУКмКУЕФбЇЯАЦїЁЃЮЊСЫЪЕЯжетвЛФПБъЃЌЮвУЧгІИУДгбЕСЗбљБОжабЇЯАГіЪЪгУгкЫљгаЧБдкбљБОЕФЦеБщЙцТЩЃЌвдБудкгіЕНаТбљБОЪБФмЙЛзіГіе§ШЗЕФХаЖЯЁЃ
- Й§ФтКЯгыЧЗФтКЯ
ШЛЖјЃЌЕБбЇЯАЦїЙ§гкЪЪгІбЕСЗбљБОЪБЃЌЫќПЩФмЛсНЋбЕСЗбљБОздЩэЕФФГаЉЬиЕуЪгЮЊЫљгаЧБдкбљБОЖМОпгаЕФвЛАуаджЪЃЌДгЖјЕМжТЗКЛЏадФмЯТНЕЁЃетжжЯжЯѓдкЛњЦїбЇЯАжаГЦЮЊЁАЙ§ФтКЯЁБЁЃгыжЎЯрЖдЕФЪЧЁАЧЗФтКЯЁБЃЌетвтЮЖзХбЇЯАЦїЩаЮДЭъШЋеЦЮебЕСЗбљБОЕФвЛАуаджЪЁЃ

ШчЙћГіЯжЙ§ФтКЯгыЧЗФтКЯЃЌашвЊЪЙгУе§дђЛЏЕШЗНЗЈРДНјааЭьОШЃЌОпЬхЗНЗЈКѓУцЛсНВЕНЁЃ
ШЛЖјБиаыШЯЪЖЕНЃЌЙ§ФтКЯЪЧЮоЗЈГЙЕзБмУтЕФЃЌЮвУЧЫљФмзіЕФжЛЪЧ"ЛКНт"ЛђепЫЕМѕаЁЦфЗчЯеЁЃЙигкетвЛЕуЃЌПЩДѓжТетбљРэНтЃКЛњЦїбЇЯАУцСйЕФЮЪЬтЭЈГЃЪЧ NP ФбЩѕжСИќФбЃЌЖјгааЇЕФбЇЯАЫуЗЈБиШЛЪЧдкЖрЯюЪНЪБМфФкдЫааЭъ ЃЌШєПЩГЙЕзБмУтЙ§ФтКЯЃЌ дђЭЈЙ§ОбщЮѓВюзюаЁЛЏОЭФмЛёзюгХНтЃЌетОЭвтЮЖзХЮвУЧЙЙдьадЕижЄУїСЫЁАP=NPЁБ ЃЛвђДЫЃЌжЛвЊЯраХ "PЁйNPЁБЃЌЙ§ФтКЯОЭВЛПЩБмУтЁЃ
- ШчКЮбЁдёЃП
дкЯжЪЕШЮЮёжаЃЌЮвУЧЭљЭљгаЖржжбЇЯАЫуЗЈЙЉбЁдёЃЌЩѕжСЖдЭЌвЛИібЇЯАЫуЗЈЃЌЕБЪЙгУВЛЭЌЕФВЮЪ§ХфжУ ?вВЛсВњЩњВЛЭЌЕФФЃаЭФЧУДЃЌЮвУЧИУбЁгУФФИібЇЯАЫуЗЈЁЂЪЙгУФФжжВЮЪ§ХфжУФиЃПетОЭЪЧЛњЦїбЇЯАжаЕФ"ФЃаЭбЁдё" (model selection) ЮЪЬтЁЃ
РэЯыЕФНтОіЗНАИЕБШЛЪЧЖдКђбЁФЃаЭЕФЗКЛЏЮѓВюНјааЦРЙРЃЌШЛКѓбЁдёЗКЛЏЮѓВюзюаЁЕФФЧИіФЃаЭЁЃ
ШЛЖјШчЩЯУцЫљЬжТлЕФЃЌЮвУЧЮоЗЈжБНгЛёЕУЗКЛЏЮѓВюЃЌЖјбЕСЗЮѓВюгжгЩгкЙ§ФтКЯЯжЯѓЕФДцдкЖјВЛЪЪКЯзїЮЊБъзМЃЌФЧУДЃЌдкЯжЪЕжаШчКЮНјааФЃаЭЦРЙРгыбЁдёФи?
3.3 ЦРЙРЗНЗЈ
ВтЪдбљБОЮЊЪВУДвЊОЁПЩФмВЛГіЯждкбЕСЗМЏжаФи?
ЮЊРэНтетвЛЕуЃЌВЛЗСПМТЧетбљвЛИіГЁОА:РЯЪІГіСЫ10ЕРЯАЬтЙЉЭЌбЇУЧСЗЯА,ПМЪдЪБРЯЪІгжгУЭЌбљЕФет10ЕРЬтзїЮЊЪдЬт,етИіПМЪдГЩМЈФмЗёгааЇЗДгГГіЭЌбЇУЧбЇЕУКУВЛКУФи?Д№АИЪЧЗёЖЈЕФ,ПЩФмгаЕФЭЌбЇжЛЛсзіет10ЕРЬтШДФмЕУИпЗжЁЃ
ЯЃЭћЕУЕНЗКЛЏадФмЧПЕФФЃаЭ,КУБШЪЧЯЃЭћЭЌбЇУЧЖдПЮГЬбЇЕУКмКУЁЂЛёЕУСЫЖдЫљбЇжЊЪЖЁАОйвЛЗДШ§ЁБЕФФмСІ;бЕСЗбљБОЯрЕБгкИјЭЌбЇУЧСЗЯАЕФЯАЬт,ВтЪдЙ§ГЬдђЯрЕБгкПМЪд.ЯдШЛ,ШєВтЪдбљБОБЛгУзїбЕСЗСЫ,дђЕУЕНЕФНЋЪЧЙ§гкЁАРжЙлЁБЕФЙРМЦНсЙћ.
3.3.1 СєГіЗЈ(Holdout Method)
ЁЎСєГіЗЈЁЏ жБНгНЋЪ§ОнМЏDЛЎЗжЮЊСНИіЛЅГтЕФМЏКЯЃЌЦфжавЛИіМЏКЯзїЮЊбЕСЗМЏSЃЌСэвЛИізїЮЊВтЪдМЏTМДD=SЁШTЃЌSЁЩTЁй?. дкSЩЯбЕСЗГіФЃаЭКѓЃЌгУTРДЦРЙРЦфВтЪдЮѓВюЃЌзїЮЊЗКЛЏЮѓВюЕФЙРМЦашвЊзЂвтЕФЪЧЃЌбЕСЗ/ВтЪдМЏЕФЛЎЗжвЊОЁПЩФмБЃГжЪ§ОнЗжВМЕФвЛжТадЃЌБмУтвђЪ§ОнЛЎЗжЙ§ГЬв§ШыЖюЭтЕФЦЋВюЖјЖдзюжеНсЙћВњЩњгАЯьЃЌдкЗжРрШЮЮёжавЊБЃГжбљБОРрБ№БШР§ЯрЫЦЃЌШЁбљЭЈГЃВЩгУЕФЪЧЁОЗжВуГщбљЁП
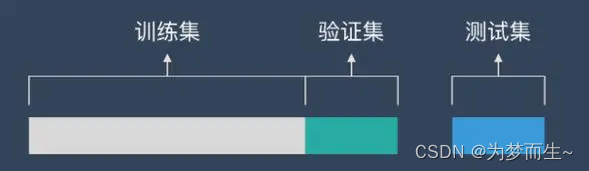
- жївЊВНжшЃК
- НЋдЪМЪ§ОнМЏЗжГЩСНИіВПЗжЃКбЕСЗМЏКЭВтЪдМЏЁЃЭЈГЃЃЌбЕСЗМЏгУгкбЕСЗФЃаЭЃЌВтЪдМЏгУгкЦРЙРФЃаЭЁЃ
- ЪЙгУбЕСЗМЏбЕСЗФЃаЭЁЃ
- ЪЙгУВтЪдМЏЦРЙРФЃаЭЃЌМЦЫуФЃаЭЕФИїЯюадФмжИБъЃЌШчзМШЗТЪЁЂОЋШЗТЪЁЂейЛиТЪЕШЁЃ
- ИљОнВтЪдМЏЕФЦРЙРНсЙћЃЌЖдФЃаЭНјааЕїећКЭгХЛЏЁЃ
- жиИДВНжшb-dЃЌжБЕНФЃаЭадФмДяЕНТњвтЕФЫЎЦНЁЃ
3.3.2 НЛВцбщжЄЗЈ (Cross-Validation Method)
Cross ValidationЃКМђбджЎЃЌОЭЪЧНјааЖрДЮtrain_test_splitЛЎЗжЃЛ
УПДЮЛЎЗжЪБЃЌдкВЛЭЌЕФЪ§ОнМЏЩЯНјаабЕСЗЁЂВтЪдЦРЙРЃЌДгЖјЕУГівЛИіЦРМлНсЙћЃЛШчЙћЪЧ5елНЛВцбщжЄЃЌвтЫМОЭЪЧдкдЪМЪ§ОнМЏЩЯЃЌНјаа5ДЮЛЎЗжЃЌУПДЮЛЎЗжНјаавЛДЮбЕСЗЁЂЦРЙРЃЌзюКѓЕУЕН5ДЮЛЎЗжКѓЕФЦРЙРНсЙћЃЌвЛАудкетМИДЮЦРЙРНсЙћЩЯШЁЦНОљЕУЕНзюКѓЕФЦРЗжЁЃk-fold cross-validation ЃЌЦфжаЃЌkвЛАуШЁ5Лђ10ЁЃ
- НЛВцбщжЄЕФгХЕуЃК
- дЪМВЩгУЕФtrain_test_splitЗНЗЈЃЌЪ§ОнЛЎЗжОпгаХМШЛадЃЛНЛВцбщжЄЭЈЙ§ЖрДЮЛЎЗжЃЌДѓДѓНЕЕЭСЫетжжгЩвЛДЮЫцЛњЛЎЗжДјРДЕФХМШЛадЃЌЭЌЪБЭЈЙ§ЖрДЮЛЎЗжЃЌЖрДЮбЕСЗЃЌФЃаЭвВФмгіЕНИїжжИїбљЕФЪ§ОнЃЌДгЖјЬсИпЦфЗКЛЏФмСІЃЛ
- гыдЪМЕФtrain_test_splitЯрБШЃЌЖдЪ§ОнЕФЪЙгУаЇТЪИќИпЁЃtrain_test_splitЃЌФЌШЯбЕСЗМЏЁЂВтЪдМЏБШР§ЮЊ3:1ЃЌЖјЖдНЛВцбщжЄРДЫЕЃЌШчЙћЪЧ5елНЛВцбщжЄЃЌбЕСЗМЏБШВтЪдМЏЮЊ4:1ЃЛ10елНЛВцбщжЄбЕСЗМЏБШВтЪдМЏЮЊ9:1ЁЃЪ§ОнСПдНДѓЃЌФЃаЭзМШЗТЪдНИпЃЁ
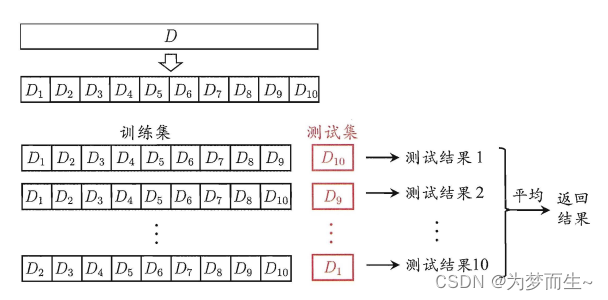
- НЛВцбщжЄЗЈЕФжївЊВНжшЃК
- НЋдЪМЪ§ОнМЏЗжГЩkИіВПЗжЃЌЦфжаk-1ИіВПЗжзїЮЊбЕСЗМЏЃЌЪЃгрЕФВПЗжзїЮЊВтЪдМЏЁЃ
- ЪЙгУk-1ИіВПЗжбЕСЗФЃаЭЁЃ
- ЪЙгУЪЃгрЕФВПЗжВтЪдФЃаЭЃЌМЦЫуФЃаЭЕФИїЯюадФмжИБъЁЃ
- жиИДВНжшb-cЃЌжБЕНУПИіВПЗжЖМБЛгУзїВтЪдМЏвЛДЮЁЃ
- ЖдЫљгаЕФВтЪдНсЙћНјааЦНОљЃЌЕУЕНФЃаЭЕФзюжеадФмжИБъЁЃ
- ИљОнзюжеадФмжИБъЃЌЖдФЃаЭНјааЕїећКЭгХЛЏЁЃ
- жиИДВНжшb-fЃЌжБЕНФЃаЭадФмДяЕНТњвтЕФЫЎЦНЁЃ
3.3.3 зджњЗЈ (Bootstrap Method)
зджњЗЈЪЧвЛжжГЃгУЕФФЃаЭЦРЙРЗНЗЈЃЌЫќЭЈЙ§ДгдЪМЪ§ОнМЏжагаЗХЛиЕиЫцЛњГщШЁбљБОРДЙЙНЈаТЪ§ОнМЏНјаабЕСЗКЭВтЪдЁЃгЩгкУПДЮГщбљПЩФмЛсВњЩњжиИДЕФбљБОЃЌвђДЫаТЪ§ОнМЏЕФДѓаЁгыдЪМЪ§ОнМЏЯрЭЌЃЌЕЋЪЧЦфжаДѓдМга36.8%ЕФбљБОУЛгаГіЯждкаТЪ§ОнМЏжаЁЃетаЉУЛгаГіЯждкаТЪ§ОнМЏжаЕФбљБОБЛгУзїВтЪдМЏЃЌЖјГіЯждкаТЪ§ОнМЏжаЕФбљБОдђБЛгУзїбЕСЗМЏЁЃ
зджњЗЈЕФгХЕуЪЧФмЙЛДггаЯоЕФЪ§ОнМЏжаВњЩњЖрИіВЛЭЌЕФбЕСЗМЏКЭВтЪдМЏЃЌДгЖјИќКУЕиЦРЙРФЃаЭЕФадФмЁЃЕЋЪЧЃЌгЩгкУПДЮГщбљЖМЛсВњЩњВЛЭЌЕФЪ§ОнМЏЃЌвђДЫзджњЗЈЛсв§ШыЖюЭтЕФЫцЛњадЃЌЪЙЕУФЃаЭЦРЙРЕФНсЙћИќМгВЛЮШЖЈЁЃ
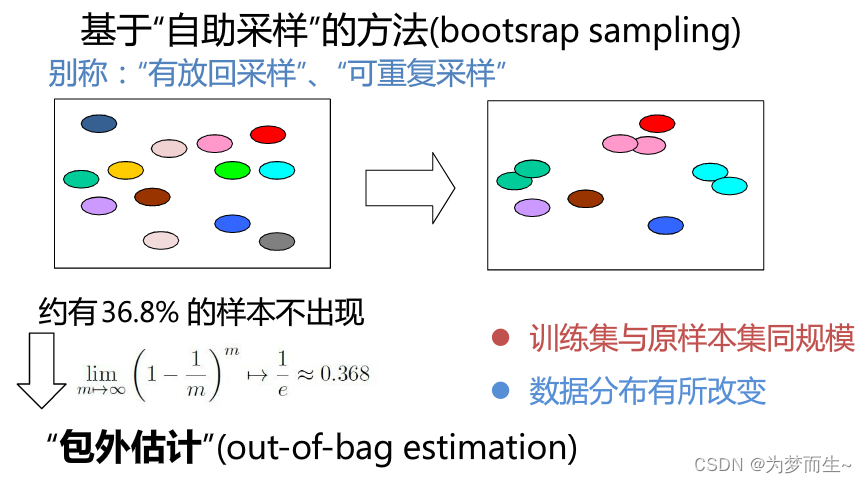
- зджњЗЈЕФВНжшЃК
- ДгдЪМЪ§ОнМЏжаЫцЛњбЁдёnИібљБОЙЙГЩвЛИіаТЕФЪ§ОнМЏЁЃ
- ЪЙгУаТЕФЪ§ОнМЏбЕСЗФЃаЭЁЃ
- ЪЙгУдЪМЪ§ОнМЏВтЪдФЃаЭЃЌМЦЫуФЃаЭЕФИїЯюадФмжИБъЁЃ
- жиИДВНжшa-cЖрДЮЃЈШч1000ДЮЃЉЃЌЕУЕНУПИіадФмжИБъЕФЦНОљжЕКЭБъзМЦЋВюЁЃ
- ИљОнЦНОљжЕКЭБъзМЦЋВюЃЌЖдФЃаЭНјааЕїећКЭгХЛЏЁЃ
- жиИДВНжшa-eЃЌжБЕНФЃаЭадФмДяЕНТњвтЕФЫЎЦНЁЃ
3.4 адФмЖШСП
ЖдбЇЯАЦїЕФЗКЛЏадФмНјааЦРЙРЃЌВЛНіашвЊгааЇПЩааЕФЪЕбщЙРМЦЗНЗЈ,ЛЙашвЊгаКтСПФЃаЭЗКЛЏФмСІЕФЦРМлБъзМ,етОЭЪЧадФмЖШСП(performance measure).
ГЃгУЕФадФмЖШСПАќРЈзМШЗЖШЁЂСщУєЖШЁЂЬивьадЁЂОЋШЗЖШЁЂейЛиТЪЁЂFЖШСПКЭGОљжЕЕШЁЃВЛЭЌЕФадФмЖШСПЛсЕМжТВЛЭЌЕФЦРЙРНсЙћЁЃЦфжаЃЌзМШЗЖШЪЧжИЗжРре§ШЗЕФбљБОЪ§еМзмбљБОЪ§ЕФБШР§ЃЛСщУєЖШЪЧжИецЪЕЮЊе§Р§ЕФбљБОжаБЛе§ШЗдЄВтЮЊе§Р§ЕФБШР§ЃЛЬивьадЪЧжИецЪЕЮЊИКР§ЕФбљБОжаБЛе§ШЗдЄВтЮЊИКР§ЕФБШР§ЃЛОЋШЗЖШЪЧжИБЛе§ШЗдЄВтЮЊе§Р§ЕФбљБОЪ§еМЫљгадЄВтЮЊе§Р§ЕФбљБОЪ§ЕФБШР§ЃЛейЛиТЪЪЧжИецЪЕЮЊе§Р§ЕФбљБОжаБЛе§ШЗдЄВтЮЊе§Р§ЕФБШР§ЃЛFЖШСПЪЧОЋШЗЖШКЭейЛиТЪЕФМгШЈЕїКЭЦНОљЪ§ЃЛGОљжЕЪЧСщУєЖШКЭЬивьадЕФГЫЛ§ЕФЦНЗНИљЁЃ
3.4.1ВщзМТЪЁЂВщШЋТЪгыF1
- ВщзМТЪЃЈPrecisionЃЉЃКЪЧжИдЄВтНсЙћжаеце§Р§ЃЈTrue PositiveЃЌTPЃЉеМЫљгадЄВтНсЙћжае§Р§ЃЈPositiveЃЌTP+FPЃЉЕФБШР§ЁЃЙЋЪНЮЊЃКPrecision = TP / (TP + FP)ЁЃВщзМТЪдНИпЃЌЫЕУїФЃаЭдЄВтНсЙћжаеце§Р§ЕФБШР§дНИпЃЌФЃаЭЖдгке§бљБОЕФЪЖБ№ФмСІдНЧПЁЃ
- ВщШЋТЪЃЈRecallЃЉЃКЪЧжИдЄВтНсЙћжаеце§Р§ЃЈTrue PositiveЃЌTPЃЉеМЫљгаЪЕМЪе§Р§ЃЈPositiveЃЌTP+FNЃЉЕФБШР§ЁЃЙЋЪНЮЊЃКRecall = TP / (TP + FN)ЁЃВщШЋТЪдНИпЃЌЫЕУїФЃаЭФмЙЛГЩЙІдЄВтГіЕФе§бљБОБШР§дНИпЃЌФЃаЭЕФЪЖБ№ФмСІдНШЋУцЁЃ
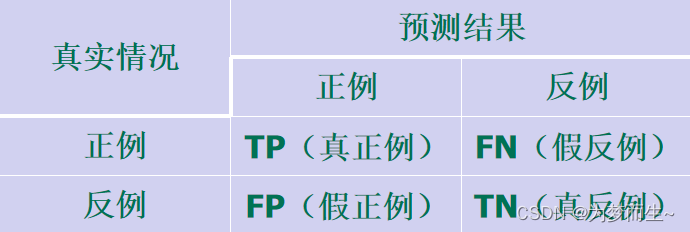
- F1жЕЃКЪЧВщзМТЪКЭВщШЋТЪЕФЕїКЭОљжЕЃЌгУгкзлКЯЦРМлФЃаЭЕФадФмЁЃЙЋЪНЮЊЃКF1 = 2 * (Precision * Recall) / (Precision + Recall)ЁЃF1жЕдНИпЃЌЫЕУїФЃаЭдкзМШЗадКЭПЩППадЗНУцЕФБэЯжЖМНЯКУЁЃ

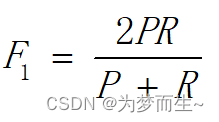
3.4.2 P-RЧњЯп
ВщзМТЪКЭВщШЋТЪЪЧвЛЖдУЌЖмЕФЖШСП.вЛАуРДЫЕЃЌВщзМТЪИпЪБЃЌВщШЋТЪЭљЭљЦЋЕЭ;ЖјВщШЋТЪИпЪБ,ВщзМТЪЭљЭљЦЋЕЭЁЃ
дкКмЖрЧщаЮЯТ,ЮвУЧПЩИљОнбЇЯАЦїЕФдЄВтНсЙћЖдбљР§НјааХХађ,ХХдкЧАУцЕФЪЧбЇЯАЦїШЯЮЊЁАзюПЩФмЁБЪЧе§Р§ЕФбљБО,ХХдкзюКѓЕФдђЪЧбЇЯАЦїШЯЮЊЁАзюВЛПЩФмЁБЪЧе§Р§ЕФбљБОЁЃ
АДДЫЫГађж№ИіАббљБОзїЮЊе§Р§НјаадЄВт,дђУПДЮПЩвдМЦЫуГіЕБЧАЕФВщШЋТЪЁЂВщзМТЪЁЃ
вдВщзМТЪЮЊзнжсЁЂВщШЋТЪЮЊКсжсзїЭМ,ОЭЕУЕНСЫВщзМТЪ-ВщШЋТЪЧњЯп,МђГЦЁАP-RЧњЯпЁБЃЌЯдЪОИУЧњЯпЕФЭМГЦЮЊЁАP-RЭМЁБ.

3.4.3 ROCгыAUC
ROCЃЈReceiver Operating CharacteristicЃЉЧњЯпКЭAUCЃЈArea Under CurveЃЉГЃБЛгУРДЦРМлвЛИіЖўжЕЗжРрЦїЃЈbinary classifierЃЉЕФгХСгЁЃROCЧњЯпвВГЦЮЊЪмЪдепЙЄзїЬиеїЧњЯпЃЈreceiver operating characteristic curveЃЌМђГЦROCЧњЯпЃЉЃЌгжГЦЮЊИаЪмадЧњЯпЃЈsensitivity curveЃЉЁЃ
- ROCЧњЯпЃКЫќЭЈЙ§НЋеце§Р§ТЪЃЈTrue Positive RateЃЌTPRЃЉКЭМйе§Р§ТЪЃЈFalse Positive RateЃЌFPRЃЉзїЮЊКсзнзјБъРДУшЛцЗжРрЦїдкВЛЭЌуажЕЯТЕФадФмЁЃ
гыP-RЧњЯпЯрЫЦЃЌИљОнбЇЯАЦїЕФдЄВтНсЙћЖдбљР§НјааХХађЃЌАДДЫЫГађж№ИіАббљБОзїЮЊе§Р§НјаадЄВтЃЌУПДЮМЦЫуГіСНИіживЊСПЕФжЕЃЌЗжБ№вдЫќУЧЮЊКсЁЂзнзјБъзїЭМЃЌОЭЕУЕНСЫROCЧњЯпЃЌгыP-RЧњЯпЪЙгУВщзМТЪЁЂВщШЋТЪЮЊзнЁЂКсжсВЛЭЌЃЌROCЧњЯпЕФзнжсЪЧеце§Р§ТЪTPRЃЌКсжсЪЧМйе§Р§ТЪFPR
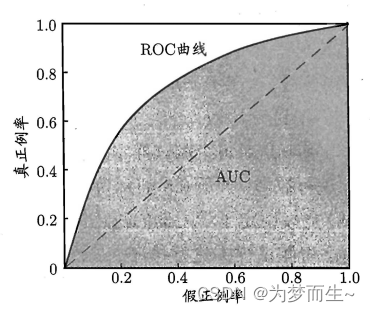
AUCЃКAUCЪЧROCЧњЯпЯТЕФУцЛ§ЃЌГЃгУгкЦРЙРФЃаЭдкЖўЗжРрЮЪЬтжаЕФадФмЁЃ
НјаабЇЯАЦїЕФБШНЯЪБЃЌгыP-R ЭМЯрЫЦШєвЛИібЇЯАЦїЕФ ROC ЧњЯпБЛСэИібЇЯАЦїЕФЧњЯпЭъШЋЁААќзЁЁБЃЌдђПЩЖЯбдКѓепЕФадФмгХгкЧАеп; ШєСНИібЇЯАЦїЕФ ROC ЧњЯпЗЂЩњНЛВцдђФбвдвЛАуадЕиЖЯбдСНепЪыгХЖиСг.ДЫЪБШчЙћвЛЖЈвЊНјааБШНЯ.дђНЯЮЊКЯРэЕФХаОнЪЧБШНЯ ROC ЧњЯпЯТЕФУцЛ§МДAUC(Area Under ROC Curve)

3.4.4 ДњМлУєИаДэЮѓТЪгыДњМлОиеѓ
дкЯжЪЕШЮЮёжаГЃЛсгіЕНетбљЕФЧщПі: ВЛЭЌРраЭЕФДэЮѓЫљдьГЩЕФКѓЙћВЛЭЌЁЃР§ШчдквНСЦеяЖЯжа,ДэЮѓЕиАбЛМепеяЖЯЮЊНЁПЕШЫгыДэЮѓЕиАбНЁПЕШЫеяЖЯЮЊЛМепПДЦ№РДЖМЪЧЗИСЫЁАвЛДЮДэЮѓЁБ,ЕЋКѓепЕФгАЯьЪЧдіМгСЫНјвЛВНМьВщЕФТщЗГ,ЧАепЕФКѓЙћШДПЩФмЪЧЩЅЪЇСЫеќОШЩњУќЕФзюМбЪБЛњ:дйШчУХНћЯЕЭГДэЮѓЕиАбПЩЭЈааШЫдБРЙдкУХЭтЃЌНЋЪЙЕУгУЛЇЬхбщВЛМб,ЕЋДэЮѓЕиАбФАЩњШЫЗХНјУХФкЃЌдђЛсдьГЩбЯжиЕФАВШЋЪТЙЪ.ЮЊШЈКтВЛЭЌРраЭДэЮѓЫљдьГЩЕФВЛЭЌЫ№ЪЇПЩЮЊДэЮѓИГгшЁАЗЧОљЕШДњМлЁБ(unequal cost)ЁЃ

costijБэЪОНЋЕкiРрбљБОдЄВтЮЊЕкjРрбљБОЕФДњМлЁЃ
МйЩшНЋЕк0РрзїЮЊе§РрЃЌЕк1РрзїЮЊЗДРрЃЌСюD+ЮЊе§Р§МЏЃЌD-ЮЊИКР§МЏЁЃЁАДњМлУєИаЁБЃЈcost-sensitiveЃЉДэЮѓТЪЮЊЃК

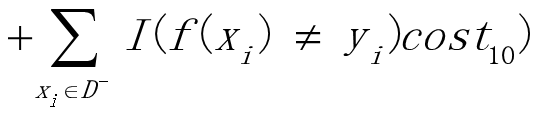

ДњМлЧњЯпЛЗЈЃК
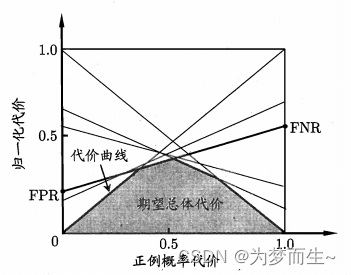
- ЩшROCЧњЯпЩЯЕуЕФзјБъЮЊЃЈFPR,TPRЃЉЃЌдђПЩМЦЫуГіЯргІЕФFNR=1-TPR
- дкДњМлЦНУцЩЯЛцжЦвЛЬѕДгЃЈ0, FPRЃЉЕНЃЈ1, FNRЃЉЕФЯпЖЮЃЌЯпЖЮЯТЕФУцЛ§МДБэЪОСЫИУЬѕМўЯТЕФЦкЭћзмЬхДњМлЃЛ
- ШчДЫНЋROCЧњЯпЩЯЕФУПИіЕузЊЛЏЮЊДњМлЦНУцЩЯЕФвЛЬѕЯпЖЮЃЌШЛКѓШЅЫљгаЯпЖЮЕФЯТНчЃЌЮЇГЩЕФУцЛ§МДЮЊдкЫљгаЬѕМўЯТбЇЯАЦкЕФзмЬхДњМлЁЃ
зЂЃКВПЗжФкШнгыЭМЦЌРДздЁЖЛњЦїбЇЯАЁЗЁЊЁЊжмжОЛЊ
