ашЧѓ
ЖдИјЖЈЕФЯШбщЪ§ОнМЏЃЌЪЙгУlogisticЛиЙщЫуЗЈЖдаТЪ§ОнЗжРр
ДњТыЪЕЯж
1.ЖЈвхsigmoidКЏЪ§
def loadDataSet(): dataMat = []; labelMat = [] fr = open('d:/testSet.txt') for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) labelMat.append(int(lineArr[2])) return dataMat,labelMat def sigmoid(inX): return 1.0/(1+exp(-inX))
2.ЗЕЛиЛиЙщЯЕЪ§
ЖдгІгкУПИіЬиеїжЕЃЌforбЛЗЪЕЯжСЫЕнЙщЬнЖШЩЯЩ§ЫуЗЈЁЃ
def gradAscent(dataMatIn, classLabels): dataMatrix = mat(dataMatIn) #НЋЯШбщЪ§ОнМЏзЊЛЛЮЊNumPy Оиеѓ labelMat = mat(classLabels).transpose() #НЋЯШбщЪ§ОнЕФРрБъЧЉзЊЛЛЮЊNumPy Оиеѓ m,n = shape(dataMatrix) alpha = 0.001 #ЩшжУБЦНќВНГЄЕїећЯЕЪ§ maxCycles = 500 #ЩшжУзюДѓЕќДњДЮЪ§ЮЊ500 weights = ones((n,1)) #weightsМДЮЊашвЊЕќДњЧѓНтЕФВЮЪ§ЯђСП for k in range(maxCycles): #heavy on matrix operations h = sigmoid(dataMatrix*weights) #ДњШыбљБОЯђСПЧѓЕУЁАбљБОyЁБsigmoidзЊЛЛжЕ error = (labelMat - h) #ЧѓВю weights = weights + alpha * dataMatrix.transpose()* error #ИљОнВюжЕЕїећВЮЪ§ЯђСП return weights
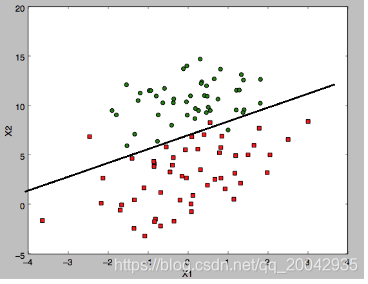
ЮвУЧЕФЪ§ОнМЏгаСНИіЬиеїжЕЗжБ№ЪЧx1ЃЌx2ЁЃдкДњТыжагждіЩшСЫx0БфСПЁЃ
НсЙћЃЌЗЕЛиСЫЬиеїжЕЕФЛиЙщЯЕЪ§ЃК
[[ 4.12414349] [ 0.48007329] [-0.6168482 ]]
ЮвУЧЕУГіx1КЭx2ЕФЙиЯЕЃЈЩшx0=1ЃЉЃЌ0=4.12414349+0.48007329x1-0.6168482x2
3.ЯпадФтКЯЯп
ЛГіx1гыx2ЕФЙиЯЕЭМЁЊЁЊЯпадФтКЯЯп