ЁОMATLABЕк34ЦкЁП MATLAB 2023ФъзиамЫуЗЈ BOA-LSTMЪБМфађСадЄВтФЃаЭ #КЌдЄВтЮДРДЙІФмЃЌвдМАгХЛЏНсЙЙВуЪ§МАЕЅЫЋЯђРраЭ баОПЙЄзїСПЗсИЛЧваТгБ
вЛЁЂДњТыгХЪЦ
1.ЪЙгУ2023ФъзиамЫуЗЈBOAгХЛЏLSTMГЌВЮЪ§ЃЈбЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§ЃЌНсЙЙВуЪ§ЃЌЕЅЫЋЯђНсЙЙРраЭЃЉ
2.ФПБъКЏЪ§ПМТЧбЕСЗМЏКЭВтЪдМЏЃЌИќМгКЯРэЃЛдЫааНсЙћЮШЖЈЃЌПЩжБНгЕїгУНсЙћЃЌЧвЕїгУНсЙћЗЧГЃЗНБуЁЃ
3.ЛЌЖЏДАПкЗНЗЈДІРэЕЅСаЪБМфађСаЪ§ОнЃЌПМТЧРњЪЗЪ§ОнЕФгАЯьЁЃ
4.ДњТывЛЬхЛЏЃЌвЛМќдЫааЃЛзЂЪЭЗсИЛЃЌЦРМлжИБъЗсИЛЃЌТпМЧхЮњЃЌЪЪКЯаЁАзбЇЯАЁЃ
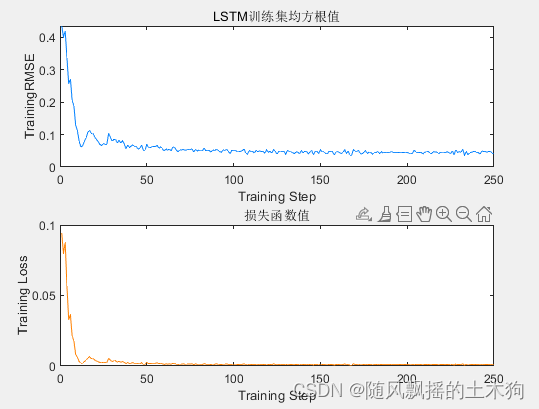
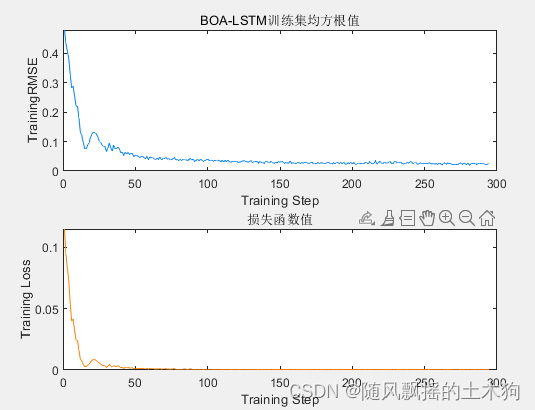
5.ДњТыЛцЭМЗсИЛЃЈГ§ЛљДЁЛцЭМвдЭтЃЌЛЙАќРЈбЕСЗLOSSЭМЁЂГЌВЮЪ§ЕќДњЭМЃЉЁЂУРЙл
6.УќСюааДАПкПЩМћдЫааЙ§ГЬЕФНсЙћ.
7.ВЮЪ§ПЩдкДњТыжаЩшжУЃЌЗНБуЕїЪдЃЛгХЛЏГЌВЮЪ§ПЩвдИљОнашЧѓИќИФ ЁЃ
8.КЌдЄВтЮДРДЙІФмЁЃ
9.КЌНсЙЙВуЪ§ЃЌвдМАLSTMЕЅЫЋЯђбЁдёЙІФм
ОйР§ЃК
1.ЛцЭМУРЙлЃЌЧвАќКЌЖдГЌВЮЪ§ЫцЕќДњДЮЪ§БфЛЏЕФбаОПЁЃ
2.ДњТыЗНБуМЦЫуКЭЕїгУЃЌжЛашвЊдкfunКЏЪ§КѓУцМгГЌВЮЪ§зщКЯЃЌОЭФмЕУЕННсЙћЁЃ
[fitness1,net1,res1,info1] = fun([0.005,50,0.005,50,1,2]); % ЛљДЁВЮЪ§ШЁжЕ(бЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§ЃЌ1ВуНсЙЙЃЌЕЅЯђLSTM)
3.КЌдЄВтЮДРДЙІФм

ЖўЁЂКѓЦкбаОПМЦЛЎ
КѓајНЋдкВЉЮФжаИќаТИќЗсИЛЁЂЙІФмИќЭъећЕФзїЦЗЃЌОДЧыЦкД§ЁЃ
1.ЖрВуLSTMНсЙЙгХЛЏЃЌКЌЕЅЯђLSTM/GRUКЭЫЋЯђBilstmЛьКЯФЃаЭ**ЃЈвбНтОіЖрВугХЛЏЁЃЛьКЯгХЛЏднЮДНтОіЃЉ**
2.ИќЖрГЌВЮЪ§гХЛЏЃЌКЌНсЙЙВуЪ§СПЁЂвўКЌВуНкЕуЪ§ЁЂзюаЁХњДІРэЪ§СПЁЂЪБМфВНЪ§ЕШ**ЃЈвбНтОіЖрВуНсЙЙВугХЛЏЃЌЦфгрВЮЪ§КУЪЕЯжЃЌИљОнОпЬхЪ§ОнЧщПіздааЬэМгЃЉ**
3.КЌдЄВтЮДРДЙІФм**ЃЈвбНтОіЃЉ**
4.ИќЖраТЕФЫуЗЈвдМАдкЛљДЁЩЯИФНјЫуЗЈЖдБШ**ЃЈвбНтОіЃЌМћ35ЦкЃЉ**ЁЃ
5.lossФкжУКЏЪ§аоИФ
6.ЖрГЁОАгІгУЃЈЗжРрЁЂЛиЙщЁЂЖрЪфШыЖрЪфГіЕШЕШЃЉ
Ш§ЁЂДњТыеЙЪО
%% 1.ЧхПеЛЗОГБфСП warning off % ЙиБеБЈОЏаХЯЂ close all % ЙиБеПЊЦєЕФЭМДА clear % ЧхПеБфСП clc % ЧхПеУќСюаа %% 2.ЕМШыЪ§ОнЃЈЪБМфађСаЕФЕЅСаЪ§ОнЃЉ result = xlsread('Ъ§ОнМЏ.xlsx'); %% 3.Ъ§ОнЗжЮі num_samples = length(result); % бљБОИіЪ§ kim = 15; % бгЪБВНГЄЃЈkimИіРњЪЗЪ§ОнзїЮЊздБфСПЃЉ zim = 1; % ПчzimИіЪБМфЕуНјаадЄВт %% 4.ЛЎЗжЪ§ОнМЏ for i = 1: num_samples - kim - zim + 1 res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)]; end %% 5.Ъ§ОнМЏЗжЮі outdim = 1; % зюКѓвЛСаЮЊЪфГі num_size = 0.7; % бЕСЗМЏеМЪ§ОнМЏБШР§ num_train_s = round(num_size * num_samples); % бЕСЗМЏбљБОИіЪ§ f_ = size(res, 2) - outdim; % ЪфШыЬиеїЮЌЖШ %% 6.ЛЎЗжбЕСЗМЏКЭВтЪдМЏ P_train = res(1: num_train_s, 1: f_)'; T_train = res(1: num_train_s, f_ + 1: end)'; M = size(P_train, 2); P_test = res(num_train_s + 1: end, 1: f_)'; T_test = res(num_train_s + 1: end, f_ + 1: end)'; N = size(P_test, 2); %% 7.Ъ§ОнЙщвЛЛЏ [P_train, ps_input] = mapminmax(P_train, 0, 1); P_test = mapminmax('apply', P_test, ps_input); [t_train, ps_output] = mapminmax(T_train, 0, 1); t_test = mapminmax('apply', T_test, ps_output); %% 8.Ъ§ОнЦНЦЬ % НЋЪ§ОнЦНЦЬГЩ1ЮЌЪ§ОнжЛЪЧвЛжжДІРэЗНЪН % вВПЩвдЦНЦЬГЩ2ЮЌЪ§ОнЃЌвдМА3ЮЌЪ§ОнЃЌашвЊаоИФЖдгІФЃаЭНсЙЙ % ЕЋЪЧгІИУЪМжеКЭЪфШыВуЪ§ОнНсЙЙБЃГжвЛжТ P_train = double(reshape(P_train, f_, 1, 1, M)); P_test = double(reshape(P_test , f_, 1, 1, N)); t_train = t_train'; t_test = t_test' ; %% 9.Ъ§ОнИёЪНзЊЛЛ for i = 1 : M p_train{i, 1} = P_train(:, :, 1, i); end for i = 1 : N p_test{i, 1} = P_test( :, :, 1, i); end %% 10.гХЛЏЫуЗЈВЮЪ§ЩшжУ SearchAgents_no = 5; % жжШКЪ§СП Max_iteration = 5; % зюДѓЕќДњДЮЪ§ lb = [1e-3, 10, 1e-4,20,1,1]; % ВЮЪ§ШЁжЕЯТНч(бЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§,вўКЌВуВуЪ§ЃЌLSTMЕЅЫЋЯђНсЙЙ) ub = [1e-2, 80, 1e-3,100,4,2]; % ВЮЪ§ШЁжЕЩЯНч(бЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§,вўКЌВуВуЪ§ЃЌLSTMЕЅЫЋЯђНсЙЙ) dim = 6;% гХЛЏВЮЪ§ИіЪ§ fobj=@(x)fun(x); %ЪЪгІЖШКЏЪ§ %% 11.гХЛЏЫуЗЈГѕЪМЛЏ [Best_sol,Best_X,Convergence,BestNet,pos_curve]=BOA(SearchAgents_no,dim,Max_iteration,lb,ub,fobj) %% 12.гХЛЏЧАLSTMдЫааНсЙћ [fitness1,net1,res1,info1] = fun([0.005,50,0.005,50]); % ЛљДЁВЮЪ§ШЁжЕ(бЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§) predict_value1=res1.predict_value1; predict_value2=res1.predict_value2; true_value1=res1.true_value1; true_value2=res1.true_value2; i=1; disp('-------------------------------------------------------------') disp('LSTMНсЙћЃК') rmse1=sqrt(mean((true_value1(i,:)-predict_value1(i,:)).^2)); disp(['LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК',num2str(rmse1)]) mae1=mean(abs(true_value1(i,:)-predict_value1(i,:))); disp(['LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК',num2str(mae1)]) mape1=mean(abs((true_value1(i,:)-predict_value1(i,:))./true_value1(i,:))); disp(['LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК',num2str(mape1*100),'%']) r2_1=R2(true_value1(i,:),predict_value1(i,:)); disp(['LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК',num2str(r2_1)]) rmse2=sqrt(mean((true_value2(i,:)-predict_value2(i,:)).^2)); disp(['LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК',num2str(rmse2)]) mae2=mean(abs(true_value2(i,:)-predict_value2(i,:))); disp(['LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК',num2str(mae2)]) mape2=mean(abs((true_value2(i,:)-predict_value2(i,:))./true_value2(i,:))); disp(['LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК',num2str(mape2*100),'%']) r2_2=R2(true_value2(i,:),predict_value2(i,:)); disp(['LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК',num2str(r2_2)]) %% 13. ЛцЭМ %% 14.гХЛЏКѓBOA-LSTMдЫааНсЙћ [fitness2,net2,res2,info2] = fun(Best_X); % ЛљДЁВЮЪ§ШЁжЕ(бЇЯАТЪЃЌвўВиВуНкЕуЃЌе§дђЛЏЯЕЪ§,бЕСЗДЮЪ§) i=1; disp('-------------------------------------------------------------') disp('BOA-LSTMНсЙћЃК') disp('BOA-LSTMгХЛЏЕУЕНЕФзюгХВЮЪ§ЮЊЃК') disp(['BOA-LSTMгХЛЏЕУЕНЕФвўВиЕЅдЊЪ§ФПЮЊЃК',num2str(round(Best_X(2)))]); disp(['BOA-LSTMгХЛЏЕУЕНЕФзюДѓбЕСЗжмЦкЮЊЃК',num2str(round(Best_X(4)))]); disp(['BOA-LSTMгХЛЏЕУЕНЕФInitialLearnRateЮЊЃК',num2str((Best_X(1)))]); disp(['BOA-LSTMгХЛЏЕУЕНЕФL2RegularizationЮЊЃК',num2str((Best_X(3)))]); op_rmse1=sqrt(mean((op_true_value1(i,:)-op_predict_value1(i,:)).^2)); disp(['BOA-LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК',num2str(op_rmse1)]) op_mae1=mean(abs(op_true_value1(i,:)-op_predict_value1(i,:))); disp(['BOA-LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК',num2str(op_mae1)]) op_mape1=mean(abs((op_true_value1(i,:)-op_predict_value1(i,:))./op_true_value1(i,:))); disp(['BOA-LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК',num2str(op_mape1*100),'%']) op_r2_1=R2(op_true_value1(i,:),op_predict_value1(i,:)); disp(['BOA-LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК',num2str(op_r2_1)]) op_rmse2=sqrt(mean((op_true_value2(i,:)-op_predict_value2(i,:)).^2)); disp(['BOA-LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК',num2str(op_rmse2)]) op_mae2=mean(abs(op_true_value2(i,:)-op_predict_value2(i,:))); disp(['BOA-LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК',num2str(op_mae2)]) op_mape2=mean(abs((op_true_value2(i,:)-op_predict_value2(i,:))./op_true_value2(i,:))); disp(['BOA-LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК',num2str(op_mape2*100),'%']) op_r2_2=R2(op_true_value2(i,:),op_predict_value2(i,:)); disp(['BOA-LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК',num2str(op_r2_2)]) %% 15.BOA-LSTMЛцЭМ %% 16.дЄВтЮДРДМАЛцЭМ ЭЈЙ§dataзюКѓkimМД15ИіЪ§ОнзїЮЊЪфШыЃЌЕУЕНдЄВтНсЙћМДЕк16ИіжЕ ЁЃ ЪфШы2-16ЃЌЕУЕНЕк17ИіжЕЁЃ БОДЮНЈвщдЄВтЮДРДжЛШЁkimИіжЕЃЌМДЖдгІЛЌЖЏДАПкГпДчЁЃ ЦфДЮЃЌУПДЮашвЊЮѓВюаое§ЃЌВЛШЛгУдЄВтжЕдйзїЮЊЪфШыЃЌЛсЮѓВюРлМЦ ЁЃ
ЮДПМТЧНсЙЙВуЪ§КЭЕЅЫЋЯђгХЛЏНсЙћ
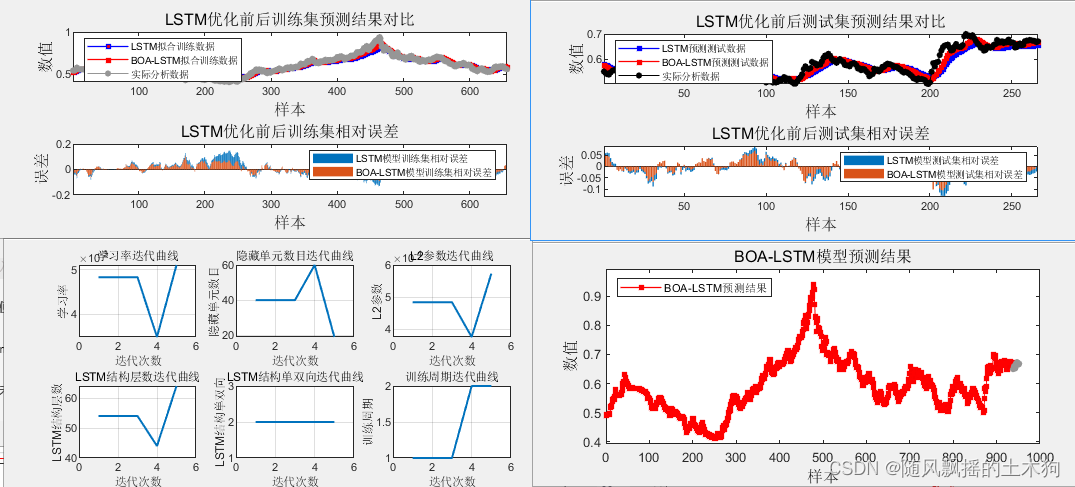
ЫФЁЂЮДПМТЧНсЙЙВуЪ§КЭЕЅЫЋЯђгХЛЏдЫааНсЙћ
LSTMНсЙћЃК
LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК0.023407
LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.01781
LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК2.9834%
LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.95768
LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК0.024046
LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.01902
LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК3.2605%
LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.78619
BOA-LSTMНсЙћЃК
BOA-LSTMгХЛЏЕУЕНЕФзюгХВЮЪ§ЮЊЃК
BOA-LSTMгХЛЏЕУЕНЕФвўВиЕЅдЊЪ§ФПЮЊЃК30
BOA-LSTMгХЛЏЕУЕНЕФзюДѓбЕСЗжмЦкЮЊЃК59
BOA-LSTMгХЛЏЕУЕНЕФInitialLearnRateЮЊЃК0.0060983
BOA-LSTMгХЛЏЕУЕНЕФL2RegularizationЮЊЃК0.00035327
BOA-LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК0.012984
BOA-LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.009747
BOA-LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК1.6228%
BOA-LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.98596
BOA-LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК0.015044
BOA-LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.011762
BOA-LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК1.9885%
BOA-LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.9183









ЮхЁЂПМТЧНсЙЙВуЪ§КЭЕЅЫЋЯђгХЛЏдЫааНсЙћ
LSTMНсЙћЃК
LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК0.029838
LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.022429
LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК3.8673%
LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.95401
LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК0.02557
LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.020291
LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК3.413%
LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.77222
BOA-LSTMНсЙћЃК
BOA-LSTMгХЛЏЕУЕНЕФзюгХВЮЪ§ЮЊЃК
BOA-LSTMгХЛЏЕУЕНЕФвўВиЕЅдЊЪ§ФПЮЊЃК19
BOA-LSTMгХЛЏЕУЕНЕФзюДѓбЕСЗжмЦкЮЊЃК64
BOA-LSTMгХЛЏЕУЕНЕФInitialLearnRateЮЊЃК0.0051093
BOA-LSTMгХЛЏЕУЕНЕФL2RegularizationЮЊЃК0.00057301
BOA-LSTMбЕСЗМЏИљОљЗНВю(RMSE)ЃК0.019895
BOA-LSTMбЕСЗМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.015285
BOA-LSTMбЕСЗМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК2.597%
BOA-LSTMбЕСЗМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.97333
BOA-LSTMВтЪдМЏИљОљЗНВю(RMSE)ЃК0.01963
BOA-LSTMВтЪдМЏЦНОљОјЖдЮѓВюЃЈMAEЃЉЃК0.015393
BOA-LSTMВтЪдМЏЦНОљЯрЖдАйЗжЮѓВюЃЈMAPEЃЉЃК2.6051%
BOA-LSTMВтЪдМЏR-squareОіЖЈЯЕЪ§ЃЈR2ЃЉЃК0.85712



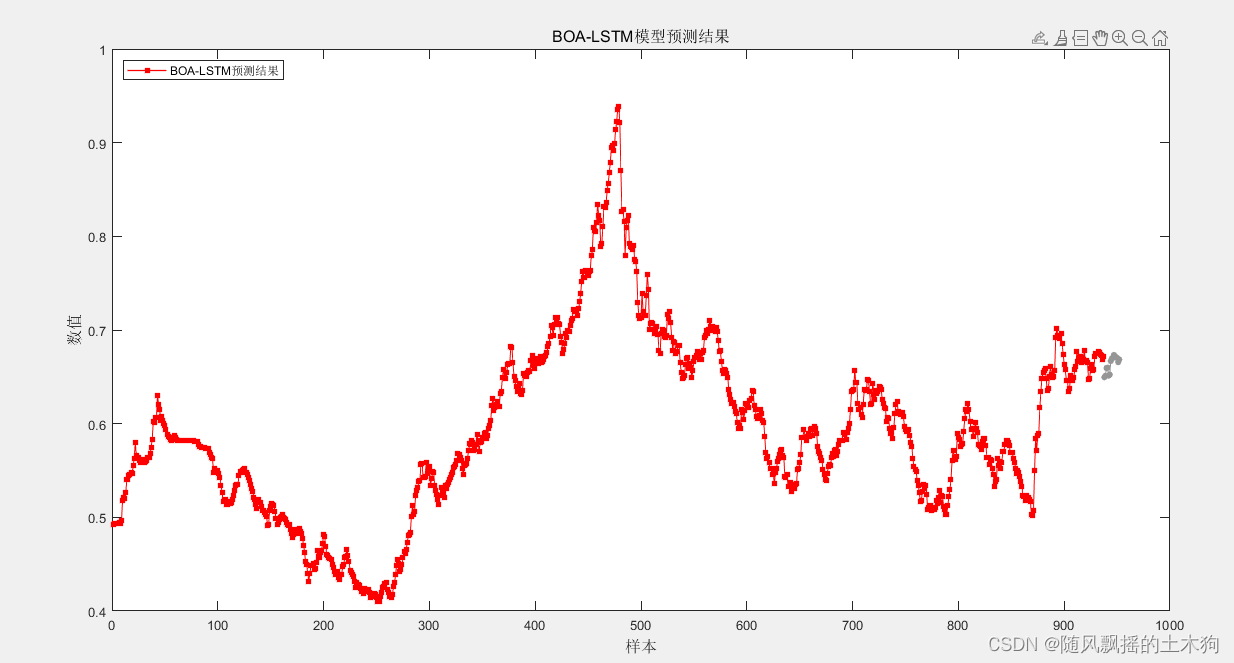
СљЁЂЗжЮі
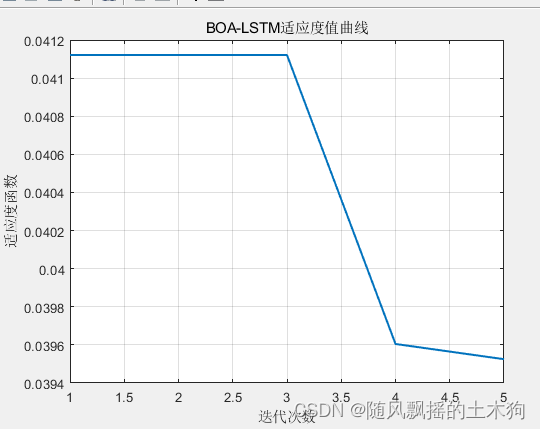
ИљОнМгШыНсЙЙВуЪ§КЭЕЅЫЋЯђНсЙЙРраЭГЌВЮЪ§гХЛЏЪБЃЌдкЭЌЕШжжШКЃЈ5ЃЉЕќДњДЮЪ§ЃЈ5ЃЉЕФЧщПіЯТЃЌНсЙћШДЯрЖдВювЛаЉЃЌЧвдЫааЫйЖШвВТ§вЛаЉЁЃЦфЪЕвВКмКУРэНтЃЌЖдгкЖргХЛЏВЮЪ§ЯрЕБгкАбМђЕЅЕФЮЪЬтИДдгЛЏЃЌВЛвЛЖЈНсЙЙВуЪ§дНЖрдНКУЃЌЗДЖјЛсАбБОМђЕЅЕФЭјТчНсЙЙИДдгЛЏЃЌЦфДЮЃЌД§гХЛЏГЌВЮЪ§ЖрСЫЃЌдкжжШКЪ§СПКЭЕќДњДЮЪ§ВЛБфЕФЧщПіЯТЃЌЫљЖдгІЕФбљБОЗсИЛадРДЫЕЃЌЗДЖјЯТНЕСЫ ЁЃЫљвдЃЌдкдіМгД§гХЛЏГЌВЮЪ§Ъ§СПЪБЃЌРэгІЬсИпжжШКЪ§СПКЭЕќДњДЮЪ§ЃЌЕЋЪЧЖдгкМђЕЅЕФЮЪЬтМђЕЅЕФЪ§ОнЃЌБОФЉЕЙжУЁЃ
ЦпЁЂДњТыЛёШЁ
КѓЬЈЫНаХЛиИДЁА34ЦкЁБМДПЩЛёШЁЯТдиСДНгЁЃ

