弹性计算-小弹_个人页

文章
117
问答
10
视频
29
个人介绍
暂无个人介绍
擅长的技术

-
发表了文章 2024-03-26
除了 Mattermost,这些开源 IM 应用也值得一试
在数字化时代,即时通讯(IM)已成为日常生活和工作的重要部分,开源IM应用因其透明度、可定制性和社区支持受到关注。
-
发表了文章 2024-03-18
AMD实例使用|配置AMD实例应用加速
本文主要讲解购买AMD实例规格时可以为实例配置应用加速功能,配置后可以针对不同的应用场景实现深度优化后的性能提升。
-
发表了文章 2024-03-21
英伟达最强 AI 芯片、人形机器人模型炸场!黄仁勋放言英语将成最强大编程语言
在2024年的GTC大会上,英伟达创始人黄仁勋揭幕了新一代AI芯片Blackwell,号称是史上最强AI芯片,目标是推动AI领域的重大进步。
-
发表了文章 2024-03-15
倚天产品介绍|倚天性能优化—YCL AI计算库在resnet50上的优化
Yitian710 作为平头哥第一代ARM通用芯片,在AI场景与X86相比,软件生态与推理性能都存在一定的短板,本文旨在通过倚天AI计算库的优化,打造适合ARM架构的软件平台,提升倚天性能
-
发表了文章 2024-03-19
AMD实例使用|AMD实例规格与操作系统兼容性说明
不同的AMD实例可能需要特定版本的驱动程序和内核来运行。购买AMD实例规格时,建议您使用官方支持的操作系统版本,以确保其包含适用于您的AMD实例的必要驱动程序和内核版本。本文主要说明不同代系的AMD实例与不同版本的操作系统镜像之间的兼容性。
-
发表了文章 2024-03-15
倚天产品介绍|阿里云核心产品—倚天710
阿里云最新产品手册——阿里云核心产品——倚天710自制脑图
-
发表了文章 2024-03-13
倚天使用|倚天ECS视频编解码之x264性能
在平头哥发布了首颗为云而生的 CPU 芯片倚天710之后,搭载倚天 710 的 ECS 实例表现出强劲的性能实力,在x264编解码场景下有着极高的性价比。
-
发表了文章 2024-03-12
Arm 发布 Neoverse 新品:数据分析性能提升 196%,奠定未来计算及 AI 的基石
北京时间 2 月 22 日,半导体巨头 Arm 更新了 Arm? Neoverse? 产品路线图,宣布推出两款基于全新第三代 Neoverse IP 构建的全新计算子系统(CSS):Arm Neoverse CSS V3 和 Arm Neoverse CSS N3。
-
发表了文章 2024-03-11
倚天测评|倚天云服务器初次体验
随着云计算技术的快速发展,云服务器在各个领域得到了广泛应用。其中,倚天云服务器以其独特的CIPU架构和倚天710处理器的优势,引起了广大用户的关注。本测评报告旨在通过对倚天云服务器的实例使用、业务部署、性能测试和迁移体验等方面进行评估。
-
发表了文章 2024-03-13
倚天使用|YODA倚天应用迁移神器,让跨架构应用迁移变得简单高效
YODA(Yitian Optimal Development Assistant,倚天应用迁移工具)旨在帮助用户更加高效、便捷地实现跨平台、跨结构下的应用迁移,大幅度缩短客户在新平台上端到端性能验证所需的人力和时间,使得客户更加专注于应用本身算法的优化,协同客户实现降本增效。
-
发表了文章 2024-03-12
倚天使用|Nginx性能高27%,性价比1.5倍,基于阿里云倚天ECS的Web server实践
倚天710构建的ECS产品,基于云原生独立物理核、大cache,结合CIPU新架构,倚天ECS在Nginx场景下,具备强大的性能优势。相对典型x86,Http长连接场景性能收益27%,开启gzip压缩时性能收益达到74%。 同时阿里云G8y实例售价比G7实例低23%,是Web Server最佳选择。
-
发表了文章 2024-03-12
倚天使用|Redis性能高30%,阿里云倚天ECS性能摸底和迁移实践
Redis在倚天ECS环境下与同规格的基于 x86 的 ECS 实例相比,Redis 部署在基于 Yitian 710 的 ECS 上可获得高达 30% 的吞吐量优势。成本方面基于倚天710的G8y实例售价比G7实例低23%,总性价比提高50%;按照相同算法,相对G8a,性价比为1.4倍左右。
-
发表了文章 2024-03-14
倚天产品介绍|倚天虚拟化:CPU虚拟化原理介绍
虚拟化技术中最关键的技术之一就是CPU虚拟化。在没有硬件辅助虚拟化技术出来之前,通常都是通过TCG(软件进行指令翻译)的方式实现CPU虚拟化。但是由于TCG方式的虚拟化层开销太大,性能太差,因此引入了硬件辅助虚拟化技术。
-
发表了文章 2024-03-11
倚天使用|倚天性能优化—YCL AI计算库在resnet50上的优化
本文介绍了x86软件迁移到Arm过程中可能遇到的弱内存序问题的解决方案,解析了弱内存序问题的根因,介绍了Hawkeyes的架构和实现原理。欢迎有需求的团队发送邮件咨询
-
发表了文章 2024-03-04
阿里云100多款产品为啥降价?看这篇就够了
2月29日,阿里云全线下调云产品官网售价,平均降价幅度超过20%,最高降幅达55%。
-
发表了文章 2024-03-01
ARM架构和避坑指南|开发者分享会
今天分享的内容来自阿里云倚天ECS高级架构师张先国的“ARM架构和避坑指南”。本文内容主要从ARM架构、C和Java如何避坑 、等方面详细讲解。
-
发表了文章 2024-02-26
OpenAI视频生成Sora技术简析
Sora是春节期间OpenAI发布的产品,主要是通过文字描述生成视频,通过大规模视频数据训练而成的生成模型,当前还没开放试用。
-
发表了文章 2024-02-23
推荐程序员必知的四大神级学习网站
今天给大家整理一些小编经常学习和访问的学习网站,供大家参考学习。
-
发表了文章 2024-02-22
ECS热门应用 | 解决Guestosssh异常
通过ECS实例快速发现操作系统内部的问题,并给出对应的修复方案。
-
发表了文章 2024-02-21
倚天经典客户案例|开发者分享会
2022年2月,基于倚天弹性计算的产品实例正式对外进行邀测。经过大半年的时间,在2022年云栖大会上,ECS倚天实例正式商业化。在宣布倚天商业化的同时,已经经历了阿里巴巴电商、双十一等流量洪峰的考验,包括邀测的内外部头部客户业务。
-
发表了文章 2024-02-06
芯片竞争格局及最佳匹配场景|开发者分享会
今天分享的内容来自阿里云智能解决方案架构师冯英飞的“芯片竞争格局及最佳匹配场景”。本文主要从ARM芯片市场竞争与生态分析、倚天竞争力分析以及优势业务场景介绍这三个内容进行讲解。
-
发表了文章 2024-02-06
来了!HelloGitHub 年度热门开源项目
本期为HelloGitHub 年度盘点,为了满足不同读者的需求,作者将内容分为 Top10 和 精选 两部分
-
发表了文章 2024-02-02
AI2 开源新 LLM,重新定义 open AI
艾伦人工智能研究所(Allen Institute for AI,简称 AI2)宣布推出一个名为 OLMo 7B 的新大语言模型,并开源发布了预训练数据和训练代码。OLMo 7B 被描述为 “一个真正开放的、最先进的大型语言模型”。
-
发表了文章 2024-01-31
【Hello AI】安装并使用FastGPU-命令行使用说明
用户可以通过FastGPU的命令行,快速地部署云上GPU集群,管理资源的生命周期。还可以便捷地为集群安装深度学习环境,在集群运行代码,查看运行日志以及释放资源。
-
发表了文章 2024-01-30
【Hello AI】安装和使用AIACC-AGSpeed(优化PyTorch深度学习模型)
AIACC-AGSpeed(简称AGSpeed)专注于优化PyTorch深度学习模型在阿里云GPU异构计算实例上的计算性能,相比原始的神龙AI加速引擎AIACC,可以实现无感的计算优化性能。本文为您介绍安装和使用AGSpeed的方法。
-
发表了文章 2024-01-30
【Hello AI】AIACC-ACSpeed体验示例
AIACC-ACSpeed(简称ACSpeed)作为阿里云自研的AI训练加速器,在提高训练效率的同时能够降低使用成本,可以实现无感的分布式通信性能优化。ACSpeed软件包中已为您提供了适配DDP的示例代码,您可以参考本文快速体验使用ACSpeed进行模型分布式训练的过程以及性能提升效果。
-
发表了文章 2024-02-01
Hadoop 已死,AI 吞噬世界!
在数据领域,AI 正逐步重塑数据处理和分析的各个环节,从 ETL、数据治理到数据分析和消费方式均会发生根本性变化。Kyligence 联合创始人 & CEO,Apache 顶级开源项目。
-
发表了文章 2024-01-29
【Hello AI】AIACC-ACSpeed性能数据
本文展示了AIACC-ACSpeed的部分性能数据,相比较通过原生DDP训练模型后的性能数据,使用AIACC-ACSpeed训练多个模型时,性能具有明显提升。
-
发表了文章 2024-03-20
AMD产品介绍|通用型实例g8a
g8a实例:高性价比X86服务器,搭载最新CIPU架构,提供100G*2网络带宽和eRDMA支持。基于AMD Genoa平台,主频2.7/3.7GHz,专为性能、成本和稳定性需求设计。适用于通用应用、AI推理训练、高清视频处理等场景。实例性能提升25%,性价比提升15%,内置安全芯片,支持可信计算和机密计算。
-
发表了文章 2024-01-29
【Hello AI】安装和使用AIACC-ACSpeed-分布式训练场景的通信优化库
AIACC-ACSpeed专注于分布式训练场景的通信优化库,通过模块化的解耦优化设计,实现了分布式训练在兼容性、适用性和性能加速等方面的升级。本文为您介绍安装和使用AIACC-ACSpeed v1.1.0的方法。
-
发表了文章 2024-03-19
马斯克旗下公司宣布开源 Grok-1 模型,参数量达3140亿
最近,Meta基础人工智能研究(FAIR)团队发布了名为Branch-Train-MiX (BTX)的方法,可从种子模型开始,该模型经过分支,以高吞吐量和低通信成本的并行方式训练专家模型。Meta FAIR的成员之一Jason Weston在其X上发文介绍了这一进展。
-
发表了文章 2024-01-30
【Hello AI】AIACC-AGSpeed性能数据
本文展示了AIACC-AGSpeed(简称AGSpeed)的部分性能数据,相比较通过PyTorch原生Eager模式训练模型后的性能数据,使用AGSpeed训练多个模型时,性能具有明显提升。
-
发表了文章 2024-01-26
【Hello AI】安装并使用DeepGPU-LLM-处理大语言模型任务
在处理大语言模型任务中,您可以根据实际业务部署情况,选择在不同环境(例如GPU云服务器环境或Docker环境)下安装推理引擎DeepGPU-LLM,然后通过使用DeepGPU-LLM工具实现大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)在GPU上的高性能推理优化功能
-
发表了文章 2024-01-26
【Hello AI】安装并使用Deepnccl-多GPU互联的AI通信加速库
Deepnccl是为阿里云神龙异构产品开发的用于多GPU互联的AI通信加速库,能够无感地加速基于NCCL通信算子调用的分布式训练或多卡推理等任务。本文主要介绍在Ubuntu或CentOS操作系统的GPU实例上安装和使用Deepnccl的操作方法。
-
发表了文章 2024-03-15
ECS热门应用 | 安装家用内网穿透服务
使用云服务器ECS,让家庭网络可以被外部网络访问。不在家时,也可以读取备份资料。
-
发表了文章 2024-03-14
英伟达GTC 2024大会倒计时!黄仁勋将发布机器人领域最新突破性成果
美国加利福尼亚州圣克拉拉 —— NVIDIA 今日宣布,将于 3 月 18 日至 21 日在圣何塞会议中心举办 GTC 2024 大会。预计将有超 30 万人亲临现场或线上注册参会。
-
发表了文章 2024-03-14
倚天产品介绍|倚天虚拟化:虚拟机热迁移特性介绍
热迁移分为热迁移和冷迁移,冷迁移过程中有一段明显的时间VM的服务不可用,而热迁移的服务的服务暂停时间非常短。热迁移过程中无需关闭或者长时间暂停VM,VM保持正常运行,只有在热迁移临近结束时有一个非常短暂的停机切换时间。热迁移可保证了VM服务的可用性,提升业务的连续性和用户体验。
-
发表了文章 2024-03-13
倚天产品介绍|倚天ECS加速国密算法性能
倚天ECS是阿里云基于平头哥自研数据中心芯片倚天710推出arm架构实例,采用armv9架构,支持SM3/SM4指令,可以加速国密算法性能。本文基于OpenSSL 3.2和Tongsuo 实测对比了倚天ECS g8y实例和Intel g7 实例国密性能。为用户选择ECS提供参考。
-
发表了文章 2024-01-23
【Hello AI】使用AIACC-Training TensorFlow版
TensorFlow目前进行数据分布式训练的主流方式是Horovod,AIACC-Training 1.5支持使用Horovod API兼容的方式对TensorFlow分布式训练进行加速。本文为您介绍使用AIACC-Training TensorFlow版的具体操作及可能遇到的问题。
-
发表了文章 2024-01-24
【新手推荐】阿里云上一键部署幻兽帕鲁服务器
幻兽帕鲁联机服务器搭建步骤,全程无需手动配置参数,3分钟完成搭建。
-
发表了文章 2024-01-23
【Hello AI】使用AIACC-Training MXNet版
由于MXNet支持KVStore和Horovod两种分布式训练方式,因此AIACC-Training 1.5能够支持使用KVStore的方式对MXNet分布式训练进行加速,同时支持Horovod的分布式训练方式,并且能够无缝兼容Horovod的API版本。
-
发表了文章 2024-01-25
一个程序员“玩”出来的网站:每月成本仅 350 元,如今赚了 16.4 万元
很难想象:一个每月运行成本不到 50 美元(约人民币 358 元)的网站,是如何做到收入 2.3 万美元(约人民币 16.4 万元)的?尤其是,这个网站只有创始人一个人在经营管理。
-
发表了文章 2024-01-25
【Hello AI】手动安装AIACC-Inference(AIACC推理加速)Torch版
AIACC-Inference(AIACC推理加速)支持优化基于Torch框架搭建的模型,能够显著提升推理性能。本文介绍如何手动安装AIACC-Inference(AIACC推理加速)Torch版并提供示例体验推理加速效果。
-
发表了文章 2024-01-23
【Hello AI】如何安装AIACC-Training(AIACC训练加速)
AIACC-Training支持基于主流人工智能(包括PyTorch、TensorFlow、MXNet、Caffe等)搭建的模型进行分布式训练。在接口层面上,目前AIACC-Training兼容了PyTorch DDP以及Horovod的API,对于原生使用上述分布式训练方法的训练代码,可以做到无感的性能加速。本文将为您介绍安装AIACC-Training 1.5.0的多种方式。
-
发表了文章 2024-01-22
ECS热门应用 | 轻松打造一套 Web IDE
使用ECS云服务器搭建网页IDE,增强编码便捷性,提升开发者体验。
-
发表了文章 2024-01-23
【Hello AI】使用AIACC-Training PyTorch版
自PyTorch 1.x发布迭代后,使用PyTorch原生自带的DDP进行分布式训练逐渐形成了主流。本文为您介绍如何使用AIACC-Training,对基于PyTorch框架搭建的模型进行分布式训练加速的方法,以及可能遇到的问题和解决办法。
-
发表了文章 2024-01-18
【Hello AI】集群极速部署工具FastGPU
FastGPU是一套阿里云推出的人工智能计算极速部署工具。您可以通过其提供的便捷的接口和自动工具,实现人工智能训练和推理任务在阿里云IaaS资源上的快速部署。本文主要分为产品介绍、组成模块、典型流程这几个部分进行讲解。
-
发表了文章 2024-01-17
【Hello AI】AIACC-ACSpeed-AI分布式训练通信优化库
AIACC-ACSpeed(AIACC 2.0-AIACC Communication Speeding)是阿里云推出的AI分布式训练通信优化库AIACC-Training 2.0版本。相比较于分布式训练AIACC-Training 1.5版本,AIACC-ACSpeed基于模块化的解耦优化设计方案,实现了分布式训练在兼容性、适用性和性能加速等方面的升级。
-
发表了文章 2024-01-17
Huggingface又上不去了?这里有个新的解决方案!
AI开发者都知道,HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。
-
发表了文章 2024-02-28
有奖调研 I 云服务器ECS有奖调研问卷来咯!
参与阿里云ECS开发者产品调研问卷,前200名赠送100-200元ECS无门槛代金券!
暂无更多信息
-
 发表了文章
2024-05-15
发表了文章
2024-05-15
华人开源最强「AI 程序员」炸场,让 GPT-4 自己修 Bug!
-
发表了文章
2024-05-15
探索游戏开源世界:引擎与框架的宝库
-
发表了文章
2024-05-15
人类标注的时代已经结束?DeepMind 开源 SAFE 根治大模型幻觉问题
-
发表了文章
2024-05-15
百亿大规模图在广告场景的应用
-
发表了文章
2024-05-15
除了 Mattermost,这些开源 IM 应用也值得一试
-
发表了文章
2024-05-15
AMD实例使用|配置AMD实例应用加速
-
发表了文章
2024-05-15
英伟达最强 AI 芯片、人形机器人模型炸场!黄仁勋放言英语将成最强大编程语言
-
发表了文章
2024-05-15
倚天产品介绍|倚天性能优化—YCL AI计算库在resnet50上的优化
-
发表了文章
2024-05-15
AMD实例使用|AMD实例规格与操作系统兼容性说明
-
发表了文章
2024-05-15
倚天产品介绍|阿里云核心产品—倚天710
-
发表了文章
2024-05-15
倚天使用|倚天ECS视频编解码之x264性能
-
发表了文章
2024-05-15
Arm 发布 Neoverse 新品:数据分析性能提升 196%,奠定未来计算及 AI 的基石
-
发表了文章
2024-05-15
倚天测评|倚天云服务器初次体验
-
发表了文章
2024-05-15
倚天使用|YODA倚天应用迁移神器,让跨架构应用迁移变得简单高效
-
发表了文章
2024-05-15
倚天使用|Nginx性能高27%,性价比1.5倍,基于阿里云倚天ECS的Web server实践
-
发表了文章
2024-05-15
倚天使用|Redis性能高30%,阿里云倚天ECS性能摸底和迁移实践
-
发表了文章
2024-05-15
倚天产品介绍|倚天虚拟化:CPU虚拟化原理介绍
-
发表了文章
2024-05-15
倚天产品介绍|倚天710平台稳定性-内存隔离降级运行
-
发表了文章
2024-05-15
马斯克搞脑机得“开瓢”?MIT 早在研究「挂耳式耳机」,戴上=“把整个互联网装进脑子”!
-
发表了文章
2024-05-15
倚天使用|倚天性能优化—YCL AI计算库在resnet50上的优化
滑动查看更多
-
 提交了问题
2024-03-13
提交了问题
2024-03-13
AMD实例可以应用在哪些有趣的场景中?
-
提交了问题
2024-03-11
使用ecs可以哪些搭建好玩的应用?
-
提交了问题
2024-01-29
我对ECS的付费方式有话说
-
提交了问题
2023-12-26
独立开发者,怎么更好使用计算巢把软件SaaS化?
-
 回答了问题
2023-12-22
回答了问题
2023-12-22
网站在ipv6环境下访问图片只能展示ipv4的内容
恭喜以上中奖用户~奉上社区20积分,感谢各位开发者们积极回复技术问题以及发表意见。从今日起,小弹会每天在问答板块挑选出优质的评论并送出20积分。积分会在7个工作日内日发放成功,请大家踊跃参与哦!
赞0 踩0 评论0 -
回答了问题
2023-12-15
为什么使用云服务器老是要这么多步骤?
恭喜以上中奖用户~奉上社区20积分,感谢各位开发者们积极回复技术问题以及发表意见。从今日起,小弹会每天在问答板块挑选出优质的评论并送出20积分。积分会在7个工作日内日发放成功,请大家踊跃参与哦!
赞0 踩0 评论0 -
回答了问题
2023-12-11
无法通过公网IP访问Web网页
恭喜以上中奖用户~奉上社区20积分,感谢各位开发者们积极回复技术问题以及发表意见。从今日起,小弹会每天在问答板块挑选出优质的评论并送出20积分。积分会在7个工作日内日发放成功,请大家踊跃参与哦!
赞8 踩0 评论0 -
回答了问题
2023-12-11
阿里云服务器是Windowsserver2008R2,配置好VPN了,但是客户端连接后,服务端提示没
恭喜以上获奖用户~奉上社区20积分,感谢各位开发者们积极回复技术问题以及发表意见。从今日起,小弹会每天在问答板块挑选出优质的评论并送出20积分。积分会在7个工作日内日发放成功,请大家踊跃参与哦!
赞0 踩0 评论0 -
回答了问题
2023-11-24
选择实验资源一直说阿里云账号不足
您好呀~这边小弹问了相关人员,目前答复是因为同时使用的人多,账号不够了,建议等会再试试!
赞4 踩0 评论0 -
回答了问题
2023-11-09
为什么领取了学生专享1个月ecs后,完成了两个任务且实例还未过期,无法0元续费?
是参加了什么活动呢?
赞10 踩0 评论0
滑动查看更多
-
 计算巢系列五:服务自定义运维项发布时间:2024-01-31 11:15:04 视频时长:3分43秒 播放量:88演示如何利用计算巢自定义运维项并使用
计算巢系列五:服务自定义运维项发布时间:2024-01-31 11:15:04 视频时长:3分43秒 播放量:88演示如何利用计算巢自定义运维项并使用 -
 计算巢系列五:服务可配置多个模板以及多个套餐发布时间:2024-01-31 10:53:39 视频时长:5分51秒 播放量:92演示创建新服务,创建2个模板、3个套餐,并完成部署,体现出模板之间的差异
计算巢系列五:服务可配置多个模板以及多个套餐发布时间:2024-01-31 10:53:39 视频时长:5分51秒 播放量:92演示创建新服务,创建2个模板、3个套餐,并完成部署,体现出模板之间的差异 -
 计算巢系列六:服务商应用管理发布时间:2024-01-09 16:02:19 视频时长:3分12秒 播放量:79演示如何利用计算巢创建一应用管理并使用。
计算巢系列六:服务商应用管理发布时间:2024-01-09 16:02:19 视频时长:3分12秒 播放量:79演示如何利用计算巢创建一应用管理并使用。 -
 计算巢系列五:服务分销授权功能发布时间:2023-12-26 17:19:59 视频时长:2分21秒 播放量:186演示如何利用计算巢申请分销授权、主动授权,和二次创建。
计算巢系列五:服务分销授权功能发布时间:2023-12-26 17:19:59 视频时长:2分21秒 播放量:186演示如何利用计算巢申请分销授权、主动授权,和二次创建。 -
 计算巢系列五:用户授权服务功能发布时间:2023-12-26 17:18:36 视频时长:1分55秒 播放量:216演示如何利用计算巢配置用户授权。
计算巢系列五:用户授权服务功能发布时间:2023-12-26 17:18:36 视频时长:1分55秒 播放量:216演示如何利用计算巢配置用户授权。 -
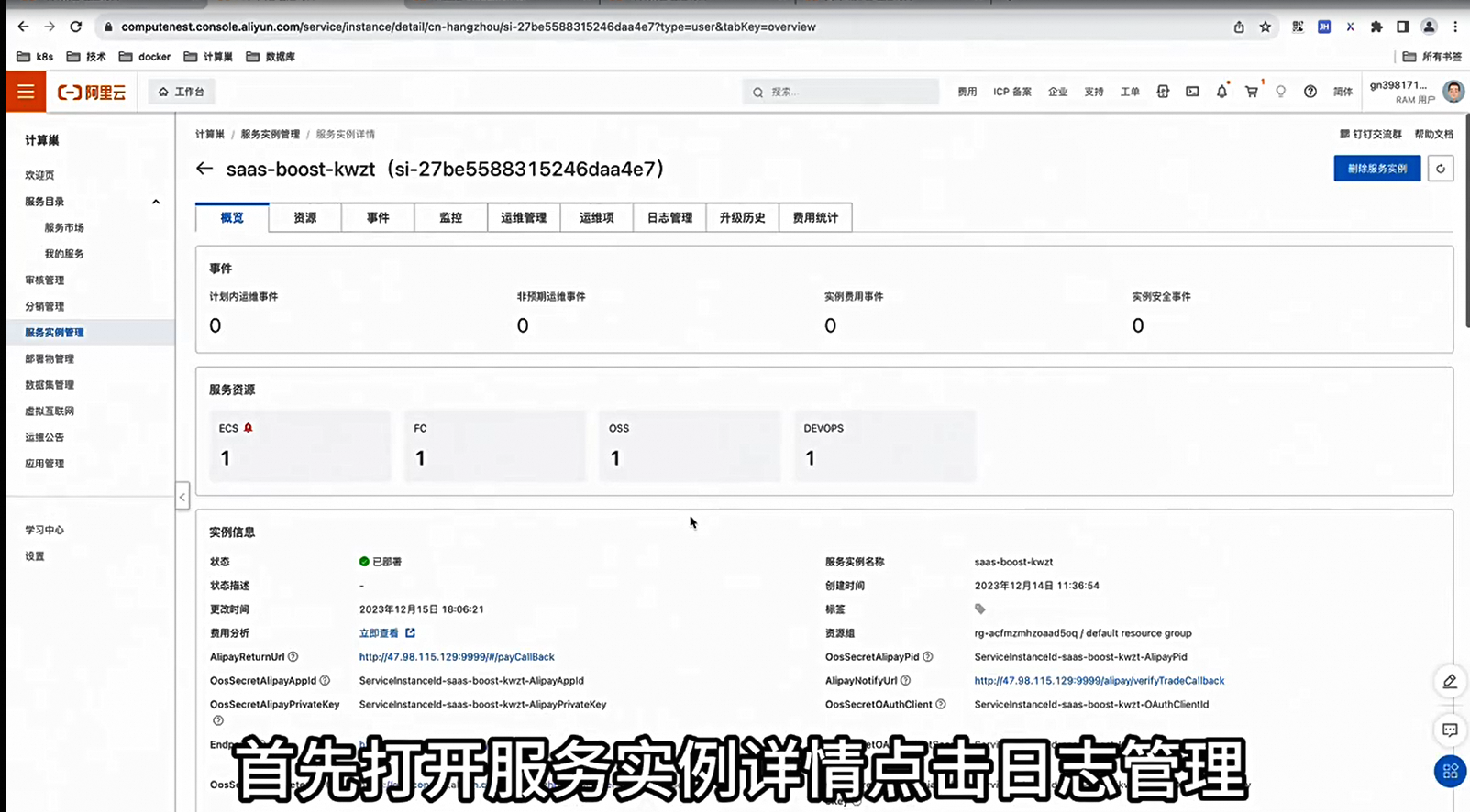 计算巢系列五:服务日志功能发布时间:2023-12-26 17:17:56 视频时长:0分52秒 播放量:228演示如何利用计算巢配置和使用日志。
计算巢系列五:服务日志功能发布时间:2023-12-26 17:17:56 视频时长:0分52秒 播放量:228演示如何利用计算巢配置和使用日志。 -
 计算巢系列五:服务监控功能发布时间:2023-12-26 17:17:09 视频时长:1分53秒 播放量:224演示如何利用计算巢配置和使用监控。
计算巢系列五:服务监控功能发布时间:2023-12-26 17:17:09 视频时长:1分53秒 播放量:224演示如何利用计算巢配置和使用监控。 -
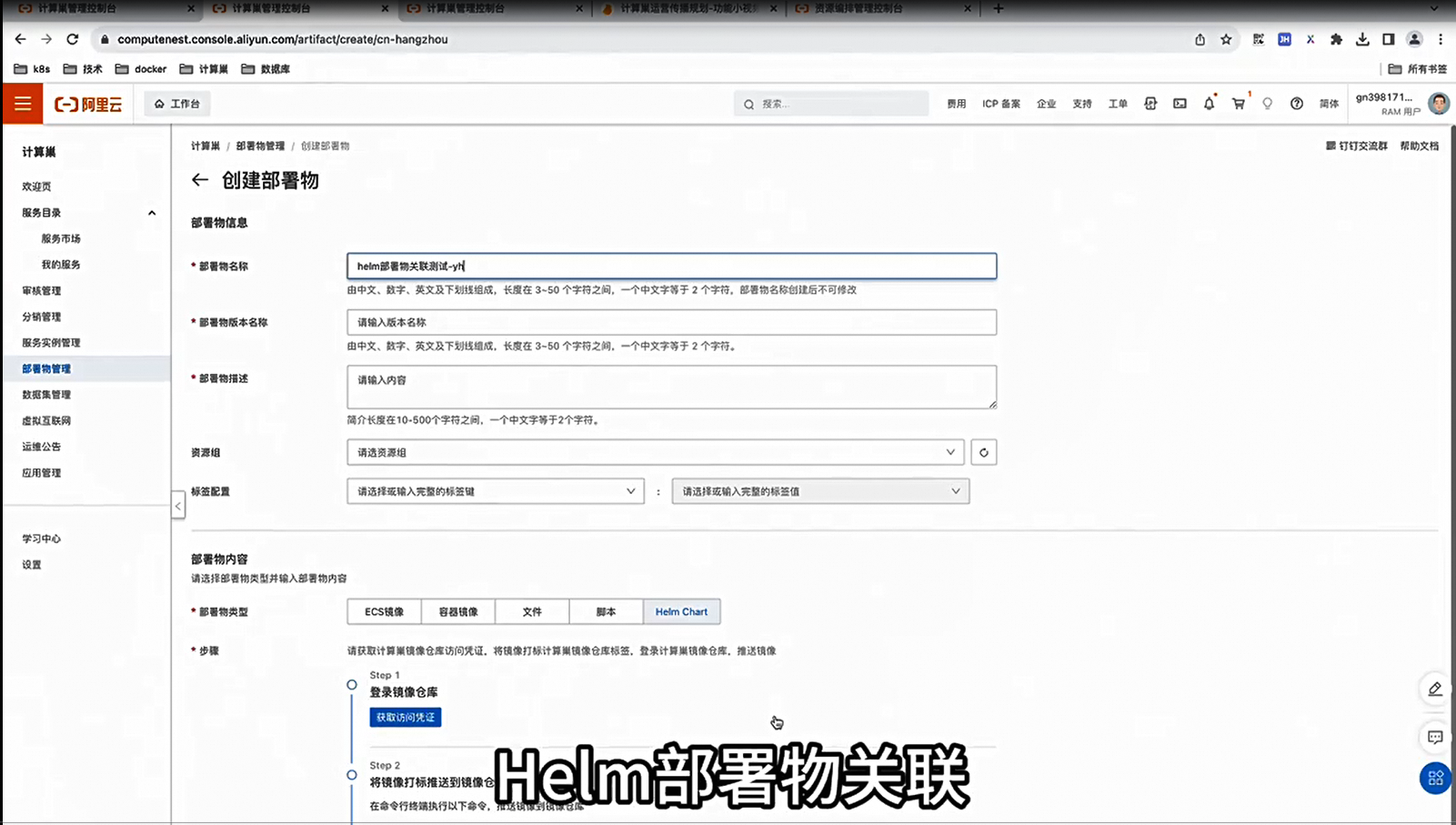 计算巢系列五:Helm部署物关联发布时间:2023-12-26 17:14:30 视频时长:2分59秒 播放量:233部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。
计算巢系列五:Helm部署物关联发布时间:2023-12-26 17:14:30 视频时长:2分59秒 播放量:233部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。 -
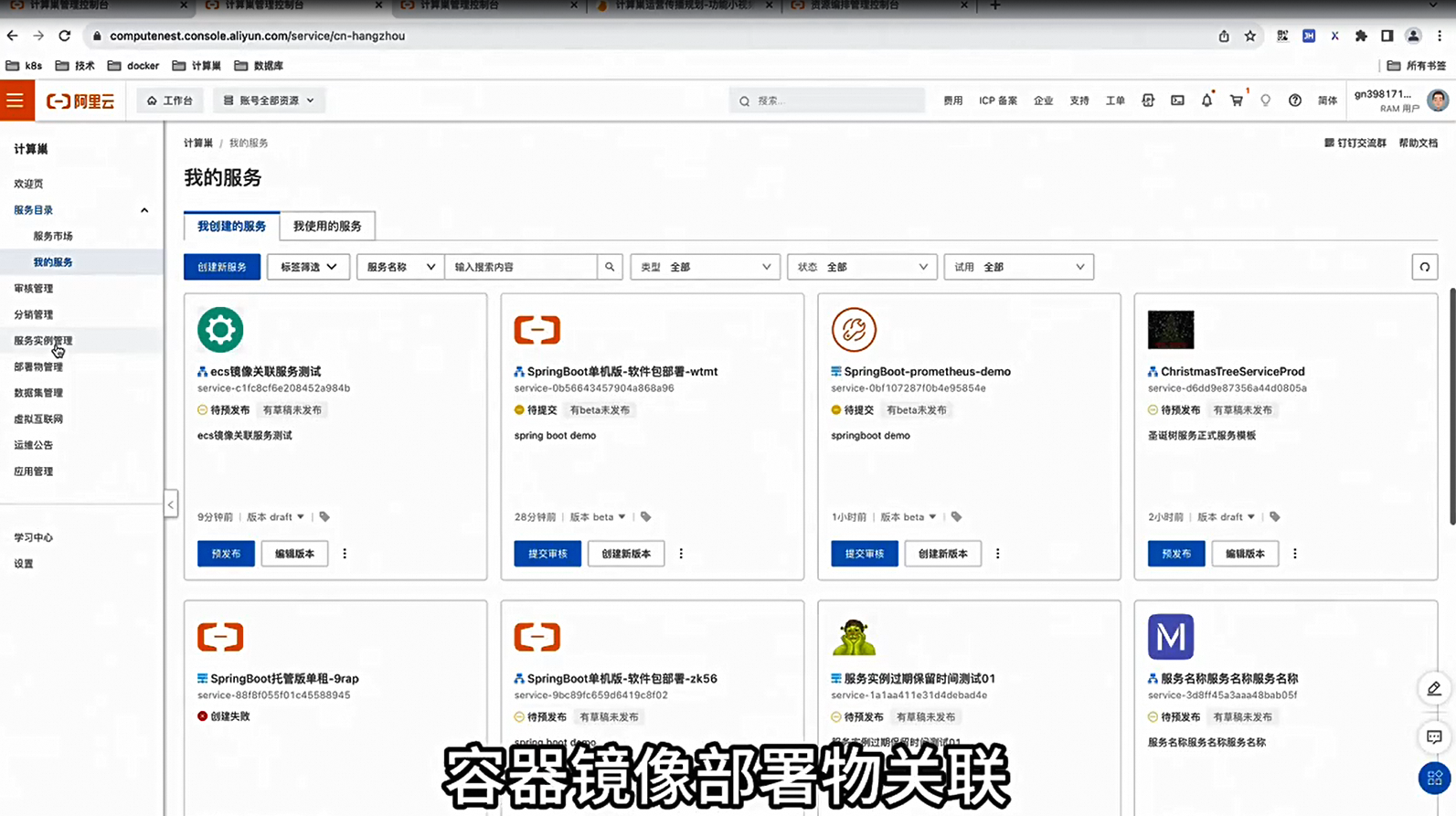 计算巢系列五:容器镜像关联发布时间:2023-12-26 17:13:56 视频时长:3分3秒 播放量:187部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。
计算巢系列五:容器镜像关联发布时间:2023-12-26 17:13:56 视频时长:3分3秒 播放量:187部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。 -
 计算巢系列五:文件部署物关联发布时间:2023-12-26 17:12:49 视频时长:2分22秒 播放量:218部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。
计算巢系列五:文件部署物关联发布时间:2023-12-26 17:12:49 视频时长:2分22秒 播放量:218部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。 -
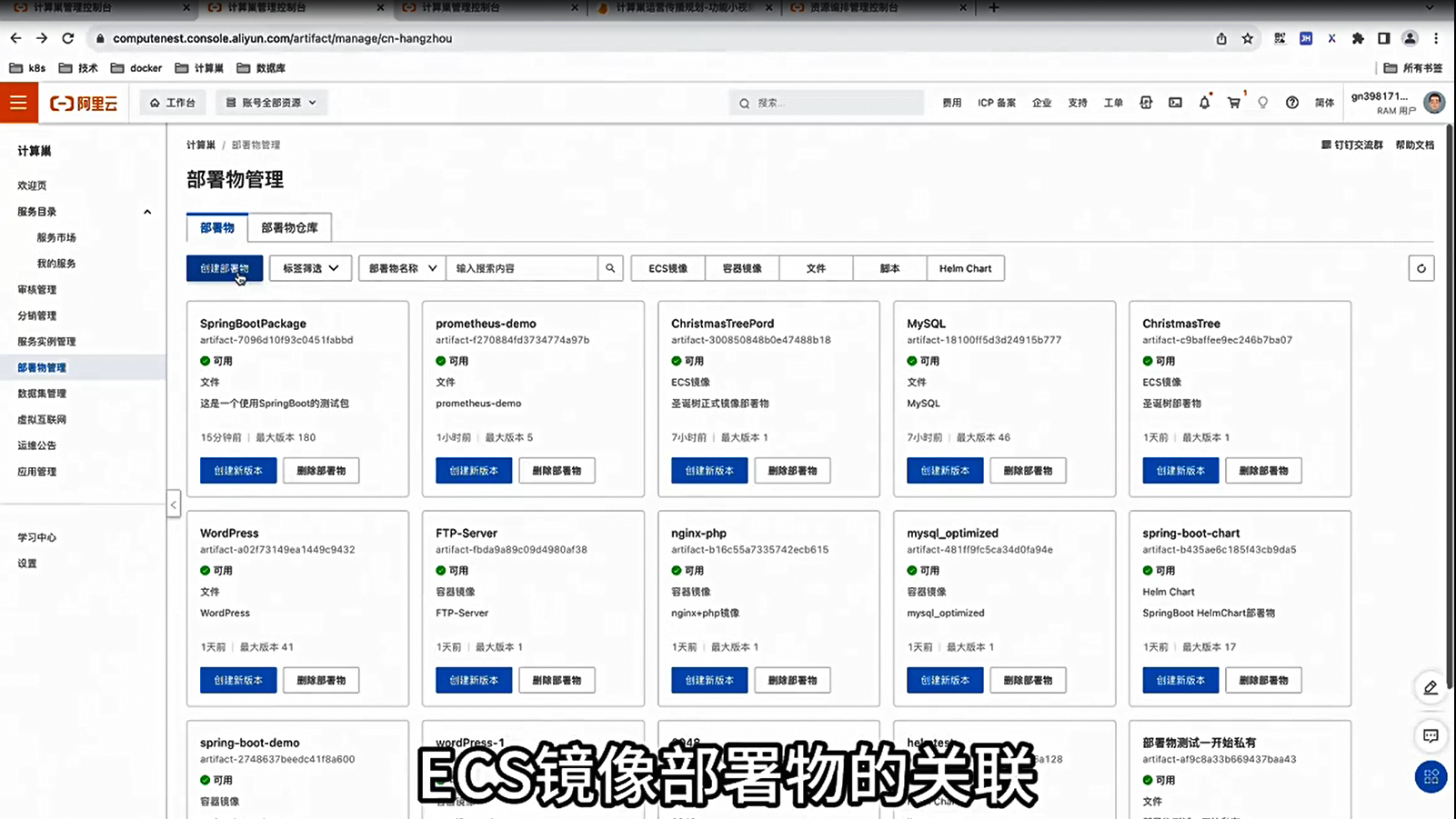 计算巢系列五:ECS镜像关联发布时间:2023-12-26 17:12:11 视频时长:2分38秒 播放量:215部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。
计算巢系列五:ECS镜像关联发布时间:2023-12-26 17:12:11 视频时长:2分38秒 播放量:215部署物关联功能,演示如何利用计算巢创建新服务,关联多种类型的部署物,并完成部署,体现出模板之间的差异。 -
 计算巢系列五:按量计费绑定云市场商品发布时间:2023-12-26 17:07:12 视频时长:5分9秒 播放量:179演示如何利用计算巢绑定成为云市场商品。
计算巢系列五:按量计费绑定云市场商品发布时间:2023-12-26 17:07:12 视频时长:5分9秒 播放量:179演示如何利用计算巢绑定成为云市场商品。 -
 计算巢系列五:按周期订阅绑定云市场商品发布时间:2023-12-26 16:56:22 视频时长:4分11秒 播放量:187演示如何利用计算巢绑定成为云市场商品。
计算巢系列五:按周期订阅绑定云市场商品发布时间:2023-12-26 16:56:22 视频时长:4分11秒 播放量:187演示如何利用计算巢绑定成为云市场商品。 -
 快速搭建python turtle画布,画出专属你的冬日浪漫发布时间:2023-12-25 16:03:05 视频时长:4分17秒 播放量:7679turtle库是Python语言中自带的一个用于绘制图像的函数库。turtle库为使用者提供一个或多个小乌龟作为画笔,使用者可通过turtle库提供的各种方法去控制小乌龟在一个平面直角坐标系中移动并绘制移动轨迹以画出想要的图案。
快速搭建python turtle画布,画出专属你的冬日浪漫发布时间:2023-12-25 16:03:05 视频时长:4分17秒 播放量:7679turtle库是Python语言中自带的一个用于绘制图像的函数库。turtle库为使用者提供一个或多个小乌龟作为画笔,使用者可通过turtle库提供的各种方法去控制小乌龟在一个平面直角坐标系中移动并绘制移动轨迹以画出想要的图案。 -
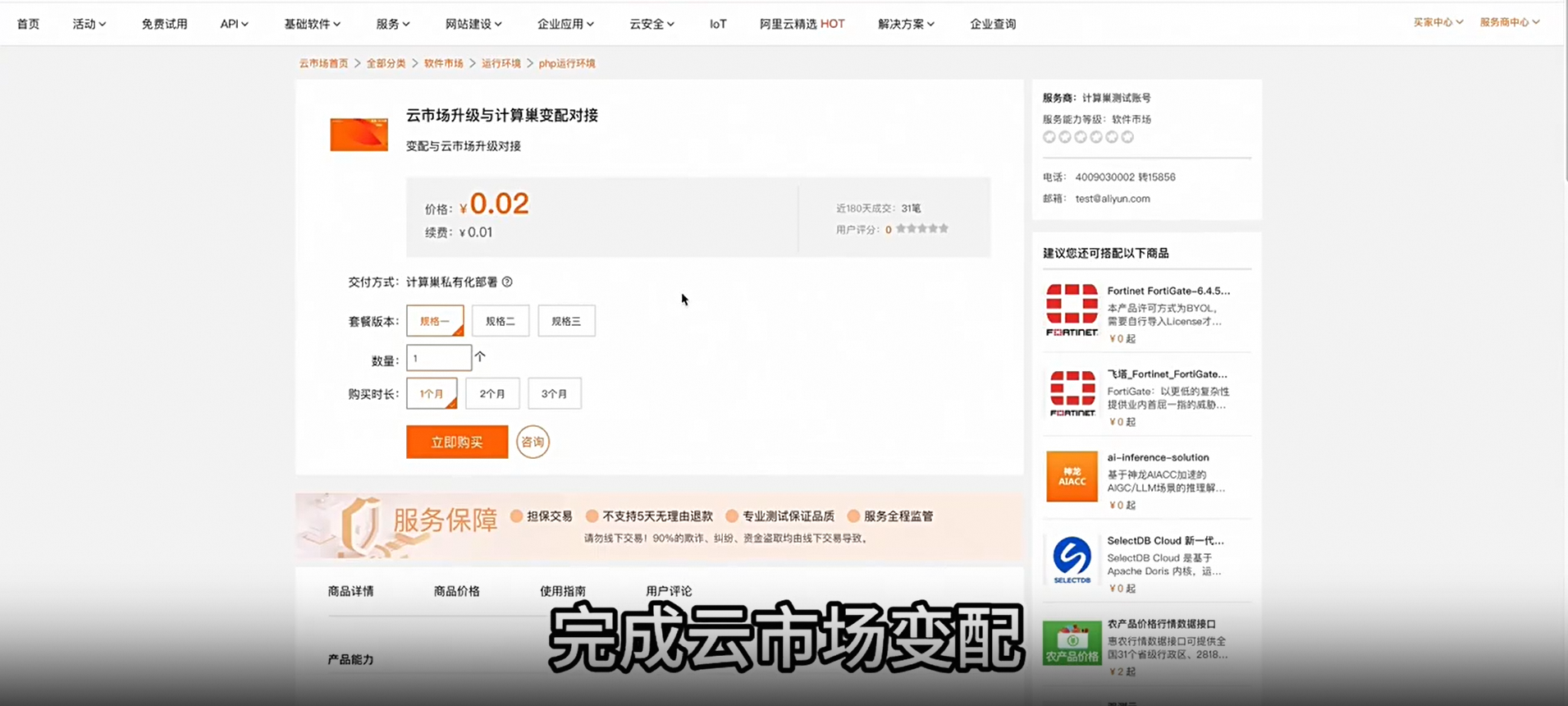 计算巢系列四:关联云市场的服务实例变配发布时间:2023-12-20 15:55:26 视频时长:1分57秒 播放量:185演示如何利用计算巢对云市场的服务实例进行套餐变配。
计算巢系列四:关联云市场的服务实例变配发布时间:2023-12-20 15:55:26 视频时长:1分57秒 播放量:185演示如何利用计算巢对云市场的服务实例进行套餐变配。 -
 计算巢系列四:服务变配配置&实例变配发布时间:2023-12-20 15:53:45 视频时长:4分45秒 播放量:187演示如何利用计算巢对已有的服务实例进行套餐变配。
计算巢系列四:服务变配配置&实例变配发布时间:2023-12-20 15:53:45 视频时长:4分45秒 播放量:187演示如何利用计算巢对已有的服务实例进行套餐变配。 -
 计算巢系列四:服务升级配置&实例升级发布时间:2023-12-20 15:51:43 视频时长:2分24秒 播放量:208演示如何利用计算巢对已有的服务实例进行版本升级。
计算巢系列四:服务升级配置&实例升级发布时间:2023-12-20 15:51:43 视频时长:2分24秒 播放量:208演示如何利用计算巢对已有的服务实例进行版本升级。 -
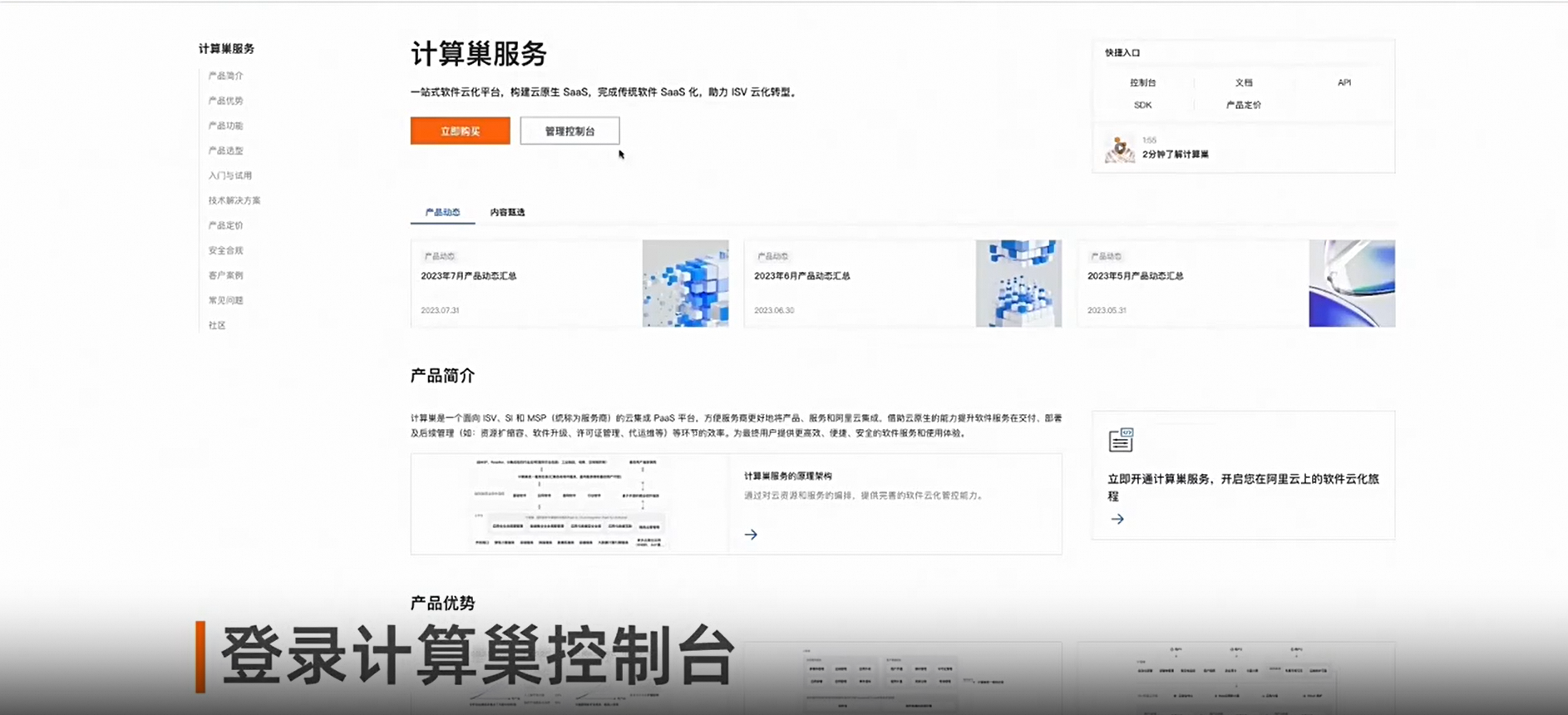 计算巢系列四:创建服务实例&并使用发布时间:2023-12-20 15:22:29 视频时长:3分52秒 播放量:227演示如何利用计算巢在服务市场选择一款服务并创建,对服务实例详情进行操作管理。
计算巢系列四:创建服务实例&并使用发布时间:2023-12-20 15:22:29 视频时长:3分52秒 播放量:227演示如何利用计算巢在服务市场选择一款服务并创建,对服务实例详情进行操作管理。 -
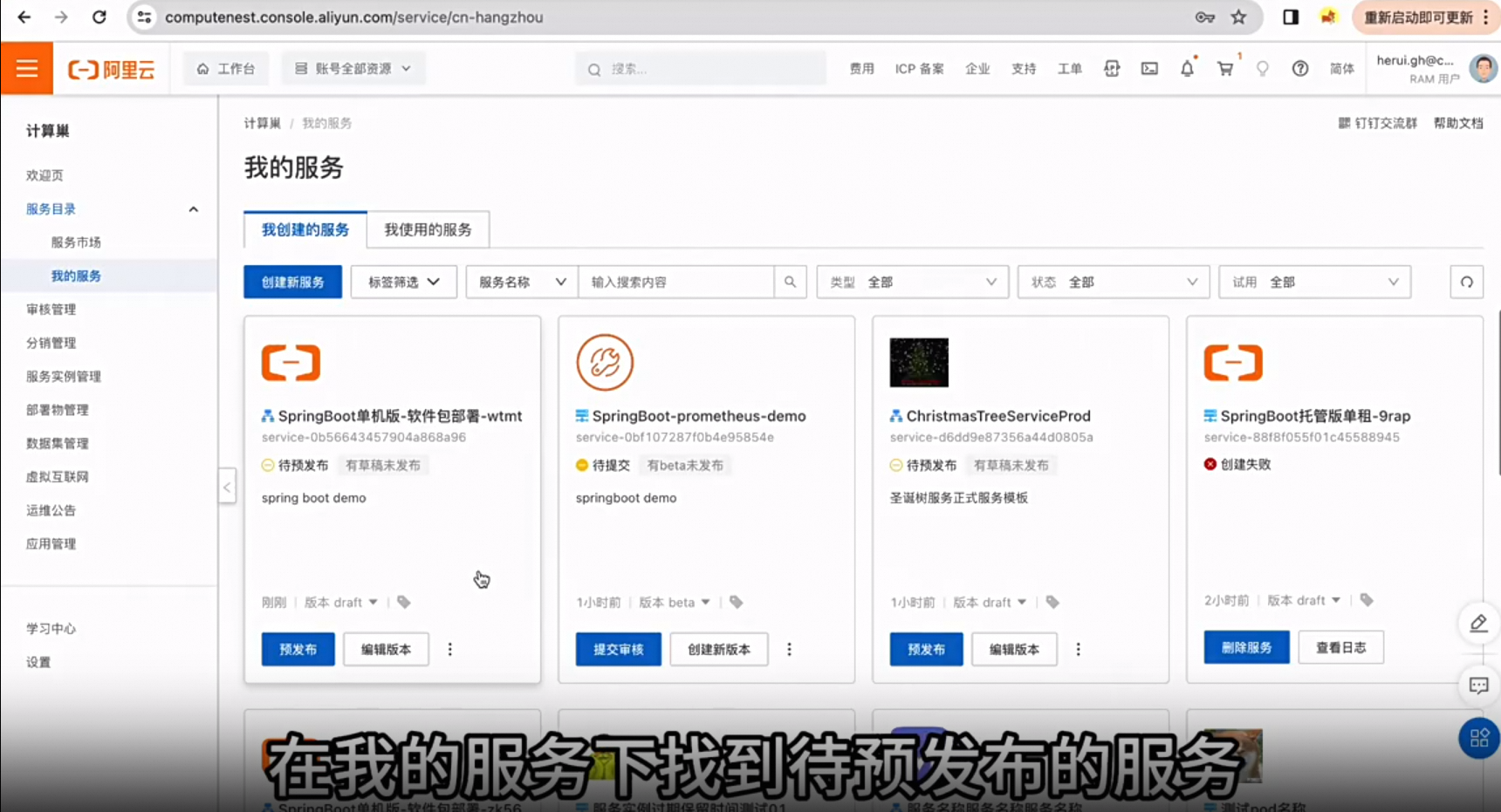 计算巢系列四:服务预发布发布时间:2023-12-20 15:18:51 视频时长:0分40秒 播放量:213演示如何利用计算巢预发布一个服务并获得受限服务,设置白名单下。
计算巢系列四:服务预发布发布时间:2023-12-20 15:18:51 视频时长:0分40秒 播放量:213演示如何利用计算巢预发布一个服务并获得受限服务,设置白名单下。 -
 计算巢系列四:服务自动化测试发布时间:2023-12-20 15:12:15 视频时长:4分30秒 播放量:196演示如何利用计算巢配置和使用。
计算巢系列四:服务自动化测试发布时间:2023-12-20 15:12:15 视频时长:4分30秒 播放量:196演示如何利用计算巢配置和使用。
滑动查看更多