



开源分布式数据库PolarDB-X源码解读
为了帮助大家理清头绪快速上手,我们发布了一系列的文章帮助大家理解阿里云云原生分布式数据库PolarDB-X源码。本书集合了PolarDB-X源码解读系列文章,希望通过这本书,能够让大家深入理解PolarDB-X。您可以了解PolarDB-X数据库的基本原理,学到一个数据库是如何实现的。您也可以把PolarDB-X的实现原理应用到其他系统,这对您学习其他数据库和分布式系统也有帮助。

PolarDB for PostgreSQL 14 开源实战训练营免费报名中!
通过本次课程您将学习到 PolarDB for PostgreSQL 架构解析以及企业级特性与应用的最佳实践、高可用、高性能、部署与使用等实战内容,更有免费线上实验环境,亲自动手体验 PolarDB for PostgreSQL 引擎兼容 PostgreSQL 14 版本的全新特性。


PolarDB for PostgreSQL 14 开源实战训练营玩法公告
通过本次课程您将学习到 PolarDB for PostgreSQL 架构解析以及企业级特性与应用的最佳实践、高可用、高性能、部署与使用等实战内容,更有免费线上实验环境,亲自动手体验 PolarDB for PostgreSQL 引擎兼容 PostgreSQL 14 版本的全新特性。

“数据库内核从入门到精通 ”系列课开讲!
基于 2022 年教育部-阿里云产学合作协同育人教学内容和课程改革项目合作,云原生分布式开源数据库 PolarDB 系列示范课程建设项目陆续和高校展开。阿里云开发者社区、阿里云PolarDB开源社区、武汉大学联合出品「数据库内核从入门到精通」系列课程正式上线,阿里云数据库专家携手高校教师系统化解读数据库理论,开展数据库实践,带学员全面掌握数据库内核开发技能。
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等
PolarDB 开源版 使用TimescaleDB 实现时序数据高速写入、压缩、实时聚合计算、自动老化等

PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)- 大数据与GIS分析解决线下店铺选址问题
寻龙点穴是风水学术语。古人说:三年寻龙,十年点穴。意思就是说,学会寻龙脉要很长的时间,但要懂得点穴,并且点得准则难上加难,甚至须要用“十年”时间。 但是,若没正确方法,就是用百年时间,也不能够点中风水穴心聚气的真点,这样一来,寻龙的功夫也白费了。 准确地点正穴心,并不是一件容易的事,对初学者来说如此,就是久年经验老手,也常常点错点偏。 寻龙点穴旨在寻找龙气聚集之地,而现实中,我们也有类似需求,比如找的可能是人气聚集之地。 PolarDB 开源版 使用PostGIS 数据寻龙点穴(空间聚集分析)- 大数据与GIS分析解决线下店铺选址问题
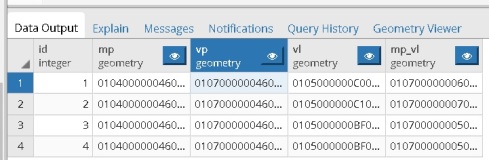
PolarDB 开源版 使用PostGIS 以及泰森多边形 解决 "零售、配送、综合体、教培、连锁店等经营"|"通信行业基站建设功率和指向" 的地理最优解问题
1、以KFC为例, 全国有很多家KFC连锁店, 每个店应该辐射哪些小区商圈? 开了新店之后, 与之相邻的老店辐射商圈应该怎么调整? KFC需要根据辐射小区商圈来预定销量、配置食材、配置多大的门店、多少营业员? 2、配送业务, 根据网点分布, 如何合理化每个网点负责的片区, 使得配送效率最高, 成本最低? 每一个写字楼有且只有一种选择到某个网点的距离最近. 3、基站建设, 每个基站应该对每个方向的功率调多大, 才能整体最优的解决网络质量和覆盖率问题. 以上其实都在回答一个问题: - 在有限的资源情况下, 如何整体最优的解决地理位置上的业务覆盖问题.

鼎医信息完成阿里云PolarDB数据库产品生态集成认证
近日,上海鼎医信息技术有限公司(以下简称鼎医信息)与阿里云PolarDB 开源数据库社区展开产品集成认证。测试结果表明,鼎医信息旗下医院资源运营管理软件(V5.0)与阿里云以下产品:阿里云PolarDB数据库管理软件,完全满足产品兼容认证要求,兼容性良好,系统运行稳定。

【Paper Reading】Cloud-Native Transactions and Analytics in SingleStore
HTAP & 云原生是如今数据库技术演进的两大热点方向。HTAP 代表既有传统的 HANA Delta RowStore+Main ColumnStore,Oracle In-MemoryColumnStore 等方案,也有像 TiDB,Snowflake Unistore这样新的技术架构;云原生代表则是以 S3 为低成本主存的 Snowflake,Redshift RA3,提供灵活弹性和Serverless 能力。SingleStore 则是首次把两者结合起来,基于计算存储分离的云原生架构,用一份存储提供低成本高性能的 HTAP 能力。
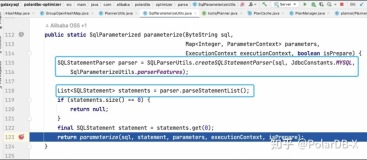
谈谈in常量查询的设计与优化
如标题所示,这是一篇介绍in常量查询的源码解读文章,但又不限于in常量查询,因为其中涉及的很多设计与优化对于大多数查询都是普适的。 一如往常一样,我们首先会过一遍整体的执行流程,梳理一个大致的框架。紧接着,同时也是更重要的,我们会通过一系列在真实场景中遇到的问题(说白了就是性能优化),来对各种细节处理进行增强。

实践教程之如何对PolarDB-X集群做动态扩缩容
PolarDB-X 为了方便用户体验,提供了免费的实验环境,您可以在实验环境里体验 PolarDB-X 的安装部署和各种内核特性。除了免费的实验,PolarDB-X 也提供免费的视频课程,手把手教你玩转 PolarDB-X 分布式数据库。
PolarDB 开源版 使用pgpool-II实现透明读写分离
PolarDB 开源版 使用pgpool-II实现透明读写分离. pgpool-II是PostgreSQL读写分离中间件, 由于PolarDB是计算存储分离架构, 和aws aurora一样, 只需要配置pgpool的负载均衡, 不需要配置它ha功能. ha功能建议采用polardb开源生态产品, 例如乘数科技的集群管理软件, 配置pgpool时使用rw, ro节点对应的vip即可(vip由乘数的集群管理软件来管理).
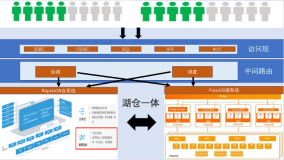
柏睿数据+PolarDB湖仓一体联合解决方案
柏睿数据和PolarDB联手,根据产品的特殊点整合统一的解决方案,新方案融合数据湖和数据仓库成为一种新型的开放式数据平台架构,PolarDB做湖,RapidsDB做仓,将数据湖和数据仓库的优势充分结合,通过RapidsDB的federation能力构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理、分析和管理功能。
PolarDB 开源生态插件心选 - 这些插件让业务战斗力提升100倍!!!
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版插件生态, 通过插件给数据库加装新的算法和索引|存储结构, 结合PolarDB的大规模存储管理能力, 实现算法和存储双剑合璧, 是企业在数据驱动时代的决胜利器.
PolarDB 开源版 轨迹应用实践 - 出行、配送、快递等业务的调度; 传染溯源; 刑侦
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 轨迹应用实践, 例如: - 出行、配送、快递等业务的调度 - 快递员有预规划的配送轨迹(轨迹) - 客户有发货需求(时间、位置) - 根据轨迹估算最近的位置和时间 - 通过多个嫌疑人的轨迹, 计算嫌疑人接触的地点、时间点
PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计算、分析
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 通过rdkit 支撑生物、化学分子结构数据存储与计算、分析
PolarDB 开源版 通过pgpointcloud 实现高效孪生数据存储和管理 - 支撑工厂、农业等现实世界数字化|数字孪生, 元宇宙相关业务的虚拟现实结合
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版 通过 pgpointcloud 实现高效孪生数据存储和管理 - 支撑工厂、农业等现实世界数字化|数字孪生, 元宇宙相关业务的虚拟现实结合
使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云数据的高速存储、压缩、高效精确提取
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 pgpointcloud 支撑激光点云数据的高速存储、压缩、高效精确提取
使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配送等商旅问题的路径规划业务
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 pgrouting 支撑出行、快递、配送等商旅问题的路径规划业务
使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路由等业务
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 部署 PostGIS 支撑时空轨迹|地理信息|路由等业务
使用 PolarDB 开源版 smlar 插件进行高效率相似文本搜索、自助选药、相似人群圈选等业务
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 smlar 插件进行高效率相似文本搜索、自助选药、相似人群圈选等业务
使用 PolarDB 开源版 bloom filter index 实现任意字段组合条件过滤
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 bloom filter index 实现任意字段组合条件过滤
使用 PolarDB 开源版 和 imgsmlr 存储图像特征值以及快速的进行图像相似搜索
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版 和 imgsmlr 存储图像特征值以及快速的进行图像相似搜索
使用 PolarDB 开源版 采用array数组和gin索引高效率解决用户画像、实时精准营销类业务需求
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍使用 PolarDB 开源版高效率解决用户画像、实时精准营销类业务需求
PolarDB 开源版通过 brin 实现千分之一的存储空间, 高效率检索时序数据
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的 价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 brin 实现千分之一的存储空间, 高效率检索时序数据
PolarDB 开源版通过 pg_trgm GIN 索引实现高效率 `like '%xxx%'` 模糊查询
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的 价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 pg_trgm GIN 索引实现高效率 `like '%xxx%'` 模糊查询
PolarDB 开源版通过 rum 实现高效率搜索和高效率排序的解决方案
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的 价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 rum 实现高效率搜索和高效率排序的解决方案
PolarDB 开源版通过 parray_gin 实现高效率 数组、JSON 内元素的模糊搜索
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的 价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 parray_gin 实现高效率 数组、JSON 内元素的模糊搜索
PolarDB 开源版通过 vrpRouting 解决 快递、出行、餐饮配送、旅游等商旅问题的最优解问题
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 vrpRouting 解决 快递、出行、餐饮配送、旅游等商旅问题的最优解问题
PolarDB 开源版通过 postgresql_hll 实现高效率 UV滑动分析、实时推荐已读列表过滤
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过 postgresql_hll 实现高效率 UV滑动分析、实时推荐已读列表过滤
PolarDB 开源版通过 duckdb_fdw 支持 parquet 列存数据文件以及高效OLAP
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力. 本文将介绍PolarDB 开源版通过duckdb_fdw 支持 parquet 列存数据文件以及高效OLAP.

PolarDB开源
PolarDB 开源社区是阿里云数据库开源产品PolarDB的技术交流平台。作为一款开源的数据库产品, 离不开用户和开发者的支持, 大家可以在社区针对PolarDB产品提问题、功能需求、交流使用心得、分享最佳实践、提交issue、贡献代码等。为了让社区成员可以更方便的交流, 促进数据库行业的发展, 社区会组织线上和线下的meetup, 举办高校、企业的交流活动, 组织技术类的竞技活动等。欢迎广大的数据库爱好者、用户、开发者加入社区大家庭。



