





Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama 3 研究论文。
千亿大模型来了!通义千问110B模型开源,魔搭社区推理、微调最佳实践
近期开源社区陆续出现了千亿参数规模以上的大模型,这些模型都在各项评测中取得杰出的成绩。今天,通义千问团队开源1100亿参数的Qwen1.5系列首个千亿参数模型Qwen1.5-110B,该模型在基础能力评估中与Meta-Llama3-70B相媲美,在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。
vanna+qwen实现私有模型的SQL转换
本文档介绍了如何在本地部署Vanna服务以使用Qwen模型进行text2sql转换。首先,通过`snapshot_download`下载Qwen-7B-Chat模型,并安装相关依赖。接着,修改`openai_api.py`设置本地LLM服务接口。然后,安装并配置Vanna Flask服务,包括自定义LLM服务、连接数据库以及修改端口。为了解决内网访问问题,使用ngrok或natapp进行内网穿透,提供公网访问。最后,处理了chromadb包中自动下载资源的问题,以防网络不佳导致的失败。通过这些步骤,实现了使用本地Qwen模型的Vanna服务。
Qwen1.5开源!魔搭最佳实践来啦!
近几个月来,通义千问团队一直在努力探索如何构建一个“好”的模型,同时优化开发者体验。就在刚刚,中国新年前夕,通义千问团队分享了Qwen开源系列的下一个版本,Qwen1.5。
幻方开源第二代MoE模型 DeepSeek-V2,魔搭社区推理、微调最佳实践教程
5月6日,幻方继1月份推出首个国产MoE模型,历时4个月,带来第二代MoE模型DeepSeek-V2,并开源了技术报告和模型权重,魔搭社区可下载体验。
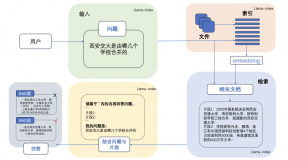
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
Llama3 中文通用Agent微调模型来啦!(附手把手微调实战教程)
Llama3模型在4月18日公布后,国内开发者对Llama3模型进行了很多训练和适配,除了中文纯文本模型外,多模态版本也陆续在发布中。
LLama Factory+ModelScope实战——使用 Web UI 进行监督微调
LLaMA Factory 是一个高效的大语言模型训练和推理框架,它通过提供一站式的 Web UI 界面和集成多种训练方法,简化了大模型的微调过程,并能够适配多种开源模型。
【RAG实践】Rerank,让RAG更近一步
本文主要关注在Rerank,本文中,Rerank可以在不牺牲准确性的情况下加速LLM的查询(实际上可能提高准确率),Rerank通过从上下文中删除不相关的节点,重新排序相关节点来实现这一点。
社区供稿 | 中文llama3模型哪家强?llama3汉化版微调模型大比拼
随着llama3的发布,业界越来越多的针对其中文能力的微调版本也不断涌现出来,我们在ModelScope魔搭社区上,搜集到几款比较受欢迎的llama3中文版本模型,来从多个维度评测一下,其对齐后的中文能力到底如何? 微调后是否产生了灾难性遗忘问题。

基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)
基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)
大模型时代,还缺一只雨燕 | SWIFT:魔搭社区轻量级微调推理框架
伴随着大数据的发展和强大的分布式并行计算能力,以预训练+微调的模型开发范式渐渐成为深度学习领域的主流。 2023年各家推出的大模型浩如烟海,如GPT4、Llama、ChatGLM、Baichuan、RWKV、Stable-Diffusion等。这些模型在达到越来越好的效果的同时也需要越来越多的算力资源:全量finetune它们动辄需要几十至上百G显存训练部署,一般的实验室和个人开发者无力承担。
Phi-3:小模型,大未来!(附魔搭社区推理、微调实战教程)
近期, Microsoft 推出 Phi-3,这是 Microsoft 开发的一系列开放式 AI 模型。Phi-3 模型是一个功能强大、成本效益高的小语言模型?(SLM),在各种语言、推理、编码和数学基准测试中,在同级别参数模型中性能表现优秀。为开发者构建生成式人工智能应用程序时提供了更多实用的选择。
FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量的计算资源,而能效比高的 Arm 架构服务器可以提供更好的性能和效率。
DeepSeek VL系列开源,魔搭社区模型微调最佳实践教程来啦!
3月11日,DeepSeek-AI开源了全新多模态大模型DeepSeek-VL系列,包含1.3b、7b两种不同规模的4个版本的模型。
社区供稿 |【中文Llama-3】Chinese-LLaMA-Alpaca-3开源大模型项目正式发布
Chinese-LLaMA-Alpaca-3开源大模型项目正式发布,开源Llama-3-Chinese-8B(基座模型)和Llama-3-Chinese-8B-Instruct(指令/chat模型)
multi-agent:多角色Agent协同合作,高效完成复杂任务
随着LLM的涌现,以LLM为中枢构建的Agent系统在近期受到了广泛的关注。Agent系统旨在利用LLM的归纳推理能力,通过为不同的Agent分配角色与任务信息,并配备相应的工具插件,从而完成复杂的任务。
社区供稿 | Llama3-8B中文版!OpenBuddy发布新一代开源中文跨语言模型
此次发布的是在3天时间内,我们对Llama3-8B模型进行首次中文跨语言训练尝试的结果:OpenBuddy-Llama3-8B-v21.1-8k。
【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人
LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
阿里云灵积平台Java SDK调用教程
开通阿里云灵积服务并创建API-KEY,添加Java依赖`dashscope-sdk-java`版本2.11.0。示例代码展示如何使用SDK进行多模态对话,调用`MultiModalConversation`进行交互,并打印结果。测试结果显示输出对一张图片的描述。参考链接提供通义千问VL快速入门指南。
LLM大模型实战 —— DB-GPT阿里云部署指南
DB-GPT 是一个实验性的开源应用,它基于FastChat,并使用vicuna-13b作为基础模型, 模型与数据全部本地化部署, 绝对保障数据的隐私安全。 同时此GPT项目可以直接本地部署连接到私有数据库, 进行私有数据处理, 目前已支持SQL生成、SQL诊断、数据库知识问答、数据处理等一系列的工作。
快来与 CodeQwen1.5 结对编程
今天,来自 Qwen1.5 开源家族的新成员,代码专家模型 CodeQwen1.5开源!CodeQwen1.5 基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了优秀的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
通义千问14B开源!内附魔搭最佳实践
9月25日,阿里云开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用。Qwen-14B在多个权威评测中超越同等规模模型,部分指标甚至接近Llama2-70B。阿里云此前开源的70亿参数模型Qwen-7B等,一个多月下载量破100万,成为开源社区的口碑之作。


