








读《长安十二时辰》有感——SIEM/SOC 建设要点—Elastic Stack 实战手册
最近读了马伯庸老师的小说《长安十二时辰》(也有改为《长安二十四时辰》的网剧,之所以改成二十四时辰,我觉得也是非常的不认可原著里面的时间观念吧?
Data stream-Elastic Stack 实战手册
时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况
跨集群操作—Elastic Stack 实战手册
Elasticsearch 集群天然支持横向水平扩展,因此当业务规模扩大、对集群产生读写压力时,增加节点总是运维人员的“懒人选择”。但随着节点数增多,集群主节点要维护的 meta 信息也随之增多,这会导致集群更新压力增大,甚至无法提供正常服务。 另外每个企业的数据中心都需要有灾备方案,在集群间同步数据,因为单点集群会存在隐患。
Rollover API— Elastic Stack 实战手册
使用`Rollover index`的方式来限制每个索引的大小。
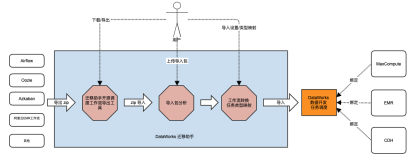
DataWorks搬站方案:Airflow作业迁移至DataWorks
DataWorks提供任务搬站功能,支持将开源调度引擎Oozie、Azkaban、Airflow的任务快速迁移至DataWorks。本文主要介绍如何将开源Airflow工作流调度引擎中的作业迁移至DataWorks上

融合趋势下基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flink、Kylin 和 Hudi 湖仓一体的大数据生态体系以及在 T3 的相关应用场景。

官方指南!史上最全实时计算 Flink 版学习资料汇总(长期更新)
阿里云实时计算 Flink 版:企业级、高性能、Serverless 实时大数据服务。

Elasticsearch生态&技术峰会 | Elasticsearch在企查查的应用实践
开源最大的特征就是开放性,云生态则让开源技术更具开放性与创造性,Elastic 与阿里云的合作正是开源与云生态共生共荣的典范。值此合作三周年之际,我们邀请业界资深人士相聚云端,共话云上Elasticsearch生态与技术的未来。
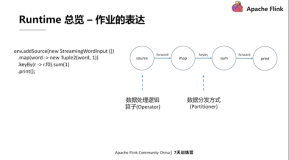
Flink 必知必会经典课程3:Flink Runtime Architecture
众所周知 Flink 是分布式的数据处理框架,用户的业务逻辑会以Job的形式提交给 Flink 集群。Flink Runtime作为 Flink 引擎,负责让这些作业能够跑起来并正常完结。这些作业既可以是流计算作业,也可以是批处理作业,既可以跑在裸机上,也可以在Flink集群上跑,Flink Runtime必须支持所有类型的作业,以及不同条件下运行的作业。

DataWorks数据建模公开课上线啦!
数据建模是数据标准化的核心内容,企业在搭建自己的数据平台时需要先建设适合公司业务的数据模型。好的数据模型可以帮助企业构建合理的数据基础结构,帮助企业少走弯路,节省长期开发成本。 本次阿里云DataWorks数据建模公开课邀请到Datablau创始人&CEO王琤老师为大家带来数据建模系列讲座,内容涵盖数据建模基本知识和企业级标准、架构与模型设计,以及阿里云DataWorks数据中台模型管理平台解决方案。

迄今为止最好用的Flink SQL教程:Flink SQL Cookbook on Zeppelin
无需写任何代码,只要照着这篇文章轻松几步就能跑各种类型的 Flink SQL 语句。

提效神器,DataWorks OpenAPI开放!
工欲善其数,必先利其器。通过DataWorks OpenAPI 功能,可以快速进行批量操作与系统集成对接,助您显著提升数据开发效率!(DataWorks OpenAPI限企业版及以上版本使用)

深度集成 Flink: Apache Iceberg 0.11.0 最新功能解读
Apache Flink 和 Apache Iceberg 在共同打造流批一体的数据湖架构上开启了新的篇章。

DataWorks OpenAPI 实战-数据开发全流程介绍
DataWorks作为飞天大数据平台操作系统,历经11年发展,形成了涵盖数据集成、数据开发、数据治理、数据服务的一站式大数据开发治理平台。很多企业用户在使用产品的过程中希望他们的本地服务能够和阿里云上的DataWorks服务进行交互,从而提升企业大数据处理的效率,减少人工操作和运维工作,降低数据风险和企业成本,现在DataWorks开放OpenAPI能力满足企业的定制化需求。
MaxCompute 行转列 列转行
搜了一下行转列、列转行,除了隐林一篇之外,好像没有了 最近在帮助项目组初学者整理初学者文档,刚好用关系型数据库的例子变化实现了一个 借鉴:/article/40518 供大家参考
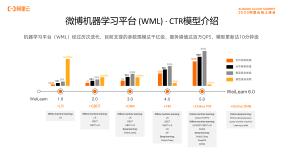
微博机器学习平台云上最佳实践
本文讲述了微博机器学习平台和深度学习平台的业务功能和云上实践,剖析了阿里云大数据在微博这两大学习平台的架构建设上所起到的作用。

金融科技数据湖构建和管理之道
上海数禾信息科技有限公司是一家拥有小贷牌照和融资担保牌照的金融科技公司(下称“数禾科技”),公司的核心产品是“还呗”。本文要分享的主题是数禾科技如何在云上构建和管理数据湖。
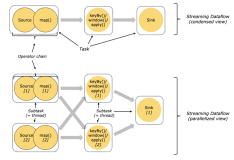
深入解析 Flink 的算子链机制
“为什么我的 Flink 作业 Web UI 中只显示出了一个框,并且 Records Sent 和Records Received 指标都是 0 ?是我的程序写得有问题吗?”

网易:Flink + Iceberg 数据湖探索与实践
今天主要和大家交流的是网易在数据湖 Iceberg 的一些思考与实践。从网易在数据仓库建设中遇到的痛点出发,介绍对数据湖 Iceberg 的探索以及实践之路。

数据湖架构,为什么需要“湖加速”?
湖加速即为数据湖加速,是指在数据湖架构中,为了统一支持各种计算,对数据湖存储提供适配支持,进行优化和缓存加速的中间层技术。那么为什么需要湖加速?数据湖如何实现“加速”?本文将从三个方面来介绍湖加速背后的原因,分享阿里云在湖加速上的实践经验和技术方案。

腾讯看点基于 Flink 的实时数仓及多维实时数据分析实践
当业务发展到一定规模,实时数据仓库是一个必要的基础服务。从数据驱动方面考虑,多维实时数据分析系统的重要性也不言而喻。但是当数据量巨大的情况下,拿腾讯看点来说,一天上报的数据量达到万亿级的规模,要实现极低延迟的实时计算和亚秒级的多维实时查询是有技术挑战的。

JindoFS缓存加速数据湖上的机器学习训练
JindoFS提供了一个计算侧的分布式缓存系统,可以有效利用计算集群上的本地存储资源(磁盘或者内存)缓存OSS上的热数据,从而减少对OSS上数据的反复拉取,消耗网络带宽。

玩转AI,你有机会吗?
随着大数据、云计算的普及,AI在各个领域的热度不断攀升,AI技术已经成为人们日常生活、工作中必不可少的要素。 于是,全民用AI带动着全民学AI的热潮的到来~
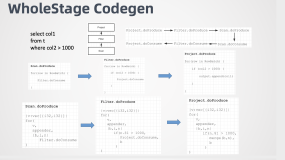
EMR Spark-SQL性能极致优化揭秘 Native Codegen Framework
EMR团队探索并开发了SparkSQL Native Codegen框架,为SparkSQL换了引擎,新引擎带来最高4倍性能提升,为EMR再次获取世界第一立下汗马功劳。来自阿里云EMR团队的周克勇将详细介绍Native Codegen框架。

双亲委派模型与 Flink 的类加载策略
Flink 作为基于 JVM 的框架,在 flink-conf.yaml 中提供了控制类加载策略的参数 classloader.resolve-order,可选项有 child-first(默认)和 parent-first。本文来简单分析一下这个参数背后的含义。
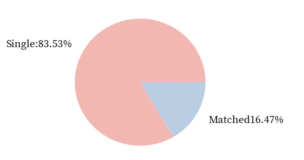
大数据算命系列之用机器学习评估你的相亲战斗力 | 《阿里云机器学习PAI-DSW入门指南》
害,想知道你的相亲战斗力是多少吗?动手体验数据科学,成为PAI-DSW探索者~你想要知道的都在这里!

基于 Flink 的典型 ETL 场景实现
本文将从数仓诞生的背景、数仓架构、离线与实时数仓的对比着手,综述数仓发展演进,然后分享基于 Flink 实现典型 ETL 场景的几个方案。

PAI:一站式云原生AI平台
本文是《飞天大数据产品价值解读系列》之《一站式云原生AI平台》的视频分享精华总结,主要由阿里云机器学习PAI团队的产品经理高慧玲(花名:玲汐)向大家介绍了阿里巴巴整体的AI情况以及一站式云原生的AI平台PAI,并且做了简单的DEMO演示。
FlinkX 如何读取和写入 Clickhouse?
本文将主要介绍 FlinkX 读取和写入 Clickhouse 的过程及相关参数,核心内容将围绕以下3个问题:1. FlinkX读写Clickhouse支持哪个版本?、2. ClickHouse读写Clickhouse有哪些参数?、3. ClickHouse读写Clickhouse参数都有哪些说明?


Apache Spark 3.0中的SQL性能改进概览
阿里巴巴高级技术专家李呈祥为大家带来Apache Spark 3.0中的SQL性能改进概览的介绍。以下由Spark+AI Summit中文精华版峰会的精彩内容整理。
DataWorks百问百答40:本地自定义函数UDF如何在DataWorks上使用?
本地自定义函数UDF如何在DataWorks上使用

Elasticsearch 字段类型之 Range 经典应用场景
Elasticsearch 产品功能越来越强大,字段类型支持很多种,部分类型还引入了专用的算法。一个客户企业选中 Elasticsearch 作为搜索中台,居然是看中了 Elasticsearch 的 Range 字段类型,下面就围绕这个 Range 类型展开。
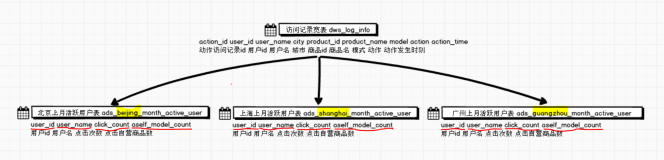
DataWorks百问百答36:如何在DataWorks中使用组件(SQL存储过程)实现代码复用?
组件-可视化SQL存储过程应用场景案例

【资源分享】esrally:Elasticsearch 官方压测工具测试数据共享(国内)
自从上篇发布的关于“【最佳实践】esrally:Elasticsearch 官方压测工具及运用详解”后,不停有同学询问使用中遇到的问题,尤其是测试数据存储在国外 aws 上,导致下载极慢的情况出现。为了让大家快速上手使用 esrally,我 build 了一个可用的 docker 镜像,将 13GB 的测试数据拉取到国内的存储上,通过百度网盘的方式分享给大家。大家只要按照下面简单的几步操作就可以顺畅地使用 esrally 来进行相关测试了。

从MongoDB迁移到Elasticsearch后,我们减少了80%的服务器
本文介绍“为什么要从MongoDB迁移到Elasticsearch?”以及“如何从MongoDB迁移到Elasticsearch?”。
揭秘!开源软件背后的神秘组织
Flink 社区将分享“走进 ASF”系列内容,先从宏观介绍 ASF 是如何运作的,然后详细解说如何参与 Apache 具体项目做贡献,如何成为某个项目的 Committer、PMC 成员,如何选择多个 Apache 项目进行多领域贡献并成为 ASF Member 等,希望有助于你真正了解开源、参与开源。
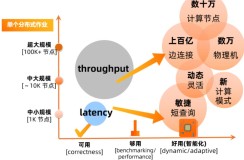
EB级计算平台调度系统伏羲DAG 2.0:构建更动态更灵活的分布式计算生态
伏羲(Fuxi)是十年前创立飞天平台时的三大服务之一(分布式存储 Pangu,分布式计算 MaxCompute(内部代号ODPS),分布式调度 Fuxi),过去十年来,伏羲在技术能力上每年都有新的进展和突破,2013年5K,2015年Sortbenchmark世界冠军,2017年超大规模离在/在离线混部能力,2019年的 Yugong 发布并且论文被VLDB2019接受等。

EMR Spark-SQL性能极致优化揭秘 概览篇
这次的优化里面,还有一个很好玩的优化,就是我们引入的 Native Runtime,如果说上述的优化器优化都是一些特殊 Case 的杀手锏,Native Runtime 就是一个广谱大杀器,根据我们后期统计,引入 Native Runtime,可以普适性的提高 SQL Query 15~20%的 E2E 耗时,这个在TPCDS Perf 里面也是一个很大的性能提升点。

Apache Flink 进阶(十二):深度探索 Flink SQL
文章将从用户的角度来讲解 Flink 1.9 版本中 SQL 相关原理及部分功能变更,希望加深大家对 Flink 1.9 新功能的理解,在使用上能够有所帮助。

MaxCompute管家详解--管家助力,轻松玩转MaxCompute
由于单台服务器的处理能力有限,海量数据的分析需要分布式的计算模型,然而分布式的计算模型对数据分析人员要求较高且不易维护。MaxCompute(原ODPS)是一项大数据计算服务,它能提供快速、完全托管的PB级数据仓库解决方案,使用户可以经济并高效的分析处理海量数据,而MaxCompute管家可以帮助用户更好地进行管理和维护。

阿里云智能事业群 EMR团队招人啦!
加入我们,成为分布式存储,计算和调度等领域的专家,与众多业界和社区技术专家一起工作,加速大数据上云,投身数字时代新基建。
Flink Weekly | 每周社区动态更新 - 20200313
Flink Weekly 周报计划每周更新一期,内容涵盖邮件列表中用户问题的解答、社区开发和提议的进展、社区新闻以及其他活动、博客文章等,欢迎持续关注~

日志分析:阿里云 Logstash & Beats 简单低成本接入上千数据源
Logstash & Beats,在整个 Elastic Stack 数据链路中,属于前数据链路,目的是把多源数据接入到 Elasticsearch 中,并由 Elasticsearch 进行各种分析及检索,所以对于 Elastic Stack 来说,前数据链路的数据接入难度及复杂度,决定了业务数据实时监测及问题定位的难度。如何快速、简单、低成本接入多源数据?本文告诉你答案。

Delta Lake - 数据湖的数据可靠性
Delta Lake 是一个开源的存储层,为数据湖带来了可靠性。Delta Lake 提供了ACID事务、可伸缩的元数据处理以及统一的流和批数据处理。它运行在现有的数据湖之上,与 Apache Spark API完全兼容。

基于 Flink 的超大规模在线实时反欺诈系统的建设与实践
如何更快速地预防或甄别可能的欺诈行为?如何从超大规模、高并发、多维度的数据中实现在线实时反欺诈?这些都是金融科技公司当下面临的主要难题。针对这一问题,玖富集团打造基于 Flink 的超大规模在线实时反欺诈系统,快速处理海量数据并实现良好的用户体验。

内核调优 | 如何提升Elasticsearch master调度性能40倍
自建集群从Elasticsearch 6.3.2 版本升至 7.4.0 版本,如何解决Master卡顿、创建/删除索引耗时过多的问题?本文给你答案。
Flink 1.10 Native Kubernetes 原理与实践
Flink 在 1.10 版本完成了 Active Kubernetes Integration 的第一阶段,支持了 session clusters。后续的第二阶段会提供更完整的支持,如支持 per-job 任务提交,以及基于原生 Kubernetes API 的高可用,支持更多的 Kubernetes 参数如 toleration, label 和 node selector 等。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
