ШЋЮФСДНгЃКhttp://tecdat.cn/?p=32633
ЮяСїЗЂЛѕУїЯИЪ§ОндкЯжДњЮяСївЕжаАчбнзХжСЙиживЊЕФНЧЩЋЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
ЭЈЙ§ЖдетаЉЪ§ОнНјааЭкОђКЭЗжЮіЃЌЮвУЧПЩвдЗЂЯжвўКЌдкБГКѓЕФЙЉгІСДдЫгЊЙцТЩКЭЩЬвЕФЃЪНЃЌДгЖјжИЕМЦѓвЕдкЮяСїВпТдЁЂГЩБОЙмРэКЭПЭЛЇЗўЮёЕШЗНУцзіГіИќМгПЦбЇКЭгааЇЕФОіВпЁЃ
SPSS ModelerЪЧвЛПюЙІФмЧПДѓЁЂНчУцгбКУЕФЪ§ОнЭкОђКЭЗжЮіЙЄОпЃЌПЩвдАяжњЦѓвЕЖдЮяСїЗЂЛѕУїЯИЪ§ОнНјааЩюШыКЭзМШЗЕФЭкОђЗжЮіЃЌЬсИпЪ§ОнМлжЕКЭдЫгЊаЇТЪЁЃ
БОЮФНЋвдSPSS ModelerАяжњПЭЛЇЗжЮіЮяСїЗЂЛѕУїЯИЪ§ОнЃЌНщЩмШчКЮЪЙгУSPSS ModelerЖдЮяСїЗЂЛѕУїЯИЪ§ОнНјааОлРрЗжЮіКЭЙиСЊЙцдђЭкОђЃЌВЂЗжЮіЕУГігавцЕФНсТлКЭНЈвщЃЌЮЊЦѓвЕЕФЮяСїдЫгЊКЭЗЂеЙЬсЙЉВЮПМгыжЇГжЁЃ
Ъ§ОнЕФдЄДІРэ
БОбаОПЕФЪ§ОнЪЧвЛзщЙигкЮяСїЕФЗЂЛѕУїЯИЃЌЪ§ОнАќРЈвдЯТзжЖЮЃКЯюФПЁЂжИСюШеЦкЁЂЪМЗЂЪЁЁЂЪМЗЂЪаЁЂФПЕФЪЁЁЂФПЕФЪаЁЂЪеЛѕШЫЕЅЮЛЁЂЦЗУћЁЂЪ§СПЁЂЧЉЪеЪБМфЁЂЧЉЪеЪ§СПЁЂОмЪеЪ§СПКЭОмЪедвђЁЃ

ЖдЪ§ОнНјаадЄДІРэЃК
ЃЈ1ЃЉВЙГфШБЪЇжЕЁЃЖдУЛгаМЧТМЕФЪ§ОнШБЪЇВЩгУЦНОљжЕЗЈЃЌвдИУзжЖЮЕФЦНОљЗжЪ§ЬюГфЁЃ
ЃЈ2ЃЉЙцЗЖЛЏЪ§ОнЁЃдЫгУзюаЁ-зюДѓЙцЗЖЛЏЗНЗЈЖдЪ§ОнНјааЙцЗЖЛЏДІРэЃЌНЋЪ§ОнгГЩфЕН[0,1]ЧјМфЃЌМЦЫуЙЋЪНШчЯТЁЃ

ЦфжаЃКymaxЮЊИУзжЖЮЕФзюДѓжЕЃЛ
yminЮЊИУзжЖЮЕФзюаЁжЕЁЃ
Й§ГЬМАНсЙћЗжЮі
ЃЈ1ЃЉЖСШЁЪ§Он
бЁдёSPSS ModelerЕФSource-Excel-DataЃЌдкDataбЁЯювГжаЭЈЙ§Import FilesЪфШыПђбЁЖЈExcelИёЪНЕФГЩМЈБэЮФМўЃЌВЂЕуЛїRead Values АДХЅЃЌНЋЫљгаЪ§ОнЖСШыЃЌШчЭМЫљЪОЁЃ
ЃЈ2ЃЉK-Means ФЃаЭЩшжУ
бЁдёSPSS ModelerЕФModeling-K-meansЃЌНЋK-MeansФЃаЭНкЕуЬэМгНјЪ§ОнСїРДЃЌЫЋЛїK-MeansЭМБъЃЌдкЕЏГіЕФЖдЛАПђжабЁдёModelбЁЯювГЃЌбЁЯювГжаЕФВЮЪ§НтЪЭШчЯТЃК
1ЃЉNumbers of clusterЃКжЦЖЈЩњГЩЕФОлРрЪ§ФПЃЌетРяЩшжУЮЊ3.
2ЃЉUse Partitioned DataЃКШчЙћгУЛЇЖЈвхСЫЗжИюЪ§ОнМЏЃЌбЁдёбЕСЗЪ§ОнМЏзїЮЊНЈФЃЪ§ОнМЏЃЌВЂРћгУВтЪдЪ§ОнМЏЖдФЃаЭНјааЦРМлЁЃ
МЬајбЁдёЖдЛАПђжаЕФExpertбЁЯювГЃЌШчЭМ5ЫљЪОЃЌЖдИУбЁЯювГжаЕФВЮЪ§зівЛЯТЩшжУЃК
ModelбЁЯюЃКбЁдёExpertФЃЪНЃЌБэЪОНЋНјааИпМЖФЃЪНЕФбЁдёЁЃ
Stop onбЁЯюЃКбЁдёcustomбЁЯюаоИФЕќДњжежЙЕФЬѕМўЃК
1ЃЉMaximum iterationsЃЈзюДѓЕќДњЪ§ЃЉЃКИУбЁЯюдЪаэдкЕќДњжЦЖЈДЮЪ§КѓжежЙбЕСЗЃЌетРяЩшжУЮЊ20.
2ЃЉChange toleranceЃЈВювьШнШЬЖШЃЉЃКИУбЁЯюдЪаэдквЛДЮЕќДњжажЪаФжЎМфЕФзюДѓВювьаЁгкжЦЖЈЫЎЦНЪБжежЙбЕСЗЁЃ

ЃЈ3ЃЉжДааКЭЪфГі
ЩшжУЭъГЩКѓЃЌбЁжаExecute АДХЅЃЌМДПЩЕУЕНжДааВЂЙлВьЕННсЙћЁЃЕуЛїVIEWбЁЯюПЈЃЌПЩвдвдЭМБэЕФаЮЪНРДЯдЪОФЃаЭЕФЭГМЦаХЯЂвдМАИїИіЪєаддкИїДижаЕФЗжВМаХЯЂЁЃ

ЕуЛїБъЬтВщдФЭљЦкФкШн

SPSSгУKОљжЕОлРрKMEANSЁЂОіВпЪїЁЂТпМЛиЙщКЭTМьбщбаОПЭЈЧкГіааНЛЭЈЗНЪНбЁдёЕФгАЯьвђЫиЕїВщЪ§ОнЗжЮі
01

02
03

04
ЃЈ4ЃЉОлРрНсЙћ
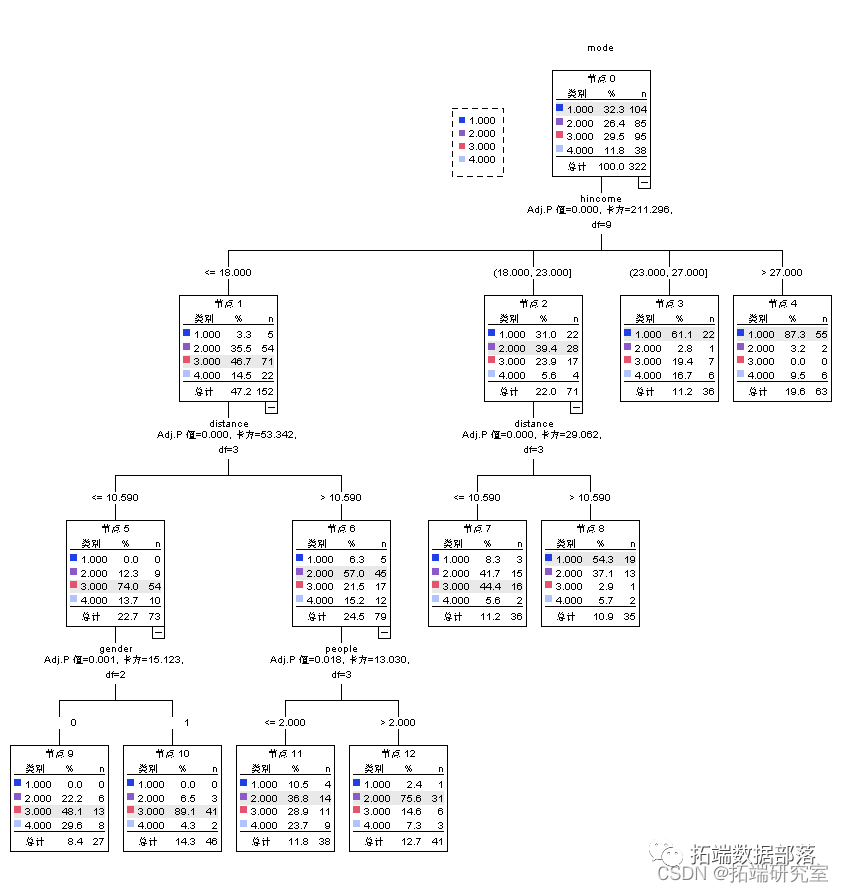
НсЙћБэУїЃКДи1КЭ2жаЕФЧЉЪеЪ§СПНЯЕЭЃЌДи5жаЕФЧЉЪеЪ§СПвЛАуЃЌДи4жаЕФЧЉЪеЪ§СПзюЕЭЃЌПЩМћЃЌДѓВПЗжбљБОЕФЧЉЪеЪ§СПДІгкжаЕШЫЎЦНЃЛИїБфСПдкИїДижаЕФЯджјГЬЖШОљНЯДѓЃЌБэУїВЛЭЌОлРрДиЕФЧЉЪеЪ§СПЕФЗжЛЏГЬЖШНЯИпЃЌВювьЯджјЁЃ
Ди1

Ди2

Ди3

Ди4

Ди5

ДгУПИіОлРрДиЕФЧщПіРДПДЃЌЧЉЪеЪ§СПзюЖрЕФЪЧЕк5ИіДиЃЌИУДижаЕФзюЖрЕФЪМЗЂЕиЪЧЙуЖЋЩюлкЃЌЧЉЪеЪ§СПДяЕНСЫ2833МўЃЌЦфДЮЪЧЩЯКЃЃЌЧЉЪеЪ§СПДяЕНСЫ1287ЁЃЭЌЪБДгНсЙћПЩвдПДЕНЫФДЈГЩЖМЕФЧЉЪеЪ§СПзюЕЭЃЌЫЕУїЮяСїЕФМЏжаЕиМЏжадкЙуЖЋЩюлкЩЯКЃЕШЕиЁЃ
ЙиСЊЙцдђЭкОђ
БОЮФЗжБ№гУAprioriЫуЗЈЖдЪ§ОнНјааДІРэЭкОђЃЌОпЬхНсЙћШчЯТЫљЪОЁЃ
ЃЈ1ЃЉAprioriЫуЗЈ
ЫфШЛ Apriori ЫуЗЈПЩвджБНгЭкОђЩњГЩБэжаЕФНЛвзЪ§ОнМЏЃЌЕЋЪЧЮЊСЫЙиСЊЭкОђЦфЫћЫуЗЈЕФашвЊЯШАбНЛвзЪ§ОнМЏзЊЛЛГЩЗжЮіЪ§ОнМЏЃЌЙЙНЈЕФЪ§ОнСїШчЭМЫљЪОЁЃ

ЭМ 1 ЩЬЦЗЙиСЊЙцдђ Apriori ЫуЗЈЭкОђСїЭМ
ЭЈЙ§ИёЪНзЊЛЛЃЌЗЂЯжЪ§ОндДжаЙВгаЖўЪЎжжЩЬЦЗЃЌЩшзюЕЭЬѕМўжЇГжЖШЮЊ15%ЃЌзюаЁЙцдђжУаХЖШЮЊ30%ЃЌзюДѓЧАЯюЪ§ЮЊ5ЃЌбЁдёзЈМвФЃЪНЃЌЭкОђГіДѓРрЩЬЦЗЕФ15ЬѕЙиСЊЙцдђЃЌШчЭМЫљЪОЁЃЩњГЩЕФ38ЬѕЙцдђШчЯТЫљЪОЃК

ЗжЮіМАНЈвщ: ЭЈЙ§ЭМПЩвдЧхЮњЕФПДЕНЩюлкЁЂЙуЖЋЁЂББОЉЕФЮяСїЖЉЕЅБШНЯЖрЃЌНЈвщЮяСїЦѓвЕПЩвдМгДѓЖдетаЉЕиЧјЕФЙЄзїШЫдБАВХХЃЌгЩЩЯЪіНсЙћПЩжЊЃЌЗЂЭљББОЉКЭЗЂЭљЙуЖЋЩюлкЕФЮяСїдЫЕЅЗжБ№еМзмдЫЕЅЪ§ЕФ51.515%ЃЌ41.414%ЃЌгЩДЫПЩМћЃЌББОЉ ЩНЖЋ ЩюлкШ§ИіФПЕФЕиЕФЙиСЊЖШНЯИпЃЌПЩвдНЋетаЉЕиЕуЕФВжПтАкЗХдквЛПщЃЌДгЖјдіМгаЇТЪЁЃЭЌЪБПЩвдПДЕН ЗЂЭљББОЉЕФЮяЦЗжаГіЯжСЫНЯЖрЕФ Ш§аЧ SM-W2016ЩЬЦЗЁЃвђДЫЃЌПЩвдНЋетаЉЩЬЦЗНЛгЩзЈШЫРДИКд№РДЬсИпаЇТЪЁЃ
зюКѓЮвУЧЕУЕНСЫвдЯТНсЙћКЭЮФМўЃК


